Im vorherigen Teil dieses Artikels haben wir besprochen, wie Sie CSV-Dateien mit Hilfe der BULK INSERT-Anweisung in SQL Server importieren. Wir haben die Hauptmethodik des Bulk-Insert-Prozesses und auch die Details der BATCHSIZE- und MAXERRORS-Optionen in Szenarien besprochen. In diesem Teil werden wir einige andere Optionen (FIRE_TRIGGERS, CHECK_CONSTRAINTS und TABLOCK) des Masseneinfügungsprozesses in verschiedenen Szenarien durchgehen.
Szenario 1:Können wir Trigger in der Zieltabelle während des Masseneinfügungsvorgangs aktivieren?
Standardmäßig werden während des Masseneinfügevorgangs die in der Zieltabelle angegebenen Einfügetrigger nicht ausgelöst, in einigen Situationen möchten wir diese Trigger jedoch möglicherweise aktivieren. Eine Lösung für dieses Problem ist die Verwendung der Option FIRE_TRIGGERS in Masseneinfügeanweisungen. Ich möchte einen Hinweis hinzufügen, dass diese Option die Leistung von Masseneinfügevorgängen beeinträchtigen und verringern kann, da Trigger/Trigger separate Vorgänge in der Datenbank ausführen können. Im folgenden Beispiel demonstrieren wir dies. Zunächst setzen wir den Parameter FIRE_TRIGGERS nicht und der Bulk-Insert-Prozess löst den Insert-Trigger nicht aus. Im folgenden T-SQL-Skript definieren wir einen Insert-Trigger für die Sales-Tabelle.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLog
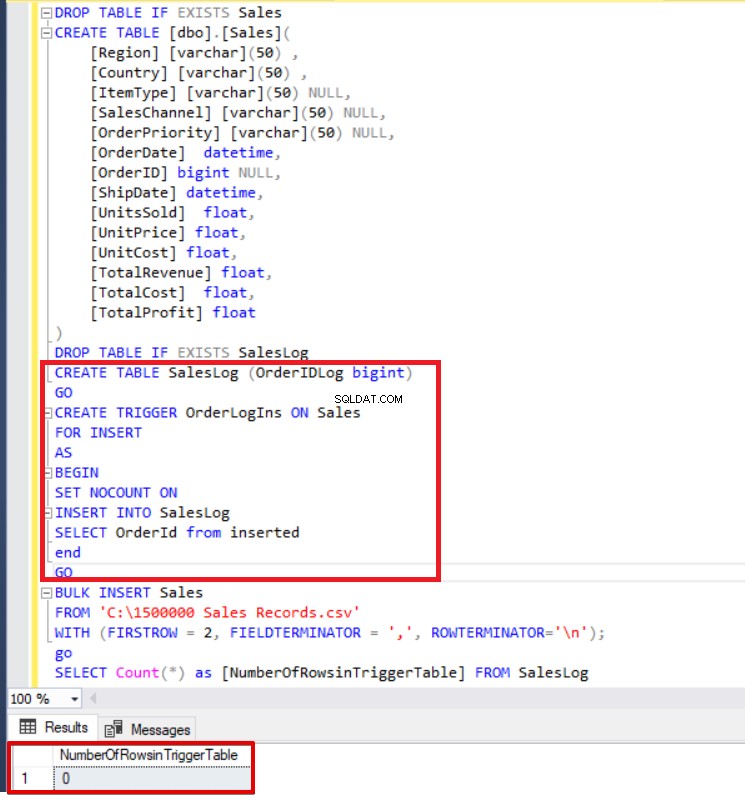
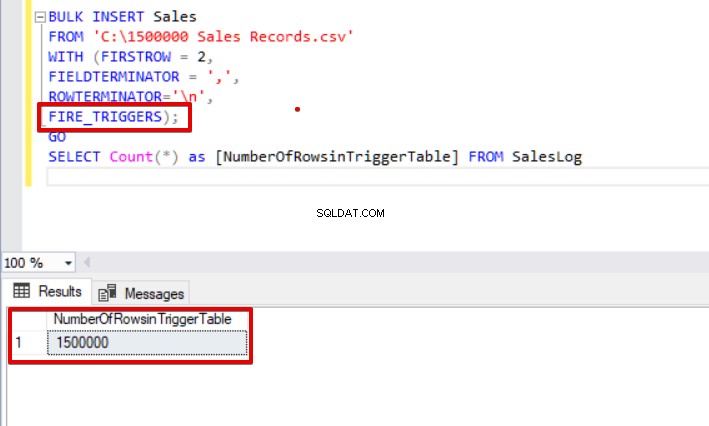
Wie Sie oben sehen können, wurde der Insert-Trigger nicht ausgelöst, weil wir die Option FIRE_TRIGGERS nicht gesetzt haben. Jetzt fügen wir die Option FIRE_TRIGGERS zur Bulk-Insert-Anweisung hinzu, sodass diese Option das Einfügen eines Feuer-Triggers ermöglicht.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FIRSTROW = 2, FIELDTERMINATOR = ',', ROWTERMINATOR='\n', FIRE_TRIGGERS); GO SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog
Szenario 2:Wie kann eine Check-Einschränkung während des Masseneinfügungsvorgangs aktiviert werden?
Check Constraints ermöglichen es uns, die Datenintegrität in SQL Server-Tabellen zu erzwingen. Zweck des Constraints ist es, eingefügte, aktualisierte oder gelöschte Werte nach ihrer Syntaxvorschrift zu prüfen. Beispielsweise sorgt die NOT NULL-Einschränkung dafür, dass eine angegebene Spalte nicht durch den NULL-Wert geändert werden kann. Jetzt konzentrieren wir uns auf Beschränkungen und Masseneinfügungsinteraktionen. Standardmäßig werden während des Masseneinfügungsprozesses alle Prüfungen und Fremdschlüsseleinschränkungen ignoriert, aber diese Option hat einige Ausnahmen. Gemäß der Microsoft-Dokumentation werden „UNIQUE- und PRIMARY-KEY-Einschränkungen immer erzwungen. Beim Importieren in eine Zeichenspalte, für die die Einschränkung NOT NULL definiert ist, fügt BULK INSERT eine leere Zeichenfolge ein, wenn die Textdatei keinen Wert enthält.“ Im folgenden T-SQL-Skript fügen wir der OrderDate-Spalte eine Check-Einschränkung hinzu, die das Bestelldatum nach dem 01.01.2016 steuert.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'
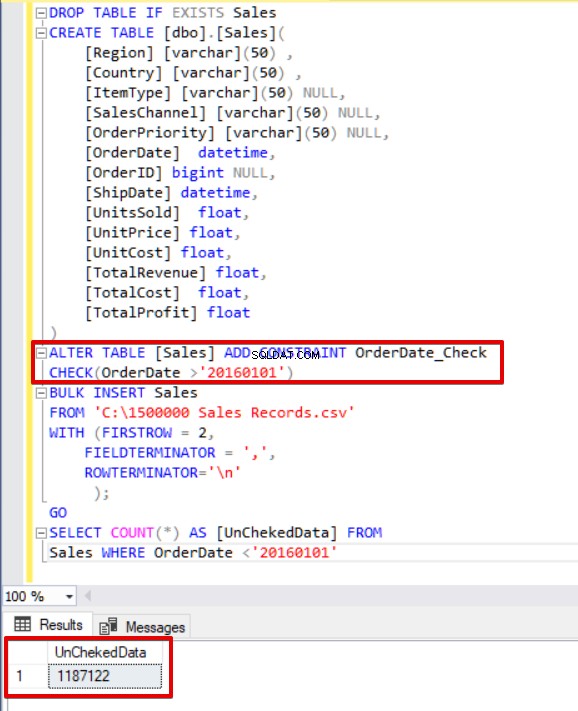
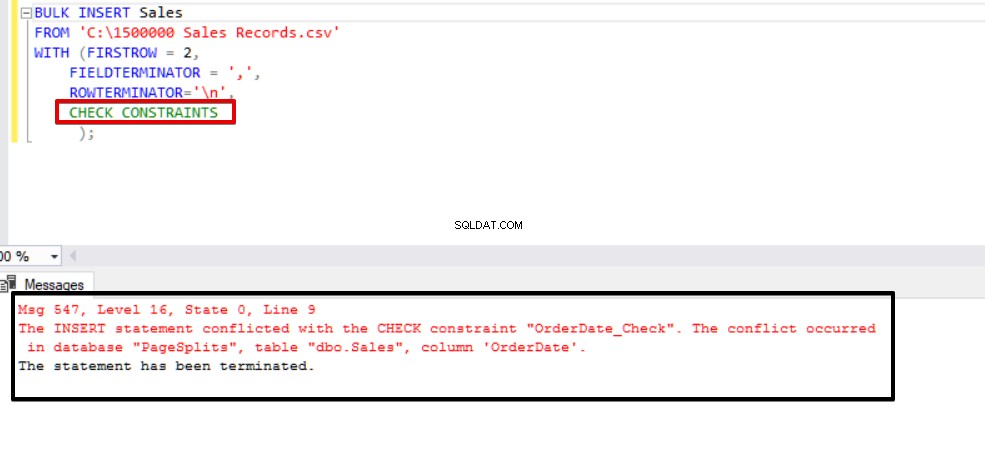
Wie Sie im obigen Beispiel sehen können, überspringt der Masseneinfügeprozess die Check-Constraint-Steuerung. SQL Server zeigt jedoch die Check-Einschränkung als nicht vertrauenswürdig an.
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'
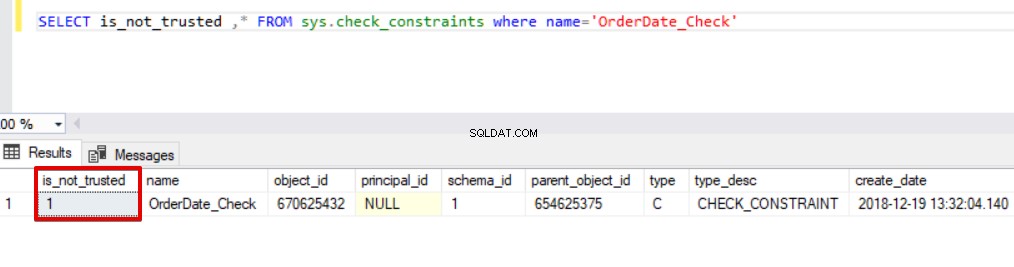
Dieser Wert zeigt an, dass jemand einige Daten in diese Spalte eingefügt oder aktualisiert hat, indem er die Check-Einschränkung übersprungen hat, gleichzeitig kann diese Spalte inkonsistente Daten in Bezug auf diese Einschränkung enthalten. Jetzt werden wir versuchen, die Bulk-Insert-Anweisung mit der Option CHECK_CONSTRAINTS auszuführen. Das Ergebnis ist sehr einfach, Check Constraint gibt einen Fehler wegen falscher Daten zurück.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
Szenario 3:Wie kann die Leistung bei mehreren Masseneinfügungen in eine Zieltabelle gesteigert werden?
Der Hauptzweck des Sperrmechanismus in SQL Server besteht darin, die Integrität von Daten zu schützen und sicherzustellen. Im Artikel Hauptkonzept von SQL Server-Sperren finden Sie Details zum Sperrmechanismus. Jetzt konzentrieren wir uns auf Sperrdetails für den Masseneinfügeprozess. Wenn Sie die Masseneinfügeanweisung ohne die Option TABLELOCK ausführen, erwirbt sie die Sperre von Zeilen oder Tabellen gemäß der Sperrhierarchie. In einigen Fällen möchten wir jedoch möglicherweise mehrere Bulk-Insert-Prozesse für eine Zieltabelle ausführen, damit wir die Operationszeit des Bulk-Insert verringern können. Zunächst werden wir zwei Bulk-Insert-Anweisungen gleichzeitig ausführen und das Verhalten des Sperrmechanismus analysieren. Wir öffnen zwei Abfragefenster in SQL Server Management Studio und führen die folgenden Bulk-Insert-Anweisungen gleichzeitig aus.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
Wenn wir die folgende dmv-Abfrage (Dynamic Management View) ausführen, die hilft, den Status des Masseneinfügungsprozesses zu überwachen.
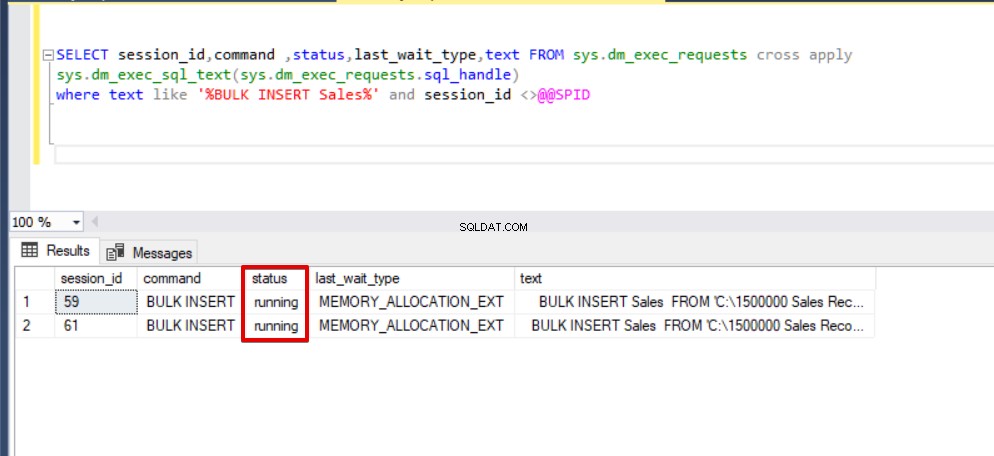
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle) where text like '%BULK INSERT Sales%' and session_id <>@@SPID
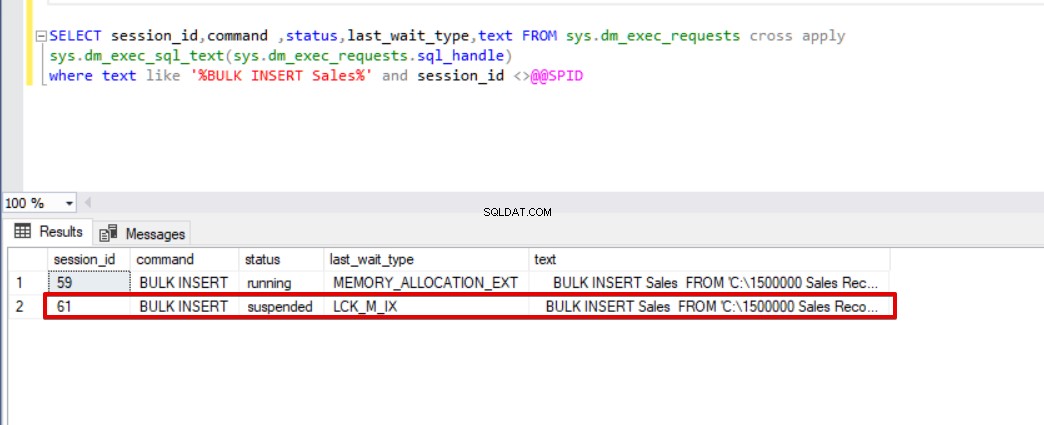
Wie Sie im obigen Bild, Sitzung 61, sehen können, wird der Status des Masseneinfügungsprozesses aufgrund einer Sperrung ausgesetzt. Wenn wir das Problem überprüfen, sperrt Sitzung 59 die Zieltabelle für die Masseneinfügung und Sitzung 61 wartet auf die Freigabe dieser Sperre, um den Masseneinfügungsprozess fortzusetzen. Jetzt werden wir die TABLOCK-Option zu den Bulk-Insert-Anweisungen hinzufügen und die Abfragen ausführen.
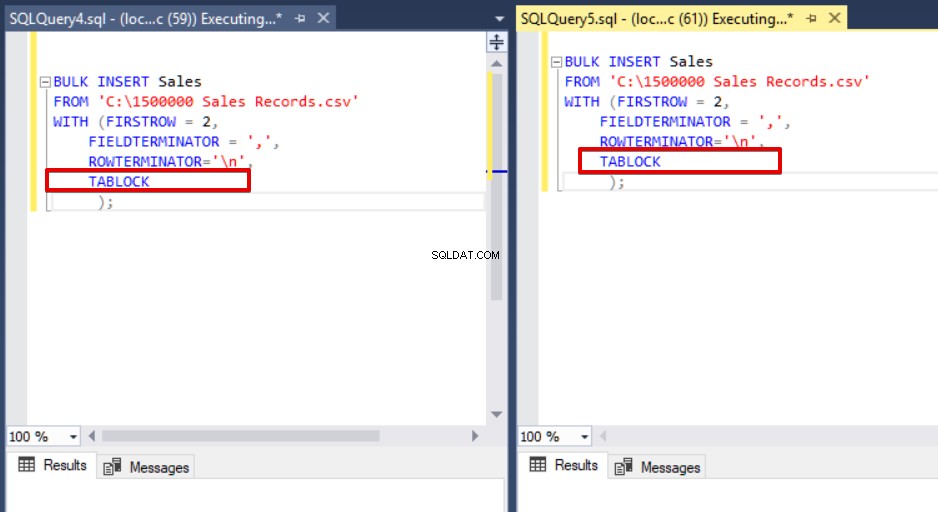
Wenn wir die dmv-Überwachungsabfrage erneut ausführen, sehen wir keinen angehaltenen Bulk-Insert-Prozess, da SQL Server einen speziellen Sperrtyp namens Bulk Update Lock (BU) verwendet. Dieser Sperrtyp ermöglicht die gleichzeitige Verarbeitung mehrerer Bulk-Insert-Vorgänge für dieselbe Tabelle, und diese Option verringert auch die Gesamtzeit des Bulk-Insert-Prozesses.
Wenn wir die folgende Abfrage während des Masseneinfügungsprozesses ausführen, können wir die Sperrdetails und Sperrtypen überwachen.
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()
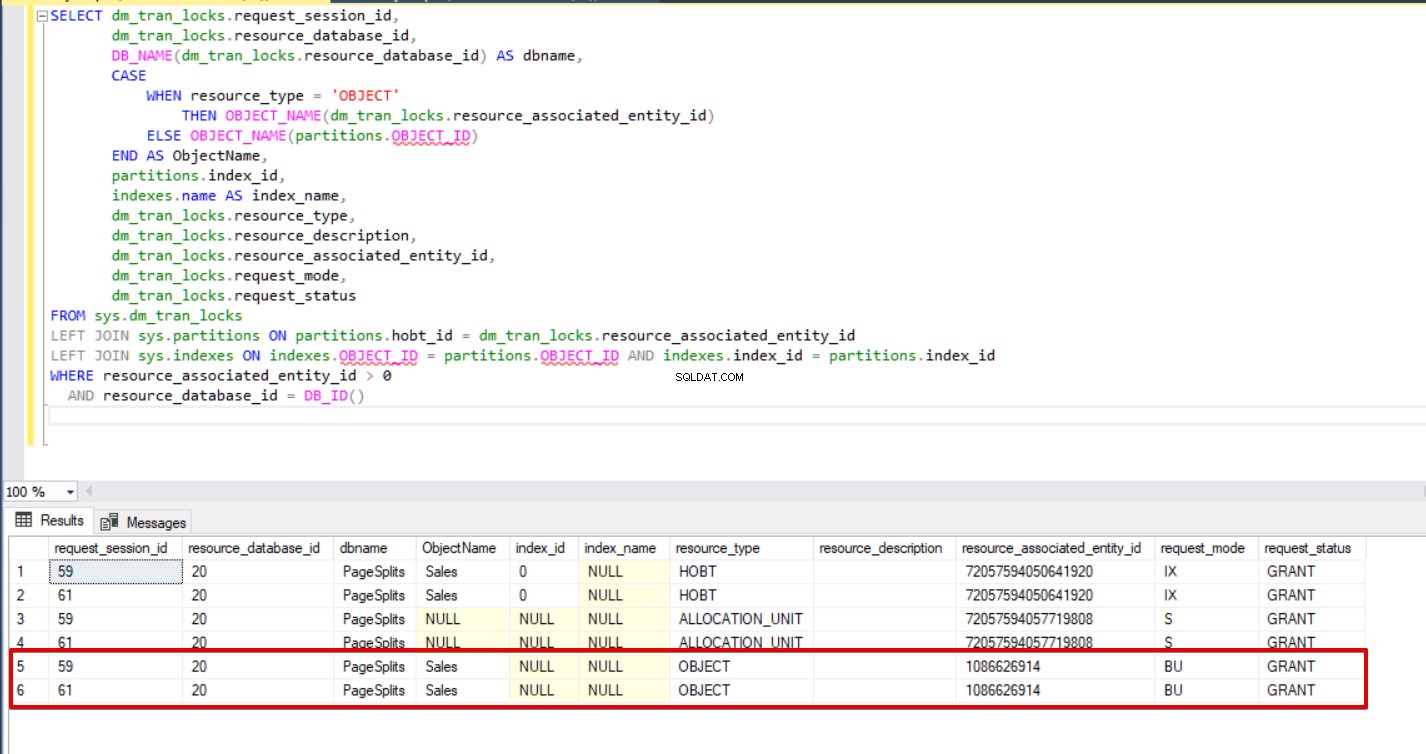
Fazit
In diesem Artikel haben wir alle Details des Masseneinfügungsvorgangs in SQL Server untersucht. Insbesondere haben wir den Befehl BULK INSERT und seine Einstellungen und Optionen erwähnt, und wir haben auch verschiedene Szenarien analysiert, die realen Problemen nahe kommen.
Referenzen
BULK INSERT (Transact-SQL)
Voraussetzungen für die minimale Protokollierung beim Massenimport
Steuern des Sperrverhaltens für den Massenimport
Weiterführende Literatur
Exportieren von Daten in Flatfiles mit dem BCP-Dienstprogramm und Importieren von Daten mit Bulk Insert
Nützliches Tool:
dbForge Data Pump – ein SSMS-Add-In zum Füllen von SQL-Datenbanken mit externen Quelldaten und zum Migrieren von Daten zwischen Systemen.