Einführung in SQL Server-Indizes
Microsoft SQL Server gilt als eines der Managementsysteme für relationale Datenbanken (RDBMS ), in der die Daten logisch in Zeilen und Spalten organisiert sind, die in Datencontainern namens Tabellen gespeichert sind. Physisch werden die Tabellen als Seiten von 8 KB gespeichert die in Heap- oder B-Tree-Cluster-Tabellen organisiert werden können. Im Haufen Tabelle, gibt es keine Sortierreihenfolge, die die Reihenfolge der Daten innerhalb der Datenseiten und die Reihenfolge der Seiten innerhalb dieser Tabelle steuert, da für diese Tabelle kein Clustered-Index definiert ist, um den Sortiermechanismus zu erzwingen. Wenn ein Clustered-Index für eine Spalte der Gruppe von Tabellenspalten definiert ist, werden die Daten innerhalb der Datenseiten basierend auf den Werten der Schlüsselspalten des Clustered-Index sortiert, und die Seiten werden basierend auf diesen Indexschlüsselwerten miteinander verknüpft. Diese sortierte Tabelle wird als Cluster-Tabelle bezeichnet .
In SQL Server gilt der Index als wichtiger und effektiver Schlüssel im Leistungsoptimierungsprozess. Der Zweck der Indexerstellung besteht darin, den Zugriff auf die Basistabelle zu beschleunigen und die angeforderten Daten abzurufen, ohne alle Tabellenzeilen durchsuchen zu müssen, um die angeforderten Daten zurückzugeben. Sie können sich den Datenbankindex als einen Buchindex vorstellen, der Ihnen hilft, die Wörter im Buch schnell zu finden, ohne das ganze Buch lesen zu müssen, um dieses Wort zu finden. Angenommen, Sie müssen mithilfe einer Kunden-ID Informationen zu einem bestimmten Kunden abrufen. Wenn für die Spalte Kunden-ID in dieser Tabelle kein Index definiert ist, prüft die SQL Server-Engine nacheinander alle Tabellenzeilen, um den Kunden mit der bereitgestellten ID abzurufen. Wenn ein Index für die Kunden-ID-Spalte in dieser Tabelle definiert ist, sucht die SQL Server-Engine nach den angeforderten Kunden-ID-Werten im sortierten Index und nicht in der Basistabelle, um Informationen über den Kunden abzurufen, wodurch die Anzahl der gescannten Daten reduziert wird Zeilen, um die Daten abzurufen.
In SQL Server ist der Index logisch als 8K-Seiten oder Indexknoten in Form einer B-Struktur strukturiert. Die B-Tree-Struktur enthält drei Ebenen:eine Root-Ebene Dazu gehört eine Indexseite ganz oben im B-Baum, eine Blattebene die sich am Ende des B-Baums befindet und Datenseiten und eine Zwischenebene enthält die alle zwischen der Wurzel- und der Blattebene befindlichen Knoten mit Indexschlüsselwerten und Zeigern auf die folgenden Seiten enthält. Diese B-Baumform bietet eine schnelle Möglichkeit, basierend auf dem Indexschlüssel von links nach rechts und von oben nach unten durch die Datenseiten zu navigieren.
In SQL Server gibt es zwei Haupttypen von Indizes, einen Clustered-Index in dem die tatsächlichen Daten auf den Blattebenenseiten des Index gespeichert werden, mit der Möglichkeit, nur einen gruppierten Index für jede Tabelle zu erstellen, da die Daten innerhalb der Datenseiten und die Reihenfolge der Seiten basierend auf dem gruppierten Index sortiert werden Schlüssel. Wenn Sie in Ihrer Tabelle eine Primärschlüsseleinschränkung definieren, wird automatisch ein Clustered-Index erstellt, wenn zuvor kein Clustered-Index für diese Tabelle definiert wurde. Der zweite Indextyp ist ein Non-Clustered-Index die eine sortierte Kopie der Indexschlüsselspalten und einen Zeiger auf die restlichen Spalten in der Basistabelle oder dem Clustered-Index enthält, mit der Möglichkeit, bis zu 999 Non-Clustered-Indizes für jede Tabelle zu erstellen.
SQL Server stellt uns andere spezielle Arten von Indizes zur Verfügung, z. B. einen eindeutigen Index der automatisch erstellt wird, wenn eine Eindeutigkeitsbeschränkung definiert wird, um die Eindeutigkeit bestimmter Spaltenwerte zu erzwingen, ein zusammengesetzter Index in dem mehr als eine Schlüsselspalte am Indexschlüssel teilnimmt, ein überdeckender Index in dem alle Spalten, die von einer bestimmten Abfrage angefordert werden, Teil des Indexschlüssels sind, ein gefilterter Index das ist ein optimierter Non-Clustered-Index mit einem Filterprädikat zum Indizieren nur eines kleinen Teils der Tabellenzeilen, ein Räumlicher Index der für die Spalten erstellt wird, die räumliche Daten speichern, ein XML-Index, der für XML-BLOBs (Binary Large Objects) in Spalten des XML-Datentyps erstellt wird, ein Columnstore-Index in dem Daten in einem Spaltendatenformat organisiert sind, ein Volltextindex der von der SQL Server-Volltext-Engine erstellt wird, und einen Hash-Index die in speicheroptimierten Tabellen verwendet wird.
Wie ich den SQL Server-Index früher nannte, ist dies ein zweischneidiges Schwert , wo der SQL Server-Abfrageoptimierer von dem gut entwickelten Index profitieren kann, um die Leistung Ihrer Anwendungen zu verbessern, indem der Datenabrufprozess beschleunigt wird. Im Gegensatz dazu wird ein schlecht entworfener Index vom SQL Server-Abfrageoptimierer nicht ausgewählt und verschlechtert die Leistung Ihrer Anwendungen, indem er die Datenänderungsvorgänge verlangsamt und Ihren Speicherplatz verbraucht, ohne ihn in den Daten zu nutzen Abrufprozesse. Daher ist es besser, zuerst die Best Practices und Richtlinien für die Indexerstellung zu befolgen, die Auswirkungen bei der Erstellung eines Index auf die Entwicklungsumgebung zu prüfen und einen Kompromiss zwischen der Geschwindigkeit der Datenabrufvorgänge und dem Aufwand für das Hinzufügen dieses Index zu den Datenänderungsvorgängen zu finden und die Platzanforderungen dieses Index, bevor Sie ihn auf die Produktionsumgebung anwenden.
Bevor Sie einen Index erstellen, müssen Sie die verschiedenen Aspekte untersuchen, die sich auf die Erstellung und Verwendung des Index auswirken. Dazu gehört der Typ der Datenbankauslastung, Online Transaction Processing (OLTP) oder Online Analytical Processing (OLAP), die Größe der Tabelle , die Eigenschaften der Tabellenspalten , die Sortierreihenfolge der Spalten in der Abfrage, der Indextyp das entspricht der Abfrage und den Speichereigenschaften wie dem FILLFACTOR und PAD_INDEX Optionen, die den Prozentsatz des Platzes auf jeder Blattebene und den mit Daten zu füllenden Seiten der Zwischenebene steuern.
SQL Server-Indexfragmentierung
Ihre Arbeit als DBA beschränkt sich nicht nur auf die Erstellung des richtigen Index. Sobald der Index erstellt ist, sollten Sie die Indexnutzung und Statistiken überwachen, zum Beispiel müssen Sie wissen, ob dieser Index schlecht oder überhaupt nicht verwendet wird. So können Sie die richtige Lösung bereitstellen, um diese Indizes zu pflegen oder durch effizientere zu ersetzen. Auf diese Weise erhalten Sie die höchstmögliche Leistung für Ihr System. Sie fragen sich vielleicht:Warum verwendet der SQL Server Query Optimizer meinen Index nicht mehr, obwohl er das vorher getan hat?
Die Antwort bezieht sich hauptsächlich auf die kontinuierlichen Daten- und Schemaänderungen, die an der Basistabelle vorgenommen werden und sich in den Indizes widerspiegeln sollten. Im Laufe der Zeit und mit all diesen Änderungen werden die Indexseiten unsortiert, wodurch der Index fragmentiert wird. Ein weiterer Grund für die Fragmentierung ist ein Versuch, einen neuen Wert einzufügen oder den aktuellen Wert zu aktualisieren, und der neue Wert passt nicht in den derzeit verfügbaren freien Speicherplatz. In diesem Fall wird die Seite in zwei Seiten aufgeteilt, wobei die neue Seite physisch nach der letzten Seite erstellt wird. Und Sie können sich vorstellen, aus einem fragmentierten Index die Anzahl der Seiten zu lesen, die gescannt werden sollten, und natürlich die Anzahl der E/A-Vorgänge, die zum Abrufen mehrerer Datensätze aufgrund der Entfernung zwischen diesen Seiten ausgeführt werden. Und wegen der zusätzlichen Kosten für die Verwendung dieses fragmentierten Index ignoriert der SQL Server-Abfrageoptimierer diesen Index.
Verschiedene Methoden zur Indexfragmentierung
SQL Server bietet uns verschiedene Möglichkeiten, den Prozentsatz der Indexfragmentierung zu ermitteln. Die erste Möglichkeit besteht darin, den Prozentsatz der Indexfragmentierung im Index zu überprüfen Eigenschaften Fenster unter Fragmentierung Registerkarte, wie unten gezeigt:
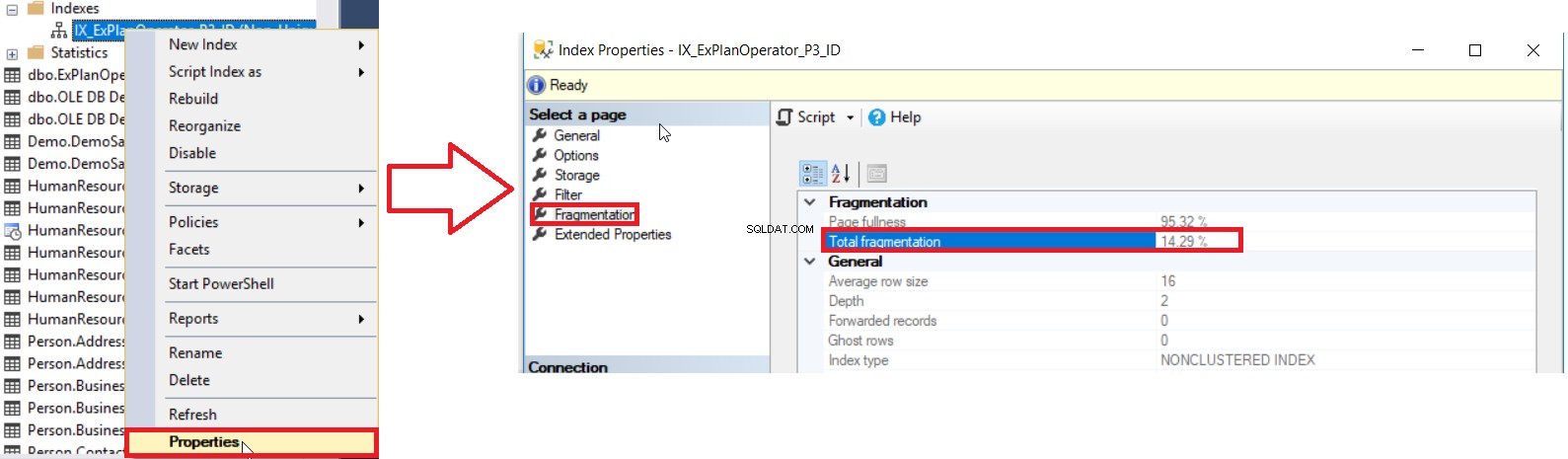
Aber um den Fragmentierungsgrad mehrerer Indizes zu überprüfen, müssen Sie zuerst die UI-Methodenprüfung für alle Indizes nacheinander durchführen, was eine zeitraubende Operation ist. Die zweite verfügbare Methode zum Überprüfen des Fragmentierungsgrades aller Datenbankindizes besteht darin, die DMF sys.dm_db_index_physical_stats abzufragen und mit der DMV sys.indexes zu verknüpfen, um alle Informationen zu diesen Indizes abzurufen, wobei zu berücksichtigen ist, dass diese Statistiken aktualisiert werden, wenn die Der SQL Server-Dienst wird mit einer Abfrage ähnlich der folgenden neu gestartet:
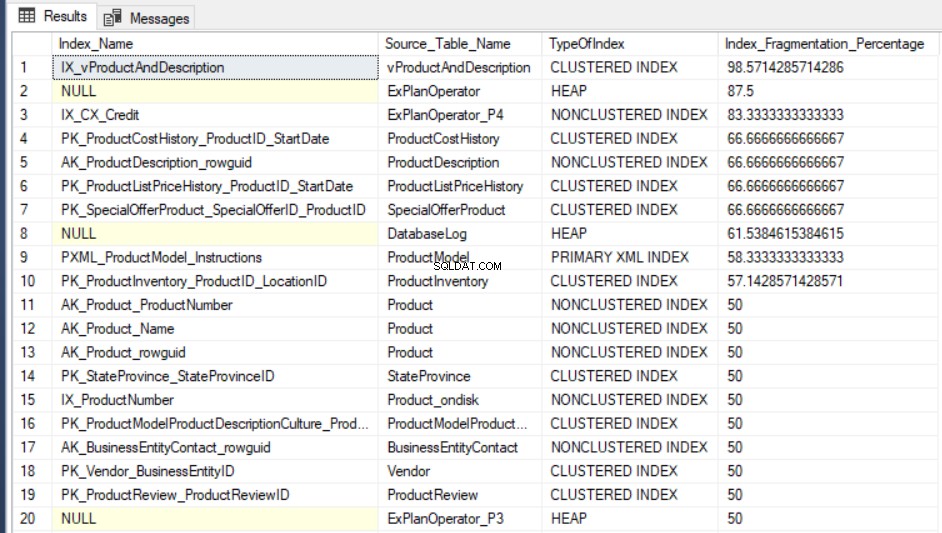
SELECT Indx.name AS Index_Name, OBJECT_NAME(Indx.OBJECT_ID) AS Source_Table_Name, Index_Stat.index_type_desc AS TypeOfIndex, Index_Stat.avg_fragmentation_in_percent Index_Fragmentation_Percentage FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) Index_Stat INNER JOIN sys.indexes Indx ON Indx.object_id = Index_Stat.object_id AND Indx.index_id = Index_Stat.index_id ORDER BY Index_Fragmentation_Percentage DESC
Das Ausgabeergebnis der Abfrage von AdventureWorks2016CTP3 Testing-Datenbank sieht etwa so aus:
Die dritte Methode zum Abrufen des Prozentsatzes der Fragmentierung besteht darin, den in SQL Server integrierten Standardbericht mit dem Namen Index Physical Statistics zu verwenden. Dieser Bericht gibt nützliche Informationen über die Indexpartitionen, den Fragmentierungsprozentsatz, die Anzahl der Seiten auf jeder Indexpartition und Empfehlungen zur Behebung des Indexfragmentierungsproblems durch Neuerstellung oder Neuorganisation des Index zurück. Um den Bericht anzuzeigen, klicken Sie mit der rechten Maustaste auf Ihre Datenbank, wählen Sie die Option „Berichte“, „Standardberichte“ und wählen Sie „Physische Statistiken indizieren“ wie folgt:
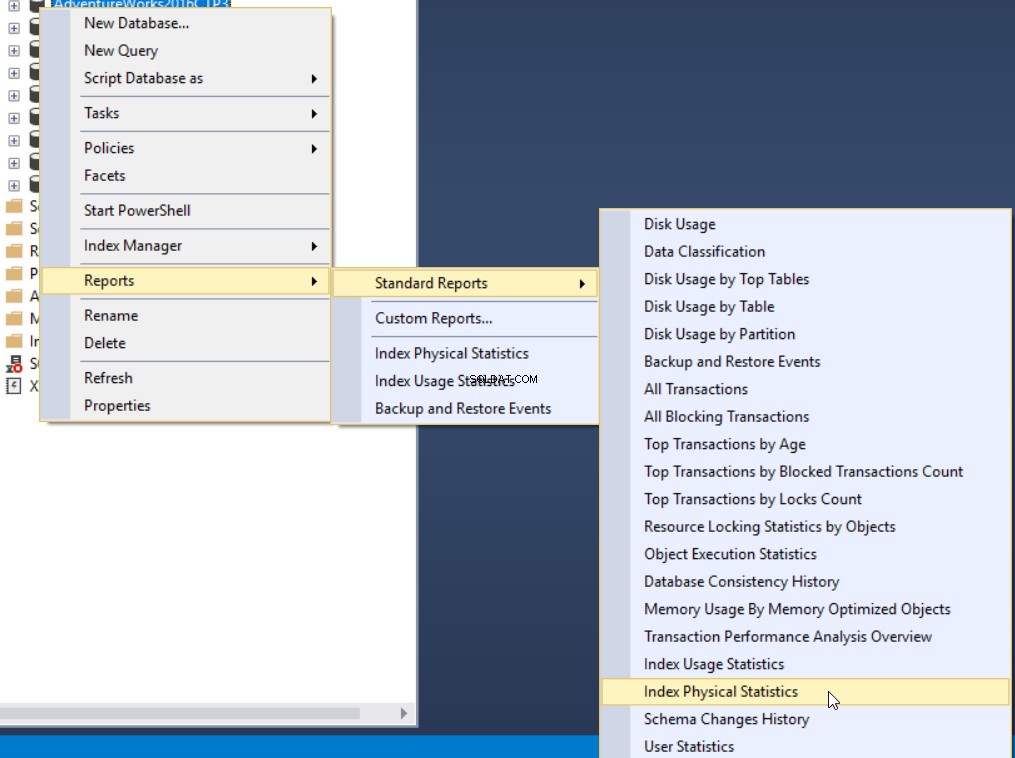
In unserem Fall sieht der generierte Bericht so aus:
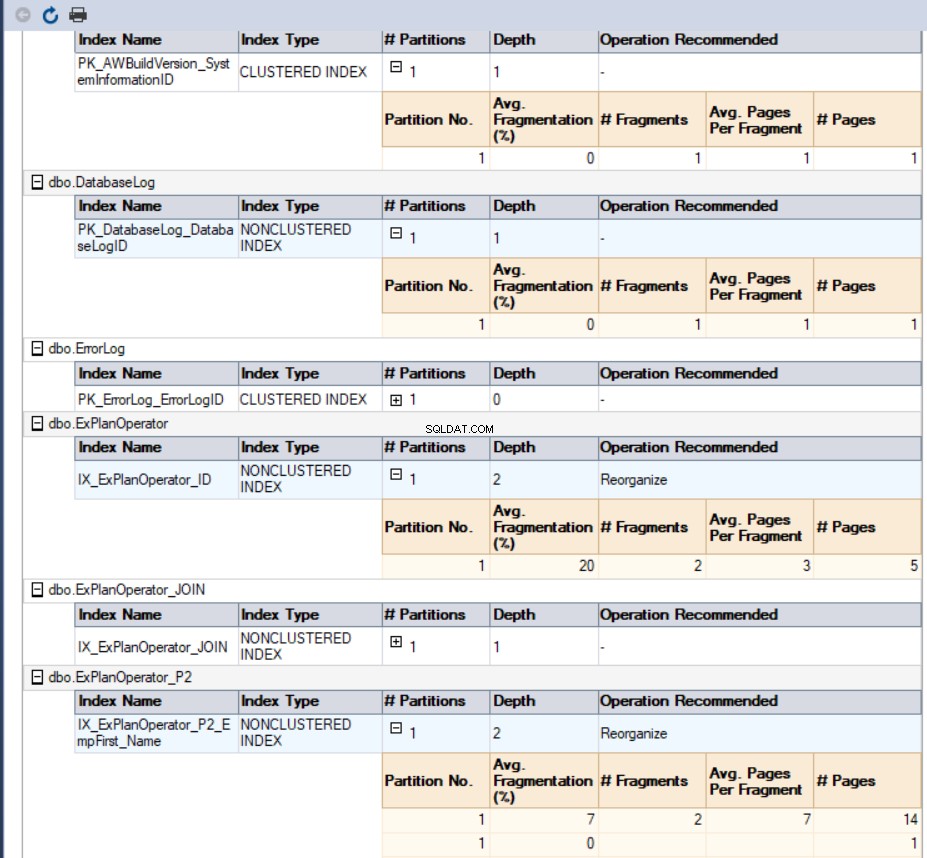
Die letzte und einfachste Möglichkeit, den Fragmentierungsprozentsatz aller Datenbankindizes abzurufen, ist das Tool dbForge Index Manager. Der dbForge Index Manager Tool ist ein Add-In, das Ihrem SQL Server Management Studio hinzugefügt werden kann, um die Indexe der SQL Server-Datenbanken zu analysieren, und Ihnen einen sehr nützlichen Bericht mit dem Status der ausgewählten Datenbankindizes und Wartungsvorschlägen zur Behebung dieser Indexfragmentierungsprobleme liefert.
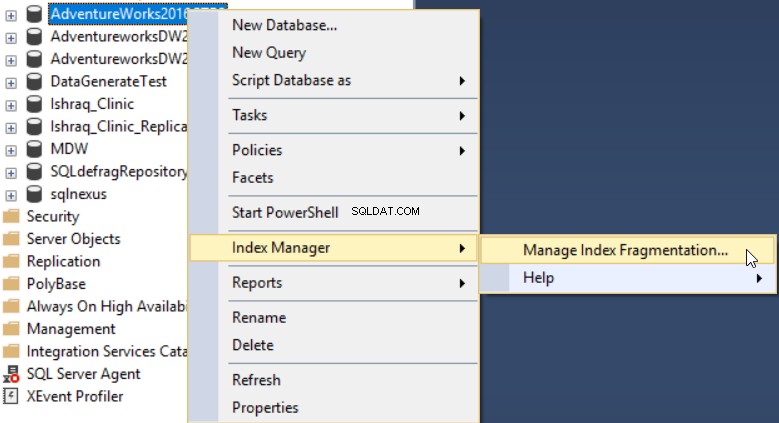
Nach der Installation des dbForge Index Manager-Add-Ins in Ihrem SSMS können Sie es ausführen, indem Sie mit der rechten Maustaste auf die zu scannende Datenbank klicken und Index Manager auswählen , dann Indexfragmentierung verwalten wie unten gezeigt:
Das dbForge Index Manager-Tool ermöglicht es Ihnen, sich ein Gesamtbild der Fragmentierung der ausgewählten Datenbankindizes zu verschaffen, mit Empfehlungen für die richtigen Maßnahmen zur Behebung dieses Problems, wie unten gezeigt:

Das dbForge Index Manager-Tool ermöglicht Ihnen auch, zwischen Datenbanken zu wechseln, und liefert Ihnen nach dem Scannen dieser Datenbank einen neuen Bericht, wie unten gezeigt:
Der vom dbForge Index Manager-Tool generierte Indexfragmentierungsbericht kann in eine CSV-Datei exportiert werden, um den Indexfragmentierungsstatus zu analysieren, wie unten gezeigt:
Mit dbForge Index Manager können Sie T-SQL-Skripte generieren, um die Indizes gemäß der Tool-Empfehlung neu zu erstellen oder zu reorganisieren. Verwenden Sie die Skriptänderungen Option zum Anzeigen oder Speichern des Skripts für die fragmentierten Indizes, wie unten gezeigt:
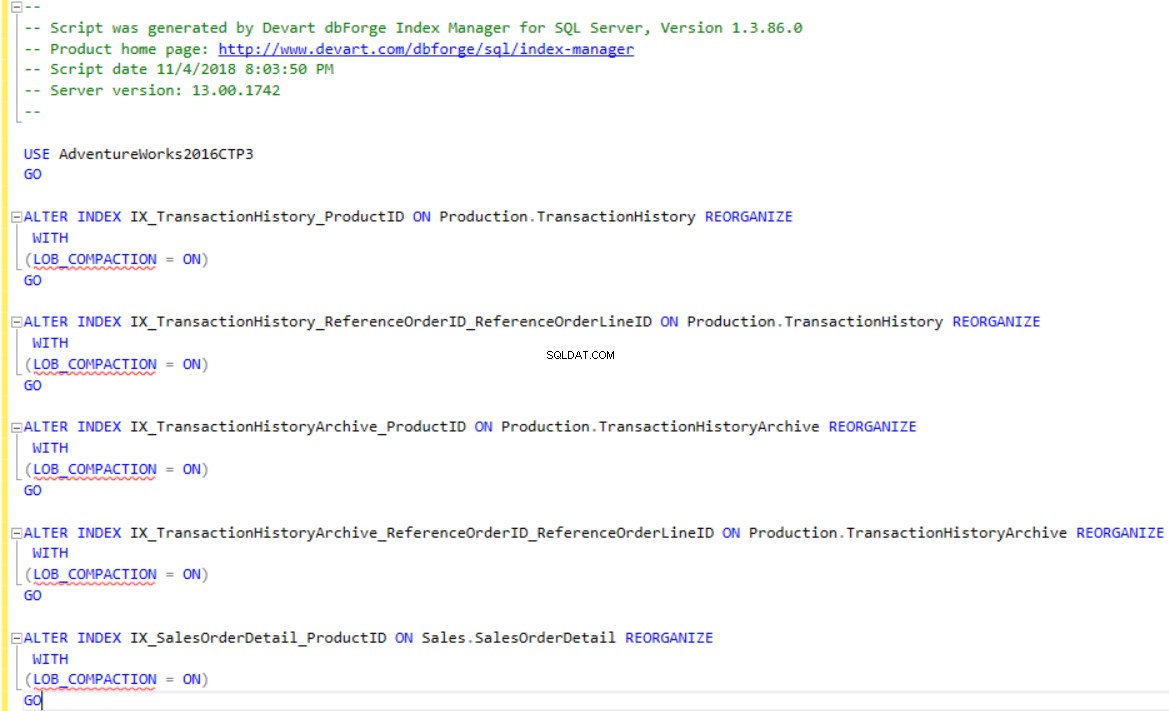
Das Tool dbForge Index Manager bietet Ihnen die Möglichkeit, das Indexfragmentierungsproblem direkt zu beheben, indem Sie auf Fixieren klicken Schaltfläche, die die empfohlene Aktion direkt für die ausgewählten Indizes durchführt und den Korrekturstatus im Ergebnis anzeigt Spalte wie unten gezeigt:

Wenn Sie auf Erneut analysieren klicken klicken, scannt es die Indexfragmentierung in der Datenbank erneut, nachdem der Korrekturvorgang erfolgreich durchgeführt wurde. Was hier in diesem Artikel aufgeführt ist, ist nur eine Einführung, wie uns das dbForge Index Manager-Tool bei der Identifizierung und Behebung von Indexfragmentierungsproblemen helfen wird. Meine Empfehlung für Sie ist, es herunterzuladen und zu prüfen, was dieses Tool Ihnen bieten kann.
Nützliche Links:
- Indexgrundlagen
- Indexarten
- Clustered und Nonclustered Indizes beschrieben
- Clustered-Index-Strukturen
Nützliches Tool:
dbForge Index Manager – praktisches SSMS-Add-in zum Analysieren des Status von SQL-Indizes und Beheben von Problemen mit der Indexfragmentierung.