Verwenden Sie SQL-Unterabfragen oder vermeiden Sie deren Verwendung?
Angenommen, der Chief Credit and Collections Officer bittet Sie, die Namen der Personen, ihre unbezahlten Salden pro Monat und den aktuellen laufenden Saldo aufzulisten, und möchte, dass Sie dieses Datenarray in Excel importieren. Der Zweck besteht darin, die Daten zu analysieren und ein Angebot zu erstellen, das Zahlungen vereinfacht, um die Auswirkungen der COVID19-Pandemie abzumildern.
Entscheiden Sie sich für eine Abfrage und eine verschachtelte Unterabfrage oder einen Join? Welche Entscheidung wirst du treffen?
SQL-Unterabfragen – Was sind sie?
Bevor wir uns eingehend mit Syntax, Auswirkungen auf die Leistung und Einschränkungen befassen, warum nicht zuerst eine Unterabfrage definieren?
Einfach ausgedrückt ist eine Unterabfrage eine Abfrage innerhalb einer Abfrage. Während eine Abfrage, die eine Unterabfrage verkörpert, die äußere Abfrage ist, bezeichnen wir eine Unterabfrage als innere Abfrage oder innere Auswahl. Und Klammern schließen eine Unterabfrage ähnlich der folgenden Struktur ein:
SELECT
col1
,col2
,(subquery) as col3
FROM table1
[JOIN table2 ON table1.col1 = table2.col2]
WHERE col1 <operator> (subquery)Wir werden uns in diesem Beitrag die folgenden Punkte ansehen:
- SQL-Unterabfragesyntax abhängig von verschiedenen Unterabfragetypen und Operatoren.
- Wann und in welcher Art von Anweisungen kann man eine Unterabfrage verwenden.
- Auswirkungen auf die Leistung im Vergleich zu JOINs .
- Allgemeine Vorbehalte bei der Verwendung von SQL-Unterabfragen.
Wie üblich liefern wir Beispiele und Illustrationen, um das Verständnis zu verbessern. Beachten Sie jedoch, dass der Schwerpunkt dieses Beitrags auf Unterabfragen in SQL Server liegt.
Fangen wir jetzt an.
Machen Sie SQL-Unterabfragen, die eigenständig oder korreliert sind
Zum einen werden Unterabfragen basierend auf ihrer Abhängigkeit von der äußeren Abfrage kategorisiert.
Lassen Sie mich beschreiben, was eine eigenständige Unterabfrage ist.
Eigenständige Unterabfragen (manchmal auch als nicht korrelierte oder einfache Unterabfragen bezeichnet) sind unabhängig von den Tabellen in der äußeren Abfrage. Lassen Sie mich das veranschaulichen:
-- Get sales orders of customers from Southwest United States
-- (TerritoryID = 4)
USE [AdventureWorks]
GO
SELECT CustomerID, SalesOrderID
FROM Sales.SalesOrderHeader
WHERE CustomerID IN (SELECT [CustomerID]
FROM [AdventureWorks].[Sales].[Customer]
WHERE TerritoryID = 4)Wie im obigen Code demonstriert, hat die Unterabfrage (unten in Klammern eingeschlossen) keine Verweise auf eine Spalte in der äußeren Abfrage. Außerdem können Sie die Unterabfrage in SQL Server Management Studio hervorheben und ausführen, ohne Laufzeitfehler zu erhalten.
Was wiederum zu einem einfacheren Debugging von eigenständigen Unterabfragen führt.
Das nächste, was zu berücksichtigen ist, sind korrelierte Unterabfragen. Im Vergleich zu seinem eigenständigen Gegenstück weist dieses mindestens eine Spalte auf, auf die von der äußeren Abfrage verwiesen wird. Zur Verdeutlichung gebe ich ein Beispiel:
USE [AdventureWorks]
GO
SELECT DISTINCT a.LastName, a.FirstName, b.BusinessEntityID
FROM Person.Person AS p
JOIN HumanResources.Employee AS e ON p.BusinessEntityID = e.BusinessEntityID
WHERE 1262000.00 IN
(SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE p.BusinessEntityID = spq.BusinessEntityID)Waren Sie aufmerksam genug, um den Verweis auf BusinessEntityID zu bemerken? von der Person Tisch? Gut gemacht!
Sobald eine Spalte aus der äußeren Abfrage in der Unterabfrage referenziert wird, wird sie zu einer korrelierten Unterabfrage. Ein weiterer zu beachtender Punkt:Wenn Sie eine Unterabfrage markieren und ausführen, tritt ein Fehler auf.
Und ja, Sie haben absolut Recht:Das macht korrelierte Unterabfragen ziemlich schwerer zu debuggen.
Führen Sie die folgenden Schritte aus, um das Debuggen zu ermöglichen:
- Unterabfrage isolieren.
- Ersetzen Sie die Referenz auf die äußere Abfrage durch einen konstanten Wert.
Wenn Sie die Unterabfrage zum Debuggen isolieren, sieht sie so aus:
SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE spq.BusinessEntityID = <constant value>Lassen Sie uns nun etwas tiefer in die Ausgabe von Unterabfragen eintauchen.
Erstellen Sie SQL-Unterabfragen mit 3 möglichen zurückgegebenen Werten
Nun, lassen Sie uns zuerst darüber nachdenken, welche zurückgegebenen Werte wir von SQL-Unterabfragen erwarten können.
Tatsächlich gibt es 3 mögliche Ergebnisse:
- Ein einzelner Wert
- Mehrere Werte
- Ganze Tabellen
Einzelwert
Beginnen wir mit der einwertigen Ausgabe. Diese Art von Unterabfrage kann überall in der äußeren Abfrage erscheinen, wo ein Ausdruck erwartet wird, wie z. B. WHERE Klausel.
-- Output a single value which is the maximum or last TransactionID
USE [AdventureWorks]
GO
SELECT TransactionID, ProductID, TransactionDate, Quantity
FROM Production.TransactionHistory
WHERE TransactionID = (SELECT MAX(t.TransactionID)
FROM Production.TransactionHistory t)Wenn Sie einen MAX verwenden ()-Funktion erhalten Sie einen einzelnen Wert. Genau das ist mit unserer obigen Unterabfrage passiert. Mit dem Gleichheitszeichen (= )-Operator teilt SQL Server mit, dass Sie einen einzelnen Wert erwarten. Eine andere Sache:Wenn die Unterabfrage mehrere Werte mit dem Gleichheitszeichen (= )-Operator erhalten Sie einen Fehler ähnlich wie unten:
Msg 512, Level 16, State 1, Line 20
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.Mehrere Werte
Als nächstes untersuchen wir die mehrwertige Ausgabe. Diese Art von Unterabfrage gibt eine Liste von Werten mit einer einzigen Spalte zurück. Außerdem Operatoren wie IN und NICHT IN erwartet einen oder mehrere Werte.
-- Output multiple values which is a list of customers with lastnames that --- start with 'I'
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.lastname LIKE N'I%' AND p.PersonType='SC')Ganze Tabellenwerte
Und last but not least, warum nicht in ganze Tabellenausgaben eintauchen.
-- Output a table of values based on sales orders
USE [AdventureWorks]
GO
SELECT [ShipYear],
COUNT(DISTINCT [CustomerID]) AS CustomerCount
FROM (SELECT YEAR([ShipDate]) AS [ShipYear], [CustomerID]
FROM Sales.SalesOrderHeader) AS Shipments
GROUP BY [ShipYear]
ORDER BY [ShipYear]Haben Sie das FROM bemerkt? Klausel?
Anstelle einer Tabelle wurde eine Unterabfrage verwendet. Dies wird als abgeleitete Tabelle oder Tabellenunterabfrage bezeichnet.
Lassen Sie mich Ihnen nun einige Grundregeln für die Verwendung dieser Art von Abfrage vorstellen:
- Alle Spalten in der Unterabfrage sollten eindeutige Namen haben. Ähnlich wie eine physische Tabelle sollte eine abgeleitete Tabelle eindeutige Spaltennamen haben.
- BESTELLEN VON ist nicht zulässig, es sei denn TOP ist ebenfalls angegeben. Das liegt daran, dass die abgeleitete Tabelle eine relationale Tabelle darstellt, in der Zeilen keine definierte Reihenfolge haben.
In diesem Fall hat eine abgeleitete Tabelle die Vorteile einer physischen Tabelle. Deshalb können wir in unserem Beispiel COUNT verwenden () in einer der Spalten der abgeleiteten Tabelle.
Das ist ungefähr alles in Bezug auf die Ausgaben von Unterabfragen. Aber bevor wir weitermachen, haben Sie vielleicht bemerkt, dass die Logik hinter dem Beispiel für mehrere Werte und andere auch mit einem JOIN ausgeführt werden kann .
-- Output multiple values which is a list of customers with lastnames that start with 'I'
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.LastName LIKE N'I%' AND p.PersonType = 'SC'Tatsächlich wird die Ausgabe dieselbe sein. Aber welches ist besser?
Bevor wir darauf eingehen, lassen Sie mich Ihnen sagen, dass ich diesem heißen Thema einen Abschnitt gewidmet habe. Wir werden es mit vollständigen Ausführungsplänen untersuchen und uns Abbildungen ansehen.
Also ertragen Sie mich einen Moment lang. Lassen Sie uns eine andere Möglichkeit besprechen, Ihre Unterabfragen zu platzieren.
Andere Anweisungen, bei denen Sie SQL-Unterabfragen verwenden können
Bisher haben wir SQL-Unterabfragen für SELECT verwendet Aussagen. Und die Sache ist die, dass Sie die Vorteile von Unterabfragen auf INSERT genießen können , AKTUALISIEREN und LÖSCHEN -Anweisungen oder in einer beliebigen T-SQL-Anweisung, die einen Ausdruck bildet.
Schauen wir uns also eine Reihe weiterer Beispiele an.
Verwenden von SQL-Unterabfragen in UPDATE-Anweisungen
Es ist ganz einfach, Unterabfragen in UPDATE einzufügen Aussagen. Warum schauen Sie sich dieses Beispiel nicht an?
-- In the products inventory, transfer all products of Vendor 1602 to ----
-- location 6
USE [AdventureWorks]
GO
UPDATE [Production].[ProductInventory]
SET LocationID = 6
WHERE ProductID IN
(SELECT ProductID
FROM Purchasing.ProductVendor
WHERE BusinessEntityID = 1602)
GOHast du gesehen, was wir dort gemacht haben?
Die Sache ist die, dass Sie Unterabfragen im WHERE platzieren können Klausel eines UPDATE Aussage.
Da wir es im Beispiel nicht haben, können Sie auch eine Unterabfrage für das SET verwenden Klausel wie SET Spalte =(Unterabfrage) . Aber seien Sie gewarnt:Es sollte einen einzelnen Wert ausgeben, da sonst ein Fehler auftritt.
Was machen wir als nächstes?
Verwenden von SQL-Unterabfragen in INSERT-Anweisungen
Wie Sie bereits wissen, können Sie mit einem SELECT Datensätze in eine Tabelle einfügen Erklärung. Ich bin sicher, Sie haben eine Vorstellung davon, wie die Struktur der Unterabfrage aussehen wird, aber lassen Sie uns dies anhand eines Beispiels demonstrieren:
-- Impose a salary increase for all employees in DepartmentID 6
-- (Research and Development) by 10 (dollars, I think)
-- effective June 1, 2020
USE [AdventureWorks]
GO
INSERT INTO [HumanResources].[EmployeePayHistory]
([BusinessEntityID]
,[RateChangeDate]
,[Rate]
,[PayFrequency]
,[ModifiedDate])
SELECT
a.BusinessEntityID
,'06/01/2020' as RateChangeDate
,(SELECT MAX(b.Rate) FROM [HumanResources].[EmployeePayHistory] b
WHERE a.BusinessEntityID = b.BusinessEntityID) + 10 as NewRate
,2 as PayFrequency
,getdate() as ModifiedDate
FROM [HumanResources].[EmployeeDepartmentHistory] a
WHERE a.DepartmentID = 6
and StartDate = (SELECT MAX(c.StartDate)
FROM HumanResources.EmployeeDepartmentHistory c
WHERE c.BusinessEntityID = a.BusinessEntityID)Also, was sehen wir uns hier an?
- Die erste Unterabfrage ruft den letzten Gehaltssatz eines Mitarbeiters ab, bevor die zusätzlichen 10 hinzugefügt werden.
- Die zweite Unterabfrage ruft den letzten Gehaltsdatensatz des Mitarbeiters ab.
- Zu guter Letzt das Ergebnis des SELECT wird in die EmployeePayHistory eingefügt Tabelle.
In anderen T-SQL-Anweisungen
Abgesehen von SELECT , EINFÜGEN , AKTUALISIEREN und LÖSCHEN , können Sie im Folgenden auch SQL-Unterabfragen verwenden:
Variablendeklarationen oder SET-Anweisungen in gespeicherten Prozeduren und Funktionen
Lassen Sie mich anhand dieses Beispiels verdeutlichen:
DECLARE @maxTransId int = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)Alternativ können Sie dies auch folgendermaßen tun:
DECLARE @maxTransId int
SET @maxTransId = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)In bedingten Ausdrücken
Sehen Sie sich dieses Beispiel an:
IF EXISTS(SELECT [Name] FROM sys.tables where [Name] = 'MyVendors')
BEGIN
DROP TABLE MyVendors
ENDAbgesehen davon können wir es so machen:
IF (SELECT count(*) FROM MyVendors) > 0
BEGIN
-- insert code here
ENDErstellen Sie SQL-Unterabfragen mit Vergleichs- oder logischen Operatoren
Bisher haben wir das Gleiche gesehen (= )-Operator und der IN-Operator. Aber es gibt noch viel mehr zu entdecken.
Verwendung von Vergleichsoperatoren
Wenn ein Vergleichsoperator wie =, <,>, <>,>=oder <=mit einer Unterabfrage verwendet wird, sollte die Unterabfrage einen einzelnen Wert zurückgeben. Außerdem tritt ein Fehler auf, wenn die Unterabfrage mehrere Werte zurückgibt.
Das folgende Beispiel generiert einen Laufzeitfehler.
USE [AdventureWorks]
GO
SELECT b.LastName, b.FirstName, b.MiddleName, a.JobTitle, a.BusinessEntityID
FROM HumanResources.Employee a
INNER JOIN Person.Person b on a.BusinessEntityID = b.BusinessEntityID
INNER JOIN HumanResources.EmployeeDepartmentHistory c on a.BusinessEntityID
= c.BusinessEntityID
WHERE c.DepartmentID = 6
and StartDate = (SELECT d.StartDate
FROM HumanResources.EmployeeDepartmentHistory d
WHERE d.BusinessEntityID = a.BusinessEntityID)Wissen Sie, was im obigen Code falsch ist?
Zunächst verwendet der Code den Gleichheitsoperator (=) mit der Unterabfrage. Außerdem gibt die Unterabfrage eine Liste mit Startdaten zurück.
Um das Problem zu beheben, verwenden Sie für die Unterabfrage eine Funktion wie MAX () in der Startdatumsspalte, um einen einzelnen Wert zurückzugeben.
Logische Operatoren verwenden
Verwendung von EXISTS oder NOT EXISTS
EXISTIERT gibt WAHR zurück wenn die Unterabfrage Zeilen zurückgibt. Andernfalls wird FALSE zurückgegeben . Verwenden Sie in der Zwischenzeit NOT EXISTIERT gibt TRUE zurück wenn es keine Zeilen gibt und FALSE , andernfalls.
Betrachten Sie das folgende Beispiel:
IF EXISTS(SELECT name FROM sys.tables where name = 'Token')
BEGIN
DROP TABLE Token
ENDLassen Sie mich zunächst erklären. Der obige Code löscht das Tabellen-Token, wenn es in sys.tables gefunden wird , dh wenn es in der Datenbank vorhanden ist. Ein weiterer Punkt:Der Verweis auf den Spaltennamen ist irrelevant.
Warum ist das so?
Es stellt sich heraus, dass die Datenbank-Engine nur mindestens 1 Zeile mit EXISTS abrufen muss . Wenn in unserem Beispiel die Unterabfrage eine Zeile zurückgibt, wird die Tabelle gelöscht. Wenn die Unterabfrage andererseits keine einzige Zeile zurückgibt, werden die nachfolgenden Anweisungen nicht ausgeführt.
Somit ist die Sorge von EXISTIERT ist nur Zeilen und keine Spalten.
Außerdem EXISTIERT verwendet zweiwertige Logik:WAHR oder FALSCH . Es gibt keine Fälle, in denen NULL zurückgegeben wird . Dasselbe passiert, wenn Sie EXISTS negieren mit NICHT .
Mit IN oder NOT IN
Eine mit IN eingeleitete Unterabfrage oder NICHT IN gibt eine Liste mit null oder mehr Werten zurück. Und im Gegensatz zu EXISTS , ist eine gültige Spalte mit dem entsprechenden Datentyp erforderlich.
Lassen Sie mich dies an einem anderen Beispiel verdeutlichen:
-- From the product inventory, extract the products that are available
-- (Quantity >0)
-- except for products from Vendor 1676, and introduce a price cut for the --- whole month of June 2020.
-- Insert the results in product price history.
USE [AdventureWorks]
GO
INSERT INTO [Production].[ProductListPriceHistory]
([ProductID]
,[StartDate]
,[EndDate]
,[ListPrice]
,[ModifiedDate])
SELECT
a.ProductID
,'06/01/2020' as StartDate
,'06/30/2020' as EndDate
,a.ListPrice - 2 as ReducedListPrice
,getdate() as ModifiedDate
FROM [Production].[ProductListPriceHistory] a
WHERE a.StartDate = (SELECT MAX(StartDate)
FROM Production.ProductListPriceHistory
WHERE ProductID = a.ProductID)
AND a.ProductID IN (SELECT ProductID
FROM Production.ProductInventory
WHERE Quantity > 0)
AND a.ProductID NOT IN (SELECT ProductID
FROM [Purchasing].[ProductVendor]
WHERE BusinessEntityID = 1676Wie Sie dem obigen Code entnehmen können, sind beide IN und NICHT IN Betreiber eingeführt werden. Und in beiden Fällen werden Zeilen zurückgegeben. Jede Zeile in der äußeren Abfrage wird mit dem Ergebnis jeder Unterabfrage abgeglichen, um ein verfügbares Produkt und ein Produkt zu erhalten, das nicht von Anbieter 1676 stammt.
Verschachtelung von SQL-Unterabfragen
Sie können Unterabfragen sogar bis zu 32 Ebenen verschachteln. Diese Funktion hängt jedoch vom verfügbaren Arbeitsspeicher des Servers und der Komplexität anderer Ausdrücke in der Abfrage ab.
Was halten Sie davon?
Nach meiner Erfahrung kann ich mich nicht erinnern, bis zu 4 verschachtelt zu haben. Ich verwende selten 2 oder 3 Ebenen. Aber das bin nur ich und meine Anforderungen.
Wie wäre es mit einem guten Beispiel, um das herauszufinden:
-- List down the names of employees who are also customers.
USE [AdventureWorks]
GO
SELECT
LastName
,FirstName
,MiddleName
FROM Person.Person
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Sales.Customer
WHERE BusinessEntityID IN
(SELECT BusinessEntityID
FROM HumanResources.Employee))Wie wir in diesem Beispiel sehen können, hat die Verschachtelung 2 Ebenen erreicht.
Sind SQL-Unterabfragen schlecht für die Leistung?
Kurz gesagt:ja und nein. Mit anderen Worten, es kommt darauf an.
Und vergessen Sie nicht, dies ist im Kontext von SQL Server.
Zunächst einmal können viele T-SQL-Anweisungen, die Unterabfragen verwenden, alternativ mit JOIN umgeschrieben werden s. Und die Leistung für beide ist normalerweise gleich. Trotzdem gibt es bestimmte Fälle, in denen ein Join schneller ist. Und es gibt Fälle, in denen die Unterabfrage schneller arbeitet.
Beispiel 1
Sehen wir uns ein Beispiel für eine Unterabfrage an. Bevor Sie sie ausführen, drücken Sie Strg-M oder aktivieren Sie Aktuellen Ausführungsplan einschließen aus der Symbolleiste von SQL Server Management Studio.
USE [AdventureWorks]
GO
SELECT Name
FROM Production.Product
WHERE ListPrice = SELECT ListPrice
FROM Production.Product
WHERE Name = 'Touring End Caps')Alternativ kann die obige Abfrage mit einem Join umgeschrieben werden, der das gleiche Ergebnis liefert.
USE [AdventureWorks]
GO
SELECT Prd1.Name
FROM Production.Product AS Prd1
INNER JOIN Production.Product AS Prd2 ON (Prd1.ListPrice = Prd2.ListPrice)
WHERE Prd2.Name = 'Touring End Caps'Am Ende sind das Ergebnis für beide Abfragen 200 Zeilen.
Außerdem können Sie sich den Ausführungsplan für beide Anweisungen ansehen.
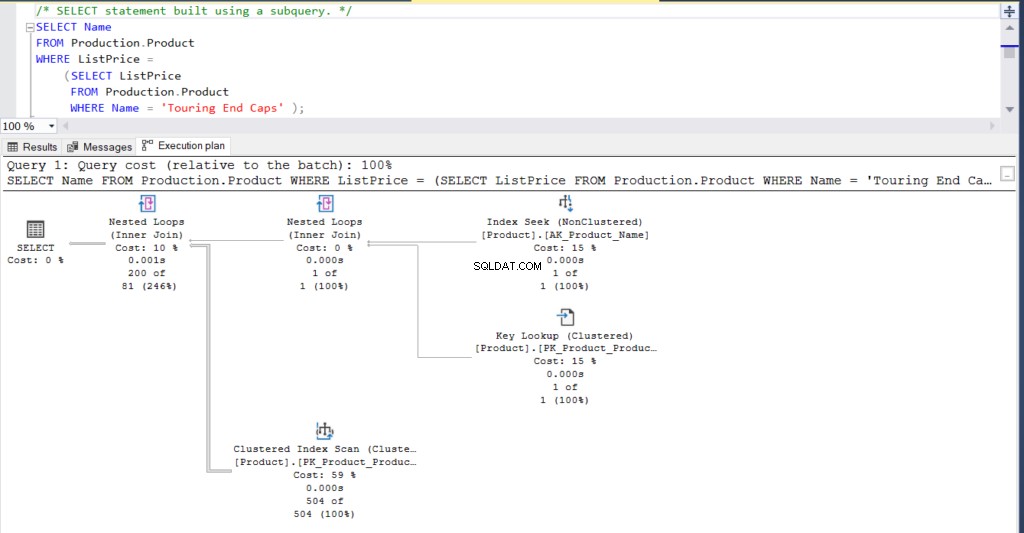
Abbildung 1:Ausführungsplan mit einer Unterabfrage
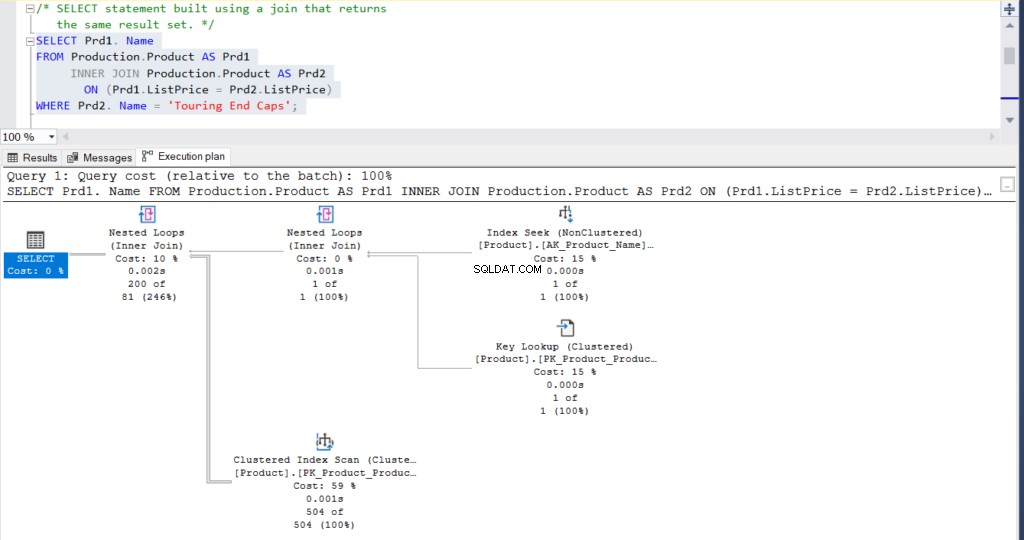
Abbildung 2:Ausführungsplan mit einem Join
Was denkst du? Sind sie praktisch gleich? Abgesehen von der tatsächlich verstrichenen Zeit jedes Knotens ist alles andere im Grunde gleich.
Aber hier ist eine andere Möglichkeit, es abgesehen von visuellen Unterschieden zu vergleichen. Ich schlage vor, den Showplan vergleichen zu verwenden .
Führen Sie dazu die folgenden Schritte aus:
- Klicken Sie mit der rechten Maustaste auf den Ausführungsplan der Anweisung, die die Unterabfrage verwendet.
- Wählen Sie Ausführungsplan speichern unter .
- Nennen Sie die Datei subquery-execution-plan.sqlplan .
- Gehen Sie zum Ausführungsplan der Anweisung, die einen Join verwendet, und klicken Sie mit der rechten Maustaste darauf.
- Wählen Sie Showplan vergleichen aus .
- Wählen Sie den Dateinamen aus, den Sie in #3 gespeichert haben.
Hier finden Sie weitere Informationen zu Showplan vergleichen .
Sie sollten in der Lage sein, etwas Ähnliches zu sehen:
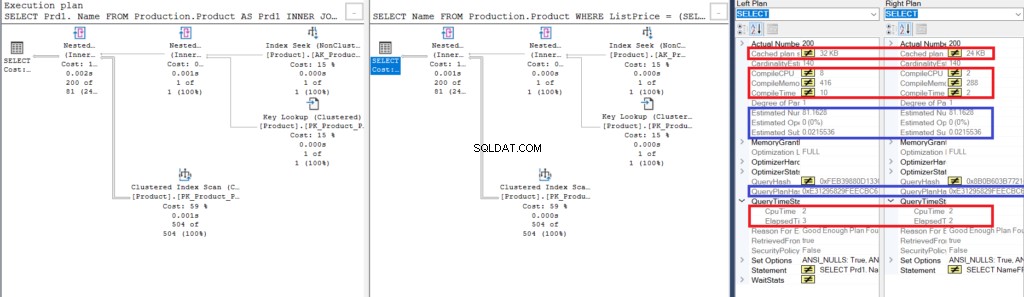
Abbildung 3:Vergleichen Sie Showplan für die Verwendung eines Joins mit der Verwendung einer Unterabfrage
Beachten Sie die Ähnlichkeiten:
- Geschätzte Zeilen und Kosten sind gleich.
- QueryPlanHash ist auch gleich, was bedeutet, dass sie ähnliche Ausführungspläne haben.
Beachten Sie dennoch die Unterschiede:
- Die Größe des Cacheplans ist bei Verwendung des Joins größer als bei Verwendung der Unterabfrage
- Die Kompilier-CPU und -Zeit (in ms), einschließlich des Arbeitsspeichers in KB, die zum Analysieren, Binden und Optimieren des Ausführungsplans verwendet werden, ist bei Verwendung des Joins höher als bei der Verwendung der Unterabfrage
- Die CPU-Zeit und die verstrichene Zeit (in ms) zum Ausführen des Plans ist bei Verwendung der Verknüpfung etwas höher als bei der Unterabfrage
In diesem Beispiel ist die Unterabfrage ein Tick schneller als der Join, obwohl die resultierenden Zeilen gleich sind.
Beispiel 2
Im vorherigen Beispiel haben wir nur eine Tabelle verwendet. Im folgenden Beispiel verwenden wir 3 verschiedene Tabellen.
Machen wir das möglich:
-- Subquery example
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID =
p.BusinessEntityID
WHERE p.PersonType='SC')-- Join example
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'Beide Abfragen geben die gleichen 3806 Zeilen aus.
Als nächstes werfen wir einen Blick auf ihre Ausführungspläne:
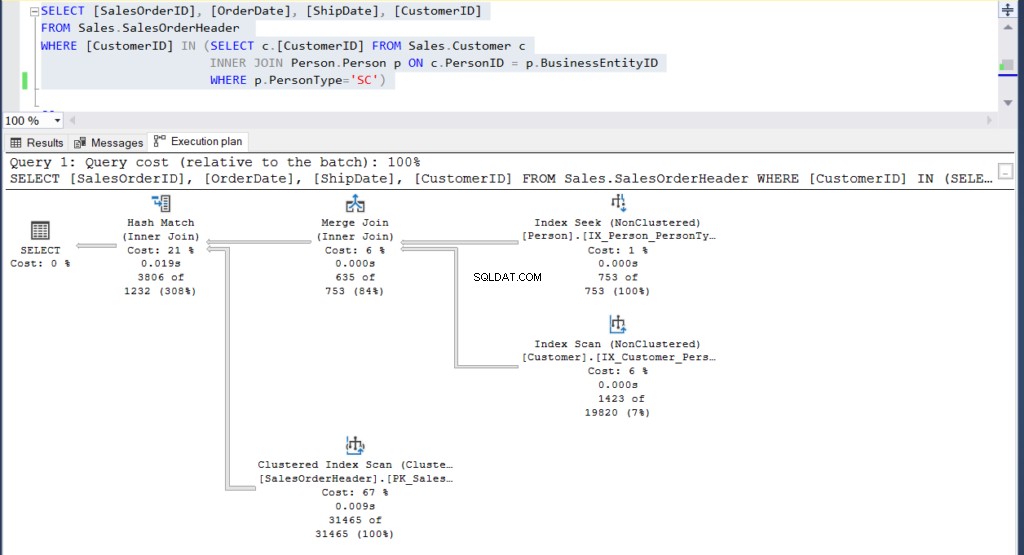
Abbildung 4:Ausführungsplan für unser zweites Beispiel mit einer Unterabfrage
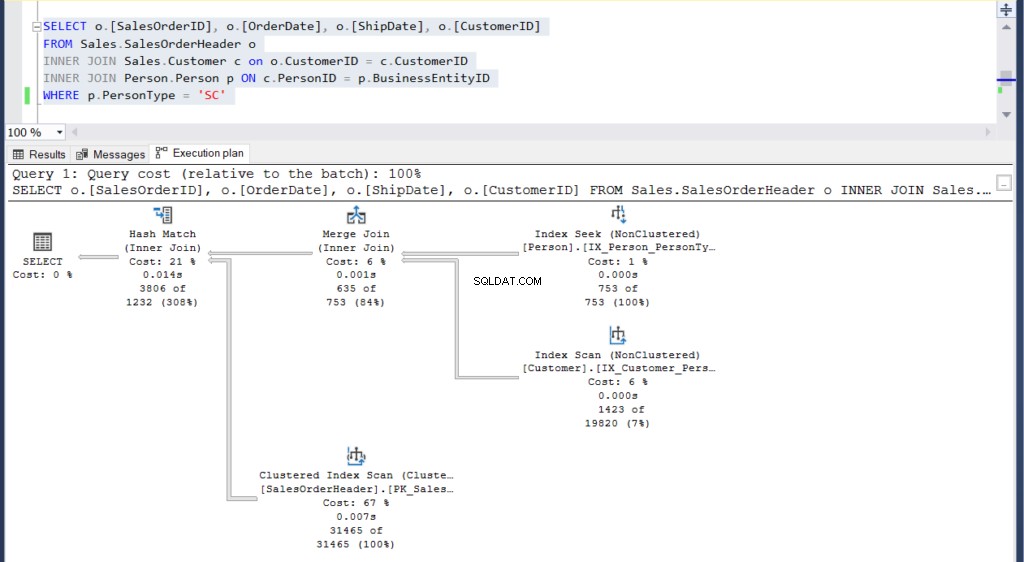
Abbildung 5:Ausführungsplan für unser zweites Beispiel mit einem Join
Können Sie die 2 Ausführungspläne sehen und Unterschiede zwischen ihnen feststellen? Auf den ersten Blick sehen sie gleich aus.
Aber eine genauere Prüfung mit dem Showplan vergleichen zeigt, was wirklich drin ist.
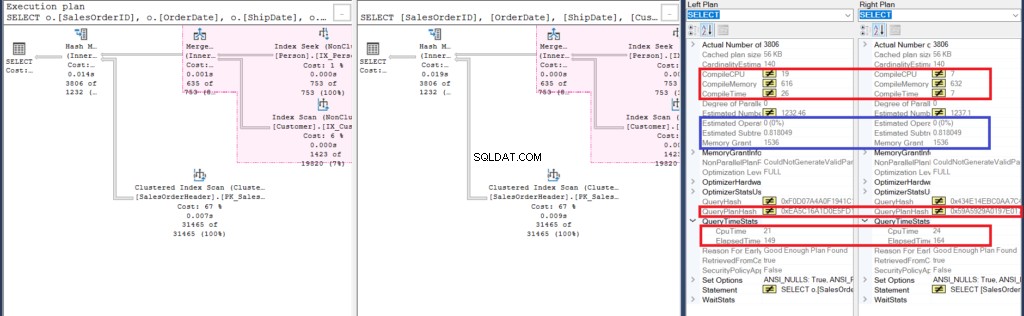
Abbildung 6:Details des Showplan-Vergleichs für das zweite Beispiel
Beginnen wir mit der Analyse einiger Ähnlichkeiten:
- Die rosa Hervorhebung im Ausführungsplan zeigt ähnliche Vorgänge für beide Abfragen. Da die innere Abfrage einen Join anstelle von verschachtelten Unterabfragen verwendet, ist dies durchaus verständlich.
- Die geschätzten Operator- und Teilbaumkosten sind gleich.
Als nächstes werfen wir einen Blick auf die Unterschiede:
- Erstens dauerte die Kompilierung länger, wenn wir Joins verwendeten. Sie können dies in der Kompilierungs-CPU und der Kompilierungszeit überprüfen. Die Abfrage mit einer Unterabfrage hat jedoch einen höheren Compile Memory in KB benötigt.
- Dann ist der QueryPlanHash beider Abfragen unterschiedlich, was bedeutet, dass sie einen unterschiedlichen Ausführungsplan haben.
- Zu guter Letzt sind die verstrichene Zeit und die CPU-Zeit zum Ausführen des Plans schneller mit dem Join als eine Unterabfrage.
Unterabfrage vs. Join-Leistungsmitnahme
Wahrscheinlich werden Sie mit zu vielen anderen abfragebezogenen Problemen konfrontiert, die durch die Verwendung eines Joins oder einer Unterabfrage gelöst werden können.
Aber unter dem Strich ist eine Unterabfrage im Vergleich zu Joins nicht von Natur aus schlecht. Und es gibt keine Faustregel, dass in einer bestimmten Situation ein Join besser ist als eine Unterabfrage oder umgekehrt.
Um sicherzustellen, dass Sie die beste Wahl haben, überprüfen Sie die Ausführungspläne. Der Zweck besteht darin, einen Einblick zu gewinnen, wie SQL Server eine bestimmte Abfrage verarbeitet.
Wenn Sie sich jedoch für die Verwendung einer Unterabfrage entscheiden, sollten Sie sich bewusst sein, dass Probleme auftreten können, die Ihre Fähigkeiten auf die Probe stellen werden.
Häufige Vorbehalte bei der Verwendung von SQL-Unterabfragen
Es gibt 2 häufige Probleme, die dazu führen können, dass sich Ihre Abfragen bei der Verwendung von SQL-Unterabfragen wild verhalten.
Der Schmerz der Spaltennamenauflösung
Dieses Problem führt logische Fehler in Ihre Abfragen ein, und es kann sehr schwierig sein, sie zu finden. Ein Beispiel kann dieses Problem weiter verdeutlichen.
Beginnen wir damit, eine Tabelle zu Demozwecken zu erstellen und sie mit Daten zu füllen.
USE [AdventureWorks]
GO
-- Create the table for our demonstration based on Vendors
CREATE TABLE Purchasing.MyVendors
(
BusinessEntity_id int,
AccountNumber nvarchar(15),
Name nvarchar(50)
)
GO
-- Populate some data to our new table
INSERT INTO Purchasing.MyVendors
SELECT BusinessEntityID, AccountNumber, Name
FROM Purchasing.Vendor
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.ProductVendor)
AND BusinessEntityID like '14%'
GONachdem die Tabelle nun eingerichtet ist, feuern wir einige Unterabfragen damit ab. Aber bevor Sie die folgende Abfrage ausführen, denken Sie daran, dass die Anbieter-IDs, die wir aus dem vorherigen Code verwendet haben, mit „14“ beginnen.
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.MyVendors)Der obige Code läuft ohne Fehler, wie Sie unten sehen können. Achten Sie auf jeden Fall auf die Liste der BusinessEntityIDs .
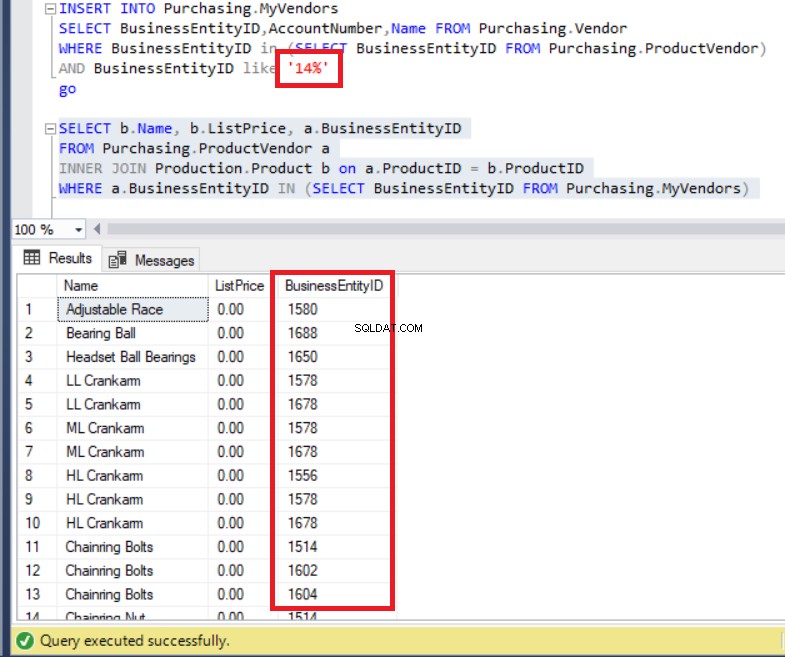
Abbildung 7:BusinessEntityIDs der Ergebnismenge stimmen nicht mit den Datensätzen der MyVendors-Tabelle überein
Haben wir nicht Daten mit BusinessEntityID eingefügt? beginnend mit '14'? Was ist dann los? Tatsächlich können wir BusinessEntityIDs sehen die mit '15' und '16' beginnen. Woher kommen diese?
Tatsächlich listete die Abfrage alle Daten von ProductVendor auf Tabelle.
In diesem Fall könnten Sie denken, dass ein Alias dieses Problem löst, sodass er auf MyVendors verweist Tabelle wie die folgende:
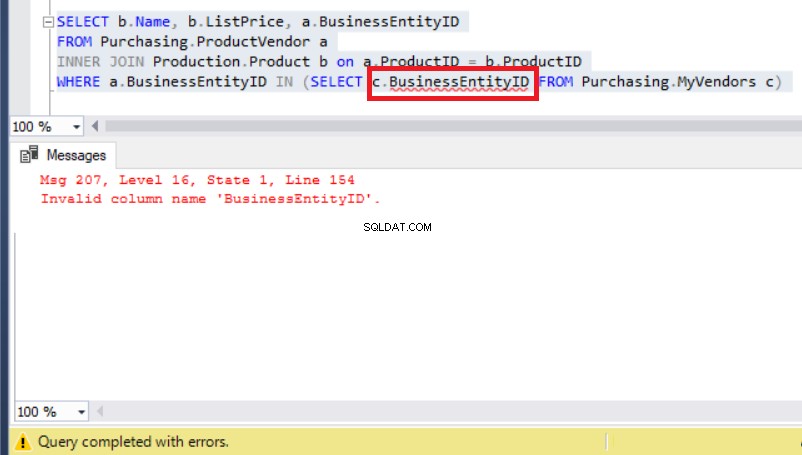
Abbildung 8:Das Hinzufügen eines Alias zur BusinessEntityID führt zu einem Fehler
Nur dass sich jetzt das eigentliche Problem aufgrund eines Laufzeitfehlers zeigte.
Prüfen Sie MyVendors Tabelle erneut und Sie sehen das anstelle von BusinessEntityID , muss der Spaltenname BusinessEntity_id lauten (mit einem Unterstrich).
Daher wird die Verwendung des richtigen Spaltennamens dieses Problem endgültig beheben, wie Sie unten sehen können:
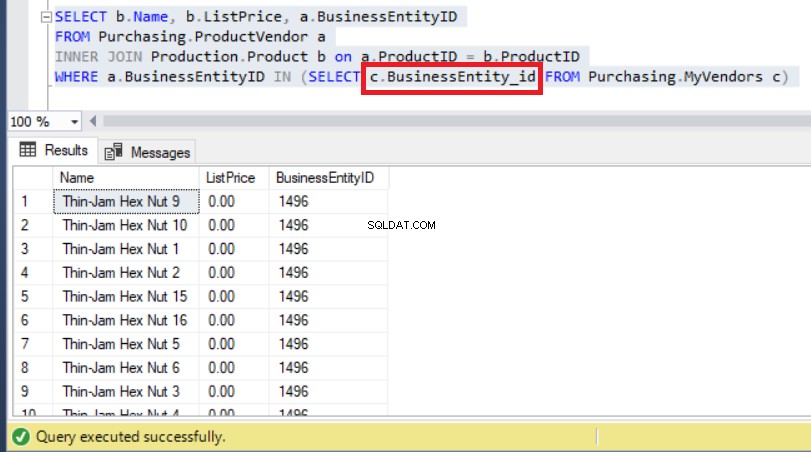
Abbildung 9:Das Ändern der Unterabfrage mit dem richtigen Spaltennamen löste das Problem
Wie Sie oben sehen können, können wir jetzt BusinessEntityIDs beobachten beginnend mit '14', wie wir es vorher erwartet haben.
Aber Sie fragen sich vielleicht:Warum um alles in der Welt hat SQL Server überhaupt zugelassen, dass die Abfrage erfolgreich ausgeführt wird?
Hier ist der Clou:Die Auflösung von Spaltennamen ohne Alias funktioniert im Kontext der Subquery von an sich ausgehend zur äußeren Query. Deshalb der Verweis auf BusinessEntityID innerhalb der Unterabfrage hat keinen Fehler ausgelöst, da sie außerhalb der Unterabfrage gefunden wird – im ProductVendor Tabelle.
Mit anderen Worten, SQL Server sucht nach der Spalte BusinessEntityID ohne Alias in Meine Anbieter Tisch. Da es nicht dort ist, hat es nach draußen gesucht und es im ProductVendor gefunden Tisch. Verrückt, nicht wahr?
Man könnte sagen, dass dies ein Fehler in SQL Server ist, aber tatsächlich ist es im SQL-Standard vorgesehen und Microsoft hat sich daran gehalten.
In Ordnung, das ist klar, wir können nichts gegen den Standard tun, aber wie können wir vermeiden, dass ein Fehler auftritt?
- Stellen Sie zuerst den Spaltennamen den Tabellennamen voran oder verwenden Sie einen Alias. Mit anderen Worten, vermeiden Sie Tabellennamen ohne Präfix oder Alias.
- Zweitens, haben Sie eine konsistente Benennung der Spalten. Vermeiden Sie es, sowohl BusinessEntityID zu haben und BusinessEntity_id , zum Beispiel.
Hört sich gut an? Ja, das bringt etwas Vernunft in die Situation.
Aber das ist noch nicht alles.
Verrückte NULLen
Wie ich bereits erwähnt habe, gibt es noch mehr zu entdecken. T-SQL verwendet 3-wertige Logik wegen seiner Unterstützung für NULL . Und NULL kann uns fast verrückt machen, wenn wir SQL-Unterabfragen mit NOT IN verwenden .
Lassen Sie mich mit diesem Beispiel beginnen:
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c)Die Ausgabe der Abfrage führt uns zu einer Liste von Produkten, die nicht in MyVendors enthalten sind Tabelle., wie unten zu sehen:
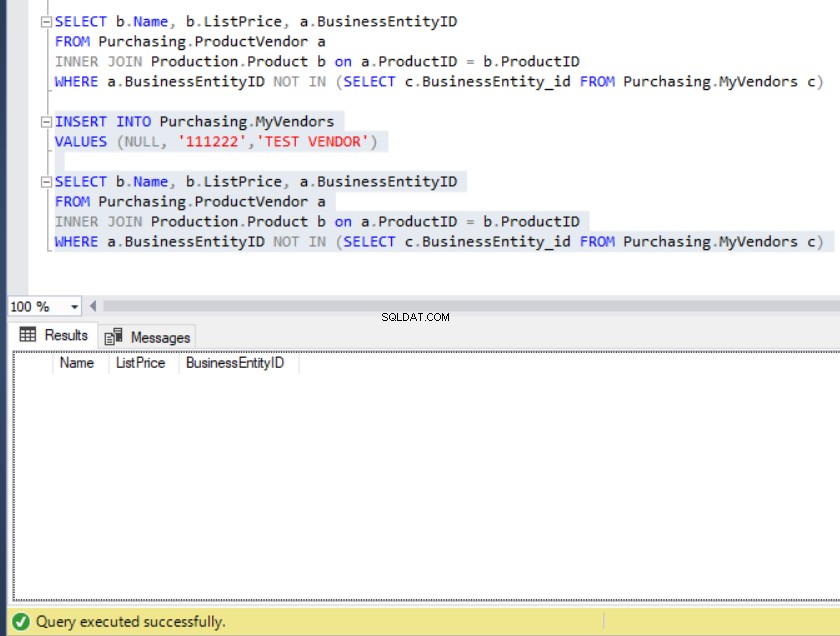
Abbildung 10:Die Ausgabe der Beispielabfrage mit NOT IN
Angenommen, jemand hat unbeabsichtigt einen Datensatz in MyVendors eingefügt Tabelle mit einem NULL BusinessEntity_id . Was werden wir dagegen tun?
Abbildung 11:Die Ergebnismenge wird leer, wenn eine NULL BusinessEntity_id in MyVendors eingefügt wird
Wo sind all die Daten hin?
Sie sehen, das NICHT Operator hat das IN negiert Prädikat. Also NICHT WAHR wird nun zu FALSE . Aber NICHT NULL ist unbekannt. Das hat dazu geführt, dass der Filter die UNBEKANNTEN Zeilen verworfen hat, und das ist der Übeltäter.
Um sicherzustellen, dass Ihnen das nicht passiert:
- Entweder die Tabellenspalte NULLs verbieten lassen wenn Daten nicht so sein sollen.
- Oder fügen Sie den Spaltennamen hinzu IST NICHT NULL zu Ihrem WO Klausel. In unserem Fall lautet die Unterabfrage wie folgt:
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c
WHERE c.BusinessEntity_id IS NOT NULL)Imbiss
Wir haben ziemlich viel über Unterabfragen gesprochen, und jetzt ist es an der Zeit, die wichtigsten Erkenntnisse aus diesem Beitrag in Form einer zusammengefassten Liste bereitzustellen:
Eine Unterabfrage:
- ist eine Abfrage innerhalb einer Abfrage.
- ist in Klammern eingeschlossen.
- kann einen Ausdruck überall ersetzen.
- kann in SELECT verwendet werden , EINFÜGEN , AKTUALISIEREN , LÖSCHEN, oder andere T-SQL-Anweisungen.
- kann eigenständig oder korreliert sein.
- gibt einzelne, mehrere oder Tabellenwerte aus.
- arbeitet mit Vergleichsoperatoren wie =, <>,>, <,>=, <=und logischen Operatoren wie IN /NICHT IN und EXISTIERT /EXISTIERT NICHT .
- ist nicht schlecht oder böse. Es kann besser oder schlechter abschneiden als JOIN s abhängig von einer Situation. Also nimm meinen Rat an und überprüfe immer die Ausführungspläne.
- kann bei NULL ein unangenehmes Verhalten zeigen s bei Verwendung mit NOT IN , und wenn eine Spalte nicht explizit mit einer Tabelle oder einem Tabellenalias identifiziert wird.
Get familiarized with several additional references for your reading pleasure:
- Discussion of Subqueries from Microsoft.
- IN (Transact-SQL)
- EXISTS (Transact-SQL)
- ALL (Transact-SQL)
- SOME | ANY (Transact-SQL)
- Comparison Operators