Relationale Datenbanken stellen die Daten einer Organisation in Tabellen dar, die Spalten mit unterschiedlichen Datentypen verwenden, die es ihnen ermöglichen, gültige Werte zu speichern. Entwickler und DBAs müssen den entsprechenden Datentyp für jede Spalte kennen und verstehen, um eine bessere Abfrageleistung zu erzielen.
Dieser Artikel befasst sich mit den beliebten Datentypen VARCHAR() und NVARCHAR(), ihrem Vergleich und Leistungsüberprüfungen in SQL Server.
VARCHAR [ ( n | maximal ) ] in SQL
Der VARCHAR Datentyp stellt den Nicht-Unicode dar String-Datentyp mit variabler Länge. Sie können darin Buchstaben, Zahlen und Sonderzeichen speichern.
- N stellt die Stringgröße in Bytes dar.
- Die Datentypspalte VARCHAR speichert maximal 8000 Nicht-Unicode-Zeichen.
- Der Datentyp VARCHAR benötigt 1 Byte pro Zeichen. Wenn Sie den Wert für N nicht explizit angeben, wird 1 Byte Speicherplatz benötigt.
Hinweis:Verwechseln Sie nicht N mit einem Wert, der die Anzahl der Zeichen in einer Zeichenfolge darstellt.
Die folgende Abfrage definiert den Datentyp VARCHAR mit 100 Datenbytes.
DECLARE @text AS VARCHAR(100) ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Es gibt die Länge als 17 zurück, wegen 1 Byte pro Zeichen, einschließlich eines Leerzeichens.
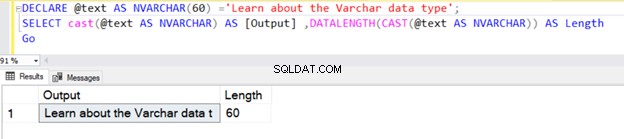
Die folgende Abfrage definiert den Datentyp VARCHAR ohne den Wert N . Daher betrachtet SQL Server den Standardwert als 1 Byte, wie unten gezeigt.
DECLARE @text AS VARCHAR ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
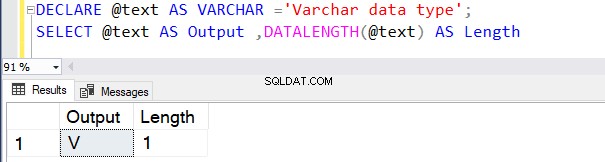
Wir können VARCHAR auch mit der CAST- oder CONVERT-Funktion verwenden. Beispielsweise haben wir in den beiden folgenden Beispielen eine Variable mit 100 Byte Länge deklariert und später den CAST-Operator verwendet.
Die erste Abfrage gibt die Länge als 30 zurück, weil wir N nicht im VARCHAR-Datentyp des CAST-Operators angegeben haben. Die Standardlänge ist 30.
DECLARE @text AS VARCHAR(100) ='Learn about the VARCHAR data type';
SELECT cast(@text AS VARCHAR) AS [Output] ,DATALENGTH(CAST(@text AS VARCHAR)) AS Length
Go
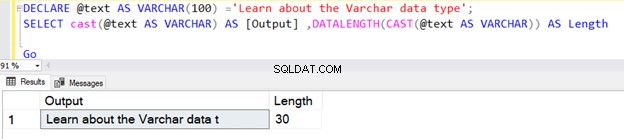
Wenn die Zeichenfolgenlänge jedoch weniger als 30 beträgt, wird die tatsächliche Größe der Zeichenfolge verwendet.

NVARCHAR [ ( n | maximal ) ] in SQL
Der NVARCHAR Datentyp ist für Unicode Datentyp für Zeichen mit variabler Länge. Hier bezieht sich N auf den Zeichensatz der Landessprache und wird verwendet, um die Unicode-Zeichenfolge zu definieren. Sie können sowohl Nicht-Unicode- als auch Unicode-Zeichen (japanisches Kanji, koreanisches Hangul usw.) speichern.
- N stellt die Stringgröße in Bytes dar.
- Es kann maximal 4000 Unicode- und Nicht-Unicode-Zeichen speichern.
- Der Datentyp VARCHAR benötigt 2 Bytes pro Zeichen. Es benötigt 2 Byte Speicherplatz, wenn Sie keinen Wert für N angeben.
Die folgende Abfrage definiert den Datentyp VARCHAR mit 100 Byte Daten.
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Es gibt die Zeichenfolgenlänge von 36 zurück, da NVARCHAR 2 Bytes pro Zeichenspeicher benötigt.
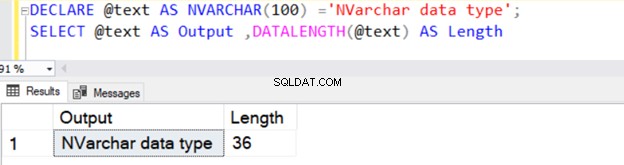
Ähnlich wie der Datentyp VARCHAR hat auch NVARCHAR einen Standardwert von 1 Zeichen (2 Bytes), ohne einen expliziten Wert für N anzugeben.
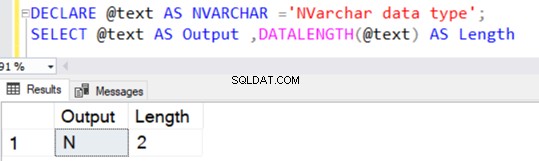
Wenn wir die NVARCHAR-Konvertierung mit der CAST- oder CONVERT-Funktion ohne einen expliziten Wert von N anwenden, beträgt der Standardwert 30 Zeichen, d. h. 60 Bytes.
Speichern der Unicode- und Nicht-Unicode-Werte im VARCHAR-Datentyp
Angenommen, wir haben eine Tabelle, die Kundenfeedback von einem E-Shopping-Portal aufzeichnet. Dazu haben wir eine SQL-Tabelle mit folgender Abfrage.
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
Wir fügen in diese Tabelle mehrere Beispieldatensätze in Englisch, Japanisch und Hindi ein. Der Datentyp für [Kommentar] ist VARCHAR und [NeuerKommentar] ist NVARCHAR() .
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
Die Abfrage wird erfolgreich ausgeführt und gibt die folgenden Zeilen aus, während ein Wert daraus ausgewählt wird. Für die 2. und 3. Zeile werden keine Daten erkannt, wenn sie nicht auf Englisch sind.
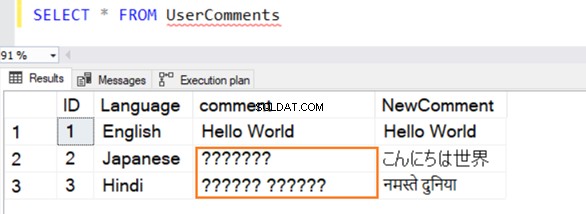
VARCHAR- und NVARCHAR-Datentypen:Leistungsvergleich
Wir sollten die Verwendung von VARCHAR- und NVARCHAR-Datentypen in den JOIN- oder WHERE-Prädikaten nicht mischen. Es macht die vorhandenen Indizes ungültig, da SQL Server dieselben Datentypen auf beiden Seiten von JOIN erfordert. SQL Server versucht, im Falle einer Nichtübereinstimmung die implizite Konvertierung mithilfe der Funktion CONVERT_IMPLICIT() durchzuführen.
SQL Server verwendet die Datentyppriorität, um den Zieldatentyp zu bestimmen. NVARCHAR hat Vorrang vor dem Datentyp VARCHAR. Daher konvertiert SQL Server während der Datentypkonvertierung die vorhandenen VARCHAR-Werte in NVARCHAR.
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
Lassen Sie uns nun zwei SELECT-Anweisungen ausführen, die Datensätze gemäß ihren Datentypen abrufen.
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
Beide Abfragen verwenden den Indexsuchoperator und die Indizes, die wir zuvor definiert haben.
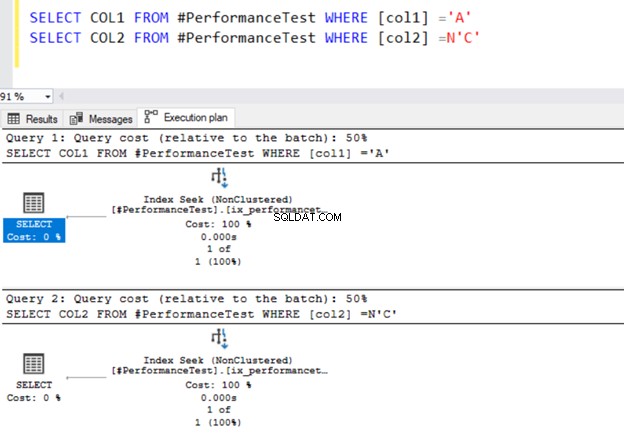
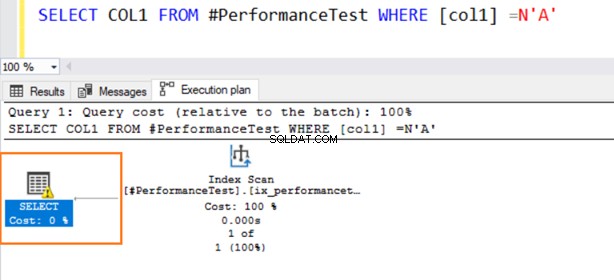
Jetzt schalten wir die Datentypwerte für den Vergleich auf das WHERE-Prädikat um. Spalte 1 hat einen VARCHAR-Datentyp, aber wir geben N’A’ an, um sie als NVARCHAR-Datentyp darzustellen.
In ähnlicher Weise ist col2 der Datentyp NVARCHAR, und wir geben den Wert „C“ an, der sich auf den Datentyp VARCHAR bezieht.
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'Im tatsächlichen Ausführungsplan der Abfrage erhalten Sie einen Indexscan, und die SELECT-Anweisung hat ein Warnsymbol.
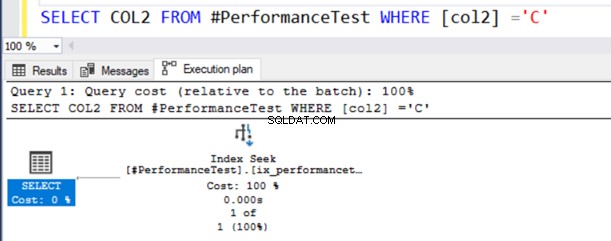
Diese Abfrage funktioniert einwandfrei, da der Datentyp NVARCHAR() sowohl Unicode- als auch Nicht-Unicode-Werte haben kann.
Jetzt verwendet die zweite Abfrage einen Index-Scan und gibt ein Warnsymbol für den SELECT-Operator aus.
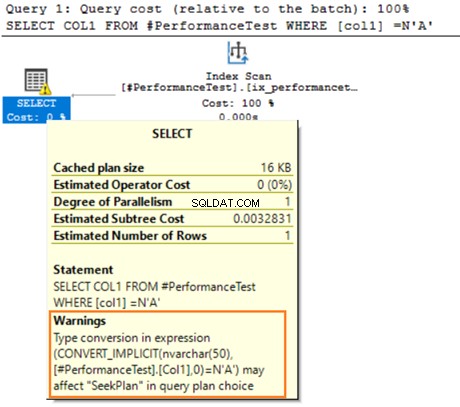
Bewegen Sie die Maus über die SELECT-Anweisung, die eine Warnung über die implizite Konvertierung ausgibt. SQL Server konnte den vorhandenen Index nicht ordnungsgemäß verwenden. Dies liegt an den unterschiedlichen Datensortieralgorithmen für die Datentypen VARCHAR und NVARCHAR.
Wenn die Tabelle Millionen von Zeilen enthält, muss SQL Server zusätzliche Arbeit leisten und Daten mithilfe der impliziten Datenkonvertierung konvertieren. Dies kann sich negativ auf Ihre Abfrageleistung auswirken. Daher sollten Sie diese Datentypen beim Optimieren der Abfragen nicht mischen und abgleichen.
Schlussfolgerung
Sie sollten Ihre Datenanforderungen überprüfen, während Sie Datenbanktabellen und deren Spaltendatentyp entsprechend entwerfen. Normalerweise erfüllt der Datentyp VARCHAR die meisten Ihrer Datenanforderungen. Wenn Sie jedoch sowohl Unicode- als auch Nicht-Unicode-Datentypen in einer Spalte speichern müssen, können Sie die Verwendung von NVARCHAR in Erwägung ziehen. Sie sollten jedoch die Auswirkungen auf die Leistung und die Speichergröße überprüfen, bevor Sie die endgültige Entscheidung treffen.