Eine virtuelle IP-Adresse ist eine IP-Adresse, die keiner tatsächlichen physischen Netzwerkschnittstelle entspricht. Es schwebt zwischen mehreren Netzwerkschnittstellen und nur eine aktive Schnittstelle hält die IP-Adresse für Fehlertoleranz und Mobilität. ClusterControl verwendet Keepalived, um die Integration virtueller IP-Adressen mit Datenbank-Load-Balancern bereitzustellen, um jeden Single Point of Failure (SPOF) auf Load-Balancer-Ebene zu eliminieren.
In diesem Blogbeitrag zeigen wir Ihnen, wie ClusterControl virtuelle IP-Adressen konfiguriert und was Sie erwarten können, wenn ein Failover oder Failback stattfindet. Das Verständnis dieses Verhaltens ist entscheidend, um Serviceunterbrechungen zu minimieren und Wartungsarbeiten, die gelegentlich durchgeführt werden müssen, reibungsloser zu gestalten.
Anforderungen
Es gibt einige Anforderungen, um Keepalived in Ihrem Netzwerk auszuführen:
- Das IP-Protokoll 112 (Virtual Router Redundancy Protocol - VRRP) muss im Netzwerk unterstützt werden. Einige Netzwerke deaktivieren die Unterstützung für VRRP, insbesondere die Kommunikation zwischen VLANs. Bitte überprüfen Sie dies mit dem Netzwerkadministrator.
- Wenn Sie Multicast verwenden, muss das Netzwerk Multicast-Anforderungen unterstützen (verwenden Sie ip a | grep -i multicast). Andernfalls können Sie Unicast über unicast_src_ip verwenden und unicast_peer Optionen. Die Verwendung von Multicast ist nützlich, wenn Sie eine dynamische Umgebung wie eine Cloud-Umgebung haben oder wenn die IP-Zuweisung über DHCP erfolgt.
- Ein Satz von VRRP-Instanzen muss eine eindeutige virtual_router_id verwenden Wert, der nicht von anderen Instanzen geteilt werden kann. Andernfalls werden Sie falsche Pakete sehen und wahrscheinlich die Master-Backup-Umschaltung unterbrechen.
- Wenn Sie in einer Cloud-Umgebung wie AWS arbeiten, müssen Sie wahrscheinlich ein externes Skript verwenden (Hinweis:Verwenden Sie die Option „benachrichtigen“), um die virtuelle IP-Adresse (Elastic IP) zu trennen und zuzuordnen, damit sie erkannt und geroutet werden kann den Router.
Bereitstellen von Keepalived
Um Keepalived über ClusterControl zu installieren, benötigen Sie zwei oder mehr Load Balancer, die von ClusterControl installiert oder in ClusterControl importiert wurden. Für die Produktionsnutzung empfehlen wir dringend, die Load Balancer-Software auf einem eigenständigen Host auszuführen und nicht zusammen mit Ihren Datenbankknoten.
Nachdem Sie mindestens zwei Load Balancer von ClusterControl verwaltet haben, um Keepalived zu installieren und die virtuelle IP-Adresse zu aktivieren, gehen Sie einfach zu ClusterControl -> Cluster auswählen -> Verwalten -> Load Balancer -> Keepalived:
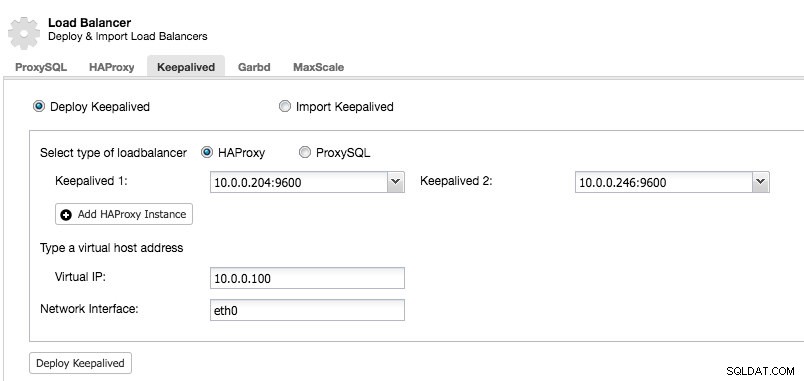
Die meisten Felder sind selbsterklärend. Sie können einen neuen Satz von Keepalived bereitstellen oder vorhandene Keepalived-Instanzen importieren. Zu den wichtigen Feldern gehören die tatsächliche virtuelle IP-Adresse und die Netzwerkschnittstelle, an der die virtuelle IP-Adresse existieren wird. Wenn die Hosts zwei verschiedene Schnittstellennamen verwenden, geben Sie den Schnittstellennamen des Keepalived 1-Hosts an und ändern Sie die Konfigurationsdatei auf Keepalived 2 später manuell mit einem korrekten Schnittstellennamen.
VRRP-Instanz
Zum jetzigen Zeitpunkt installiert ClusterControl v1.5.1 Keepalived v1.3.5 (abhängig vom Host-Betriebssystem) und Folgendes ist für die VRRP-Instanz konfiguriert:
vrrp_instance VI_PROXYSQL {
interface eth0 # interface to monitor
state MASTER
virtual_router_id 51 # Assign one ID for this route
priority 100
unicast_src_ip 10.0.0.246
unicast_peer {
10.0.0.204
}
virtual_ipaddress {
10.0.0.100 # the virtual IP
}
track_script {
chk_proxysql
}
# notify /usr/local/bin/notify_keepalived.sh
}ClusterControl konfiguriert die VRRP-Instanz für die Kommunikation über Unicast. Bei Unicast müssen wir alle Unicast-Peers der anderen Keepalived-Knoten definieren. Es ist weniger dynamisch, funktioniert aber die meiste Zeit. Mit Multicast können Sie diese Zeilen (unicast_*) entfernen und sich für die Hosterkennung und das Peering auf die Multicast-IP-Adresse verlassen. Es ist einfacher, wird aber häufig von Netzwerkadministratoren blockiert.
Der nächste Teil ist die virtuelle IP-Adresse. Sie können mehrere virtuelle IP-Adressen pro VRRP-Instanz angeben, getrennt durch eine neue Zeile. Load Balancing in HAProxy/ProxySQL und Keepalived erfordert gleichzeitig auch die Fähigkeit, sich an eine nicht lokale IP-Adresse zu binden, was bedeutet, dass sie keinem Gerät auf dem lokalen System zugewiesen ist. Dadurch kann eine ausgeführte Load-Balancer-Instanz für ein Failover an eine IP gebunden werden, die nicht lokal ist. Daher konfiguriert ClusterControl auch net.ipv4.ip_nonlocal_bind=1 in /etc/sysctl.conf.
Die nächste Direktive ist das track_script , wo Sie das Skript für den Zustandsprüfungsprozess angeben können, der im nächsten Abschnitt erläutert wird.
Zustandsprüfungen
ClusterControl konfiguriert Keepalived so, dass Zustandsprüfungen durchgeführt werden, indem der vom track_script zurückgegebene Fehlercode untersucht wird. In der Keepalived-Konfigurationsdatei, die sich standardmäßig unter /etc/keepalived/keepalived.conf befindet, sollten Sie etwa Folgendes sehen:
track_script {
chk_proxysql
}Wo es chk_proxysql aufruft, das Folgendes enthält:
vrrp_script chk_proxysql {
script "killall -0 proxysql" # verify the pid existence
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}Der Befehl „killall -0“ gibt den Exit-Code 0 zurück, wenn auf dem Host ein Prozess namens „proxysql“ läuft. Andernfalls müsste sich die Instanz selbst herabstufen und mit dem Initiieren des Failovers beginnen, wie im nächsten Abschnitt erläutert. Beachten Sie, dass Keepalived auch Linux Virtual Server (LVS)-Komponenten unterstützt, um Zustandsprüfungen durchzuführen, wo es auch in der Lage ist, TCP/IP-Verbindungen auszugleichen, ähnlich wie HAProxy, aber das geht über den Rahmen dieses Blogbeitrags hinaus.
Failover simulieren
Für VRRP-Komponenten verwendet Keepalived das VRRP-Protokoll (IP-Protokoll 112), um zwischen VRRP-Instanzen zu kommunizieren. Der höhere Prioritätswert eines MASTERS bedeutet, dass der Master immer das höhere Privileg hat, die virtuelle IP-Adresse zu halten, es sei denn, Sie konfigurieren die Instanz mit „nopreempt“. Lassen Sie uns ein Beispiel verwenden, um den Failover- und Failback-Fluss besser zu erklären. Betrachten Sie das folgende Diagramm:
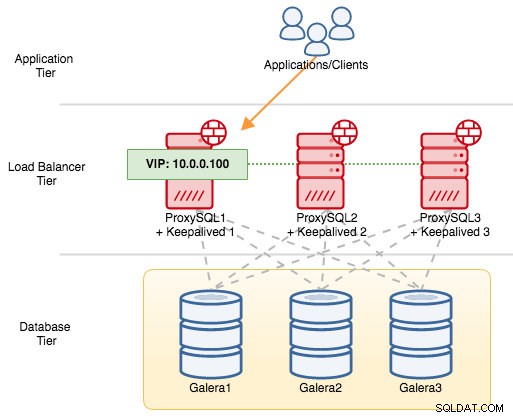
Es gibt drei ProxySQL-Instanzen vor drei MySQL Galera-Knoten. Jeder ProxySQL-Host wird mit Keepalived als MASTER mit der folgenden Prioritätsnummer konfiguriert:
- ProxySQL1 - Priorität 101
- ProxySQL2 - Priorität 100
- ProxySQL3 - Priorität 99
Wenn Keepalived als MASTER gestartet wird, gibt es den Mitgliedern zuerst die Prioritätsnummer bekannt und ordnet sich dann der virtuellen IP-Adresse zu. Im Gegensatz zur BACKUP-Instanz beobachtet sie nur die Werbung und weist die virtuelle IP-Adresse erst zu, wenn sie bestätigt hat, dass sie sich selbst zum MASTER erheben kann.
Beachten Sie, dass, wenn Sie den „proxysql“- oder „haproxy“-Prozess manuell über den Befehl „kill“ beenden, der systemd-Prozessmanager standardmäßig versucht, den Prozess wiederherzustellen, der nicht ordnungsgemäß gestoppt wurde. Wenn Sie die automatische Wiederherstellung von ClusterControl aktiviert haben, wird ClusterControl immer versuchen, den Prozess zu starten, selbst wenn Sie ein sauberes Herunterfahren über systemd durchführen (systemctl stop proxysql). Um den Fehler bestmöglich zu simulieren, empfehlen wir dem Benutzer, die automatische Wiederherstellungsfunktion von ClusterControl zu deaktivieren oder einfach den ProxySQL-Server herunterzufahren, um die Kommunikation zu unterbrechen.
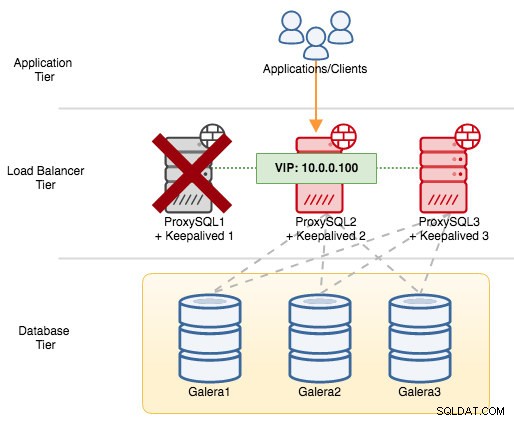
Wenn wir ProxySQL1 herunterfahren, wird die virtuelle IP-Adresse auf den nächsten Host umgeleitet, der zu diesem bestimmten Zeitpunkt die höhere Priorität hat (das ist ProxySQL2):
Im Syslog des ausgefallenen Knotens würden Sie Folgendes sehen:
Feb 27 05:21:59 proxysql1 systemd: Unit proxysql.service entered failed state.
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: /usr/bin/killall -0 proxysql exited with status 1
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) failed
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 103 to 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 102, ours 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.Auf dem sekundären Knoten ist Folgendes passiert:
Feb 27 05:22:00 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:22:01 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 avahi-daemon[346]: Registering new address record for 10.0.0.100 on eth0.IPv4.In diesem Fall dauerte das Failover etwa 3 Sekunden, wobei die maximale Failover-Zeit Intervall wäre + advert_int . Hinter den Kulissen hat sich der Datenbankendpunkt geändert und der Datenbankdatenverkehr wird über ProxySQL2 geleitet, ohne dass Anwendungen dies bemerken.
Wenn ProxySQL1 wieder online geht, erzwingt er eine neue MASTER-Wahl und übernimmt die IP-Adresse aufgrund höherer Priorität:
Feb 27 05:38:34 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) succeeded
Feb 27 05:38:35 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 101 to 103
Feb 27 05:38:36 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:38:37 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 avahi-daemon[343]: Registering new address record for 10.0.0.100 on eth0.IPv4.Gleichzeitig degradiert ProxySQL2 sich selbst in den Zustand BACKUP und entfernt die virtuelle IP-Adresse von der Netzwerkschnittstelle:
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 103, ours 102
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.
Feb 27 05:38:36 proxysql2 avahi-daemon[346]: Withdrawing address record for 10.0.0.100 on eth0.An diesem Punkt ist ProxySQL1 wieder online und wird zum aktiven Load Balancer, der die Verbindungen von Anwendungen und Clients bedient. VRRP verdrängt normalerweise einen Server mit niedrigerer Priorität, wenn ein Server mit höherer Priorität online geht. Wenn Sie möchten, dass die IP-Adresse auf ProxySQL2 bleibt, nachdem ProxySQL1 wieder online ist, verwenden Sie die Option „nopreempt“. Dadurch kann die Maschine mit niedrigerer Priorität die Master-Rolle beibehalten, selbst wenn eine Maschine mit höherer Priorität wieder online geht. Damit dies funktioniert, muss der Ausgangszustand dieses Eintrags jedoch BACKUP sein. Andernfalls werden Sie die folgende Zeile bemerken:
Feb 27 05:50:33 proxysql2 Keepalived_vrrp[6298]: (VI_PROXYSQL): Warning - nopreempt will not work with initial state MASTERDa ClusterControl standardmäßig alle Knoten als MASTER konfiguriert, müssen Sie die folgende Konfigurationsoption für die jeweilige VRRP-Instanz entsprechend konfigurieren:
vrrp_instance VI_PROXYSQL {
...
state BACKUP
nopreempt
...
}Starten Sie den Keepalived-Prozess neu, um diese Änderungen zu laden. Die virtuelle IP-Adresse wird nur dann auf ProxySQL1 oder ProxySQL3 umgeleitet (abhängig von der Priorität und dem zu diesem Zeitpunkt verfügbaren Knoten), wenn die Zustandsprüfung auf ProxySQL2 fehlschlägt. In vielen Fällen reicht es aus, Keepalived auf zwei Hosts auszuführen.