SQL Server stellt uns eine Reihe von Fensterfunktionen zur Verfügung, die uns helfen, Berechnungen über eine Reihe von Zeilen hinweg durchzuführen, ohne die Aufrufe an die Datenbank wiederholen zu müssen. Im Gegensatz zu den standardmäßigen Aggregatfunktionen gruppieren die Fensterfunktionen die Zeilen nicht in einer einzelnen Ausgabezeile, sondern geben einen einzelnen aggregierten Wert für jede Zeile zurück, wobei die separaten Identitäten für diese Zeilen beibehalten werden. Der Windows-Begriff bezieht sich hier nicht auf das Microsoft Windows-Betriebssystem, er beschreibt den Satz von Zeilen, die die Funktion verarbeitet.
Einer der nützlichsten Typen von Fensterfunktionen sind Ranking-Fensterfunktionen, die verwendet werden, um bestimmte Feldwerte einzustufen und sie gemäß dem Rang jeder Zeile zu kategorisieren, was zu einem einzigen aggregierten Wert für jede beteiligte Zeile führt. Es gibt vier Ranking-Fensterfunktionen, die in SQL Server unterstützt werden; ROW_NUMBER(), RANK(), DENSE_RANK() und NTILE(). Alle diese Funktionen werden verwendet, um die ROWID für das bereitgestellte Zeilenfenster auf ihre eigene Weise zu berechnen.
Vier Ranking-Fensterfunktionen verwenden die OVER()-Klausel, die einen benutzerdefinierten Satz von Zeilen innerhalb eines Abfrageergebnissatzes definiert. Indem Sie die OVER()-Klausel definieren, können Sie auch die PARTITION BY-Klausel einschließen, die den Satz von Zeilen bestimmt, die die Fensterfunktion verarbeitet, indem Sie Spalten oder durch Kommas getrennte Spalten angeben, um die Partition zu definieren. Zusätzlich kann die ORDER BY-Klausel eingefügt werden, die die Sortierkriterien innerhalb der Partitionen definiert, die die Funktion während der Verarbeitung durch die Zeilen durchgeht.
In diesem Artikel werden wir diskutieren, wie vier Ranking-Fensterfunktionen praktisch verwendet werden:ROW_NUMBER(), RANK(), DENSE_RANK() und NTILE() und den Unterschied zwischen ihnen.
Um unsere Demo bereitzustellen, erstellen wir eine neue einfache Tabelle und fügen mit dem folgenden T-SQL-Skript einige Datensätze in die Tabelle ein:
CREATE TABLE StudentScore
(
Student_ID INT PRIMARY KEY,
Student_Name NVARCHAR (50),
Student_Score INT
)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978)
INSERT INTO StudentScore VALUES (2,'Zaid', 770)
INSERT INTO StudentScore VALUES (3,'Mohd', 1140)
INSERT INTO StudentScore VALUES (4,'Jack', 770)
INSERT INTO StudentScore VALUES (5,'John', 1240)
INSERT INTO StudentScore VALUES (6,'Mike', 1140)
INSERT INTO StudentScore VALUES (7,'Goerge', 885)
Sie können das erfolgreiche Einfügen der Daten mit der folgenden SELECT-Anweisung überprüfen:
SELECT * FROM StudentScore ORDER BY Student_ScoreWenn das sortierte Ergebnis angewendet wird, sieht die Ergebnismenge wie folgt aus:

ROW_NUMBER()
Die Ranking-Fensterfunktion ROW_NUMBER() gibt eine eindeutige fortlaufende Nummer für jede Zeile innerhalb der Partition des angegebenen Fensters zurück, beginnend bei 1 für die erste Zeile in jeder Partition und ohne Wiederholung oder Überspringen von Zahlen im Ranking-Ergebnis jeder Partition. Wenn innerhalb des Rowsets doppelte Werte vorhanden sind, werden die Ranking-ID-Nummern willkürlich zugewiesen. Wenn die Klausel PARTITION BY angegeben ist, wird die Nummer der Rangfolgezeile für jede Partition zurückgesetzt. In der zuvor erstellten Tabelle zeigt die folgende Abfrage, wie die ROW_NUMBER Ranking-Fensterfunktion verwendet wird, um die StudentScore-Tabellenzeilen gemäß der Punktzahl jedes Schülers zu ordnen:
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
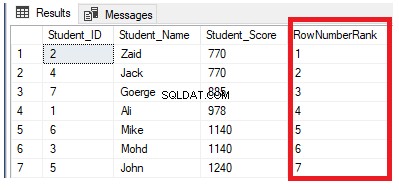
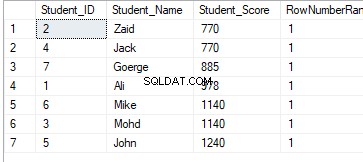
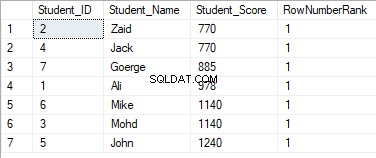
Aus dem Ergebnissatz unten geht hervor, dass die Fensterfunktion ROW_NUMBER die Tabellenzeilen gemäß den Werten der Spalte Student_Score für jede Zeile einordnet, indem sie eine eindeutige Nummer für jede Zeile generiert, die ihren Student_Score-Rang widerspiegelt, beginnend mit der Zahl 1 ohne Duplikate oder Lücken und Umgang mit allen Zeilen als eine Partition. Sie können auch sehen, dass die doppelten Punktzahlen zufällig verschiedenen Rängen zugewiesen werden:
Wenn wir die vorherige Abfrage ändern, indem wir die Klausel PARTITION BY einfügen, um mehr als eine Partition zu haben, wie in der T-SQL-Abfrage unten gezeigt:
SELECT *, ROW_NUMBER() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
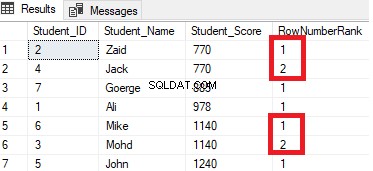
Das Ergebnis zeigt, dass die Fensterfunktion ROW_NUMBER die Tabellenzeilen gemäß den Student_Score-Spaltenwerten für jede Zeile einordnet, aber die Zeilen behandelt, die denselben Student_Score-Wert wie eine Partition haben. Sie werden sehen, dass für jede Zeile eine eindeutige Nummer generiert wird, die ihren Student_Score-Rang widerspiegelt, beginnend mit der Nummer 1 ohne Duplikate oder Lücken innerhalb derselben Partition, wobei die Rangnummer zurückgesetzt wird, wenn Sie zu einem anderen Student_Score-Wert wechseln.
Beispielsweise werden die Schüler mit einer Punktzahl von 770 innerhalb dieser Punktzahl eingestuft, indem ihr eine Rangnummer zugewiesen wird. Wenn es jedoch auf den Schüler mit der Punktzahl 885 verschoben wird, wird die Rangstartnummer zurückgesetzt und beginnt wieder bei 1, wie unten gezeigt:
RANK()
Die Ranking-Fensterfunktion RANK() gibt eine eindeutige Rangnummer für jede unterschiedliche Zeile innerhalb der Partition gemäß einem angegebenen Spaltenwert zurück, beginnend bei 1 für die erste Zeile in jeder Partition, mit demselben Rang für doppelte Werte und mit Lücken zwischen den Rängen; diese Lücke erscheint in der Sequenz nach den doppelten Werten. Mit anderen Worten, die RANK()-Ranking-Fensterfunktion verhält sich wie die ROW_NUMBER()-Funktion, mit Ausnahme der Zeilen mit gleichen Werten, wo sie mit derselben Rang-ID rangiert und danach eine Lücke erzeugt. Wenn wir die vorherige Ranking-Abfrage ändern, um die Ranking-Funktion RANK() zu verwenden:
SELECT *, RANK () OVER( ORDER BY Student_Score) AS RankRank
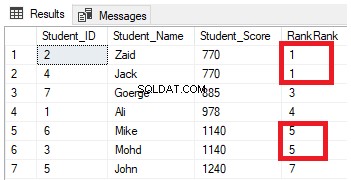
FROM StudentScoreSie werden aus dem Ergebnis ersehen, dass die Fensterfunktion RANK die Tabellenzeilen gemäß den Werten der Spalte Student_Score für jede Zeile einordnet, wobei ein Rangordnungswert ihren Student_Score widerspiegelt, beginnend mit der Zahl 1, und die Zeilen mit demselben Student_Score mit einordnet gleichen Rangwert. Sie können auch sehen, dass zwei Zeilen mit Student_Score gleich 770 mit demselben Wert eingestuft werden, sodass nach der zweitplatzierten Zeile eine Lücke verbleibt, nämlich die fehlende Zahl 2. Dasselbe passiert mit den Zeilen, in denen Student_Score gleich 1140 ist, die mit demselben Wert eingestuft werden, wobei eine Lücke bleibt, nämlich die fehlende Zahl 6 nach der zweiten Zeile, wie unten gezeigt:
Ändern der vorherigen Abfrage durch Einfügen der PARTITION BY-Klausel, um mehr als eine Partition zu haben, wie in der T-SQL-Abfrage unten gezeigt:
SELECT *, RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreDas Ranking-Ergebnis hat keine Bedeutung, da das Ranking gemäß den Student_Score-Werten für jede Partition erfolgt und die Daten gemäß den Student_Score-Werten partitioniert werden. Und aufgrund der Tatsache, dass jede Partition Zeilen mit denselben Student_Score-Werten hat, werden die Zeilen mit denselben Student_Score-Werten in derselben Partition mit einem Wert gleich 1 eingestuft. Wenn Sie also zur zweiten Partition wechseln, wird der Rang zurückgesetzt werden, beginnend wieder mit der Nummer 1, wobei alle Ranking-Werte gleich 1 sind, wie unten gezeigt:
DENSE_RANK()
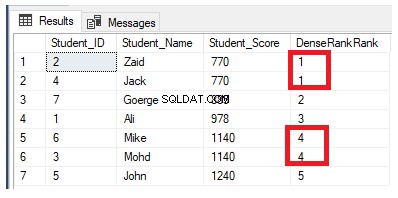
Die Rangfolgefensterfunktion DENSE_RANK() ähnelt der Funktion RANK(), indem sie eine eindeutige Rangnummer für jede einzelne Zeile innerhalb der Partition gemäß einem angegebenen Spaltenwert generiert, beginnend bei 1 für die erste Zeile in jeder Partition, wobei die Zeilen mit einer Rangfolge versehen werden gleiche Werte mit derselben Rangnummer, außer dass kein Rang übersprungen wird und keine Lücken zwischen den Rängen bleiben.
Wenn wir die vorherige Ranking-Abfrage umschreiben, um die Ranking-Funktion DENSE_RANK() zu verwenden:
Ändern Sie erneut die vorherige Abfrage, indem Sie die Klausel PARTITION BY einfügen, um mehr als eine Partition zu haben, wie in der T-SQL-Abfrage unten gezeigt:
SELECT *, DENSE_RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Die Ranking-Werte haben keine Bedeutung, wenn alle Zeilen mit dem Wert 1 eingestuft werden, da die doppelten Werte demselben Ranking-Wert zugewiesen und die Rang-Start-ID zurückgesetzt werden, wenn eine neue Partition verarbeitet wird, wie unten gezeigt:
NTILE(N)
Die Rangfolgefensterfunktion NTILE(N) wird verwendet, um die Zeilen im Zeilensatz in eine bestimmte Anzahl von Gruppen zu verteilen, wobei jede Zeile im Zeilensatz mit einer eindeutigen Gruppennummer versehen wird, beginnend mit der Nummer 1, die angibt, zu welcher Gruppe diese Zeile gehört bis, wobei N eine positive Zahl ist, die die Anzahl der Gruppen definiert, in die Sie die Zeilengruppe verteilen müssen.
Mit anderen Worten, wenn Sie bestimmte Datenzeilen der Tabelle basierend auf bestimmten Spaltenwerten in 3 Gruppen unterteilen müssen, hilft Ihnen die Rangfolgefensterfunktion NTILE(3) dabei, dies ganz einfach zu erreichen.
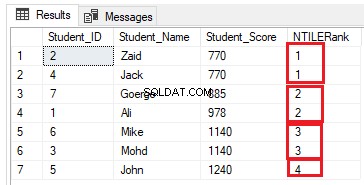
Die Anzahl der Zeilen in jeder Gruppe kann berechnet werden, indem die Anzahl der Zeilen in die erforderliche Anzahl von Gruppen geteilt wird. Wenn wir die vorherige Ranking-Abfrage ändern, um die NTILE(4)-Ranking-Window-Funktion zu verwenden, um sieben Tabellenzeilen in vier Gruppen einzuordnen, wie die folgende T-SQL-Abfrage:
SELECT *, NTILE(4) OVER( ORDER BY Student_Score) AS NTILERank
FROM StudentScore
Die Anzahl der Zeilen sollte (7/4 =1,75) Zeilen in jeder Gruppe betragen. Mit der Funktion NTILE() weist die SQL Server-Engine den ersten drei Gruppen zwei Zeilen und der letzten Gruppe eine Zeile zu, damit alle Zeilen in den Gruppen enthalten sind, wie im Ergebnissatz unten gezeigt:
Ändern der vorherigen Abfrage durch Einfügen der PARTITION BY-Klausel, um mehr als eine Partition zu haben, wie in der T-SQL-Abfrage unten gezeigt:
SELECT *, NTILE(4) OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreDie Zeilen werden auf jeder Partition in vier Gruppen verteilt. Beispielsweise befinden sich die ersten beiden Zeilen mit Student_Score gleich 770 in derselben Partition und werden innerhalb der Gruppen verteilt, wobei jede mit einer eindeutigen Nummer bewertet wird, wie im Ergebnissatz unten gezeigt:
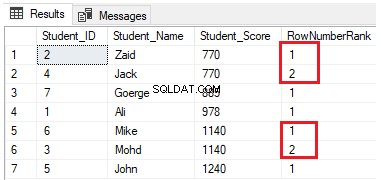
Alles zusammen
Um ein klareres Vergleichsszenario zu erhalten, lassen Sie uns die vorherige Tabelle kürzen, ein weiteres Klassifizierungskriterium hinzufügen, nämlich die Klasse der Schüler, und schließlich sieben neue Zeilen mit dem folgenden T-SQL-Skript einfügen:
TRUNCATE TABLE StudentScore
GO
ALTER TABLE StudentScore ADD CLASS CHAR(1)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978,'A')
INSERT INTO StudentScore VALUES (2,'Zaid', 770,'B')
INSERT INTO StudentScore VALUES (3,'Mohd', 1140,'A')
INSERT INTO StudentScore VALUES (4,'Jack', 879,'B')
INSERT INTO StudentScore VALUES (5,'John', 1240,'C')
INSERT INTO StudentScore VALUES (6,'Mike', 1100,'B')
INSERT INTO StudentScore VALUES (7,'Goerge', 885,'C')Danach ordnen wir sieben Zeilen nach jeder Schülerpunktzahl und teilen die Schüler nach ihrer Klasse auf. Mit anderen Worten, jede Partition enthält eine Klasse, und jede Klasse von Schülern wird gemäß ihrer Punktzahl innerhalb derselben Klasse eingestuft, wobei vier zuvor beschriebene Ranking-Fensterfunktionen verwendet werden, wie im folgenden T-SQL-Skript gezeigt:
SELECT *, ROW_NUMBER() OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RowNumberRank,
RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RankRank,
DENSE_RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS DenseRankRank,
NTILE(7) OVER(PARTITION BY CLASS ORDER BY Student_Score) AS NTILERank
FROM StudentScore
GOAufgrund der Tatsache, dass es keine doppelten Werte gibt, funktionieren vier Ranking-Fensterfunktionen auf die gleiche Weise und geben das gleiche Ergebnis zurück, wie im Ergebnissatz unten gezeigt:
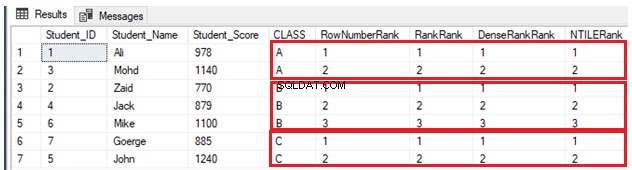
Wenn ein anderer Schüler in Klasse A mit einer Punktzahl aufgenommen wird, die ein anderer Schüler in derselben Klasse bereits hat, verwenden Sie die folgende INSERT-Anweisung:
INSERT INTO StudentScore VALUES (8,'Faisal', 978,'A')Für die Ranglistenfensterfunktionen ROW_NUMBER() und NTILE() ändert sich nichts. Die Funktionen RANK und DENSE_RANK() weisen den Schülern mit derselben Punktzahl denselben Rang zu, mit einer Lücke in den Rängen nach den doppelten Rängen bei Verwendung der RANK-Funktion und ohne Lücke in den Rängen nach den doppelten Rängen bei Verwendung der DENSE_RANK( ), wie im Ergebnis unten gezeigt:
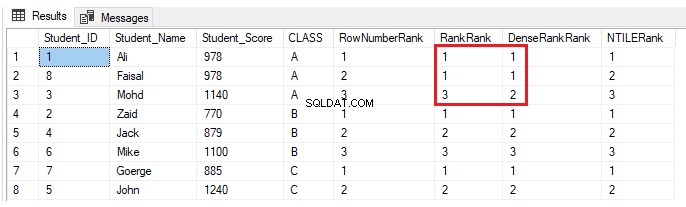
Praxisszenario
Die Ranking-Fensterfunktionen werden häufig von SQL Server-Entwicklern verwendet. Eines der häufigsten Szenarien für die Verwendung von Ranking-Funktionen, wenn Sie bestimmte Zeilen abrufen und andere überspringen möchten, indem Sie die Ranking-Fensterfunktion ROW_NUMBER (,) innerhalb eines CTE verwenden, wie im folgenden T-SQL-Skript, das die Schüler mit Rängen dazwischen zurückgibt 2 und 5 und überspringe die anderen:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
WHERE RowNumberRank >= 2 and RowNumberRank <=5
ORDER BY RowNumberRank
Das Ergebnis zeigt, dass nur Schüler mit Rängen zwischen 2 und 5 zurückgegeben werden:
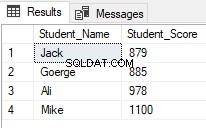
Ab SQL Server 2012 gibt es einen neuen nützlichen Befehl, OFFSET FETCH wurde eingeführt, der verwendet werden kann, um die gleiche vorherige Aufgabe auszuführen, indem bestimmte Datensätze abgerufen und die anderen übersprungen werden, indem das folgende T-SQL-Skript verwendet wird:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
ORDER BY
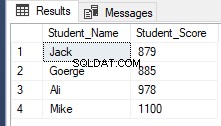
RowNumberRank OFFSET 1 ROWS FETCH NEXT 4 ROWS ONLY;Abrufen des gleichen vorherigen Ergebnisses wie unten gezeigt:
Schlussfolgerung
SQL Server stellt uns vier Ranking-Fensterfunktionen zur Verfügung, die uns helfen, die bereitgestellten Zeilen nach bestimmten Spaltenwerten zu ordnen. Diese Funktionen sind:ROW_NUMBER(), RANK(), DENSE_RANK() und NTILE(). Alle diese Ranking-Funktionen führen die Ranking-Aufgabe auf ihre eigene Weise aus und geben das gleiche Ergebnis zurück, wenn es keine doppelten Werte in den Zeilen gibt. Wenn innerhalb des Zeilensatzes ein doppelter Wert vorhanden ist, weist die RANK-Funktion allen Zeilen mit demselben Wert dieselbe Ranking-ID zu, wodurch Lücken zwischen den Rängen nach den Duplikaten entstehen. Die DENSE_RANK-Funktion weist auch allen Zeilen mit demselben Wert dieselbe Ranking-ID zu, hinterlässt jedoch keine Lücke zwischen den Rängen nach den Duplikaten. Wir gehen in diesem Artikel verschiedene Szenarien durch, um alle möglichen Fälle abzudecken, die Ihnen helfen, die Funktionen des Ranking-Fensters praktisch zu verstehen.
Referenzen:
- ROW_NUMBER (Transact-SQL)
- RANK (Transact-SQL)
- DENSE_RANK (Transact-SQL)
- NTILE (Transact-SQL)
- OFFSET FETCH-Klausel (SQL Server Compact)