Einführung
Kürzlich sind wir auf ein interessantes Leistungsproblem bei einer unserer SQL Server-Datenbanken gestoßen, die Transaktionen mit hoher Geschwindigkeit verarbeiten. Die Transaktionstabelle, die zum Erfassen dieser Transaktionen verwendet wurde, wurde zu einer heißen Tabelle. Als Ergebnis zeigte sich das Problem in der Anwendungsschicht. Es war eine zeitweilige Zeitüberschreitung der Sitzung, bei der versucht wurde, Transaktionen zu buchen.
Dies geschah, weil eine Sitzung normalerweise an der Tabelle „festhielt“ und eine Reihe von falschen Sperren in der Datenbank verursachte.
Die erste Reaktion eines typischen Datenbankadministrators wäre, die primär blockierende Sitzung zu identifizieren und sie sicher zu beenden. Dies war sicher, da es sich normalerweise um eine SELECT-Anweisung oder eine Leerlaufsitzung handelte.
Es gab auch andere Versuche, das Problem zu lösen:
- Räumen der Tabelle. Dies sollte eine gute Leistung erbringen, selbst wenn die Abfrage eine vollständige Tabelle scannen musste.
- Aktivieren der Isolationsstufe READ COMMITTED SNAPSHOT, um die Auswirkungen der Blockierung von Sitzungen zu reduzieren.
In diesem Artikel werden wir versuchen, eine vereinfachte Version des Szenarios nachzubilden und es zu verwenden, um zu zeigen, wie eine einfache Indizierung Situationen wie diese bewältigen kann, wenn sie richtig gemacht wird.
Zwei verknüpfte Tabellen
Sehen Sie sich Listing 1 und Listing 2 an. Sie zeigen die vereinfachten Versionen von Tabellen, die in dem betrachteten Szenario enthalten sind.
-- Listing 1: Create TranLog Table
use DB2
go
create table TranLog (
TranID INT IDENTITY(1,1)
,CustomerID char(4)
,ProductCount INT
,TotalPrice Money
,TranTime Timestamp
)
-- Listing 2: Create TranDetails Table
use DB2
go
create table TranDetails (
TranDetailsID INT IDENTITY(1,1)
,TranID INT
,ProductCode uniqueidentifier
,UnitCost Money
,ProductCount INT
,TotalPrice Money
)
Listing 3 zeigt einen Trigger, der vier Zeilen in die TranDetails einfügt Tabelle für jede in das TranLog eingefügte Zeile Tabelle.
-- Listing 3: Create Trigger
CREATE TRIGGER dbo.GenerateDetails
ON dbo.TranLog
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
END
GO
Join-Abfrage
Es ist typisch, Transaktionstabellen zu finden, die von großen Tabellen unterstützt werden. Der Zweck besteht darin, viel ältere Transaktionen aufzubewahren oder die Details von Datensätzen zu speichern, die in der ersten Tabelle zusammengefasst sind. Betrachten Sie dies als Befehle und Bestelldetails Tabellen, die in SQL Server-Beispieldatenbanken typisch sind. In unserem Fall betrachten wir das TranLog und TranDetails Tabellen.
Unter normalen Umständen füllen Transaktionen diese beiden Tabellen im Laufe der Zeit. In Bezug auf die Berichterstellung oder einfache Abfragen führt die Abfrage eine Verknüpfung dieser beiden Tabellen durch. Dieser Join nutzt eine gemeinsame Spalte zwischen den Tabellen.
Zuerst füllen wir die Tabelle mit der Abfrage in Listing 4.
-- Listing 4: Insert Rows in TranLog
use DB2
go
insert into TranLog values ('CU01', 5, '50.45', DEFAULT);
insert into TranLog values ('CU02', 7, '42.35', DEFAULT);
insert into TranLog values ('CU03', 15, '39.55', DEFAULT);
insert into TranLog values ('CU04', 9, '33.50', DEFAULT);
insert into TranLog values ('CU05', 2, '105.45', DEFAULT);
go 1000
use DB2
go
select * from TranLog;
select * from TranDetails;
In unserem Beispiel ist die gemeinsame Spalte, die vom Join verwendet wird, die TranID Spalte:
-- Listing 5 Join Query
-- 5a
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.CustomerID='CU03';
-- 5b
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.TranID=30;
Sie können die beiden einfachen Beispielabfragen sehen, die einen Join verwenden, um Datensätze aus TranLog abzurufen und TranDetails .
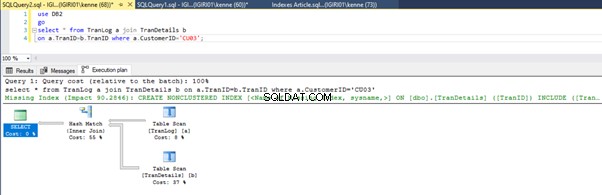
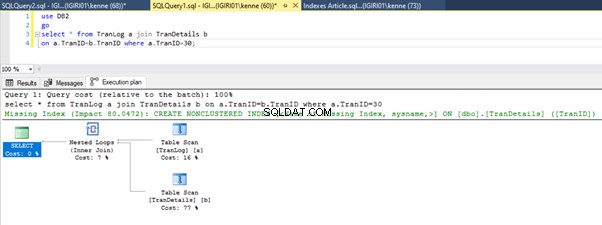
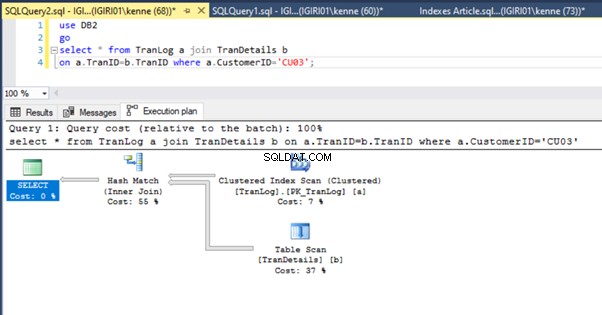
Wenn wir die Abfragen in Listing 5 ausführen, müssen wir in beiden Fällen einen vollständigen Tabellenscan für beide Tabellen durchführen (siehe Abbildungen 1 und 2). Der dominierende Teil jeder Abfrage sind die physikalischen Operationen. Beides sind innere Verknüpfungen. Listing 5a verwendet jedoch ein Hash-Match join, während Listing 5b eine Nested Loop verwendet beitreten. Hinweis:Listing 5a gibt 4000 Zeilen zurück, während Listing 4b 4 Zeilen zurückgibt.
Drei Schritte zur Leistungsoptimierung
Die erste Optimierung, die wir vornehmen, besteht darin, einen Index (einen Primärschlüssel, um genau zu sein) auf der TranID einzuführen Spalte des TranLog Tabelle:
-- Listing 6: Create Primary Key
alter table TranLog add constraint PK_TranLog primary key clustered (TranID);
Die Abbildungen 3 und 4 zeigen, dass SQL Server diesen Index in beiden Abfragen verwendet und in Listing 5a einen Scan und in Listing 5b eine Suche durchführt.
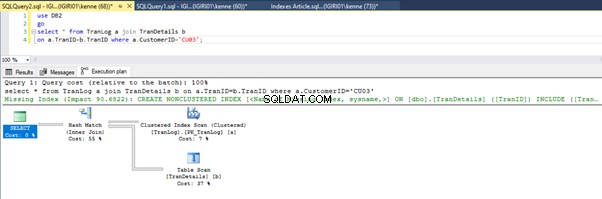
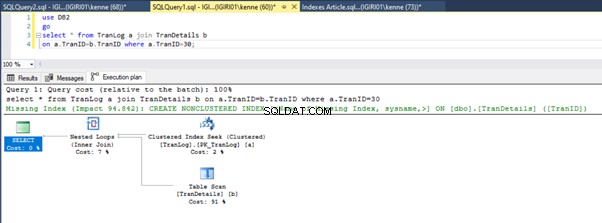
Wir haben eine Indexsuche in Listing 5b. Dies geschieht aufgrund der Spalte, die im Prädikat der WHERE-Klausel enthalten ist – TranID. Auf diese Spalte haben wir einen Index angewendet.
Als nächstes führen wir einen Fremdschlüssel auf der TranID ein Spalte der TranDetails Tabelle (Listing 7).
-- Listing 7: Create Foreign Key
alter table TranDetails add constraint FK_TranDetails foreign key (TranID) references TranLog (TranID);
Am Ausführungsplan ändert sich dadurch nicht viel. Die Situation ist praktisch die gleiche wie zuvor in den Abbildungen 3 und 4 gezeigt.
Dann führen wir einen Index für die Fremdschlüsselspalte ein:
-- Listing 8: Create Index on Foreign Key
create index IX_TranDetails on TranDetails (TranID);
Diese Aktion ändert den Ausführungsplan von Listing 5b dramatisch (siehe Abbildung 6). Wir sehen weitere Indexversuche. Beachten Sie auch die RID-Suche in Abbildung 6.
RID-Lookups auf Heaps finden normalerweise statt, wenn kein Primärschlüssel vorhanden ist. Ein Heap ist eine Tabelle ohne Primärschlüssel.
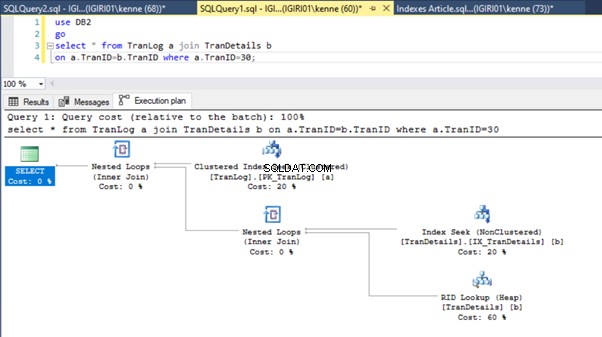
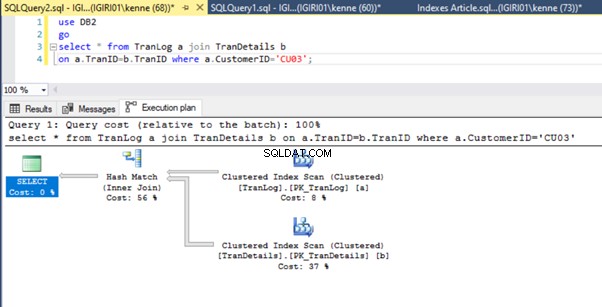
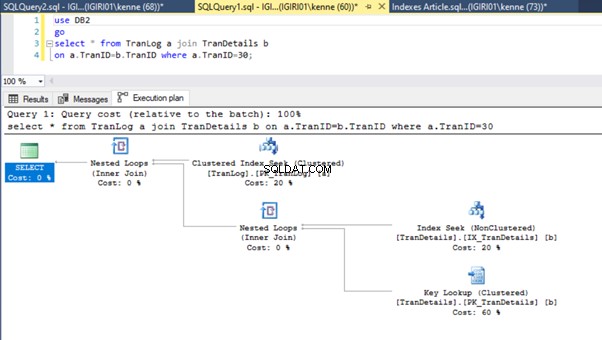
Schließlich fügen wir den TranDetails einen Primärschlüssel hinzu Tisch. Dadurch werden der Tabellen-Scan und die RID-Heap-Suche in Listing 5a bzw. 5b entfernt (siehe Abbildungen 7 und 8).
-- Listing 9: Create Primary Key on TranDetailsID
alter table TranDetails add constraint PK_TranDetails primary key clustered (TranDetailsID);
Schlussfolgerung
Die durch Indizes eingeführte Leistungsverbesserung ist selbst unerfahrenen DBAs wohlbekannt. Wir möchten jedoch darauf hinweisen, dass Sie sich genau ansehen müssen, wie Abfragen Indizes verwenden.
Darüber hinaus besteht die Idee darin, die Lösung in dem speziellen Fall zu etablieren, in dem wir die Verknüpfungsabfragen zwischen Transaktionsprotokoll haben Tabellen und Transaktionsdetails Tabellen.
Im Allgemeinen ist es sinnvoll, die Beziehung zwischen solchen Tabellen mithilfe eines Schlüssels zu erzwingen und Indizes für die Primär- und Fremdschlüsselspalten einzuführen.
Bei der Entwicklung von Anwendungen, die ein solches Design verwenden, sollten Entwickler die erforderlichen Indizes und Beziehungen in der Designphase berücksichtigen. Moderne Tools für SQL-Server-Spezialisten machen diese Anforderungen viel einfacher zu erfüllen. Sie können Ihre Abfragen mit dem spezialisierten Query Profiler-Tool profilieren. Es ist Teil der multifunktionalen professionellen Lösung dbForge Studio für SQL Server, die von Devart entwickelt wurde, um das Leben von DBAs einfacher zu machen.