Das Speichern von ~3,5 TB Daten und das Einfügen von etwa 1K/Sek. rund um die Uhr sowie das Abfragen mit einer nicht angegebenen Rate ist mit SQL Server möglich, aber es gibt weitere Fragen:
- Welche Verfügbarkeitsanforderung haben Sie dafür? 99,999 % Betriebszeit oder reichen 95 % aus?
- Welche Zuverlässigkeitsanforderung haben Sie? Kostet Sie das Fehlen einer Beilage 1 Million Dollar?
- Welche Wiederherstellungsanforderung haben Sie? Spielt es eine Rolle, wenn Sie einen Tag an Daten verlieren?
- Welche Konsistenzanforderung haben Sie? Muss ein Schreibvorgang garantiert beim nächsten Lesevorgang sichtbar sein?
Wenn Sie alle diese von mir hervorgehobenen Anforderungen benötigen, wird die von Ihnen vorgeschlagene Last Millionen an Hardware und Lizenzierung auf einem relationalen System, jedem System, kosten, egal welche Gimmicks Sie ausprobieren (Sharding, Partitionierung usw.). Ein nosql-System würde per Definition nicht alle erfüllen diese Anforderungen.
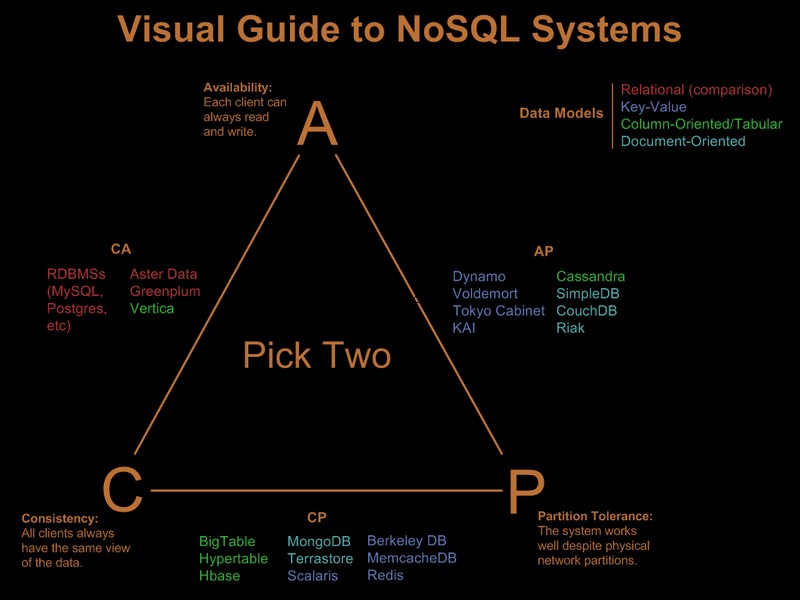
Offensichtlich haben Sie einige dieser Anforderungen also bereits gelockert. Es gibt einen netten visuellen Leitfaden, der die nosql-Angebote basierend auf dem Paradigma „Wähle 2 aus 3“ unter Visual Guide to NoSQL Systems vergleicht:
Nach OP-Kommentaraktualisierung
Mit SQL Server wäre dies eine einfache Implementierung:
- ein einziger gruppierter Tabellenschlüssel (GUID, Zeit). Ja, wird fragmentiert, aber wirkt sich die Fragmentierung auf Read-Aheads aus, und Read-Aheads werden nur für Scans mit signifikantem Bereich benötigt. Da Sie nur nach einer bestimmten GUID und einem Datumsbereich abfragen, spielt die Fragmentierung keine große Rolle. Ja, ist ein breiter Schlüssel, daher haben Nicht-Blattseiten eine schlechte Schlüsseldichte. Ja, das führt zu einem schlechten Füllfaktor. Und ja, Seitenteilungen können auftreten. Trotz dieser Probleme ist es angesichts der Anforderungen immer noch die beste Wahl für geclusterte Schlüssel.
- Partitionieren Sie die Tabelle nach Zeit, damit Sie die abgelaufenen Datensätze über ein automatisch gleitendes Fenster effizient löschen können. Erweitern Sie dies mit einem Online-Neuaufbau der Indexpartition des letzten Monats, um den schlechten Füllfaktor und die Fragmentierung zu beseitigen, die durch das GUID-Clustering eingeführt wurden.
- Seitenkomprimierung aktivieren. Da die Schlüsselgruppen zuerst nach GUID geclustert werden, liegen alle Datensätze einer GUID nebeneinander, was der Seitenkomprimierung eine gute Chance gibt, die Wörterbuchkomprimierung einzusetzen.
- Sie benötigen einen schnellen IO-Pfad für die Protokolldatei. Sie sind an einem hohen Durchsatz interessiert, nicht an einer niedrigen Latenz, damit ein Protokoll mit 1.000 Einfügungen/Sek. Schritt halten kann, daher ist Stripping ein Muss.
Partitionierung und Seitenkomprimierung erfordern jeweils einen Enterprise Edition SQL Server, sie funktionieren nicht auf der Standard Edition und beide sind sehr wichtig, um die Anforderungen zu erfüllen.
Als Nebenbemerkung:Wenn die Datensätze von einer Front-End-Webserver-Farm stammen, würde ich Express auf jedem Webserver platzieren und anstelle von INSERT am Back-End würde ich SEND verwenden die Informationen an das Back-End unter Verwendung einer lokalen Verbindung/Transaktion auf dem Express, der sich gemeinsam mit dem Webserver befindet. Dies gibt der Lösung eine viel viel bessere Verfügbarkeitsstory.
So würde ich es in SQL Server machen. Die gute Nachricht ist, dass die Probleme, mit denen Sie konfrontiert werden, gut verstanden und Lösungen bekannt sind. das bedeutet nicht unbedingt, dass dies besser ist als das, was Sie mit Cassandra, BigTable oder Dynamo erreichen könnten. Ich lasse jemanden, der sich in Dingen ohne SQL besser auskennt, seinen Fall argumentieren.
Beachten Sie, dass ich das Programmiermodell, die .Net-Unterstützung und dergleichen nie erwähnt habe. Ich denke ehrlich gesagt, dass sie in großen Bereitstellungen irrelevant sind. Sie machen einen großen Unterschied im Entwicklungsprozess, aber wenn sie einmal implementiert sind, spielt es keine Rolle, wie schnell die Entwicklung war, wenn der ORM-Overhead die Leistung zerstört :)