Einführung
Vor einigen Jahren wurden wir mit einer Geschäftsanforderung für Kartendaten in einem bestimmten Format zum Zwecke eines sogenannten „Abgleichs“ beauftragt. Die Idee war, die Daten in einer Tabelle einer Anwendung zu präsentieren, die die Daten mit einer Aufbewahrungsfrist von sechs Monaten konsumieren und verarbeiten würde. Wir mussten eine neue Datenbank für diese Geschäftsanforderungen erstellen und dann die Kerntabelle als partitionierte Tabelle erstellen. Der hier beschriebene Prozess ist der Prozess, den wir verwenden, um sicherzustellen, dass Daten, die älter als sechs Monate sind, sauber aus der Tabelle verschoben werden.
Ein bisschen über Partitionierung
Tabellenpartitionierung ist eine Datenbanktechnologie, die es Ihnen ermöglicht, Daten, die zu einer logischen Einheit (der Tabelle) gehören, als eine Reihe von Partitionen zu speichern, die auf separaten physischen Strukturen – Datendateien – über eine Abstraktionsschicht namens Dateigruppen in SQL Server sitzen. Der Prozess zum Erstellen dieser partitionierten Tabelle umfasst zwei Schlüsselobjekte:
Eine Partitionsfunktion :Eine Partitionsfunktion definiert, wie die Zeilen einer partitionierten Tabelle basierend auf den Werten einer angegebenen Spalte (der Partitionsspalte) zugeordnet werden. Eine partitionierte Tabelle könnte entweder auf einer Liste basieren oder eine Reihe. Für unseren Anwendungsfall (Aufbewahrung der Daten von nur sechs Monaten) haben wir eine Bereichspartition verwendet . Eine Partitionsfunktion kann entweder als BEREICH RECHTS oder BEREICH LINKS definiert werden. Wir haben RANGE RIGHT verwendet, wie im Code in Listing 1 gezeigt, was bedeutet, dass der Grenzwert zur rechten Seite des Grenzwertintervalls gehört, wenn die Werte in aufsteigender Reihenfolge von links nach rechts sortiert werden.
-- Listing 1: Create a Partition Function
USE [post_office_history]
GO
CREATE PARTITION FUNCTION
PostTranPartFunc (datetime)
AS RANGE RIGHT
FOR VALUES
('20190201'
,'20190301'
,'20190401'
,'20190501'
,'20190601'
,'20190701'
,'20190801'
,'20190901'
,'20191001'
,'20191101'
,'20191201'
)
GO Ein Partitionsschema :Ein Partitionsschema basiert auf der Partitionsfunktion und bestimmt, auf welchen physikalischen Strukturen Zeilen platziert werden, die zu jeder Partition gehören. Dies wird erreicht, indem solche Zeilen Dateigruppen zugeordnet werden. Listing 2 zeigt den Code zum Erstellen eines Partitionsschemas. Vor dem Erstellen des Partitionsschemas müssen die Dateigruppen, auf die es verweist, vorhanden sein.
-- Listing 2: Create Partition Scheme -- -- Step 1: Create Filegroups -- USE [master] GO ALTER DATABASE [post_office_history] ADD FILEGROUP [JAN] ALTER DATABASE [post_office_history] ADD FILEGROUP [FEB] ALTER DATABASE [post_office_history] ADD FILEGROUP [MAR] ALTER DATABASE [post_office_history] ADD FILEGROUP [APR] ALTER DATABASE [post_office_history] ADD FILEGROUP [MAY] ALTER DATABASE [post_office_history] ADD FILEGROUP [JUN] ALTER DATABASE [post_office_history] ADD FILEGROUP [JUL] ALTER DATABASE [post_office_history] ADD FILEGROUP [AUG] ALTER DATABASE [post_office_history] ADD FILEGROUP [SEP] ALTER DATABASE [post_office_history] ADD FILEGROUP [OCT] ALTER DATABASE [post_office_history] ADD FILEGROUP [NOV] ALTER DATABASE [post_office_history] ADD FILEGROUP [DEC] GO -- Step 2: Add Data Files to each Filegroup -- USE [master] GO ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_01', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_01.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [JAN] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_02', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_02.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [FEB] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_03', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_03.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [MAR] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_04', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_04.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [APR] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_05', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_05.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [MAY] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_06', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_06.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [JUN] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_07', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_07.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [JUL] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_08', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_08.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [AUG] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_09', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_09.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [SEP] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_10', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_10.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [OCT] GO ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_09', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_11.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [NOV] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_10', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_12.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [DEC] GO -- Step 3: Create Partition Scheme -- PRINT 'creating partition scheme ...' GO USE [post_office_history] GO CREATE PARTITION SCHEME PostTranPartSch AS PARTITION PostTranPartFunc TO ( JAN, FEB, MAR, APR, MAY, JUN, JUL, AUG, SEP, OCT, NOV, DEC ) GO
Beachten Sie das für N Partitionen gibt es immer N-1 Grenzen. Beim Definieren der ersten Dateigruppe im Partitionsschema ist Vorsicht geboten. Die erste in der Partitionsfunktion aufgeführte Grenze liegt zwischen der ersten und der zweiten Dateigruppe, sodass dieser Grenzwert (20190201) in der zweiten Partition (FEB) liegt. Außerdem ist es tatsächlich möglich, alle Partitionen in einer einzigen Dateigruppe zu platzieren, aber wir haben uns in diesem Fall für separate Dateigruppen entschieden.
Wir machen uns die Hände schmutzig
Lassen Sie uns also in die Aufgabe eintauchen, Partitionen auszutauschen!
Als erstes müssen wir genau bestimmen, wie unsere Daten auf die Partitionen verteilt sind, damit wir wissen, welche Partition wir austauschen möchten. Normalerweise tauschen wir die älteste Partition aus.
-- Listing 3: Check Data Distribution in Partitions -- USE POST_OFFICE_HISTORY GO SELECT $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) AS [PARTITION NUMBER] , MIN(DATETIME_TRAN_LOCAL) AS [MIN DATE] , MAX(DATETIME_TRAN_LOCAL) AS [MAX DATE] , COUNT(*) AS [ROWS IN PARTITION] FROM DBO.POST_TRAN_TAB -- PARTITIONED TABLE GROUP BY $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) ORDER BY [PARTITION NUMBER] GO
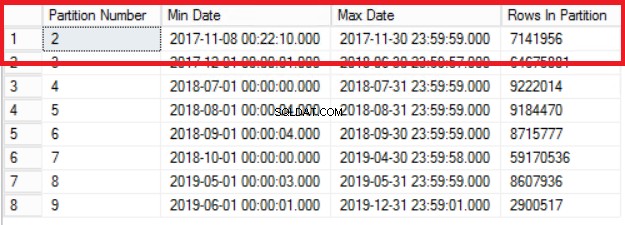
Abb. 1 Ausgabe von Listing 3
Abb. 1 zeigt uns die Ausgabe der Abfrage in Listing 3. Die älteste Partition ist Partition 2, die Zeilen aus dem Jahr 2017 enthält. Wir überprüfen dies mit der Abfrage in Listing 4. Listing 4 zeigt uns auch, welche Dateigruppe die Daten in Partition enthält 2.
-- Listing 4: Check Filegroup Associated with Partition --
USE POST_OFFICE_HISTORY
GO
SELECT PS.NAME AS PSNAME,
DDS.DESTINATION_ID AS PARTITIONNUMBER,
FG.NAME AS FILEGROUPNAME
FROM (((SYS.TABLES AS T
INNER JOIN SYS.INDEXES AS I
ON (T.OBJECT_ID = I.OBJECT_ID))
INNER JOIN SYS.PARTITION_SCHEMES AS PS
ON (I.DATA_SPACE_ID = PS.DATA_SPACE_ID))
INNER JOIN SYS.DESTINATION_DATA_SPACES AS DDS
ON (PS.DATA_SPACE_ID = DDS.PARTITION_SCHEME_ID))
INNER JOIN SYS.FILEGROUPS AS FG
ON DDS.DATA_SPACE_ID = FG.DATA_SPACE_ID
WHERE (T.NAME = 'POST_TRAN_TAB') AND (I.INDEX_ID IN (0,1))
AND DDS.DESTINATION_ID = $PARTITION.POSTTRANPARTFUNC('20171108') ; Abb. 1 Ausgabe von Listing 3
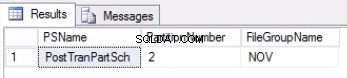
Abb. 2 Ausgabe von Listing 4
Listing 4 zeigt uns, dass die mit Partition 2 verknüpfte Dateigruppe NOV ist . Um Partition 2 auszutauschen, benötigen wir eine Verlaufstabelle, die eine Kopie der Live-Tabelle ist, sich aber in derselben Dateigruppe befindet wie die Partition, die wir austauschen möchten. Da wir diese Tabelle bereits haben, müssen wir sie nur in der gewünschten Dateigruppe neu erstellen. Sie müssen auch den gruppierten Index neu erstellen. Beachten Sie, dass dieser Clustered-Index dieselbe Definition hat wie der Clustered-Index für die Tabelle post_tran_tab und befindet sich auch in derselben Dateigruppe wie post_tran_tab_hist Tabelle.
-- Listing 5: Re-create the History Table -- Re-create the History Table -- USE [post_office_history] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO SET ANSI_PADDING ON GO DROP TABLE [dbo].[post_tran_tab_hist] GO CREATE TABLE [dbo].[post_tran_tab_hist]( [tran_nr] [bigint] NOT NULL, [tran_type] [char](2) NULL, [tran_reversed] [char](2) NULL, [batch_nr] [int] NULL, [message_type] [char](4) NULL, [source_node_name] [varchar](12) NULL, [system_trace_audit_nr] [char](6) NULL, [settle_currency_code] [char](3) NULL, [sink_node_name] [varchar](30) NULL, [sink_node_currency_code] [char](3) NULL, [to_account_id] [varchar](30) NULL, [pan] [varchar](19) NOT NULL, [pan_encrypted] [char](18) NULL, [pan_reference] [char](70) NULL, [datetime_tran_local] [datetime] NOT NULL, [tran_amount_req] [float] NOT NULL, [tran_amount_rsp] [float] NOT NULL, [tran_cash_req] [float] NOT NULL, [tran_cash_rsp] [float] NOT NULL, [datetime_tran_gmt] [char](10) NULL, [merchant_type] [char](4) NULL, [pos_entry_mode] [char](3) NULL, [pos_condition_code] [char](2) NULL, [acquiring_inst_id_code] [varchar](11) NULL, [retrieval_reference_nr] [char](12) NULL, [auth_id_rsp] [char](6) NULL, [rsp_code_rsp] [char](2) NULL, [service_restriction_code] [char](3) NULL, [terminal_id] [char](8) NULL, [terminal_owner] [varchar](25) NULL, [card_acceptor_id_code] [char](15) NULL, [card_acceptor_name_loc] [char](40) NULL, [from_account_id] [varchar](28) NULL, [auth_reason] [char](1) NULL, [auth_type] [char](1) NULL, [message_reason_code] [char](4) NULL, [datetime_req] [datetime] NULL, [datetime_rsp] [datetime] NULL, [from_account_type] [char](2) NULL, [to_account_type] [char](2) NULL, [insert_date] [datetime] NOT NULL, [tran_postilion_originated] [int] NOT NULL, [card_product] [varchar](20) NULL, [card_seq_nr] [char](3) NULL, [expiry_date] [char](4) NULL, [srcnode_cash_approved] [float] NOT NULL, [tran_completed] [char](2) NULL ) ON [NOV] GO SET ANSI_PADDING OFF GO -- Re-create the Clustered Index -- USE [post_office_history] GO CREATE CLUSTERED INDEX [IX_Datetime_Local] ON [dbo].[post_tran_tab_hist] ( [datetime_tran_local] ASC, [tran_nr] ASC ) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [NOV] GO
Das Auswechseln der letzten Partition ist jetzt ein einzeiliger Befehl. Wenn Sie beide Tabellen vor und nach der Ausführung dieses einzeiligen Befehls zählen, können Sie sicher sein, dass wir alle gewünschten Daten haben.
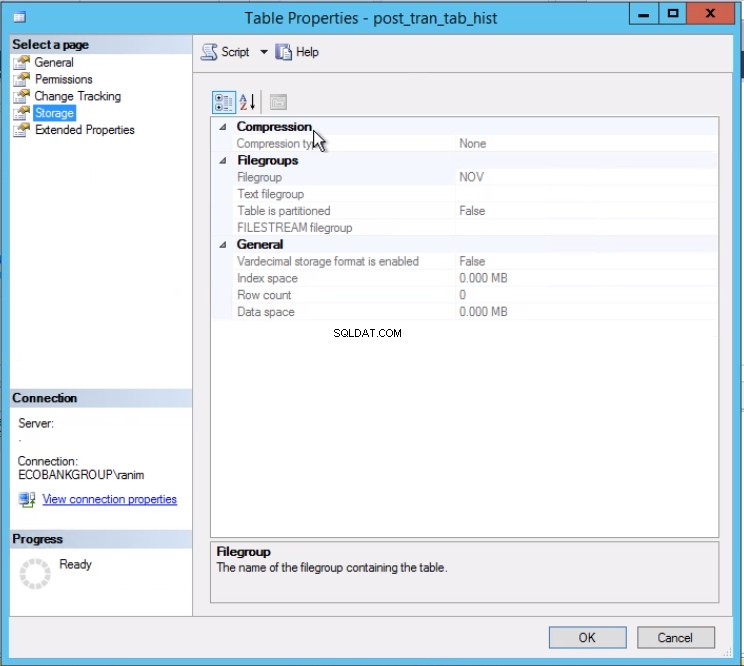
Abb. 3 Die Tabelle post_tran_tab_hist befindet sich in der NOV-Dateigruppe
-- Listing 6: Switching Out the Last Partition SELECT COUNT(*) FROM 'POST_TRAN_TAB'; SELECT COUNT(*) FROM 'POST_TRAN_TAB_HIST'; USE [POST_OFFICE_HISTORY] GO ALTER TABLE POST_TRAN_TAB SWITCH PARTITION 2 TO POST_TRAN_TAB_HIST GO SELECT COUNT(*) FROM 'POST_TRAN_TAB'; SELECT COUNT(*) FROM 'POST_TRAN_TAB_HIST';
Da wir die letzte Partition ausgetauscht haben, brauchen wir die Grenze nicht mehr. Wir führen die beiden Bereiche zusammen, die zuvor durch diese Grenze getrennt wurden, indem wir den Befehl in Listing 7 verwenden. Wir kürzen die Verlaufstabelle weiter, wie in Listing 8 gezeigt. Wir tun dies, weil dies der springende Punkt ist:das Entfernen alter Daten, die wir nicht mehr benötigen.
-- Listing 7: Merging Partition Ranges
-- Merge Range
USE [POST_OFFICE_HISTORY]
GO
ALTER PARTITION FUNCTION POSTTRANPARTFUNC() MERGE RANGE ('20171101');
-- Confirm Range Is Merged
USE [POST_OFFICE_HISTORY]
GO
SELECT * FROM SYS.PARTITION_RANGE_VALUES
GO
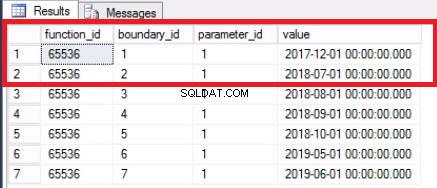
Abb. 4 Grenze zusammengeführt
-- Listing 8: Truncate the History Table USE [post_office_history] GO TRUNCATE TABLE post_tran_tab_hist; GO
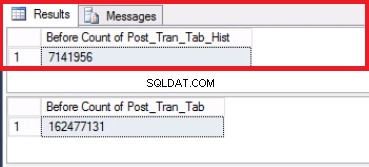
Abb. 5 Zeilenanzahl für beide Tabellen vor dem Abschneiden
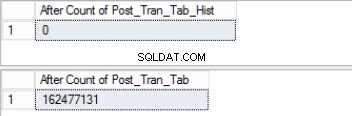
Beachten Sie, dass die Anzahl der Zeilen in der Verlaufstabelle genau die gleiche ist wie die Anzahl der Zeilen zuvor in Partition 2, wie in Abb. 1 gezeigt. Sie können auch noch einen Schritt weiter gehen, indem Sie den leeren Speicherplatz in der Dateigruppe wiederherstellen, die zur letzten gehört Partition. Dies ist nützlich, wenn Sie diesen Speicherplatz für die neuen Daten benötigen, die sich auf der früheren Partition befinden. Dieser Schritt ist möglicherweise nicht erforderlich, wenn Sie der Meinung sind, dass in Ihrer Umgebung ausreichend Platz vorhanden ist.
-- Listing 9: Recover Space on Operating System -- Determine that File has been emptied USE [post_office_history] GO SELECT DF.FILE_ID, DF.NAME, DF.PHYSICAL_NAME, DS.NAME, DS.TYPE, DF.STATE_DESC FROM SYS.DATABASE_FILES DF JOIN SYS.DATA_SPACES DS ON DF.DATA_SPACE_ID = DS.DATA_SPACE_ID;
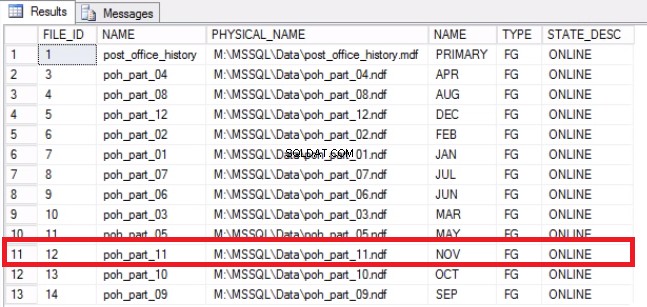
Abb. 7 Zuordnungen von Datei zu Dateigruppe
-- Shrink the file to 2GB USE [post_office_history] GO DBCC SHRINKFILE (N'post_office_history_part_11’, 2048) GO -- From the OS confirm free space on disks SELECT DISTINCT DB_NAME (S.DATABASE_ID) AS DATABASE_NAME, S.DATABASE_ID, S.VOLUME_MOUNT_POINT --, S.VOLUME_ID , S.LOGICAL_VOLUME_NAME , S.FILE_SYSTEM_TYPE , S.TOTAL_BYTES/1024/1024/1024 AS [TOTAL_SIZE (GB)] , S.AVAILABLE_BYTES/1024/1024/1024 AS [FREE_SPACE (GB)] , LEFT ((ROUND (((S.AVAILABLE_BYTES*1.0)/S.TOTAL_BYTES), 4)*100),4) AS PERCENT_FREE FROM SYS.MASTER_FILES AS F CROSS APPLY SYS.DM_OS_VOLUME_STATS (F.DATABASE_ID, F.FILE_ID) AS S WHERE DB_NAME (S.DATABASE_ID) = 'POST_OFFICE_HISTORY';

Abb. 8 Freier Speicherplatz auf dem Betriebssystem
Schlussfolgerung
In diesem Artikel haben wir eine exemplarische Vorgehensweise zum Austauschen von Partitionen aus einer partitionierten Tabelle durchgeführt. Dies ist eine sehr effiziente Möglichkeit, das Datenwachstum nativ in SQL Server zu verwalten. Fortgeschrittenere Technologien wie Stretch Database sind in aktuellen Versionen von SQL Server verfügbar.
Referenzen
Isakov, V. (2018). Prüfung Ref 70-764 Verwaltung einer SQL-Datenbankinfrastruktur. Pearson-Bildung
Partitionierte Tabellen und Indizes in SQL Server