Nun, um Ihre Frage zu beantworten, warum SQL Server dies tut, lautet die Antwort, dass die Abfrage nicht in einer logischen Reihenfolge kompiliert wird, jede Anweisung wird für sich kompiliert, also wenn der Abfrageplan für Ihre select-Anweisung generiert wird, der Optimierer weiß nicht, dass @val1 und @Val2 zu 'val1' bzw. 'val2' werden.
Wenn SQL Server den Wert nicht kennt, muss er möglichst gut schätzen, wie oft diese Variable in der Tabelle erscheinen wird, was manchmal zu suboptimalen Plänen führen kann. Mein Hauptpunkt ist, dass dieselbe Abfrage mit unterschiedlichen Werten unterschiedliche Pläne generieren kann. Stellen Sie sich dieses einfache Beispiel vor:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 991 1
FROM sys.all_objects a
UNION ALL
SELECT TOP 9 ROW_NUMBER() OVER(ORDER BY a.object_id) + 1
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Alles, was ich hier getan habe, ist, eine einfache Tabelle zu erstellen und 1000 Zeilen mit den Werten 1-10 für die Spalte val hinzuzufügen , jedoch kommt 1 991 Mal vor und die anderen 9 nur einmal. Die Prämisse ist diese Abfrage:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 1;
Es wäre effizienter, einfach die gesamte Tabelle zu scannen, als den Index für eine Suche zu verwenden und dann 991 Lesezeichensuchen durchzuführen, um den Wert für Filler zu erhalten , jedoch mit nur 1 Zeile folgende Abfrage:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 2;
Es ist effizienter, eine Indexsuche und eine einzelne Lesezeichensuche durchzuführen, um den Wert für Filler zu erhalten (und das Ausführen dieser beiden Abfragen bestätigt dies)
Ich bin mir ziemlich sicher, dass die Grenze für eine Suche und eine Lesezeichensuche tatsächlich je nach Situation variiert, aber sie ist ziemlich niedrig. Anhand der Beispieltabelle habe ich mit ein wenig Trial-and-Error herausgefunden, dass ich den Val benötige Spalte 38 Zeilen mit dem Wert 2 haben, bevor der Optimierer einen vollständigen Tabellenscan über eine Indexsuche und eine Lesezeichensuche durchführte:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
DECLARE @I INT = 38;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP (991 - @i) 1
FROM sys.all_objects a
UNION ALL
SELECT TOP (@i) 2
FROM sys.all_objects a
UNION ALL
SELECT TOP 8 ROW_NUMBER() OVER(ORDER BY a.object_id) + 2
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
SELECT COUNT(Filler), COUNT(*)
FROM #T
WHERE Val = 2;
Für dieses Beispiel liegt die Grenze also bei 3,7 % der übereinstimmenden Zeilen.
Da die Abfrage nicht weiß, wie viele Zeilen übereinstimmen, wenn Sie eine Variable verwenden, muss sie raten, und der einfachste Weg besteht darin, die Gesamtzahl der Zeilen zu ermitteln und diese durch die Gesamtzahl der unterschiedlichen Werte in der Spalte zu dividieren. also in diesem Beispiel die geschätzte Anzahl von Zeilen für WHERE val = @Val ist 1000 / 10 =100. Der eigentliche Algorithmus ist komplexer als dieser, aber zum Beispiel reicht dies aus. Wenn wir uns also den Ausführungsplan ansehen für:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
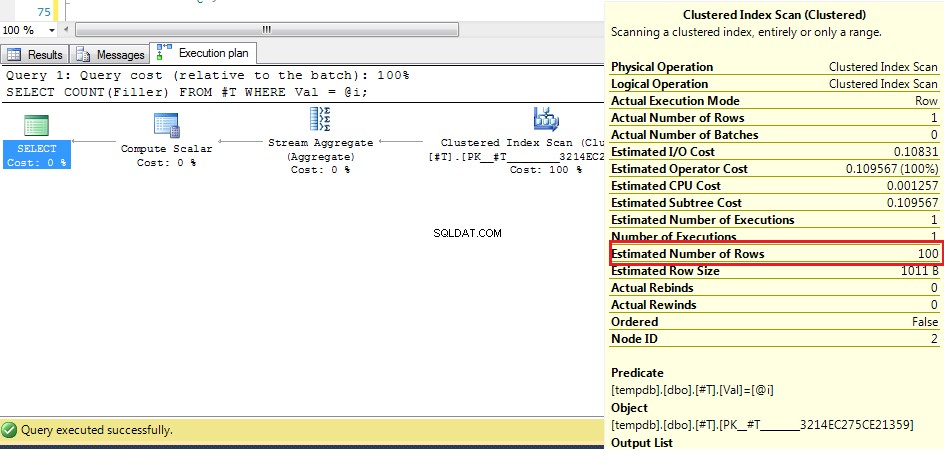
Wir können hier (mit den Originaldaten) sehen, dass die geschätzte Anzahl der Zeilen 100 beträgt, die tatsächliche Zeilen jedoch 1. Aus den vorherigen Schritten wissen wir, dass sich der Optimierer bei mehr als 38 Zeilen für einen Clustered-Index-Scan anstelle eines Index entscheiden wird suchen, da die beste Schätzung für die Anzahl der Zeilen höher ist, ist der Plan für eine unbekannte Variable ein Clustered-Index-Scan.
Nur um die Theorie weiter zu beweisen, wenn wir die Tabelle mit 1000 Zeilen mit den Zahlen 1-27 erstellen, die gleichmäßig verteilt sind (also wird die geschätzte Zeilenzahl ungefähr 1000 / 27 =37.037 betragen)
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 27 ROW_NUMBER() OVER(ORDER BY a.object_id)
FROM sys.all_objects a;
INSERT #T (val)
SELECT TOP 973 t1.Val
FROM #T AS t1
CROSS JOIN #T AS t2
CROSS JOIN #T AS t3
ORDER BY t2.Val, t3.Val;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Führen Sie dann die Abfrage erneut aus, wir erhalten einen Plan mit einer Indexsuche:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
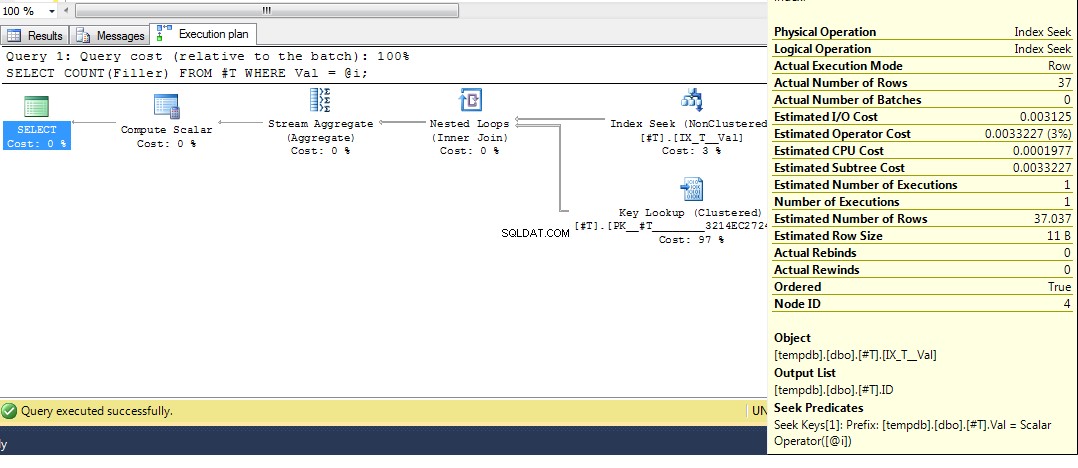
Hoffentlich deckt das ziemlich umfassend ab, warum Sie diesen Plan erhalten. Nun, ich nehme an, die nächste Frage ist, wie Sie einen anderen Plan erzwingen, und die Antwort lautet, den Abfragehinweis OPTION (RECOMPILE) zu verwenden , um zu erzwingen, dass die Abfrage zur Ausführungszeit kompiliert wird, wenn der Wert des Parameters bekannt ist. Zurück zu den ursprünglichen Daten, wo der beste Plan für Val = 2 ist eine Suche ist, aber die Verwendung einer Variablen einen Plan mit einem Index-Scan ergibt, können wir Folgendes ausführen:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
GO
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i
OPTION (RECOMPILE);
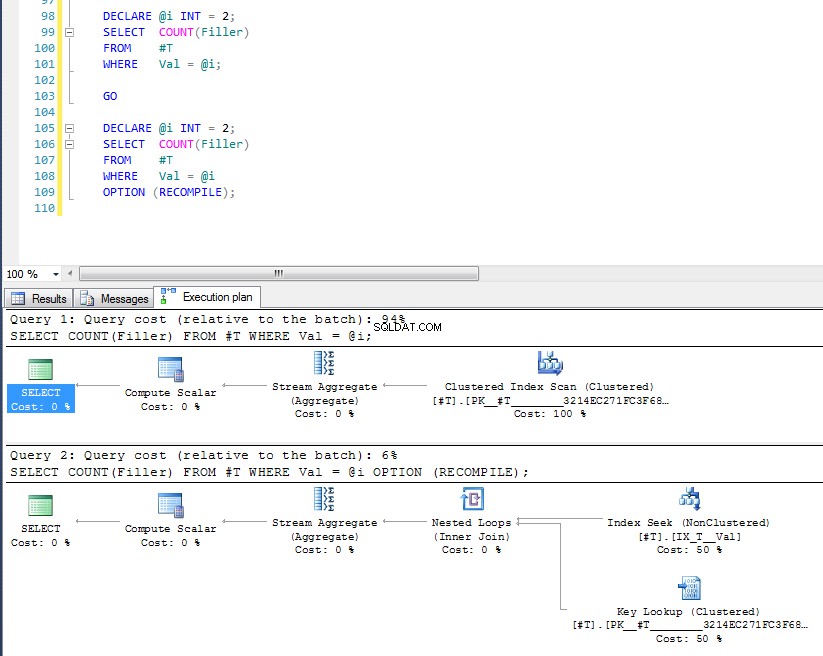
Wir können sehen, dass letzteres die Indexsuche und Schlüsselsuche verwendet, da es den Wert der Variablen zur Ausführungszeit überprüft hat und der am besten geeignete Plan für diesen spezifischen Wert ausgewählt wird. Das Problem mit OPTION (RECOMPILE) Dies bedeutet, dass Sie keine zwischengespeicherten Abfragepläne nutzen können, sodass jedes Mal zusätzliche Kosten für die Kompilierung der Abfrage anfallen.



