Ein Beispiel, wo dies einen Unterschied machen kann, ist, dass es eine Leistungsoptimierung verhindern kann, die das Hinzufügen von Zeilenversionsinformationen zu Tabellen mit After-Triggern vermeidet.
Dies wird hier von Paul White abgedeckt
Die tatsächliche Größe der gespeicherten Daten ist unerheblich – entscheidend ist die potenzielle Größe.
Ebenso war es bei der Verwendung von speicheroptimierten Tabellen seit 2016 möglich, LOB-Spalten oder Kombinationen von Spaltenbreiten zu verwenden, die möglicherweise das Inrow-Limit überschreiten könnten, jedoch mit einem Nachteil.
(Max) Spalten werden immer Off-Row gespeichert. Wenn bei anderen Spalten die Datenzeilengröße in der Tabellendefinition 8.060 Byte überschreiten kann, verschiebt SQL Server die größte(n) Spalte(n) mit variabler Länge außerhalb der Zeile. Auch hier kommt es nicht auf die Menge der Daten an, die Sie dort speichern.
Dies kann sich stark negativ auf den Speicherverbrauch und die Leistung auswirken
Ein weiterer Fall, in dem das Überdeklarieren von Spaltenbreiten einen großen Unterschied machen kann, ist, ob die Tabelle jemals mit SSIS verarbeitet wird. Der für Spalten mit variabler Länge (nicht BLOB) zugewiesene Speicher ist für jede Zeile in einem Ausführungsbaum festgelegt und entspricht der deklarierten maximalen Länge der Spalten, was zu einer ineffizienten Nutzung von Speicherpuffern führen kann (Beispiel). Während der SSIS-Paketentwickler eine kleinere Spaltengröße als die Quelle deklarieren kann, wird diese Analyse am besten im Voraus durchgeführt und dort durchgesetzt.
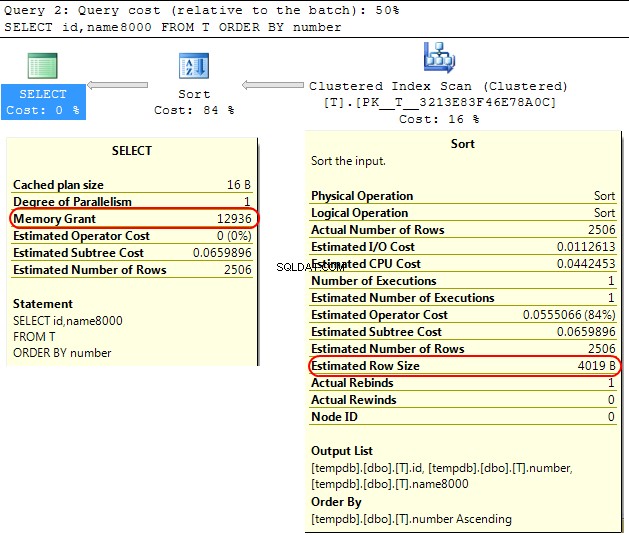
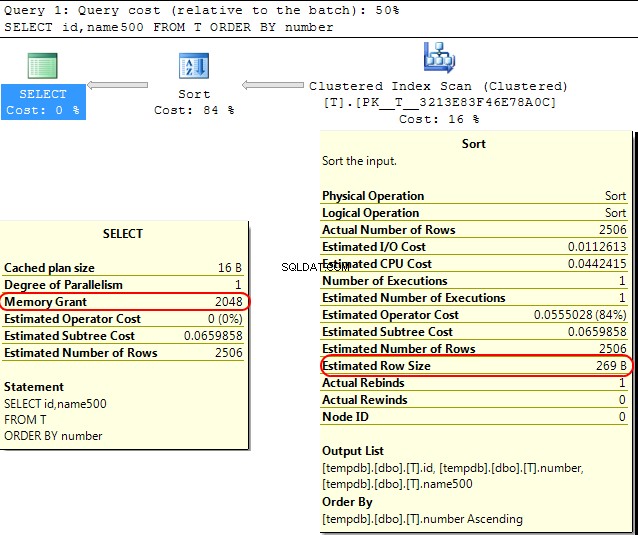
Zurück in der SQL Server-Engine selbst liegt ein ähnlicher Fall vor, wenn die Speicherzuweisung für SORT berechnet wird Operationen SQL Server geht davon aus, dass varchar(x) Spalten verbrauchen im Durchschnitt x/2 Bytes.
Wenn die meisten Ihrer varchar Spalten voller sind, als dass dies zum sort führen kann Operationen, die zu tempdb überlaufen .
In Ihrem Fall, wenn Ihr varchar Spalten werden als 8000 deklariert Bytes, aber tatsächlich viel weniger Inhalt haben, als dass Ihrer Abfrage Speicher zugewiesen wird, den sie nicht benötigt, was offensichtlich ineffizient ist und zu Wartezeiten auf Speicherzuweisungen führen kann.
Dies wird in Teil 2 des SQL Workshops Webcast 1 behandelt, der hier heruntergeladen werden kann oder unten steht.
use tempdb;
CREATE TABLE T(
id INT IDENTITY(1,1) PRIMARY KEY,
number int,
name8000 VARCHAR(8000),
name500 VARCHAR(500))
INSERT INTO T
(number,name8000,name500)
SELECT number, name, name /*<--Same contents in both cols*/
FROM master..spt_values
SELECT id,name500
FROM T
ORDER BY number
SELECT id,name8000
FROM T
ORDER BY number