In diesem Artikel werden wir typische Fehler besprechen, mit denen neue Entwickler beim Entwerfen von T-SQL-Code konfrontiert werden können. Darüber hinaus sehen wir uns die Best Practices und einige nützliche Tipps an, die Ihnen bei der Arbeit mit SQL Server helfen können, sowie Problemumgehungen zur Verbesserung der Leistung.
Inhalt:
1. Datentypen
2. *
3. Pseudonym
4. Spaltenreihenfolge
5. NICHT IN gegen NULL
6. Datumsformat
7. Datumsfilter
8. Berechnung
9. Implizit konvertieren
10. LIKE &unterdrückter Index
11. Unicode vs. ANSI
12. ZUSAMMENSTELLEN
13. BINÄR ZUSAMMENSTELLEN
14. Codestil
15. [var]char
16. Datenlänge
17. ISNULL gegen COALESCE
18. Mathe
19. UNION gegen UNION ALLE
20. Nochmals lesen
21. Unterabfrage
22. FALL WENN
23. Skalarfunktion
24. ANSICHTEN
25. CURSOR
26. STRING_CONCAT
27. SQL-Injection
Datentypen
Das Hauptproblem bei der Arbeit mit SQL Server ist die falsche Auswahl von Datentypen.
Angenommen, wir haben zwei identische Tabellen:
DECLARE @Employees1 TABLE ( EmployeeID BIGINT PRIMARY KEY , IsMale VARCHAR(3) , BirthDate VARCHAR(20))INSERT INTO @Employees1VALUES (123, 'YES', '2012-09-01')DECLARE @Employees2 TABLE ( EmployeeID INT PRIMARY KEY , IsMale BIT , BirthDate DATE)INSERT INTO @Employees2VALUES (123, 1, '2012-09-01')
Lassen Sie uns eine Abfrage ausführen, um zu überprüfen, was der Unterschied ist:
DECLARE @BirthDate DATE ='2012-09-01'SELECT * FROM @Employees1 WHERE BirthDate =@BirthDateSELECT * FROM @Employees2 WHERE BirthDate =@BirthDate
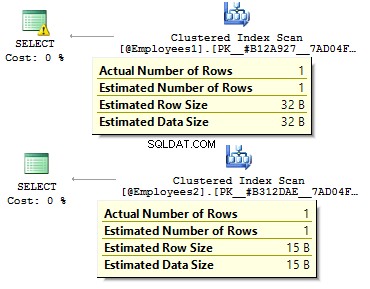
Im ersten Fall sind die Datentypen redundanter als sie sein könnten. Warum sollten wir einen Bitwert als JA/NEIN speichern? Reihe? Warum sollten wir ein Datum als Zeile speichern? Warum sollten wir BIGINT verwenden? für Angestellte in der Tabelle statt INT ?
Dies führt zu folgenden Nachteilen:
- Tabellen können viel Speicherplatz auf der Festplatte beanspruchen;
- Wir müssen mehr Seiten lesen und mehr Daten in BufferPool einfügen um mit Daten umzugehen.
- Schlechte Leistung.
*
Ich habe die Situation erlebt, in der Entwickler alle Daten aus einer Tabelle abrufen und dann auf der Clientseite DataReader verwenden um nur erforderliche Felder auszuwählen. Ich empfehle diesen Ansatz nicht:
USE AdventureWorks2014GOSET STATISTICS TIME, IO ONSELECT *FROM Person.PersonSELECT BusinessEntityID , FirstName , MiddleName , LastNameFROM Person.PersonSET STATISTICS TIME, IO OFF
Es gibt einen signifikanten Unterschied in der Ausführungszeit der Abfrage. Darüber hinaus kann der abdeckende Index eine Anzahl logischer Lesevorgänge reduzieren.
Tabelle 'Person'. Scan-Anzahl 1, logische Lesevorgänge 3819, physische Lesevorgänge 3, ... SQL Server-Ausführungszeiten:CPU-Zeit =31 ms, verstrichene Zeit =1235 ms. Tabelle „Person“. Scan-Anzahl 1, logische Lesevorgänge 109, physische Lesevorgänge 1, ... SQL Server-Ausführungszeiten:CPU-Zeit =0 ms, verstrichene Zeit =227 ms.
Alias
Lassen Sie uns eine Tabelle erstellen:
USE AdventureWorks2014GOIF OBJECT_ID('Sales.UserCurrency') IS NOT NULL DROP TABLE Sales.UserCurrencyGOCREATE TABLE Sales.UserCurrency (CurrencyCode NCHAR(3) PRIMARY KEY)INSERT INTO Sales.UserCurrencyVALUES ('USD') Angenommen, wir haben eine Abfrage, die die Anzahl identischer Zeilen in beiden Tabellen zurückgibt:
SELECT COUNT_BIG(*)FROM Sales.CurrencyWHERE CurrencyCode IN ( SELECT CurrencyCode FROM Sales.UserCurrency )
Alles funktioniert wie erwartet, bis jemand eine Spalte in Sales.UserCurrency umbenennt Tabelle:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLUMN'
Als Nächstes führen wir eine Abfrage aus und prüfen, ob wir alle Zeilen in Sales.Currency erhalten Tabelle, statt 1 Zeile. Beim Erstellen eines Ausführungsplans würde SQL Server in der Bindungsphase die Spalten von Sales.UserCurrency, prüfen CurrencyCode wird nicht gefunden dort und entscheidet, dass diese Spalte zur Sales.Currency gehört Tisch. Danach löscht ein Optimierer CurrencyCode =CurrencyCode Zustand.
Daher empfehle ich die Verwendung von Aliasnamen:
SELECT COUNT_BIG(*)FROM Sales.Currency cWHERE c.CurrencyCode IN ( SELECT u.CurrencyCode FROM Sales.UserCurrency u )
Spaltenreihenfolge
Angenommen, wir haben eine Tabelle:
WENN OBJECT_ID('dbo.DatePeriod') NICHT NULL IST DROP TABLE dbo.DatePeriodGOCREATE TABLE dbo.DatePeriod ( StartDate DATE , EndDate DATE) Wir fügen dort immer Daten basierend auf den Informationen über die Spaltenreihenfolge ein.
INSERT INTO dbo.DatePeriodSELECT '2015-01-01', '2015-01-31'
Angenommen, jemand ändert die Reihenfolge der Spalten:
CREATE TABLE dbo.DatePeriod ( EndDate DATE , StartDate DATE)
Die Daten werden in einer anderen Reihenfolge eingefügt. In diesem Fall ist es eine gute Idee, Spalten explizit in der INSERT-Anweisung anzugeben:
INSERT INTO dbo.DatePeriod (StartDate, EndDate)SELECT '2015-01-01', '2015-01-31'
Hier ist ein weiteres Beispiel:
SELECT TOP(1) *FROM dbo.DatePeriodORDER BY 2 DESC
In welcher Spalte werden wir Daten anordnen? Dies hängt von der Spaltenreihenfolge in einer Tabelle ab. Ändert man die Reihenfolge, erhalten wir falsche Ergebnisse.
NICHT IN gegen NULL
Lassen Sie uns über NICHT IN sprechen Aussage.
Beispielsweise müssen Sie einige Abfragen schreiben:die Datensätze aus der ersten Tabelle zurückgeben, die in der zweiten Tabelle nicht vorhanden sind, und umgekehrt. Normalerweise verwenden Junior-Entwickler IN und NICHT IN :
DECLARE @t1 TABLE (t1 INT, UNIQUE CLUSTERED(t1))INSERT IN @t1 VALUES (1), (2)DECLARE @t2 TABLE (t2 INT, UNIQUE CLUSTERED(t2))INSERT IN @t2 VALUES (1 )SELECT *FROM @t1WHERE t1 NOT IN (SELECT t2 FROM @t2)SELECT *FROM @t1WHERE t1 IN (SELECT t2 FROM @t2)
Die erste Abfrage hat 2 zurückgegeben, die zweite – 1. Außerdem fügen wir einen weiteren Wert in der zweiten Tabelle hinzu – NULL :
INSERT INTO @t2 VALUES (1), (NULL)
Beim Ausführen der Abfrage mit NOT IN , erhalten wir keine Ergebnisse. Warum IN funktioniert und NICHT In nicht? Der Grund dafür ist, dass SQL Server TRUE verwendet , FALSCH , und UNBEKANNT Logik beim Datenvergleich.
Beim Ausführen einer Abfrage interpretiert SQL Server die IN-Bedingung folgendermaßen:
a IN (1, NULL) ==a=1 ODER a=NULL
NICHT IN :
a NICHT IN (1, NULL) ==a<>1 UND a<>NULL
Beim Vergleich eines beliebigen Werts mit NULL, SQL Server gibt UNBEKANNT zurück. Entweder 1=NULL oder NULL=NULL – beide führen zu UNKNOWN. Soweit wir AND im Ausdruck haben, geben beide Seiten UNKNOWN zurück.
Ich möchte darauf hinweisen, dass dieser Fall nicht selten ist. Beispielsweise markieren Sie eine Spalte als NOT NULL. Nach einer Weile beschließt ein anderer Entwickler, NULLs für zuzulassen diese Spalte. Dies kann dazu führen, dass ein Client-Bericht nicht mehr funktioniert, sobald ein NULL-Wert in die Tabelle eingefügt wurde.
In diesem Fall würde ich empfehlen, NULL-Werte auszuschließen:
SELECT *FROM @t1WHERE t1 NOT IN ( SELECT t2 FROM @t2 WHERE t2 IS NOT NULL )
Außerdem ist es möglich, EXCEPT zu verwenden :
SELECT * FROM @t1EXCEPTSELECT * FROM @t2
Alternativ können Sie NOT EXISTS verwenden :
SELECT *FROM @t1WHERE NOT EXISTS( SELECT 1 FROM @t2 WHERE t1 =t2 )
Welche Variante ist vorzuziehen? Letztere Option mit NOT EXISTS scheint am produktivsten zu sein, da es das optimalere Prädikat-Pushdown generiert Operator, um auf Daten aus der zweiten Tabelle zuzugreifen.
Tatsächlich können die NULL-Werte ein unerwartetes Ergebnis zurückgeben.
Betrachten Sie es an diesem speziellen Beispiel:
USE AdventureWorks2014GOSELECT COUNT_BIG(*)FROM Production.ProductSELECT COUNT_BIG(*)FROM Production.ProductWHERE Color ='Grey'SELECT COUNT_BIG(*)FROM Production.ProductWHERE Color <> 'Grey'
Wie Sie sehen können, haben Sie nicht das erwartete Ergebnis erhalten, weil NULL-Werte separate Vergleichsoperatoren haben:
SELECT COUNT_BIG(*)FROM Production.ProductWHERE Color IS NULLSELECT COUNT_BIG(*)FROM Production.ProductWHERE Color IS NOT NULL
Hier ist ein weiteres Beispiel mit CHECK Einschränkungen:
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL DROP TABLE #tempGOCREATE TABLE #temp ( Color VARCHAR(15) --NULL , CONSTRAINT CK CHECK (Color IN ('Black', 'White') )) Wir erstellen eine Tabelle mit der Berechtigung, nur weiße und schwarze Farben einzufügen:
INSERT INTO #temp VALUES ('Black')(1 Zeile(n) betroffen) Alles funktioniert wie erwartet.
INSERT INTO #temp VALUES ('Rot')Die INSERT-Anweisung steht in Konflikt mit der CHECK-Einschränkung ... Die Anweisung wurde beendet. Jetzt fügen wir NULL hinzu:
INSERT INTO #temp VALUES (NULL)(1 Zeile(n) betroffen)
Warum hat die CHECK-Einschränkung den NULL-Wert übergeben? Nun, der Grund dafür ist, dass es genügend NICHT FALSCH gibt Bedingung, eine Aufzeichnung zu machen. Die Problemumgehung besteht darin, eine Spalte explizit als NOT NULL zu definieren oder verwenden Sie NULL in der Einschränkung.
Datumsformat
Sehr oft haben Sie Probleme mit Datentypen.
Beispielsweise müssen Sie das aktuelle Datum abrufen. Dazu können Sie die GETDATE-Funktion verwenden:
SELECT GETDATE()
Kopieren Sie dann einfach das zurückgegebene Ergebnis in eine erforderliche Abfrage und löschen Sie die Zeit:
SELECT *FROM sys.objectsWHERE create_date <'2016-11-14'
Ist das richtig?
Das Datum wird durch eine String-Konstante angegeben:
SET LANGUAGE GermanSET DATEFORMAT DMYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05 -dec-2016'SELECT @d1, @d2, @d3, @d4
Alle Werte haben eine einwertige Interpretation:
----------- ----------- ----------- -----------2016-12 -05 2016-05-12 2016-05-12 2016-12-05
Es wird keine Probleme verursachen, bis die Abfrage mit dieser Geschäftslogik auf einem anderen Server ausgeführt wird, auf dem die Einstellungen abweichen können:
SET DATEFORMAT MDYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05-dec -2016'SELECT @d1, @d2, @d3, @d4
Diese Optionen können jedoch zu einer falschen Interpretation des Datums führen:
----------- ----------- ----------- -----------2016-05 -12 2016-12-05 2016-12-05 2016-12-05
Außerdem kann dieser Code sowohl zu einem sichtbaren als auch zu einem verborgenen Fehler führen.
Betrachten Sie das folgende Beispiel. Wir müssen Daten in eine Testtabelle einfügen. Auf einem Testserver funktioniert alles perfekt:
DECLARE @t TABLE (a DATETIME)INSERT INTO @t VALUES ('05/13/2016') Auf der Clientseite wird diese Abfrage jedoch Probleme haben, da unsere Servereinstellungen unterschiedlich sind:
DECLARE @t TABLE (a DATETIME)SET DATEFORMAT DMYINSERT INTO @t VALUES ('05/13/2016') Msg 242, Level 16, State 3, Line 28Die Konvertierung eines varchar-Datentyps in einen datetime-Datentyp führte zu einem außerhalb des zulässigen Bereichs liegenden Wert.
Welches Format sollten wir also verwenden, um Datumskonstanten zu deklarieren? Um diese Frage zu beantworten, führen Sie diese Abfrage aus:
SET DATEFORMAT YMDSET LANGUAGE GermanDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112 'SELECT @d1, @d2, @d3, @d4GOSET LANGUAGE DeutschDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112'SELECT @d1, @d2, @d3, @d4
Die Interpretation von Konstanten kann je nach installierter Sprache unterschiedlich sein:
----------- ----------- ----------- -----------2016-01 -12 2016-01-12 2016-01-12 2016-01-12 ----------- ----------- ----------- -----------2016-12-01 2016-12-01 2016-01-12 2016-01-12
Daher ist es besser, die letzten beiden Optionen zu verwenden. Außerdem möchte ich hinzufügen, dass es keine gute Idee ist, das Datum explizit anzugeben:
SET LANGUAGE FrenchDECLARE @d DATETIME ='12-jan-2016'Msg 241, Level 16, State 1, Line 29Échec de la conversion de la date et/ou de l'heure à partir d'une chaîne de caractères.
Wenn Sie also möchten, dass Konstanten mit Datumsangaben korrekt interpretiert werden, müssen Sie sie im folgenden Format JJJJMMTT. angeben
Außerdem möchte ich Sie auf das Verhalten einiger Datentypen aufmerksam machen:
SET LANGUAGE EnglishSET DATEFORMAT YMDDECLARE @d1 DATE ='2016-01-12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2GOSET LANGUAGE DeutschSET DATEFORMAT DMYDECLARE @d1 DATE ='2016-01- 12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2
Anders als DATETIME, das DATE Typ wird bei verschiedenen Einstellungen auf einem Server richtig interpretiert:
---------- ----------2016-01-12 2016-01-12---------- ------- ---2016-01-12 2016-12-01
Datumsfilter
Um fortzufahren, werden wir uns überlegen, wie Daten effektiv gefiltert werden können. Beginnen wir mit DATETIME/DATE:
USE AdventureWorks2014GOUPDATE TOP(1) dbo.DatabaseLogSET PostTime ='20140716 12:12:12'
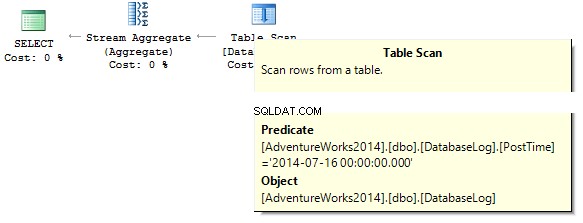
Jetzt versuchen wir herauszufinden, wie viele Zeilen die Abfrage für einen bestimmten Tag zurückgibt:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime ='20140716'
Die Abfrage gibt 0 zurück. Beim Erstellen eines Ausführungsplans versucht der SQL-Server, eine Zeichenfolgenkonstante in den Datentyp der Spalte umzuwandeln, die wir herausfiltern müssen:
Erstellen Sie einen Index:
NICHT EINGESCHLOSSENEN INDEX IX_PostTime AUF dbo.DatabaseLog (PostTime) ERSTELLEN
Es gibt richtige und falsche Möglichkeiten, Daten auszugeben. Beispielsweise müssen Sie die Zeitspalte löschen:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) ='20140716'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CAST(PostTime AS DATE) ='20140716'
Oder wir müssen einen Bereich angeben:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime BETWEEN '20140716' AND '20140716 23:59:59.997'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140716' AND PostTime <'20140717'
Unter Berücksichtigung der Optimierung kann ich sagen, dass diese beiden Abfragen die richtigen sind. Der Punkt ist, dass alle Konvertierungen und Berechnungen von Indexspalten, die herausgefiltert werden, die Leistung drastisch verringern und die Zeit für logische Lesevorgänge erhöhen können:
Tabelle 'DatabaseLog'. Scan-Zähler 1, logische Lesevorgänge 7, ...Tabelle 'DatabaseLog'. Scan-Anzahl 1, logische Lesevorgänge 2, ...
Die PostTime war zuvor noch nicht im Index enthalten, und wir konnten keine Effizienz bei der Verwendung dieses korrekten Ansatzes beim Filtern erkennen. Eine andere Sache ist, wenn wir Daten für einen Monat ausgeben müssen:
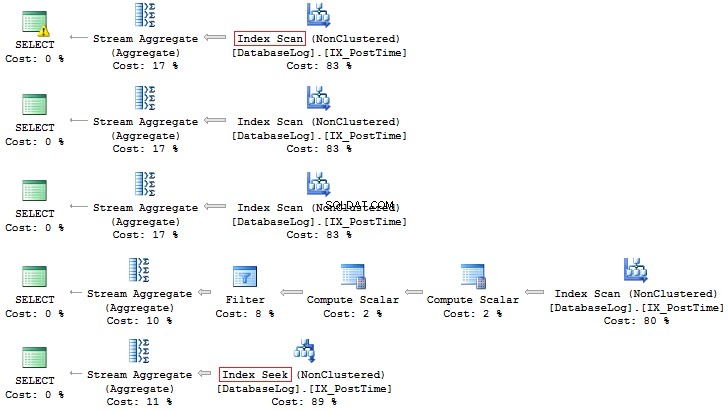
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE DATEPART(YEAR, PostTime) =2014 AND DATEPART(MONTH, PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE YEAR(PostTime) =2014 AND MONTH(PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE EOMONTH(PostTime) ='20140731'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140701' UND PostTime <'20140801'
Auch hier ist letztere Option vorzuziehen:
Außerdem können Sie jederzeit einen Index basierend auf einem berechneten Feld erstellen:
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') IS NOT NULL ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDayGOALTER TABLE dbo.DatabaseLog ADD MonthLastDay AS EOMONTH(PostTime) --PERSISTEDGOCREATE INDEX IX_MonthLastDay ON dbo.DatabaseLog (MonthLastDay) Im Vergleich zur vorherigen Abfrage kann der Unterschied in den logischen Messwerten erheblich sein (wenn es sich um große Tabellen handelt):
SET STATISTICS IO ONSELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140701' AND PostTime <'20140801'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE MonthLastDay ='20140731'SET STATISTICS IO OFFTable 'DatabaseLog'. Scan-Zähler 1, logische Lesevorgänge 7, ...Tabelle 'DatabaseLog'. Scananzahl 1, logische Lesevorgänge 3, ...
Berechnung
Wie bereits besprochen, verringern alle Berechnungen für Indexspalten die Leistung und erhöhen die Zeit für logische Lesevorgänge:
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID * 2 =10000SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =2500 * 2SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =5000Table 'Person'. Scan-Zähler 1, logische Lesevorgänge 67, ...Tabelle 'Person'. Scananzahl 0, logische Lesevorgänge 3, ...
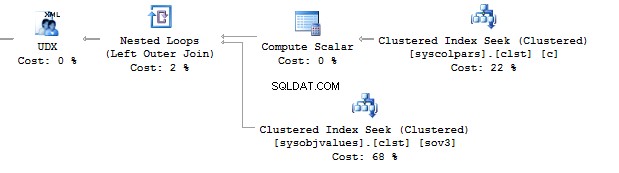
Wenn wir uns die Ausführungspläne ansehen, dann führt SQL Server im ersten IndexScan aus :
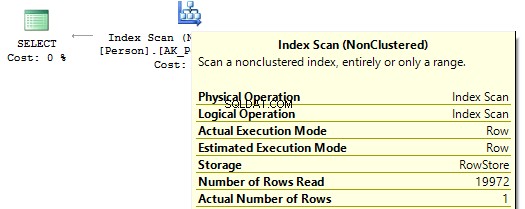
Wenn es dann keine Berechnungen für die Indexspalten gibt, sehen wir IndexSeek :

Implizit konvertieren
Sehen wir uns diese beiden Abfragen an, die nach demselben Wert filtern:
USE AdventureWorks2014GOSELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber =30845SELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber ='30845'
Die Ausführungspläne enthalten die folgenden Informationen:
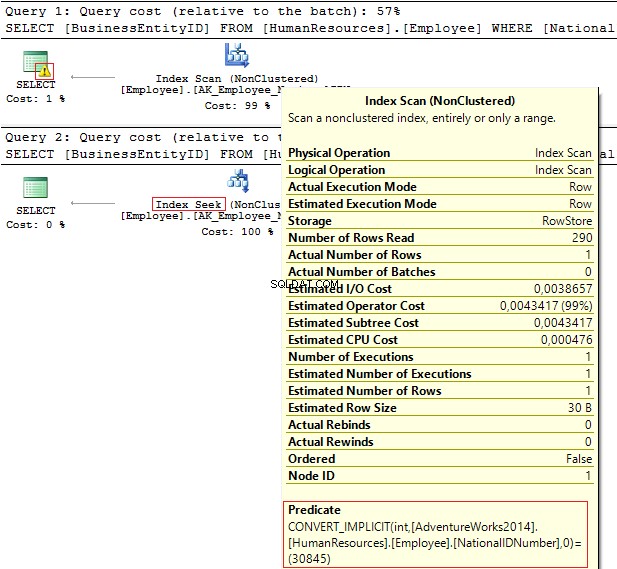
- Warnung und IndexScan auf dem ersten Plan
- IndexSeek – auf der zweiten.
Tabelle 'Mitarbeiter'. Scan-Anzahl 1, logische Lesevorgänge 4, ...Tabelle 'Mitarbeiter'. Scananzahl 0, logische Lesevorgänge 2, ...
Die NationalIDNumber Spalte hat den NVARCHAR(15) Datentyp. Die Konstante, die wir zum Herausfiltern von Daten verwenden, ist auf INT festgelegt was uns zu einer impliziten Datentypkonvertierung führt. Im Gegenzug kann es die Leistung verringern. Sie können es überwachen, wenn jemand den Datentyp in der Spalte ändert, die Abfragen werden jedoch nicht geändert.
Es ist wichtig zu verstehen, dass eine implizite Datentypkonvertierung zur Laufzeit zu Fehlern führen kann. Bevor das PostalCode-Feld beispielsweise numerisch war, stellte sich heraus, dass eine Postleitzahl Buchstaben enthalten konnte. Somit wurde der Datentyp aktualisiert. Wenn wir jedoch eine alphabetische Postleitzahl einfügen, funktioniert die alte Abfrage nicht mehr:
SELECT AddressIDFROM Person.[Address]WHERE PostalCode =92700SELECT AddressIDFROM Person.[Address]WHERE PostalCode ='92700'Msg 245, Level 16, State 1, Line 16Conversion failed when converting the nvarchar value 'K4B 1S2' to data type int.
Ein weiteres Beispiel ist, wenn Sie EntityFramework verwenden müssen auf dem Projekt, das standardmäßig alle Zeilenfelder als Unicode interpretiert:
SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber =N'AW00000009'SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber ='AW00000009'
Daher werden falsche Abfragen generiert:

Um dieses Problem zu lösen, stellen Sie sicher, dass die Datentypen übereinstimmen.
LIKE &unterdrückter Index
Tatsächlich bedeutet ein abdeckender Index nicht, dass Sie ihn effektiv nutzen werden.
Lassen Sie es uns an diesem speziellen Beispiel überprüfen. Angenommen, wir müssen alle Zeilen ausgeben, die mit …
beginnenUSE AdventureWorks2014GOSET STATISTICS IO ONSELECT AddressLine1FROM Person.[Address]WHERE SUBSTRING(AddressLine1, 1, 3) ='100'SELECT AddressLine1FROM Person.[Address]WHERE LEFT(AddressLine1, 3) ='100'SELECT AddressLine1FROM Person.[ Address]WHERE CAST(AddressLine1 AS CHAR(3)) ='100'SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '100%'
Wir erhalten die folgenden logischen Messwerte und Ausführungspläne:
Tabelle 'Adresse'. Scan-Zähler 1, logische Lesevorgänge 216, ...Tabelle 'Adresse'. Scan-Zähler 1, logische Lesevorgänge 216, ...Tabelle 'Adresse'. Scan-Zähler 1, logische Lesevorgänge 216, ...Tabelle 'Adresse'. Scananzahl 1, logische Lesevorgänge 4, ...
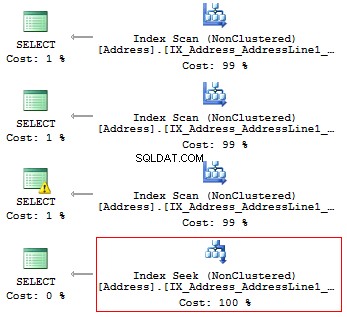
Wenn also ein Index vorhanden ist, sollte dieser keine Berechnungen oder Konvertierungen von Typen, Funktionen usw. enthalten.
Aber was tun Sie, wenn Sie das Vorkommen eines Teilstrings in einem String finden müssen?
SELECT AddressLine1FROM Person.[Adresse]WHERE AddressLine1 LIKE '%100%'v
Wir werden später auf diese Frage zurückkommen.
Unicode vs. ANSI
Es ist wichtig, daran zu denken, dass es den UNICODE gibt und ANSI Saiten. Der UNICODE-Typ enthält NVARCHAR/NCHAR (2 Bytes zu einem Symbol). Zum Speichern von ANSI Zeichenfolgen ist es möglich, VARCHAR/CHAR zu verwenden (1 Byte zu 1 Symbol). Es gibt auch TEXT/NTEXT , aber ich empfehle nicht, sie zu verwenden, da sie die Leistung beeinträchtigen können.
Wenn Sie in einer Abfrage eine Unicode-Konstante angeben, muss ihr das N-Symbol vorangestellt werden. Um dies zu überprüfen, führen Sie die folgende Abfrage aus:
SELECT '文本 ANSI' , N'文本 UNICODE'------- ------------?? ANSI 文本 UNICODE
Wenn N nicht vor der Konstante steht, versucht SQL Server, ein passendes Symbol in der ANSI-Codierung zu finden. Wenn es nicht gefunden wird, wird ein Fragezeichen angezeigt.
SORTIEREN
Sehr oft stellt ein Interviewer bei Vorstellungsgesprächen für die Position Middle/Senior DB Developer die folgende Frage:Wird diese Abfrage die Daten zurückgeben?
DECLARE @a NCHAR(1) ='Ё' , @b NCHAR(1) ='Ф'SELECT @a, @bWHERE @a =@b
Es hängt davon ab, ob. Erstens steht das N-Symbol nicht vor einer Zeichenfolgekonstanten, daher wird es als ANSI interpretiert. Zweitens hängt viel vom aktuellen COLLATE-Wert ab, bei dem es sich um eine Reihe von Regeln handelt, wenn Zeichenfolgendaten ausgewählt und verglichen werden.
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_100_CI_ASGOUSE testGODECLARE @a NCHAR(1) ='Ё' , @b NCHAR(1 ) ='Ä'SELECT @a, @bWHERE @a =@b Diese COLLATE-Anweisung gibt Fragezeichen zurück, da ihre Symbole gleich sind:
---- ----? ?
Wenn wir die COLLATE-Anweisung für eine andere Anweisung ändern:
ALTER DATABASE-Test COLLATE Cyrillic_General_100_CI_AS
In diesem Fall gibt die Abfrage nichts zurück, da kyrillische Zeichen korrekt interpretiert werden.
Wenn daher eine Zeichenkettenkonstante UNICODE belegt, dann ist es notwendig, N vor eine Zeichenkettenkonstante zu setzen. Trotzdem würde ich aus den oben genannten Gründen nicht empfehlen, es überall einzustellen.
Eine weitere Frage, die im Interview gestellt werden muss, bezieht sich auf den Reihenvergleich.
Betrachten Sie das folgende Beispiel:
DECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a =@b, 'TRUE', 'FALSE')
Sind diese Zeilen gleich? Um dies zu überprüfen, müssen wir COLLATE:
explizit angebenDECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a COLLATE Latin1_General_CS_AS =@b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE')
Da es beim Vergleichen und Auswählen von Zeilen COLLATEs gibt, bei denen die Groß- und Kleinschreibung beachtet wird (CS) und die Groß-/Kleinschreibung nicht beachtet werden (CI), können wir nicht mit Sicherheit sagen, ob sie gleich sind. Darüber hinaus gibt es verschiedene COLLATEs sowohl auf Testserver- als auch auf Clientseite.
Es gibt einen Fall, in dem eine Zielbasis und tempdb ZUSAMMENGESTELLT werden stimmen nicht überein.
Erstellen Sie eine Datenbank mit COLLATE:
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Albanian_100_CS_ASGOUSE testGOCREATE TABLE t (c CHAR(1))INSERT INTO t VALUES ('a ')GOIF OBJECT_ID('tempdb.dbo.#t1') IST NICHT NULL DROP TABLE #t1IF OBJECT_ID('tempdb.dbo.#t2') IST NICHT NULL DROP TABLE #t2IF OBJECT_ID('tempdb.dbo.#t3') IS NOT NULL DROP TABLE #t3GOCREATE TABLE #t1 (c CHAR(1))INSERT IN #t1 VALUES ('a')CREATE TABLE #t2 (c CHAR(1) COLLATE database_default)INSERT INTO #t2 VALUES ('a') SELECT c =CAST('a' AS CHAR(1))INTO #t3DECLARE @t TABLE (c VARCHAR(100))INSERT INTO @t VALUES ('a')SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'collation ')UNION ALLSELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation')UNION ALLSELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') FROM tUNION ALLSELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') FROM # t1UNION ALLSELECT '#t2', SQL_VARIANT_PROPERTY(c, 'collation') FROM # t2UNION ALLSELECT '#t3', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t3UNION ALLSELECT '@t', SQL_VARIANT_PROPERTY(c, 'collation') FROM @t Beim Erstellen einer Tabelle erbt sie COLLATE von einer Datenbank. Der einzige Unterschied zur ersten temporären Tabelle, für die wir explizit ohne COLLATE eine Struktur festlegen, ist, dass sie COLLATE von der tempdb erbt Datenbank.
------ --------------------------tempdb Kyrillisch_Allgemein_CI_AStest Albanisch_100_CS_ASt Albanisch_100_CS_AS#t1 Kyrillisch_Allgemein_CI_AS#t2 Albanisch_100_CS_AS#t3 Albanisch_100_CS_AS@t Albanisch_100_CS_AS
Ich werde den Fall beschreiben, wenn COLLATEs in dem speziellen Beispiel mit #t1. nicht übereinstimmen
Beispielsweise werden Daten nicht korrekt herausgefiltert, da COLLATE möglicherweise einen Fall nicht berücksichtigt:
SELECT *FROM #t1WHERE c ='A'
Alternativ können wir einen Konflikt haben, um Tabellen mit verschiedenen COLLATEs zu verbinden:
SELECT *FROM #t1JOIN t ON [#t1].c =t.c
Auf einem Testserver scheint alles perfekt zu funktionieren, während wir auf einem Client-Server eine Fehlermeldung erhalten:
Msg 468, Level 16, State 9, Line 93Collation-Konflikt zwischen "Albanian_100_CS_AS" und "Cyrillic_General_CI_AS" kann nicht in der gleichen Operation gelöst werden.
Um das zu umgehen, müssen wir überall Hacks setzen:
SELECT *FROM #t1JOIN t ON [#t1].c =t.c COLLATE database_default
BINARY COLLATE
Jetzt werden wir herausfinden, wie Sie COLLATE zu Ihrem Vorteil nutzen können.
Betrachten Sie das Beispiel mit dem Auftreten eines Teilstrings in einem String:
SELECT AddressLine1FROM Person.[Adresse]WHERE AddressLine1 LIKE '%100%'
Es ist möglich, diese Abfrage zu optimieren und ihre Ausführungszeit zu verkürzen.
Zuerst müssen wir eine große Tabelle generieren:
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_100_CS_ASGOALTER DATABASE test MODIFY FILE (NAME =N'test', SIZE =64MB)GOALTER DATABASE test MODIFY FILE (NAME =N'test_log', SIZE =64MB)GOUSE testGOCREATE TABLE t ( ansi VARCHAR(100) NOT NULL , unicod NVARCHAR(100) NOT NULL)GO;WITH E1(N) AS ( SELECT * FROM ( WERTE (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N ) AS (SELECT 1 FROM E1 a, E1 b), E4(N) AS (SELECT 1 FROM E2 a, E2 b), E8(N) AS (SELECT 1 FROM E4 a, E4 b)INSERT INTO tSELECT v, vFROM ( SELECT TOP(50000) v =REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '') FROM E8) t Erstellen Sie berechnete Spalten mit binären COLLATEs und Indizes:
ALTER TABLE t ADD ansi_bin AS UPPER(ansi) COLLATE Latin1_General_100_Bin2ALTER TABLE t ADD unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2CREATE NONCLUSTERED INDEX ansi ON t (ansi)CREATE NONCLUSTERED INDEX unicod ON t (unicod)CREATE NONCLUSTERED INDEX ansi_bin)CREATE NOCLLUSTERED INDEX unicod_bin ON t (unicod_bin)
Führen Sie den Filtervorgang aus:
SET STATISTICS TIME, IO ONSELECT COUNT_BIG(*)FROM tWHERE ansi LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE unicod LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SELECT COUNT_BIG(*)FROM tWHERE unicod_bin WIE '%AB%' --COLLATE Latin1_General_100_BIN2SET STATISTICS TIME, IO OFF
Wie Sie sehen können, gibt diese Abfrage das folgende Ergebnis zurück:
SQL Server-Ausführungszeiten:CPU-Zeit =350 ms, verstrichene Zeit =354 ms.SQL Server-Ausführungszeiten:CPU-Zeit =335 ms, verstrichene Zeit =355 ms.SQL Server-Ausführungszeiten:CPU-Zeit =16 ms, verstrichene Zeit =18 ms. SQL Server-Ausführungszeiten:CPU-Zeit =17 ms, verstrichene Zeit =18 ms.
Der Punkt ist, dass das Filtern basierend auf dem binären Vergleich weniger Zeit in Anspruch nimmt. Wenn Sie also das Auftreten von Zeichenfolgen häufig und schnell filtern müssen, können Sie Daten mit COLLATE speichern, die auf BIN enden. Es sollte jedoch beachtet werden, dass bei allen binären COLLATEs zwischen Groß- und Kleinschreibung unterschieden wird.
Codestil
Ein Codierungsstil ist streng individuell. Dennoch sollte dieser Code einfach von anderen Entwicklern gepflegt werden und bestimmten Regeln entsprechen.
Erstellen Sie eine separate Datenbank und eine Tabelle darin:
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_CI_ASGOUSE testGOCREATE TABLE dbo.Employee (EmployeeID INT PRIMARY KEY) Schreiben Sie dann die Abfrage:
Mitarbeiter-ID von Mitarbeiter auswählen
Ändern Sie jetzt COLLATE in ein beliebiges, bei dem die Groß-/Kleinschreibung beachtet wird:
ALTER DATABASE-Test COLLATE Latin1_General_CS_AI
Versuchen Sie dann, die Abfrage erneut auszuführen:
Msg 208, Level 16, State 1, Line 19Ungültiger Objektname 'employee'.
Ein Optimierer verwendet Regeln für das aktuelle COLLATE im Bindungsschritt, wenn er nach Tabellen, Spalten und anderen Objekten sucht, und er vergleicht jedes Objekt des Syntaxbaums mit einem realen Objekt eines Systemkatalogs.
Wenn Sie Abfragen manuell generieren möchten, müssen Sie in Objektnamen immer die richtige Groß-/Kleinschreibung verwenden.
Wie bei Variablen werden COLLATEs von der Master-Datenbank geerbt. Daher müssen Sie auch die richtige Groß-/Kleinschreibung verwenden, um mit ihnen zu arbeiten:
SELECT DATABASEPROPERTYEX('master', 'collation')DECLARE @EmpID INT =1SELECT @empid In diesem Fall erhalten Sie keinen Fehler:
-----------------------Cyrillic_General_CI_AS-----------1
Dennoch kann auf einem anderen Server ein Groß-/Kleinschreibungsfehler auftreten:
--------------------------Latin1_General_CS_ASMsg 137, Level 15, State 2, Line 4 Muss die skalare Variable "@empid".[var]char
Wie Sie wissen, gibt es feste (CHAR , NCHAR ) und Variable (VARCHAR , NVARCHAR ) Datentypen:
DECLARE @a CHAR(20) ='text' , @b VARCHAR(20) ='text'SELECT LEN(@a) , LEN(@b) , DATALENGTH(@a) , DATALENGTH(@b) , '"' + @a + '"' , '"' + @b + '"'SELECT [a =b] =IIF(@a =@b, 'TRUE', 'FALSE') , [b =a] =IIF(@b =@a, 'TRUE', 'FALSE') , [a LIKE b] =IIF(@a WIE @b, 'TRUE', 'FALSE') , [b WIE a] =IIF(@ b LIKE @a, 'TRUE', 'FALSE')Wenn eine Zeile eine feste Länge hat, sagen wir 20 Zeichen, Sie aber nur 4 Zeichen geschrieben haben, fügt SQL Server standardmäßig rechts 16 Leerzeichen hinzu:
--- --- ---- ---- ---------------------- ----------- -----------4 4 20 4 "text" "text"In addition, it is important to understand that when comparing rows with =, blanks on the right are not taken into account:
a =b b =a a LIKE b b LIKE a----- ----- -------- --------TRUE TRUE TRUE FALSEAs for the LIKE operator, blanks will be always inserted.
SELECT 1WHERE 'a ' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a ' -- !!!SELECT 1WHERE 'a' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a%'Data length
It is always necessary to specify type length.
Consider the following example:
DECLARE @a DECIMAL , @b VARCHAR(10) ='0.1' , @c SQL_VARIANTSELECT @a =@b , @c =@aSELECT @a , @c , SQL_VARIANT_PROPERTY(@c,'BaseType') , SQL_VARIANT_PROPERTY(@c,'Precision') , SQL_VARIANT_PROPERTY(@c,'Scale')As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- -----0 0 decimal 18 0As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ----40 123456789_123456789_123456789_123456789_ 1 1 30 30In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions:ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) =NULLSELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL')DECLARE @i INT =NULLSELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ----N NULL---- ----7 7.1As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN operator.
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3SELECT 1.0 / 3However, it is not. Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
-----------0-----------0.333333Also, let’s consider this particular example:
SELECT COUNT(*) , COUNT(1) , COUNT(val) , COUNT(DISTINCT val) , SUM(val) , SUM(DISTINCT val)FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)SELECT AVG(val) , SUM(val) / COUNT(val) , AVG(val * 1.) , AVG(CAST(val AS FLOAT))FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id]FROM sys.system_objectsUNIONSELECT [object_id]FROM sys.objectsSELECT [object_id]FROM sys.system_objectsUNION ALLSELECT [object_id]FROM sys.objects
Also, I would like to point out the difference of these operators:the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)SET @AddressLine ='4775 Kentucky Dr.'SELECT TOP(1) AddressIDFROM Person.[Address]WHERE AddressLine1 =@AddressLine OR AddressLine2 =@AddressLineAs we have OR in the statement, we will receive IndexScan:
Table 'Address'. Scan count 1, logical reads 90, ...Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressIDFROM ( SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine1 =@AddressLine UNION ALL SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine2 =@AddressLine) tWhen the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
Table 'Worktable'. Scan count 0, logical reads 0, ...Table 'Address'. Scan count 1, logical reads 3, ...Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT e.BusinessEntityID , ( SELECT p.LastName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID ) , ( SELECT p.FirstName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID )FROM HumanResources.Employee eSELECT e.BusinessEntityID , p.LastName , p.FirstNameFROM HumanResources.Employee eJOIN Person.Person p ON e.BusinessEntityID =p.BusinessEntityIDThe fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ...Table 'Employee'. Scan count 1, logical reads 2, ...Table 'Person'. Scan count 0, logical reads 888, ...Table 'Employee'. Scan count 1, logical reads 2, ...SubQuery
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
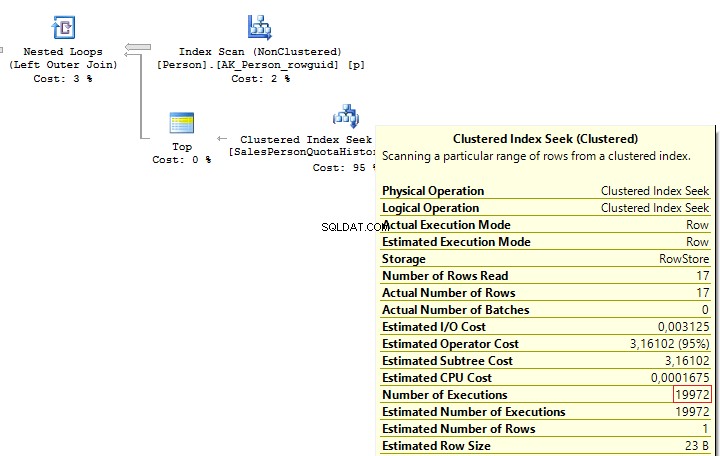
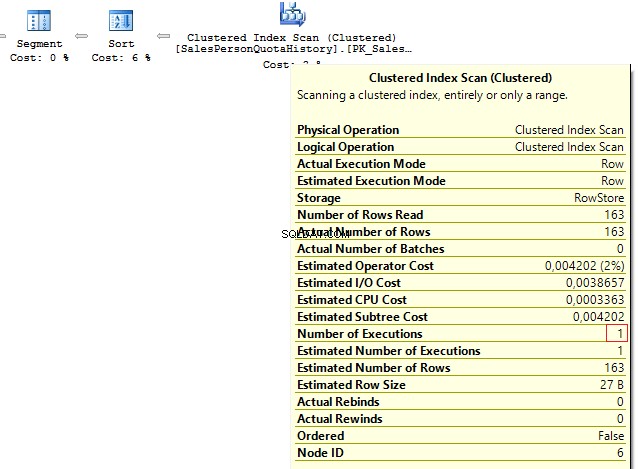
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT p.BusinessEntityID , ( SELECT s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID )FROM Person.Person pHowever, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <=,>,>=or when the subquery is used as an expression.It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
SELECT p.BusinessEntityID , ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC )FROM Person.Person pSELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pOUTER APPLY ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC) tWhen executing these queries, we will get the same issue – multiple IndexSeek operators:
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ...Table 'Person'. Scan count 1, logical reads 67, ...Re-write this query with a window function:
SELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pLEFT JOIN ( SELECT s.BusinessEntityID , s.SalesQuota , RowNum =ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC) FROM Sales.SalesPersonQuotaHistory s) t ON p.BusinessEntityID =t.BusinessEntityID AND t.RowNum =1We get the following result:
Table 'Person'. Scan count 1, logical reads 67, ...Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014GOSELECT BusinessEntityID , Gender , Gender =CASE Gender WHEN 'M' THEN 'Male' WHEN 'F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.EmployeeSQL Server will decompose the statement to the following:
SELECT BusinessEntityID , Gender , Gender =CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.EmployeeThus, this will lead to the main issue:each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL DROP FUNCTION dbo.GetMailUrlGOCREATE FUNCTION dbo.GetMailUrl( @Email NVARCHAR(50))RETURNS NVARCHAR(50)AS BEGIN RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))ENDThen, configure SQL Profiler to build SQL events:StmtStarting / SP:StmtCompleted (if you want to do this with XEvents :sp_statement_starting / sp_statement_completed ).
Execute the query:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) --WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddressThe function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddressIn this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID , EmailAddress , CASE MailUrl WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM ( SELECT TOP(10) EmailAddressID , EmailAddress , MailUrl =dbo.GetMailUrl(EmailAddress) FROM Person.EmailAddress) tIn this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='M' THEN '...' WHEN Gender ='M' THEN '......' WHEN Gender ='F' THEN 'Female' WHEN Gender ='F' THEN '...' ELSE 'Unknown' ENDFROM HumanResources.EmployeeThough statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE 1/0 ENDGODECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE MIN(1/0) ENDScalar func
It is not recommended to use scalar functions in T-SQL queries.
Consider the following example:
USE AdventureWorks2014GOUPDATE TOP(1) Person.[Address]SET AddressLine2 =AddressLine1GOIF OBJECT_ID('dbo.isEqual') IS NOT NULL DROP FUNCTION dbo.isEqualGOCREATE FUNCTION dbo.isEqual( @val1 NVARCHAR(100), @val2 NVARCHAR(100))RETURNS BITAS BEGIN RETURN CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 =@val2 THEN 1 ELSE 0 ENDENDThe queries return the identical data:
SET STATISTICS TIME ONSELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE dbo.IsEqual(AddressLine1, AddressLine2) =1SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL) OR AddressLine1 =AddressLine2SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE AddressLine1 =ISNULL(AddressLine2, '')SET STATISTICS TIME OFFHowever, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times:CPU time =63 ms, elapsed time =57 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL DROP FUNCTION dbo.GetPIGOCREATE FUNCTION dbo.GetPI ()RETURNS FLOATWITH SCHEMABINDINGAS BEGIN RETURN PI()ENDGOSELECT dbo.GetPI()FROM Sales.CurrencyIn this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL DROP TABLE dbo.tblGOCREATE TABLE dbo.tbl (a INT, b INT)GOINSERT INTO dbo.tbl VALUES (0, 1)GOIF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL DROP VIEW dbo.vw_tblGOCREATE VIEW dbo.vw_tblAS SELECT * FROM dbo.tblGOSELECT * FROM dbo.vw_tblAs you can see, we get the correct result:
a b----------- -----------0 1Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl ADD c INT NOT NULL DEFAULT 2GOSELECT * FROM dbo.vw_tblWe receive the same result:
a b----------- -----------0 1Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname =N'dbo.vw_tbl'GOSELECT * FROM dbo.vw_tblResult:
a b c----------- ----------- -----------0 1 2When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
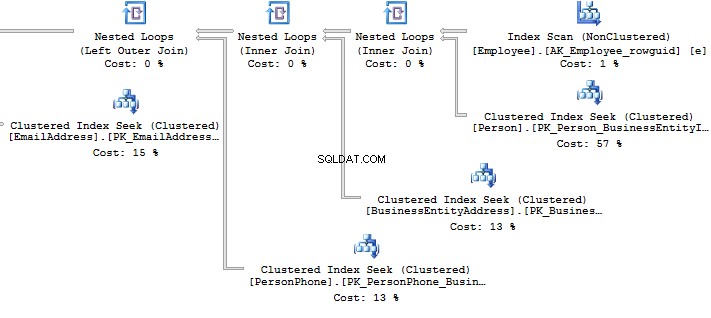
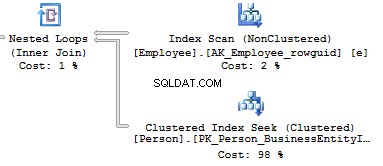
ALTER VIEW HumanResources.vEmployeeAS SELECT e.BusinessEntityID , p.Title , p.FirstName , p.MiddleName , p.LastName , p.Suffix , e.JobTitle , pp.PhoneNumber , pnt.[Name] AS PhoneNumberType , ea.EmailAddress , p.EmailPromotion , a.AddressLine1 , a.AddressLine2 , a.City , sp.[Name] AS StateProvinceName , a.PostalCode , cr.[Name] AS CountryRegionName , p.AdditionalContactInfo FROM HumanResources.Employee e JOIN Person.Person p ON p.BusinessEntityID =e.BusinessEntityID JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID =e.BusinessEntityID JOIN Person.[Address] a ON a.AddressID =bea.AddressID JOIN Person.StateProvince sp ON sp.StateProvinceID =a.StateProvinceID JOIN Person.CountryRegion cr ON cr.CountryRegionCode =sp.CountryRegionCode LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID =p.BusinessEntityID LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID =pnt.PhoneNumberTypeID LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID =ea.BusinessEntityIDWhat should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
SELECT BusinessEntityID , FirstName , LastNameFROM HumanResources.vEmployeeSELECT p.BusinessEntityID , p.FirstName , p.LastNameFROM Person.Person pWHERE p.BusinessEntityID IN ( SELECT e.BusinessEntityID FROM HumanResources.Employee e )Look at the execution plan in the case of using a view:
Table 'EmailAddress'. Scan count 290, logical reads 640, ...Table 'PersonPhone'. Scan count 290, logical reads 636, ...Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ...Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...Now, we will compare it with the query we have written manually:
Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INTDECLARE cur CURSOR FOR SELECT BusinessEntityID FROM HumanResources.EmployeeOPEN curFETCH NEXT FROM cur INTO @BusinessEntityIDWHILE @@FETCH_STATUS =0 BEGIN UPDATE HumanResources.Employee SET VacationHours =0 WHERE BusinessEntityID =@BusinessEntityID FETCH NEXT FROM cur INTO @BusinessEntityIDENDCLOSE curDEALLOCATE curThough, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.EmployeeSET VacationHours =0WHERE VacationHours <> 0In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT could be used. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL DROP TABLE #tGOCREATE TABLE #t (i CHAR(1))INSERT INTO #tVALUES ('1'), ('2'), ('3')Then, assign values to the variable:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tSELECT @txt--------123Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tORDER BY LEN(i)SELECT @txt--------3Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] =iFROM #tFOR XML PATH('')--------123It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'------------------------ ------------------------------------ScrapReason ScrapReasonID, Name, ModifiedDateShift ShiftID, Name, StartTime, EndTimeIn addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name , STUFF(( SELECT ', ' + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name , STUFF(( SELECT ', ' + CHAR(13) + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’… .
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX)SET @param =1DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =' + @paramPRINT @SQLEXEC (@SQL)Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1If we add any additional value to the property,
SET @param ='1; select ''hack'''Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1; select 'hack'This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id ={0}", value), conn); using (SqlDataReader reader =command.ExecuteReader()) { while (reader.Read()) {} }}When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)SET @param ='1; select ''hack'''DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id'PRINT @SQLEXEC sys.sp_executesql @SQL , N'@schema_id INT' , @schema_id =@paramIt is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( "SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id", conn); command.Parameters.Add(new SqlParameter("schema_id", value)); ...}Zusammenfassung
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.