Mit der Einführung von Azure SQL-Datenbank und dem Hinzufügen weiterer Funktionen in Version 12 sehen Datenbankadministratoren, dass ihre Organisationen zunehmend daran interessiert sind, Datenbanken auf diese Plattform zu verschieben.
Ich habe vor kurzem begonnen, mehr in Azure SQL-Datenbank einzutauchen, um zu sehen, was sich drastisch von der Unterstützung der Box-Version in Rechenzentren auf der ganzen Welt und der Azure SQL-Datenbank unterscheidet. In meinem vorherigen Artikel „Tuning:A Good Place to Start“ (Optimierung:Ein guter Ausgangspunkt) habe ich meinen Ansatz für die ersten Schritte mit der Optimierung von SQL Server beschrieben. Ich habe mich entschieden, dies anhand der Azure SQL-Datenbank zu überprüfen, um die Hauptunterschiede zu ermitteln.
In meinem ursprünglichen Artikel habe ich mit allgemeinen Einstellungen auf Instanzebene begonnen, die meiner Meinung nach ignoriert oder als Standard belassen werden, sowie mit Wartungselementen. Dazu gehören Arbeitsspeicher, maxdop, Kostenschwellenwert für Parallelität, Aktivieren der Optimierung für Ad-hoc-Workloads und Konfigurieren von tempdb. Bei Azure SQL-Datenbank sind Sie nicht für die Instanz verantwortlich und können diese Einstellungen nicht ändern. Azure SQL-Datenbank ist eine Platform as a Service (PaaS), was bedeutet, dass Microsoft die Instanz für Sie verwaltet; Sie sind einfach ein Mieter mit Ihrer Datenbank oder Ihren Datenbanken.
Sie sind jedoch für die Wartung verantwortlich, also müssen Sie Statistiken aktualisieren und die Indexfragmentierung handhaben, wie Sie es für das Box-Produkt tun. Für diese Aufgaben habe ich festgestellt, dass die meisten Clients diese Prozesse mit einer dedizierten Azure-VM verwalten, auf der SQL Server ausgeführt wird und der SQL Server-Agent mit geplanten Jobs verwendet wird.
In Anlehnung an die Schritte aus meinem Artikel sind die nächsten Bereiche, mit denen ich mich befasse, Datei- und Wartestatistiken und kostspielige Abfragen. Wenn Sie sich fragen, ob sich dieser Aspekt Ihrer Arbeit als Produktions-DBA mit lokalen Datenbanken ändern wird, wenn Sie mit Azure SQL-Datenbank arbeiten, lautet die Antwort nicht wirklich . Datei- und Wartestatistiken sind immer noch da, aber wir müssen sie auf etwas andere Weise erreichen. Wenn Sie daran gewöhnt sind, Paul Randals Skripte für Dateistatistiken und Wartestatistiken (oder die Abfragen für Dateistatistiken für einen bestimmten Zeitraum und Wartestatistiken für einen bestimmten Zeitraum) zu verwenden, müssen Sie einige Änderungen vornehmen, um dies zu tun diese Skripts, damit sie mit Azure SQL-Datenbank funktionieren.
Als ich Pauls Dateistatistikskript zum ersten Mal ausprobierte, schlug es fehl, weil die Azure SQL-Datenbank sys.master_files nicht unterstützte :
Ungültiger Objektname „sys.master_files“.
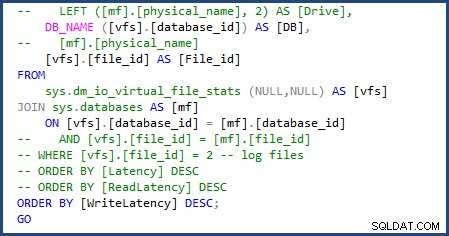
Ich konnte das Skript ändern, um sys.databases zu verwenden in der Verknüpfung, um den Datenbanknamen zu erhalten, und entfernen Sie den Teil des Skripts, um die einzelnen Dateinamen zu erhalten, da wir es nur mit einer einzigen Daten- und Protokolldatei zu tun haben. Sie können die Änderungen sehen, die ich im folgenden Bild vornehmen musste:
Als ich das file-stats-over-a-period-of-time-Skript danach ausführte, nahm ich dieselbe Änderung an sys.databases vor und Entfernen der Verweise auf file_id bei der Verknüpfung ist ein Fehler aufgetreten, weil Azure SQL-Datenbank v12 globale ##temp-Tabellen nicht unterstützt.
Nachdem ich alle globalen ##temp-Tabellen in lokale geändert hatte, hatte ich ein weiteres Problem mit dem Skript, das vorhandene temporäre Tabellen, die verwendet wurden, nicht löschen konnte, da auf lokale #temp-Tabellen nicht direkt über den Namen verwiesen werden kann, wie dies bei globalen ##temp-Tabellen der Fall ist. aber das war leicht zu überwinden, indem man solche Prüfungen auf OBJECT_ID('tempdb..#SQLskillsStats1') änderte . Ich habe die gleiche Änderung für die zweite temporäre Tabelle vorgenommen und den Codeblock am Anfang und am Ende des Skripts aktualisiert.
Ich musste noch eine Änderung vornehmen und [mf].[type_desc] entfernen und LEFT ([mf].[physical_name], 2) AS [Drive] da diese von sys.master_files abhängig sind . Das Skript war dann vollständig und bereit zur Verwendung mit Azure SQL-Datenbank.
Ich verwende die Dateistatistiken über einen bestimmten Zeitraum regelmäßig, wenn ich Leistungsprobleme behebe. Die kumulativen Daten haben ihren Zweck, aber ich interessiere mich mehr für bestimmte Zeitabschnitte, in denen Benutzerarbeitslasten ausgeführt werden.
Bei Dateistatistiken geht es uns um unsere Latenz pro Datenbankdatei und darum, wie wir sie optimieren können, um die Gesamt-E/A zu reduzieren. Der Ansatz ist der gleiche wie bei SQL Server, wo Sie Ihre Abfragen richtig optimieren und die richtigen Indizes haben müssen. Wenn die Arbeitslast einfach zu groß ist, müssen Sie zu einer schnelleren DTU-Datenbankschicht wechseln. Für mich ist das großartig:Sie werfen nur Hardware darauf; aber es ist nicht wirklich Hardware im herkömmlichen Sinne. Mit Azure SQL-Datenbank können Sie mit einer kostengünstigeren Ebene beginnen und skalieren, wenn Ihr Geschäft und Ihre E/A-Anforderungen wachsen – im Wesentlichen durch einfaches Umlegen eines Schalters.
Der Versuch, die beste Methode zum Abrufen von Wartestatistiken zu finden, war einfacher. Das Standardskript, das viele von uns verwenden, funktioniert immer noch, zieht jedoch Wartestatistiken für den Container, in dem Ihre Datenbank ausgeführt wird. Diese Wartezeiten gelten weiterhin für Ihr System, können jedoch Wartezeiten umfassen, die von anderen Datenbanken im selben Container verursacht werden. Azure SQL-Datenbank enthält eine neue DMV, sys.dm_db_wait_stats , die nach der aktuellen Datenbank filtert. Wenn Sie wie ich sind und hauptsächlich Pauls Wait-Stats-Skript verwenden, das alle gutartigen Wartezeiten weglässt, ändern Sie einfach sys.dm_os_wait_stats zu sys.dm_db_wait_stats . Die gleiche Änderung funktioniert auch für das Waits-over-a-Time-of-Time-Skript, aber Sie müssen auch die Änderung von globalen Variablen zu lokalen vornehmen.
Wenn es darum geht, kostspielige Abfragen zu finden, findet eines meiner bevorzugten auszuführenden Skripts die am häufigsten verwendeten Ausführungspläne. Meiner Erfahrung nach ist das Optimieren einer Abfrage, die 100.000 Mal pro Tag aufgerufen wird, normalerweise ein größerer Gewinn als das Optimieren einer Abfrage, die den höchsten IO hat, aber nur einmal pro Woche ausgeführt wird. Die folgende Abfrage verwende ich, um die am häufigsten verwendeten Pläne zu finden:
SELECT usecounts , cacheobjtype , objtype , [text]FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_sql_text(plan_handle)WHERE usecounts> 1 AND objtype IN ( N'Adhoc', N'Prepared' )ORDER BY usecounts DESC;Wenn ich diese Abfrage in Demos verwende, leere ich immer meinen Plan-Cache, um die Werte zurückzusetzen. Als ich versuchte,
DBCC FREEPROCCACHEauszuführen In der Azure SQL-Datenbank wurde mir der folgende Fehler angezeigt:Es stellt sich heraus, dass
SQL Azure unterstützt derzeit DBCC FREEPROCCACHE (Transact-SQL) nicht, sodass Sie einen Ausführungsplan nicht manuell aus dem Cache entfernen können. Wenn Sie jedoch Änderungen an der Tabelle oder Ansicht vornehmen, auf die von der Abfrage verwiesen wird (ALTER TABLE und ALTER VIEW), wird der Plan aus dem Cache entfernt.DBCC FREEPROCCACHEwird in Azure SQL-Datenbank nicht unterstützt. Das war beunruhigend für mich, was ist, wenn ich in der Produktion bin und einige schlechte Pläne habe und den Prozedur-Cache löschen möchte, wie ich es mit der Box-Version kann. Eine kleine Google/Bing-Recherche führte mich zu dem Microsoft-Artikel „Understanding the Procedure Cache on SQL Azure“, in dem es heißt:Wenn Sie dies mit Kimberly Tripp besprechen, nachdem Sie das beschriebene Verhalten nicht gesehen haben, wird der Plan nicht aus dem Cache gelöscht, aber der Plan wird ungültig (und dann wird der Plan schließlich aus dem Cache entfernt). Dies ist zwar in bestimmten Situationen hilfreich, aber das war nicht das, was ich brauchte. Für meine Demo wollte ich die Zähler in sys.dm_exec_cached_plans zurücksetzen. Das Erstellen eines neuen Plans brachte mir nicht die gewünschten Ergebnisse. Ich habe mich an mein Team gewandt und Glenn Berry hat mir geraten, das folgende Skript auszuprobieren:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;Dieser Befehl funktionierte; Ich konnte den Prozedurcache für die spezifische Datenbank löschen. Database Scoped Configurations ist ein neues Feature, das in SQL Server 2016 RC0 hinzugefügt wurde; Glenn hat hier darüber gebloggt:Using ALTER DATABASE SCOPED CONFIGURATION in SQL Server 2016.
Ich freue mich darauf, mehrere meiner eigenen Datenbanken in Azure SQL-Datenbank zu verschieben und mich weiter über die neuen Features und Skalierbarkeitsoptionen zu informieren. Ich freue mich auch auf die Zusammenarbeit mit SentryOne DB Sentry, einer neuen Ergänzung der SentryOne-Plattform. Am meisten interessiert mich das Experimentieren mit dem DTU-Nutzungs-Dashboard, das Mike Wood in seinem letzten Beitrag beschrieben hat.