Die SQL Server-Transaktionsreplikation ist eine der am häufigsten verwendeten Replikationstechniken zum Kopieren oder Verteilen von Daten über mehrere Ziele hinweg.
In den vorherigen Artikeln haben wir die SQL Server-Replikation, ihre interne Funktionsweise und die Konfiguration der Replikation über den Replikations-Assistenten oder den T-SQL-Ansatz besprochen. Jetzt konzentrieren wir uns auf SQL Replication-Probleme und deren korrekte Fehlerbehebung.
SQL-Replikationsprobleme
Die Mehrheit der Kunden, die die SQL Server-Transaktionsreplikation verwenden, konzentriert sich hauptsächlich darauf, Daten nahezu in Echtzeit zu erhalten, die in den Abonnentendatenbankinstanzen verfügbar sind. Daher sollte sich der DBA, der die Replikation verwaltet, über verschiedene mögliche Probleme im Zusammenhang mit der SQL-Replikation im Klaren sein, die auftreten können. Außerdem muss der DBA in der Lage sein, diese Probleme innerhalb kurzer Zeit zu lösen.
Wir können alle SQL Replication-Probleme in die folgenden Kategorien einteilen (basierend auf meiner Erfahrung):
Konfigurationsprobleme
- Maximale Textreplikationsgröße
- SQL Server Agent-Dienst nicht auf Start des automatischen Modus eingestellt
- Nicht überwachte Replikationsinstanzen geraten in einen nicht initialisierten Abonnementstatus
- Bekannte Probleme in SQL Server
Berechtigungsprobleme
- Probleme mit der Auftragsberechtigung für den SQL Server-Agent
- Snapshot-Agent-Job-Anmeldedaten können nicht auf Snapshot-Ordnerpfad zugreifen
- Logreader-Agent-Job-Anmeldedaten können keine Verbindung zur Herausgeber-/Verteilungsdatenbank herstellen
- Anmeldedaten für den Verteilungsagenten-Job können keine Verbindung zur Verteilungs-/Abonnentendatenbank herstellen
Verbindungsprobleme
- Publisher-Server wurde nicht gefunden oder war nicht erreichbar
- Verteilungsserver wurde nicht gefunden oder war nicht erreichbar
- Abonnentenserver wurde nicht gefunden oder war nicht erreichbar
Datenintegritätsprobleme
- Primärschlüssel- oder eindeutige Schlüsselverletzungsfehler
- Fehler "Zeile nicht gefunden"
- Fremdschlüssel- oder andere Einschränkungsverletzungsfehler
Leistungsprobleme
- Aktive Transaktionen mit langer Laufzeit in der Publisher-Datenbank
- Massen-INSERT/UPDATE/DELETE-Operationen für Artikel
- Riesige Datenänderungen innerhalb einer einzigen Transaktion
- Sperrungen in der Verteilungsdatenbank
Korruptionsbezogene Probleme
- Beschädigungen der Publisher-Datenbank
- Korruption der Publisher-Transaktionsprotokolldatei
- Beschädigungen der Verteilungsdatenbank
- Beschädigungen der Abonnentendatenbank
Vorbereitung der DEMO-Umgebung
Bevor wir uns mit Details zu den Problemen mit der SQL-Replikation befassen, müssen wir unsere Umgebung für die Demo vorbereiten. Wie in meinen vorherigen Artikeln besprochen, sind alle Datenänderungen, die in der Abonnentendatenbank in der Transaktionsreplikation vorgenommen werden, nicht direkt für die Herausgeberdatenbank sichtbar. Daher werden wir zu Lernzwecken bestimmte Änderungen direkt in der Abonnentendatenbank vornehmen.
Bitte seien Sie äußerst vorsichtig und ändern Sie nichts in den Produktionsdatenbanken. Dies wirkt sich auf die Datenintegrität der Abonnentendatenbanken aus. Ich nehme die Sicherungsskripts für jede durchgeführte Änderung und verwende diese Skripts, um die Probleme mit der SQL-Replikation zu beheben.
Änderung 1 – Einfügen von Datensätzen in die Person.ContactType-Tabelle
Vor dem Einfügen von Datensätzen in Person.ContacType Tabelle, werfen wir einen Blick auf diese Tabellenstruktur, einige Standardeinschränkungen und erweiterte Eigenschaften, die im folgenden Skript redigiert wurden:
CREATE TABLE [Person].[ContactType](
[ContactTypeID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[Name] [dbo].[Name] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_ContactType_ContactTypeID] PRIMARY KEY CLUSTERED
(
[ContactTypeID] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
Ich habe diese Tabelle gewählt, da sie weniger Spalten hat. Es ist bequemer für Testzwecke. Sehen wir uns nun an, was wir über seine Struktur wissen:
- ContactTypeId ist als IDENTITÄTSSPALTE definiert – sie generiert automatisch die Primärschlüsselwerte und NICHT ZUR REPLIKATION.
- NOT FOR REPLICATION ist eine spezielle Eigenschaft, die für verschiedene Objekttypen wie Tabellen, Einschränkungen wie Foreign Key Constraints, Check Constraints, Triggers und Identity-Spalten auf Verlegern oder Abonnenten verwendet werden kann, während nur eine der Replikationsmethoden verwendet wird. Damit kann der DBA die Replikation planen oder implementieren, um sicherzustellen, dass sich bestimmte Funktionen in Publisher/Subscriber bei der Verwendung der Replikation anders verhalten.
- In unserem Fall weisen wir SQL Server an, die IDENTITY-Werte zu verwenden, die nur in der Publisher-Datenbank generiert wurden. Die IDENTITY-Eigenschaft sollte nicht für Person.ContactType verwendet werden Tabelle in der Abonnentendatenbank. In ähnlicher Weise können wir die Einschränkungen oder Trigger ändern, damit sie sich anders verhalten, während die Replikation mit dieser Option konfiguriert wird.
- 2 weitere NOT NULL-Spalten sind in der Tabelle verfügbar.
- Die Tabelle hat einen Primärschlüssel, der auf ContactTypeId definiert ist . Zur Erinnerung:Der Primärschlüssel ist eine zwingende Voraussetzung für die Replikation. Ohne es auf einem Tisch wären wir nicht in der Lage, einen Tischartikel zu replizieren.
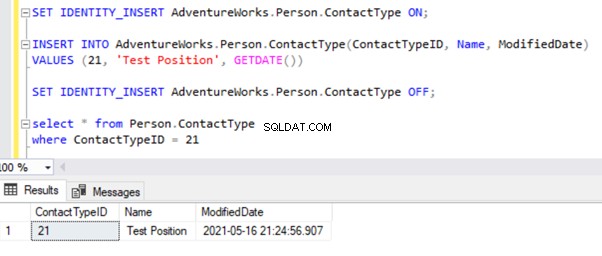
Lassen Sie uns nun einen Beispieldatensatz in Person einfügen .Kontaktart Tabelle in AdventureWorks_REPL Datenbank:
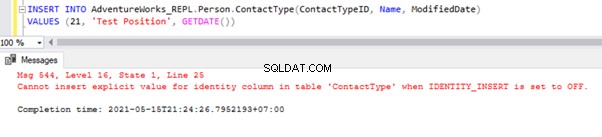
Das direkte INSERT in der Tabelle schlägt in der Abonnentendatenbank fehl, da die Identitätseigenschaft nur für die Replikation deaktiviert ist durch die Option NOT FOR REPLICATION. Wann immer wir die INSERT-Operation manuell ausführen, müssen wir dennoch die SET IDENTITY_INSERT-Option wie folgt verwenden:
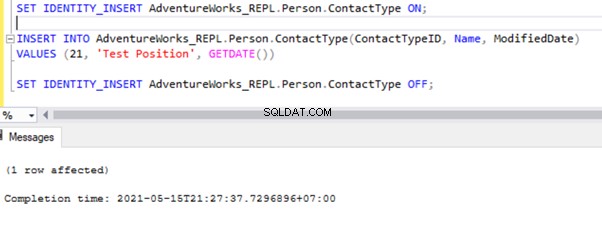
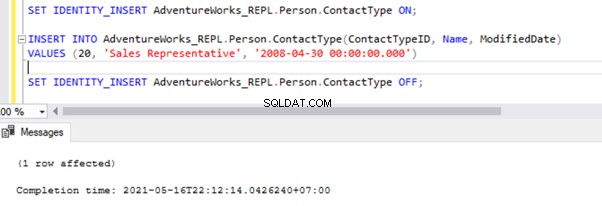
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType ON;
INSERT INTO AdventureWorks_REPL.Person.ContactType(ContactTypeID, Name, ModifiedDate)
VALUES (21, 'Test Position', GETDATE())
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType OFF;
Nach dem Hinzufügen der Option SET IDENTITY_INSERT können wir den Datensatz erfolgreich in Person.ContactType einfügen Tabelle.
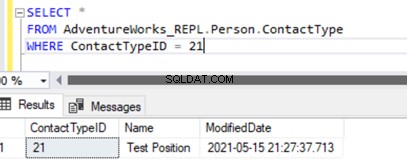
Die Ausführung von SELECT auf der Tabelle zeigt den neu eingefügten Datensatz:
Wir haben nur der Abonnentendatenbank einen neuen Datensatz hinzugefügt, der in der Herausgeberdatenbank für Person.ContactType nicht verfügbar ist Tabelle.
Das Ausführen eines SELECT für dieselbe Tabelle der Publisher-Datenbank zeigt keine Datensätze an. Daher werden an der Abonnentendatenbank vorgenommene Änderungen nicht in die Herausgeberdatenbank repliziert.
Änderung 2 – Löschen von 2 Datensätzen aus der Person.ContactType-Tabelle
Wir bleiben bei unserem bekannten Person.ContactType Tisch. Vor dem Löschen von Datensätzen aus der Abonnentendatenbank müssen wir überprüfen, ob diese Datensätze sowohl für den Herausgeber als auch für den Abonnenten vorhanden sind. Siehe unten:
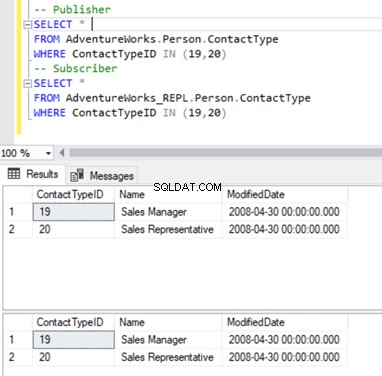
Jetzt können wir diese 2 ContactTypeId löschen mit der folgenden Anweisung:
DELETE FROM AdventureWorks_REPL.Person.ContactType
WHERE ContactTypeID IN (19,20)
Mit dem obigen Skript können wir 2 Datensätze aus Person.ContactType löschen Tabelle in der Abonnentendatenbank:
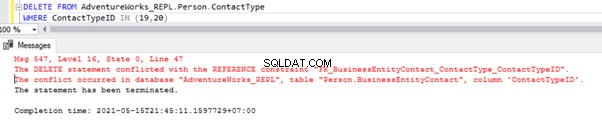
Wir haben die Fremdschlüsselreferenz, die das Löschen dieser 2 Datensätze aus Person.ContactType verhindert Tisch. Wir können dieses Szenario handhaben, indem wir die Fremdschlüsseleinschränkung für die untergeordnete Tabelle vorübergehend deaktivieren. Das Skript ist unten:
ALTER TABLE [Person].[BusinessEntityContact] NOCHECK CONSTRAINT [FK_BusinessEntityContact_ContactType_ContactTypeID];
Sobald die Fremdschlüssel deaktiviert sind, können wir Datensätze erfolgreich aus Person.ContactType löschen Tabelle:
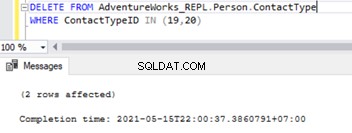
Dadurch wurde auch die referenzielle Einschränkung des Fremdschlüssels für die beiden Tabellen geändert. Wir können versuchen, SQL Replication-Probleme basierend auf diesem Szenario zu simulieren.
In unserem aktuellen Szenario wissen wir, dass Person.ContactType Die Tabelle hatte keine synchronisierten Daten zwischen dem Verleger und dem Abonnenten.
Glauben Sie mir, in wenigen Produktionsumgebungen nehmen Entwickler oder DBAs einige Datenkorrekturen in der Abonnentendatenbank vor. Wie alle zuvor durchgeführten Änderungen verursachten die Datenintegritätsprobleme in der Verleger- und Abonnentendatenbank in derselben Tabelle. Als DBA benötige ich einen einfacheren Mechanismus, um diese Art von Diskrepanzen zu überprüfen. Andernfalls würde es das Leben des Datenbankadministrators erbärmlich machen.
Hier kommt die Lösung von Microsoft, mit der wir die Datenabweichungen zwischen den Tabellen im Verleger und im Abonnenten überprüfen können. Ja, du hast es richtig erraten. Es ist das Dienstprogramm TableDiff, das wir in früheren Artikeln besprochen haben.
TableDiff-Dienstprogramm
Das Dienstprogramm TableDiff wird hauptsächlich in Replikationsumgebungen verwendet. Wir können es auch für andere Fälle verwenden, in denen wir 2 SQL Server-Tabellen auf Nichtkonvergenz vergleichen müssen. Wir können sie vergleichen und die Unterschiede zwischen diesen beiden Tabellen identifizieren. Dann hilft das Dienstprogramm, das Ziel zu synchronisieren Tabelle zur Quelle Tabelle durch Generieren der erforderlichen INSERT/UPDATE/DELETE-Skripte.
TableDiff ist ein eigenständiges Programm tablediff.exe, das standardmäßig unter C:\Programme\Microsoft SQL Server\130\COM installiert wird, nachdem wir die Replikationskomponenten installiert haben. Bitte beachten Sie, dass der Standardpfad je nach SQL Server-Installationsparametern variieren kann. Die Zahl 130 im Pfad gibt die SQL Server-Version (SQL Server 2016) an. Daher wird es für jede andere Version der SQL Server-Installation unterschiedlich sein.
Sie können auf das Dienstprogramm TableDiff nur über die Eingabeaufforderung oder über Batchdateien zugreifen. Das Dienstprogramm verfügt nicht über einen ausgefallenen Assistenten oder eine GUI. Die detaillierte Syntax des TableDiff-Dienstprogramms finden Sie im MSDN-Artikel. Unser aktueller Artikel konzentriert sich nur auf einige notwendige Optionen.
Um 2 Tabellen mit dem Dienstprogramm TableDiff zu vergleichen, müssen wir obligatorische Details für die Quell- und Zieltabellen angeben, z. B. Quellservername, Quelldatenbankname, Quellschemaname, Quelltabellenname, Zielservername, Zieldatenbankname, Ziel Schemaname und Zieltabellenname.
Lassen Sie uns versuchen, TableDiff mit Person.ContactType zu testen Tabelle mit Unterschieden zwischen dem Herausgeber und dem Abonnenten.
Öffnen Sie die Eingabeaufforderung und navigieren Sie zum Pfad des TableDiff-Dienstprogramms (falls dieser Pfad nicht zu den Umgebungsvariablen hinzugefügt wurde).
Um die Liste aller verfügbaren Parameter anzuzeigen, geben Sie den Befehl „tablediff-?“ ein. , um alle verfügbaren Optionen und Parameter aufzulisten. Die Ergebnisse sind unten:
Sehen wir uns die Person.ContactType an Tabelle in unseren Publisher- und Subscriber-Datenbanken, indem Sie den folgenden Befehl ausführen:
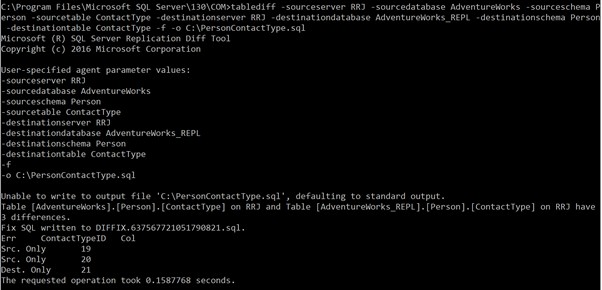
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactTypeBeachten Sie, dass ich den sourceuser nicht angegeben habe , Quellkennwort , Zielbenutzer , und Zielpasswort da meine Windows-Anmeldung Zugriff auf die Tabellen hat. Wenn Sie anstelle der Windows-Authentifizierung SQL-Anmeldeinformationen verwenden möchten, sind die obigen Parameter obligatorisch, um auf die Vergleichstabellen zuzugreifen . Andernfalls erhalten Sie Fehler.
Die Ergebnisse der korrekten Befehlsausführung:
Es zeigt, dass wir 3 Diskrepanzen haben. Einer ist ein neuer Datensatz in der Zieldatenbank und zwei Datensätze sind in der Zieldatenbank nicht verfügbar.
Werfen wir nun einen kurzen Blick auf Verschiedenes Optionen, die für das TableDiff-Dienstprogramm verfügbar sind.
- -et – protokolliert die Ergebniszusammenfassung in der Zieltabelle
- -dt – löscht die Ergebniszieltabelle, falls sie bereits existiert
- -f – Generiert ein T-SQL-DML-Skript mit INSERT/UPDATE/DELETE-Anweisungen, um die Zieltabelle mit der Quelltabelle in Konvergenz zu bringen.
- -o – Dateinamen ausgeben, wenn Option -f wird verwendet, um die Konvergenzdatei zu generieren.
Wir erstellen eine Konvergenzdatei mit dem -f und -o Optionen zu unserem früheren Befehl:
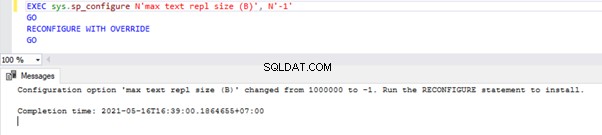
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactType -f -o C:\PersonContactType.sqlDie Konvergenzdatei wurde erfolgreich erstellt:
Wie Sie sehen können, ist das Erstellen einer neuen Datei im Stammverzeichnis des Laufwerks C:aus Sicherheitsgründen nicht erlaubt. Daher zeigt es eine Fehlermeldung an und erstellt die Ausgabedatei DIFFIX.*.sql-Datei im Dienstprogrammordner TableDiff. Wenn wir diese Datei öffnen, können wir die folgenden Details sehen:

Die INSERT-Skripts wurden für die beiden gelöschten Datensätze erstellt, und die DELETE-Skripts wurden für die neu in die Abonnentendatenbank eingefügten Datensätze erstellt. Das Tool kümmert sich auch um die Verwendung der IDENTITY_INSERT-Optionen, die für das Ziel erforderlich sind Tisch. Daher ist dieses Tool immer dann von großem Nutzen, wenn ein DBA zwei Tabellen synchronisieren muss.
In unserem Fall werde ich die Skripte nicht ausführen, da wir diese Abweichungen benötigen, um unsere SQL-Replikationsprobleme zu simulieren.
Vorteile des TableDiff-Dienstprogramms
- TableDiff ist ein kostenloses Dienstprogramm, das Teil der Installation der SQL Server Replication-Komponenten ist und für den Tabellenvergleich oder die Konvergenz verwendet werden kann.
- Die Konvergenzerstellungsskripte können ohne manuellen Eingriff erstellt werden.
Einschränkungen des TableDiff-Dienstprogramms
- Das Dienstprogramm TableDiff kann nur von der Eingabeaufforderung oder der Stapeldatei ausgeführt werden.
- Von der Eingabeaufforderung aus können Sie jeweils nur einen Tabellenvergleich durchführen, es sei denn, Sie haben mehrere Eingabeaufforderungen parallel geöffnet, um mehrere Tabellen zu vergleichen.
- Für die Quelltabelle, die Sie mit dem Dienstprogramm TableDiff vergleichen müssen, ist entweder ein Primärschlüssel oder eine definierte Identitätsspalte oder die ROWGUID-Spalte erforderlich, um den zeilenweisen Vergleich durchzuführen. Wenn das -strenge Option verwendet wird, erfordert die Zieltabelle auch einen Primärschlüssel oder eine Identitätsspalte oder die ROWGUID-Spalte verfügbar.
- Wenn die Quell- oder Zieltabelle die sql_variant enthält datatype-Spalte, können Sie das Dienstprogramm TableDiff nicht verwenden, um sie zu vergleichen.
- Leistungsprobleme können beim Ausführen des TableDiff-Dienstprogramms für Tabellen mit großen Datensätzen festgestellt werden, da es den zeilenweisen Vergleich für diese Tabellen durchführt.
- Konvergenzskripts, die vom TableDiff-Dienstprogramm erstellt wurden, enthalten keine Spalten des BLOB-Zeichendatentyps, wie z. B. varchar(max) , nvarchar(max) , varbinary(max) , Text , ntext , oder Bild Spalten und xml oder Zeitstempel Säulen. Daher benötigen Sie alternative Ansätze, um die Tabellen mit diesen Datentypspalten zu handhaben.
Aber auch mit diesen Einschränkungen kann das Dienstprogramm TableDiff für eine schnelle Datenüberprüfung oder Konvergenzprüfung für alle SQL Server-Tabellen verwendet werden. Sie können jedoch auch ein gutes Drittanbieter-Tool erwerben.
Betrachten wir nun die verschiedenen Probleme der SQL-Replikation im Detail.
Konfigurationsprobleme
Aus meiner Erfahrung heraus habe ich die häufig übersehenen Replikationskonfigurationsoptionen kategorisiert, die zu kritischen SQL-Replikationsproblemen führen können als Konfiguration Probleme. Einige davon sind unten aufgeführt.
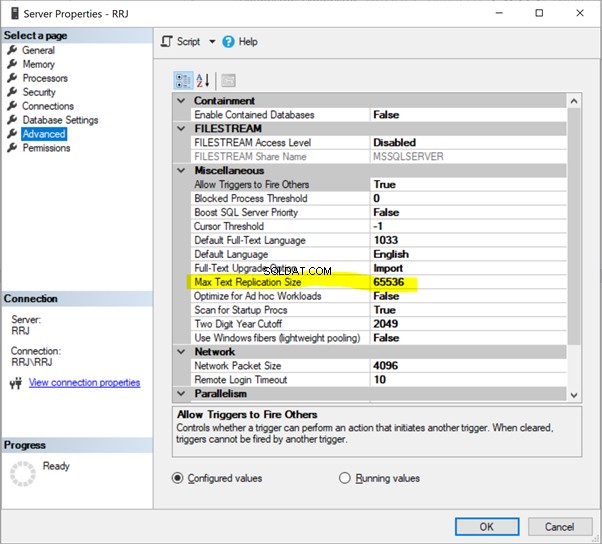
Maximale Textreplikationsgröße
Max. Textersetzungsgröße bezieht sich auf die Maximale Textreplikationsgröße in Bytes . Es gilt für alle Datentypen wie char(max), nvarchar(max), varbinary(max), text, ntext, varbinary, xml, undBild .
SQL Server verfügt über eine Standardoption zum Begrenzen der maximalen Spaltenlänge des Zeichenfolgendatentyps (in Byte), die auf 65536 repliziert werden soll Bytes.
Wir müssen die Max Text Repl Size sorgfältig auswerten, wenn die Replikation für eine Datenbank konfiguriert wird. Dazu müssen wir alle oben genannten Datentypspalten überprüfen und die maximal möglichen Bytes identifizieren, die über die Replikation übertragen werden.
Wenn Sie den Wert auf -1 ändern, bedeutet dies, dass es keine Begrenzungen gibt. Wir empfehlen jedoch, die maximale Zeichenfolgenlänge auszuwerten und diesen Wert zu konfigurieren.
Wir können Max Text Repl Size mit SSMS oder T-SQL konfigurieren.
Klicken Sie in SSMS mit der rechten Maustaste auf den Servernamen> Eigenschaften > Erweitert :
Klicken Sie einfach auf 65536 um es zu ändern. Für Tests habe ich 65536 in 1000000 geändert und auf OK geklickt :
Öffnen Sie zum Konfigurieren der Option Max Text Repl Size über T-SQL ein neues Abfragefenster und führen Sie das folgende Skript für die Master-Datenbank aus:
EXEC sys.sp_configure N'max text repl size (B)', N'-1'
GO
RECONFIGURE WITH OVERRIDE
GO
Diese Abfrage ermöglicht es der Replikation, die Größe der obigen Datentypspalten nicht einzuschränken.
Zur Überprüfung können wir ein SELECT auf sys.configurations durchführen DMV und überprüfen Sie den value_in_use Spalte wie folgt:

SQL Server Agent-Dienst nicht auf Start des automatischen Modus eingestellt
Die Replikation basiert auf Replication Agents, die als SQL Server Agent-Jobs ausgeführt werden. Daher wirkt sich jedes Problem mit einigen SQL Server Agent-Diensten direkt auf die Replikationsfunktionalität aus.
Wir müssen sicherstellen, dass der Startmodus von SQL Server und SQL Server Agent Services auf Automatisch eingestellt ist. Wenn es auf Manuell eingestellt ist, sollten wir einige Warnungen konfigurieren. Sie würden den DBA oder die Serveradministratoren benachrichtigen, den SQL Server Agent-Dienst zu starten, wenn der Server geplante oder ungeplante Neustarts durchführt.
Andernfalls wird die Replikation möglicherweise längere Zeit nicht ausgeführt, was sich auch auf andere Jobs des SQL Server-Agenten auswirkt.
Nicht überwachte Replikationsinstanzen geraten in einen nicht initialisierten Abonnementstatus
Ähnlich wie bei der Überwachung des SQL Server Agent-Dienstes spielt die Konfiguration des Datenbank-E-Mail-Dienstes in einer beliebigen SQL Server-Instanz eine wichtige Rolle bei der rechtzeitigen Benachrichtigung des DBA oder der konfigurierten Person. Bei Jobfehlern oder -problemen können SQL Server-Agent-Jobs wie Log Reader Agent oder Distribution Agent so konfiguriert werden, dass Warnungen per E-Mail an DBA oder das entsprechende Teammitglied gesendet werden. Der Fehler bei der Auftragsausführung des Replikations-Agents kann zu den folgenden Szenarien führen:
Nichtausführung des Protokolllese-Agent-Jobs . Die Transaktionsprotokolldatei der Publisher-Datenbank wird erst nach dem Befehl Marked for Replication wiederverwendet wird vom Protokollleseagenten gelesen und erfolgreich an die Verteilungsdatenbank gesendet. Andernfalls wird die Datei log_reuse_wait_desc Spalte von sys.databases zeigt den Wert als Replikation an, was darauf hinweist, dass das Datenbankprotokoll nicht wiederverwendet werden kann, bis es erfolgreich Änderungen an die Verteilungsdatenbank übertragen hat. Daher wird die Nichtausführung des Protokollleseagenten die Größe der Transaktionsprotokolldatei der Herausgeberdatenbank weiter erhöhen, und wir werden Leistungsprobleme während der vollständigen Sicherung oder Speicherplatzprobleme auf der Herausgeberdatenbankinstanz feststellen.
Nichtausführung des Verteilungsagentenjobs. Der Verteilungs-Agent-Auftrag liest die Daten aus der Verteilungsdatenbank und sendet sie an die Abonnentendatenbank. Dann markiert es diese Datensätze zum Löschen in der Verteilungsdatenbank. Wenn der Verteilungs-Agent-Auftrag nicht ausgeführt wird, erhöht er die Größe der Verteilungsdatenbank, was zu Leistungsproblemen bei der Gesamtreplikationsleistung führt. Standardmäßig ist die Verteilungsdatenbank so konfiguriert, dass Datensätze maximal 0-72 Stunden aufbewahrt werden, wie in der Eigenschaft „Transaktionsaufbewahrung“ unten gezeigt. Wenn die Replikation länger als 72 Stunden fehlschlägt, wird das entsprechende Abonnement als nicht initialisiert markiert, was uns dazu zwingt, entweder das Abonnement neu zu konfigurieren oder einen neuen Snapshot zu erstellen, damit die Replikation wieder funktioniert.
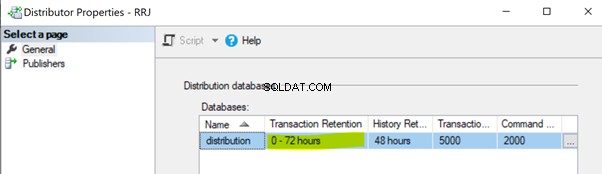
Nichtausführung der Verteilungsbereinigung:Verteilungsjob . Der Bereinigungsauftrag der Verteilung ist für das Löschen aller replizierten Datensätze aus der Verteilungsdatenbank verantwortlich, um die Größe der Verteilungsdatenbank unter Kontrolle zu halten. Die Nichtausführung dieses Auftrags führt zu einer erhöhten Größe der Verteilungsdatenbank, was zu Leistungsproblemen bei der Replikation führt.
Um sicherzustellen, dass wir nicht auf eines dieser nicht überwachten Probleme stoßen, sollte die Datenbank-E-Mail so konfiguriert werden, dass alle Jobfehler oder Wiederholungsversuche an die entsprechenden Teammitglieder gemeldet werden, damit sie umgehend reagieren können.
Bekannte Probleme in SQL Server
Bestimmte SQL Server-Versionen hatten bekannte Replikationsprobleme in der RTM-Version oder früheren Versionen. Diese Probleme wurden in den nachfolgenden Service Packs oder CU-Packs behoben. Daher wird empfohlen, die neuesten Service Packs oder CU-Packs anzuwenden, sobald sie für alle SQL Server verfügbar sind, nachdem Sie sie in der QA-Umgebung getestet haben. Obwohl dies eine allgemeine Empfehlung für Server ist, auf denen SQL Server ausgeführt wird, gilt sie auch für die Replikation.
Berechtigungsprobleme
In einer Umgebung mit konfigurierter SQL Server-Transaktionsreplikation können wir die Berechtigungsprobleme häufig beobachten. Wir können ihnen während der Zeit der Replikationskonfiguration oder Wartungsaktivitäten auf den Datenbankinstanzen des Herausgebers oder Verteilers oder des Abonnenten begegnen. Dies führt zu verlorenen Anmeldeinformationen oder Berechtigungen. Betrachten wir nun einige häufige Berechtigungsprobleme im Zusammenhang mit der Replikation.
Probleme mit der Auftragsberechtigung des SQL Server-Agenten
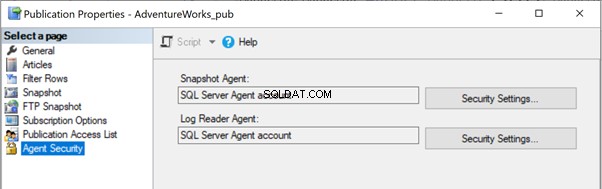
Alle Replikations-Agents verwenden SQL Server-Agent-Jobs. Jeder SQL Server-Agent-Auftrag, der sich auf den Snapshot oder den Protokolllese-Agent oder die Verteilung bezieht, wird unter bestimmten Windows- oder SQL-Anmeldeinformationen ausgeführt, wie unten gezeigt:
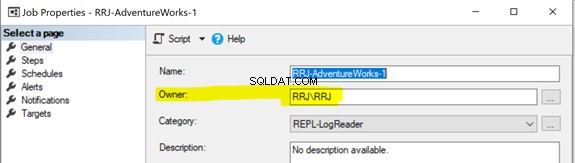
Um einen SQL Server Agent-Job zu starten, müssen Sie entweder die SQLAgentOperatorRole besitzen zum Starten aller Jobs oder entweder SQLAgentUserRole oder die SQLAgentReaderRole Jobs zu starten, die Sie besitzen. Wenn ein Job nicht ordnungsgemäß gestartet werden konnte, überprüfen Sie, ob der Jobbesitzer die erforderlichen Rechte hat, um diesen Job auszuführen.
Snapshot-Agent-Job-Anmeldedaten können nicht auf Snapshot-Ordnerpfad zugreifen
In unseren vorherigen Artikeln haben wir festgestellt, dass die Snapshot-Agent-Ausführung den Snapshot der Artikel entweder im lokalen oder freigegebenen Ordnerpfad erstellen würde, um ihn über den Verteilungs-Agent an die Abonnentendatenbank weiterzugeben. Der Speicherort des Snapshot-Pfads kann unter den Veröffentlichungseigenschaften identifiziert werden > Schnappschuss :
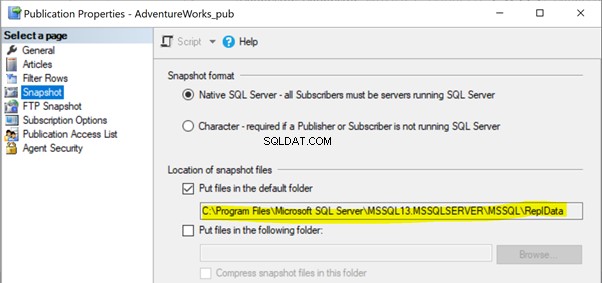
Wenn der Snapshot-Agent keinen Zugriff auf diesen Speicherort der Snapshot-Dateien hat, erhalten wir möglicherweise die folgende Fehlermeldung:
Der Zugriff auf den Pfad „C:\Programme\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\XXXX\YYYYMMDDHHMISS\“ wird verweigert.
Um das Problem zu beheben, ist es besser, vollständigen Zugriff auf den Ordnerpfad C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\ zu gewähren für das Konto, unter dem der Snapshot-Agent ausgeführt wird. In unserer Konfiguration verwenden wir das SQL Server Agent-Konto, und der SQL Server Agent-Dienst wird unter dem RRJ\RRJ-Konto ausgeführt.
Die Anmeldedaten des Protokollleseagenten-Jobs können keine Verbindung zur Herausgeber-/Verteilungsdatenbank herstellen
Der Protokollleseagent stellt eine Verbindung zur Herausgeberdatenbank her, um sp_replcmds auszuführen Verfahren, um nach Transaktionen zu suchen, die für die Replikation aus den Transaktionsprotokollen der Publisher-Datenbank markiert sind.
Wenn der Datenbankeigentümer der Publisher-Datenbank nicht richtig eingestellt ist, erhalten wir möglicherweise die folgenden Fehler:
Der Prozess konnte „sp_replcmds“ auf „RRJ“ nicht ausführen.
Oder
Kann nicht als Datenbankprinzipal ausgeführt werden, da der Prinzipal „dbo“ nicht vorhanden ist, dieser Prinzipaltyp nicht imitiert werden kann oder Sie keine Berechtigung haben.
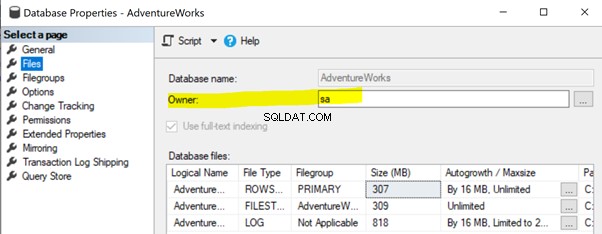
Um dieses Problem zu beheben, stellen Sie sicher, dass die Datenbankbesitzereigenschaft der Herausgeberdatenbank auf sa gesetzt ist oder ein anderes gültiges Konto (siehe unten).
Klicken Sie mit der rechten Maustaste auf den Publisher Datenbank (AdventureWorks )> Eigenschaften > Dateien . Stellen Sie sicher, dass der Inhaber Feld ist auf sa gesetzt oder ein beliebiges gültiges Login und nicht leer .
Wenn beim Herstellen einer Verbindung mit dem Herausgeber oder der Verteilungsdatenbank Berechtigungsprobleme auftreten, überprüfen Sie die Anmeldeinformationen, die für den Protokollleseagenten verwendet werden, und erteilen Sie ihnen Berechtigungen für den Zugriff auf diese Datenbanken.
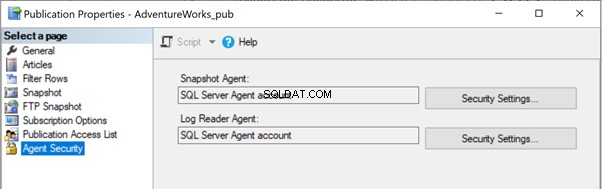
Die Auftragsanmeldeinformationen des Verteilungsagenten können keine Verbindung zur Verteilungs-/Abonnentendatenbank herstellen
Der Verteilungs-Agent hat möglicherweise Berechtigungsprobleme, wenn das Konto nicht auf die Verteilungsdatenbank zugreifen oder eine Verbindung mit der Abonnentendatenbank herstellen darf. In diesem Fall erhalten wir möglicherweise die folgenden Fehler:
Die Ausführung von Schritt 2 kann nicht gestartet werden (Grund:Fehler beim Authentifizieren von Proxy RRJ\RRJ, Systemfehler:Der Benutzername oder das Passwort ist falsch.)
Der Prozess konnte keine Verbindung zum Abonnenten „RRJ.“ herstellen.
Anmeldung für Benutzer „RRJ\RRJ“ fehlgeschlagen.
Um dies zu beheben, überprüfen Sie das verwendete Konto in den Abonnementeigenschaften und stellen Sie sicher, dass es über die erforderlichen Berechtigungen zum Herstellen einer Verbindung mit der Verteilungs- oder Abonnentendatenbank verfügt.
Verbindungsprobleme
Wir konfigurieren die Transaktionsreplikation normalerweise über Server innerhalb desselben Netzwerks oder über geografisch verteilte Standorte hinweg. Wenn sich die Verteilungsdatenbank auf einem dedizierten Server neben dem Herausgeber oder Abonnenten befindet, wird sie anfällig für Netzwerkpaketverluste – Verbindungsprobleme.
Im Falle solcher Probleme können Replikationsagenten (Protokolllese- oder Verteilungsagent) die folgenden Fehler melden:
Publisher-Server wurde nicht gefunden oder war nicht erreichbar
Verteilungsserver wurde nicht gefunden oder war nicht erreichbar
Abonnentenserver wurde nicht gefunden oder war nicht erreichbar
Um diese Probleme zu beheben, versuchen wir möglicherweise, eine Verbindung zur Herausgeber-, Verteiler- oder Abonnentendatenbank in SSMS herzustellen, um zu prüfen, ob wir ohne Probleme eine Verbindung zu diesen SQL Server-Instanzen herstellen können.
Wenn häufig Verbindungsprobleme auftreten, können wir versuchen, den Server kontinuierlich zu pingen, um Paketverluste zu identifizieren. Außerdem müssen wir mit den erforderlichen Teammitgliedern zusammenarbeiten, um diese Probleme zu lösen und den Server zum Laufen zu bringen, damit die Replikation die Datenübertragung fortsetzen kann.
Datenintegritätsprobleme
Da die Transaktionsreplikation ein unidirektionaler Mechanismus ist, werden alle Datenänderungen, die auf dem Abonnenten (manuell oder von der Anwendung) vorgenommen werden, nicht auf dem Verleger widergespiegelt. Dies kann zu Datenabweichungen zwischen dem Herausgeber und dem Abonnenten führen.
Lassen Sie uns diese Probleme im Zusammenhang mit der Datenintegrität überprüfen und sehen, wie sie gelöst werden können. Beachten Sie, dass wir einen Datensatz in Person.ContactType eingefügt haben Tabelle und löschte 2 Datensätze aus Person.ContactType Tabelle in der Abonnentendatenbank. Wir werden diese 3 Datensätze verwenden, um Fehler zu finden.
Die Primärschlüssel- oder eindeutigen Schlüsselverletzungsfehler
Ich werde den INSERT-Eintrag auf Person.ContactType testen Tisch. Lassen Sie uns diesen Datensatz in die Publisher-Datenbank einfügen und sehen, was passiert:
Starten Sie den Replikationsmonitor, um zu sehen, wie es läuft. Wir erhalten den Fehler:
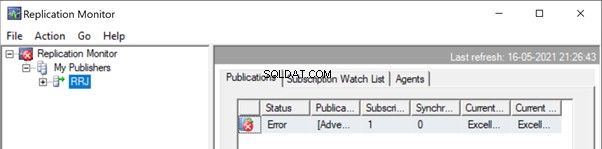
Erweitern von Publisher und Veröffentlichung , erhalten wir die folgenden Details:
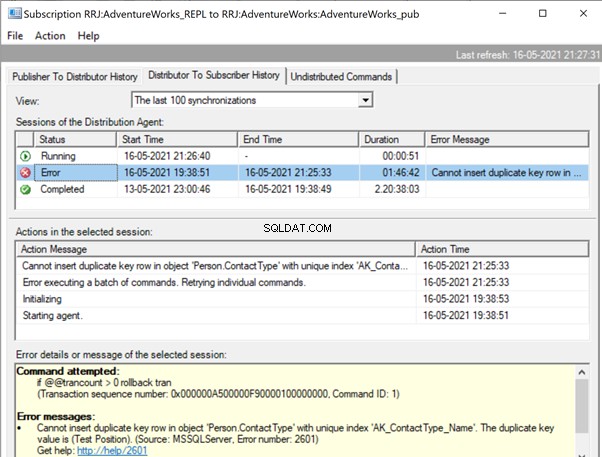
Wenn wir die Replikationswarnungen konfiguriert und entsprechende Personen zugewiesen haben, um ihre E-Mail-Benachrichtigung zu erhalten, erhalten wir entsprechende E-Mail-Benachrichtigungen mit der Fehlermeldung:Kann keine doppelte Schlüsselzeile in Objekt „Person.ContactType“ mit eindeutigem Index „AK_ContactType_Name“ einfügen ' . Der doppelte Schlüsselwert ist (Testposition). (Quelle:MSSQLServer, Fehlernummer:2601)
Um das Problem mit Verletzungen des eindeutigen Schlüssels oder Primärschlüsselproblemen zu lösen, haben wir mehrere Möglichkeiten:
- Analysieren Sie, warum dieser Fehler aufgetreten ist, wie der Datensatz in der Abonnentendatenbank verfügbar war und wer ihn aus welchen Gründen eingefügt hat. Stellen Sie fest, ob es notwendig war oder nicht.
- Fügen Sie die Skiperrors hinzu -Parameter an das Verteilungs-Agent-Profil an, um Fehlernummer 2601 zu überspringen oder Fehlernummer 2627 im Falle einer Verletzung des Primärschlüssels.
In unserem Fall haben wir absichtlich Daten eingefügt, um diesen Fehler zu erhalten. Um dieses Problem zu beheben, löschen Sie diesen manuell eingefügten Datensatz, um die Replikation der vom Herausgeber empfangenen Änderungen fortzusetzen.
DELETE from Person.ContactType
where ContactTypeID = 21
Um andere Optionen zu untersuchen und die Unterschiede zwischen diesen beiden Ansätzen zu vergleichen, überspringe ich die erste Option (die effizient und empfehlenswert ist) und fahre mit der zweiten Option fort, indem ich die -skiperrors hinzufüge -Parameter an den Verteilungs-Agent-Job.
Wir können es implementieren, indem wir den Distribution Agent Job bearbeiten > Schritte > klicken Sie auf 2 Auftragsschritt mit dem Namen Agent ausführen > klicken Sie auf Bearbeiten um den verfügbaren Befehl anzuzeigen:
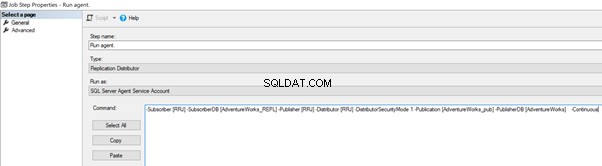
Fügen Sie nun -SkipErrors 2601 hinzu Schlüsselwort am Ende (2601 ist die Fehlernummer – wir können jede im Rahmen der Replikation empfangene Fehlernummer überspringen) und klicken Sie auf OK .
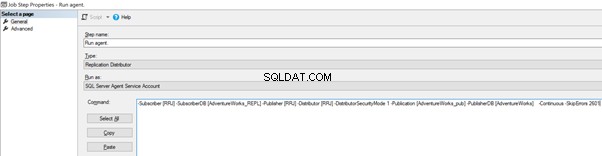
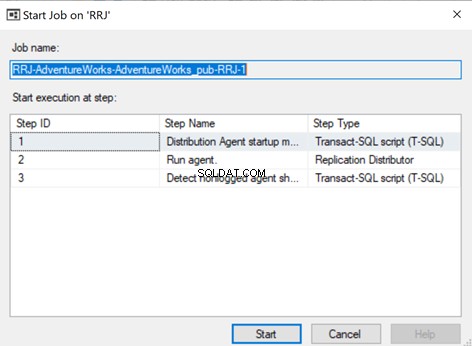
To make sure that the Distribution job is aware of this configuration change, we need to restart the Distribution agent job. For that, stop it and start again from Step 1 as shown below:
The Replication Monitor displays that one of the error records is skipped from the Replication, that started working fine.
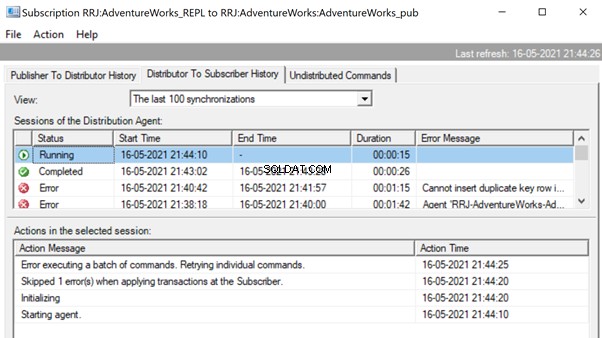
Since the Replication issue is resolved successfully, we’d recommend removing the -SkipErrors parameter from the Distribution Agent job. Then, restart the job to get the changes reflected.
Thus, we’ve fixed the replication issue, but let’s compare the data across the same Person.ContactType in the Publisher and Subscriber databases. The results show the data variance, or the data integrity issue :
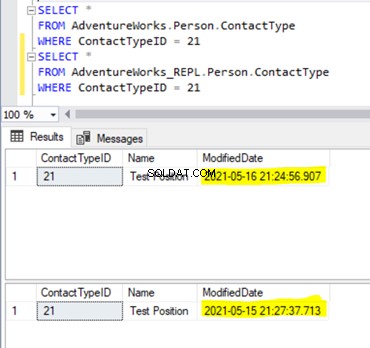
ModifiedDate is different across the Publisher and Subscriber databases. It happens because the data in the Subscriber database was inserted earlier (when we were preparing the test data), and the data in the Publisher database has just been inserted.
If we deleted the record from the Subscriber database, the record from the Publisher would have been inserted to match the data across the Publisher and the Subscriber databases.
Most of the newbie DBAs simply add the -SkipErrors option to get the replication working immediately without detailed investigations of the issue. Hence, it is recommended not to use the -SkipErrors option as a primary solution without proper examination of the problem. The Person.ContactType table had only 3 columns. Assume that the table has over 20 columns. Then, we have just screwed up the Data integrity of this table with that -SkipErrors Befehl.
We used this approach just to illustrate the usage of that option. The best way is to examine and clarify the reason for variance and then perform the appropriate DELETE statements on the Subscriber database to maintain the Data Integrity across the Publisher and Subscriber databases.
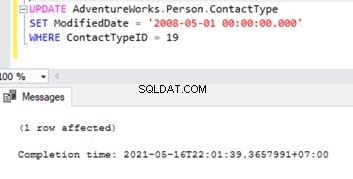
Row Not Found Errors
Let’s try to perform an UPDATE on one of the records that were deleted from the Subscriber database:
Let’s check the Replication Monitor to see the performance. We have the following error:
The row was not found at the Subscriber when applying the replicated UPDATE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =19 (Source:MSSQLServer, Error number:20598).
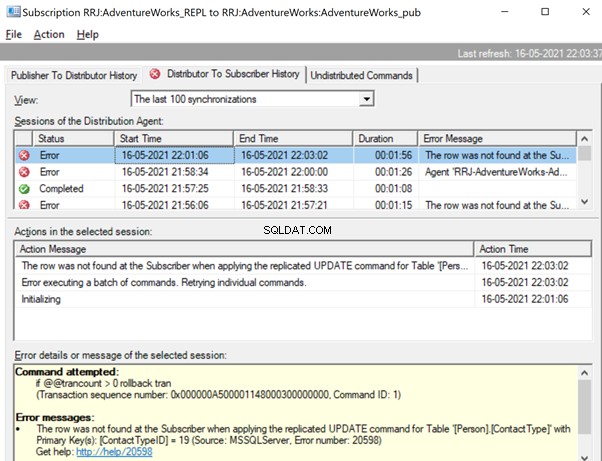
There are two ways to resolve this error. First, we can use -SkipErrors for Error Number 20598 . Or, we can INSERT the record with ContactTypeID =19 (shown in the error message) to get the data changes reflected.
If we skip this error, we’ll lose the record with ContactTypeId =19 from the Subscriber database permanently. It can cause data inconsistency issues. Hence, we aren’t going to use the -SkipErrors Möglichkeit. Instead, we’ll apply the INSERT approach.
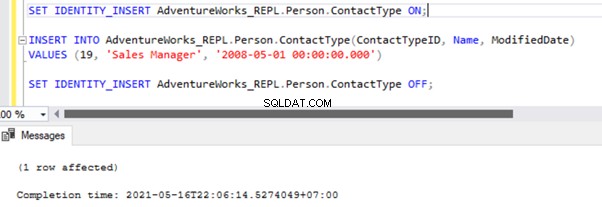
The Replication resumes correctly by sending the UPDATE to the Subscriber database.
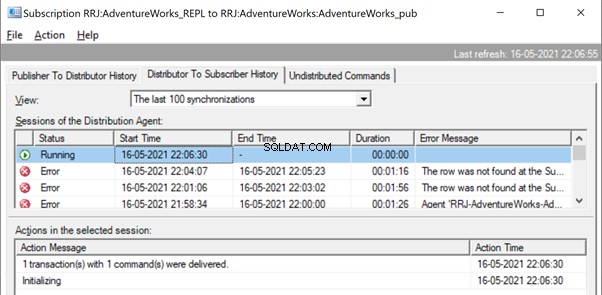
It is the same when we try to delete the ContactTypeId =20 from the Publisher database and see the error popping up in the Replication Monitor.
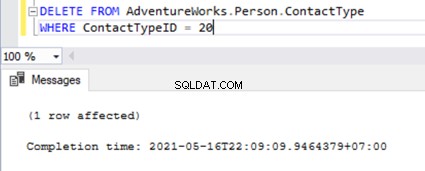
The Replication Monitor shows us a message similar to the one we already noticed:
The row was not found at the Subscriber when applying the replicated DELETE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =20 (Source:MSSQLServer, Error number:20598)
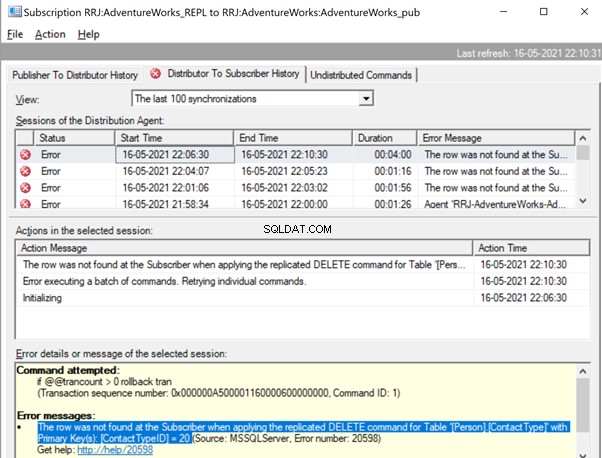
Similar to the previous error, we need to identify the missing record and insert it back to the Subscriber database for the DELETE statement to get replicated properly. For DELETE scenario, using -SkipErrors doesn’t have any issues but can’t be considered as a safe option, as both missing UPDATE or missing DELETE record are captured with the same error number 20598 and adding -SkipErrors 20598 will skip applying all records from the Subscriber database.
We can also get more details about the problematic command by using the sp_browsereplcmds stored procedure which we have discussed earlier as well. Let’s try to use sp_browsereplcmds stored procedure for the previous error we have received out as shown below.

exec sp_browsereplcmds @xact_seqno_start = '0x000000A500001160000600000000'
, @xact_seqno_end = '0x000000A500001160000600000000'
, @publisher_database_id = 1
, @command_id = 1
@xact_seqno_start and @xact_seqno_end will be the same value. We can fetch that value from the Transaction Sequence number in the Replication Monitor along with Command ID.
@publisher_database_id can be fetched from the id column of the distribution..MSPublisher_databases DMV.
select * from MSpublisher_databases Foreign Key or Other Constraint Violation Errors
The error messages related to Foreign keys or any other data issues are slightly different. Microsoft has made these error messages detailed and self-explanatory for anyone to understand what the issue is about.
To identify the exact command that was executed on the Publisher and resolve it efficiently, we can use the sp_browsereplcmds procedure explained above and identify the root cause of the issue.
Once the commands are identified as INSERT/UPDATE/DELETE which caused the errors, we can take corresponding actions to resolve the problems correctly which is more efficient compared to simply adding -SkipErrors approach. Once corrective measures are taken, Replication will start resuming fine immediately.
Word of Caution Using -SkipErrors Option
Those who are comfortable using -SkipErrors option to resolve error quickly should remember that -SkipErrors option is added at the Distribution agent level and applies to all Published articles in that Publication. Command -SkipErrors will result in skipping any number of commands related to that particular error across all published articles any number of times resulting in discrepancies we have seen in demo resulting in data discrepancies across Publisher and Subscriber without knowing how many tables are having discrepancies and would require efforts to compare the tables and fix it out.
Schlussfolgerung
Thanks for going through another robust article. I hope it was helpful for you to understand the SQL Server Transactional Replication issues and methods of troubleshooting them. In our next article, we’ll continue the discussion about the SQL Transaction Replication issues, examine other types, such as Corruption-related issues, and learn the best methods of handling them.