Wir untersuchen die Migration einer Oracle-Datenbank von einer EC2-Instance zu einem Managed Service RDS. Im ersten von vier Artikeln, „Migration einer Oracle-Datenbank von AWS EC2 zu AWS RDS, Teil 1“, haben wir Datenbankinstanzen auf EC2 und RDS erstellt. Im zweiten Artikel „Migration einer Oracle-Datenbank von AWS EC2 zu AWS RDS, Teil 2“ haben wir einen IAM-Benutzer für die Datenbankmigration und auch eine zu migrierende Datenbanktabelle erstellt. Nur im zweiten Artikel haben wir eine Replikationsinstanz und Replikationsendpunkte erstellt. Im dritten Artikel „Migration einer Oracle-Datenbank von AWS EC2 zu AWS RDS, Teil 3“ haben wir eine Migrationsaufgabe erstellt, um vorhandene Änderungen zu migrieren. In diesem Folgeartikel migrieren wir laufende Datenänderungen. Dieser Artikel hat die folgenden Abschnitte:
- Erstellen und Ausführen einer Replikationsaufgabe zum Migrieren laufender Änderungen
- Zusätzliche Protokollierung hinzufügen
- Hinzufügen einer Tabelle zu einer Oracle-Datenbankinstanz auf EC2
- Hinzufügen von Tabellendaten
- Erkunden der replizierten Datenbanktabelle
- Daten löschen und neu laden
- Stoppen und Starten einer Aufgabe
- Datenbanken löschen
- Schlussfolgerung
Erstellen und Ausführen einer Replikationsaufgabe zum Migrieren laufender Änderungen
In den folgenden Unterabschnitten werden wir eine Aufgabe erstellen, um laufende Änderungen zu replizieren. Um die fortlaufende Replikation zu demonstrieren, starten wir zuerst die Aufgabe und erstellen anschließend eine Tabelle und fügen Daten hinzu. Löschen Sie die Tabelle DVOHRA.WLSLOG , wie in Abbildung 1 gezeigt; Wir werden dieselbe Tabelle erstellen, um die fortlaufende Replikation zu demonstrieren.

Abbildung 1: Löschen der Tabelle DVOHRA.WLSLOG
Zusätzliche Protokollierung hinzufügen
Datenbankmigrationsdienst erfordert, dass die zusätzliche Protokollierung aktiviert ist, um die Änderungsdatenerfassung (CDC) zu aktivieren, die zum Replizieren laufender Änderungen verwendet wird. Bei der ergänzenden Protokollierung werden Informationen darüber gespeichert, welche Datenzeilen in einer Tabelle geändert wurden. Die zusätzliche Protokollierung fügt zusätzliche oder zusätzliche Spaltendaten in Redo-Protokolldateien hinzu, wenn eine Aktualisierung für eine Tabelle durchgeführt wird. Die geänderten Spalten werden als zusätzliche Daten in Redo-Log-Dateien zusammen mit einem Identifizierungsschlüssel aufgezeichnet, der der Primärschlüssel oder ein eindeutiger Index sein kann. Wenn eine Tabelle keinen Primärschlüssel oder eindeutigen Index hat, werden alle Skalarspalten in den Redo-Log-Dateien aufgezeichnet, um eine Datenzeile eindeutig zu identifizieren, wodurch die Redo-Log-Dateien sehr groß werden könnten. Oracle Database unterstützt die folgenden Arten von zusätzlicher Protokollierung:
- Minimale zusätzliche Protokollierung: In Redo-Log-Dateien wird nur die minimale Datenmenge aufgezeichnet, die LogMiner für die DML-Änderungen benötigt.
- Schlüsselprotokollierung zur Identifizierung auf Datenbankebene: Es werden verschiedene Arten der Protokollierung von Identifikationsschlüsseln auf Datenbankebene unterstützt – ALL, PRIMARY KEY, UNIQUE und FOREIGN KEY. Beim ALL-Level werden alle Spalten (außer LOBs, Longs und ADTs) in Redo-Log-Dateien aufgezeichnet. Für PRIMARY KEY werden nur Primärschlüsselspalten in Redo-Log-Dateien gespeichert, wenn eine Zeile, die einen Primärschlüssel enthält, aktualisiert wird; Es ist nicht erforderlich, dass eine Primärschlüsselspalte aktualisiert wird. Die Art FOREIGN KEY speichert nur die Fremdschlüssel einer Zeile in Redo-Log-Dateien, wenn eine der Red-Log-Dateien aktualisiert wird. Die Art UNIQUE speichert nur die Spalten in einem eindeutigen zusammengesetzten Schlüssel oder Bitmap-Index, wenn sich eine Spalte im eindeutigen zusammengesetzten Schlüssel oder Bitmap-Index geändert hat.
- Zusätzliche Protokollierung auf Tabellenebene: Gibt auf Tabellenebene an, welche Spalten in Redo-Log-Dateien gespeichert werden. Die Protokollierung von Identifikationsschlüsseln auf Tabellenebene unterstützt die gleichen Ebenen wie die Protokollierung von Identifikationsschlüsseln auf Datenbankebene; ALL, PRIMARY KEY, UNIQUE und FOREIGN KEY. Auf Tabellenebene werden auch benutzerdefinierte Zusatzprotokollgruppen unterstützt, mit denen ein Benutzer definieren kann, welche Spalten zusätzlich protokolliert werden sollen. Die benutzerdefinierten zusätzlichen Protokollgruppen können bedingt oder unbedingt sein.
Für die fortlaufende Replikation müssen wir die minimale zusätzliche Protokollierung und die zusätzliche Protokollierung auf Tabellenebene für ALLE Spalten festlegen.
Führen Sie in SQL*Plus die folgende Anweisung aus, um die minimale zusätzliche Protokollierung festzulegen:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
Die Ausgabe sieht wie folgt aus:
SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA; Database altered.
Führen Sie die folgende Anweisung aus, um den Status der minimalen zusätzlichen Protokollierung zu ermitteln. Und wenn die Ausgabe einen SUPPLEME-Spaltenwert von YES hat, ist die minimale zusätzliche Protokollierung aktiviert.
SQL> SELECT supplemental_log_data_min FROM v$database; SUPPLEME -------- YES
Das Einstellen der minimalen zusätzlichen Protokollierung und die Überprüfung der Statusausgabe ist in Abbildung 2 dargestellt.
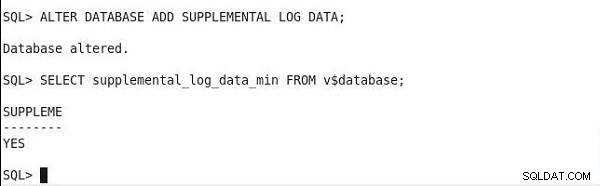
Abbildung 2: Einstellen und Überprüfen der minimalen zusätzlichen Protokollierung
Wir werden auch die Protokollierung von Identifikationsschlüsseln auf Tabellenebene festlegen, wenn wir Tabellen- und Tabellendaten hinzufügen, um die fortlaufende Replikation zu demonstrieren, nachdem die Aufgabe gestartet wurde. Wenn wir Tabellen und Tabellendaten hinzufügen, bevor wir eine Aufgabe erstellen und starten, können wir keine fortlaufende Replikation nachweisen.
Um eine Aufgabe für die fortlaufende Replikation zu erstellen, klicken Sie auf Aufgabe erstellen , wie in Abbildung 3 gezeigt.

Abbildung 3: Aufgaben>Aufgabe erstellen
In der Aufgabe erstellen Assistenten, geben Sie einen Aufgabennamen und eine Beschreibung ein und wählen Sie die Replikationsinstanz, den Quellendpunkt und den Zielendpunkt aus, wie in Abbildung 4 gezeigt. Wählen Sie Migrationstyp aus als Vorhandene Daten migrieren und laufende Änderungen replizieren .
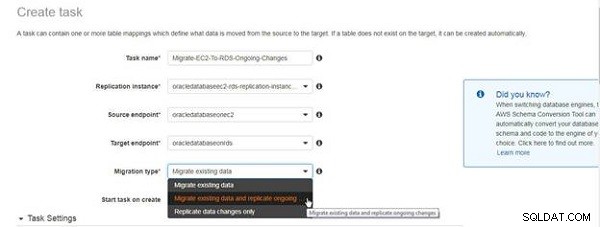
Abbildung 4: Auswählen des Migrationstyps für die laufende Replikation
Eine in Abbildung 5 gezeigte Meldung weist darauf hin, dass die zusätzliche Protokollierung für die laufende Replikation aktiviert werden muss. Die Meldung soll nicht darauf hinweisen, dass die zusätzliche Protokollierung nicht aktiviert wurde, sondern nur als Erinnerung. Wir haben die zusätzliche Protokollierung bereits aktiviert. Aktivieren Sie das Kontrollkästchen Aufgabe beim Erstellen starten .
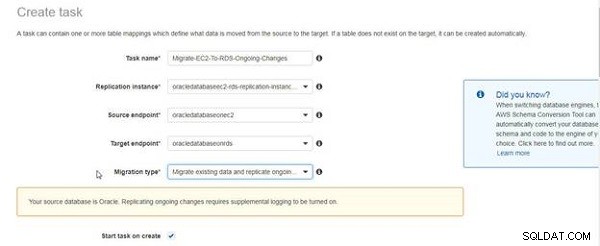
Abbildung 5: Nachricht über zusätzliche Protokollierungsanforderungen zum Replizieren laufender Änderungen
Die Aufgabeneinstellungen sind die gleichen wie bei der reinen Migration bestehender Daten (siehe Abbildung 6).
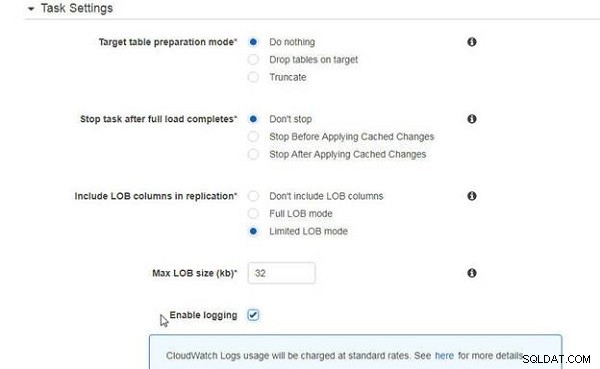
Abbildung 6: Aufgabeneinstellungen
Für Tabellenzuordnungen ist mindestens eine Auswahlregel erforderlich. Fügen Sie eine Auswahlregel hinzu, um alle Tabellen in die DVOHRA aufzunehmen Tabelle, wie in Abbildung 7 gezeigt.
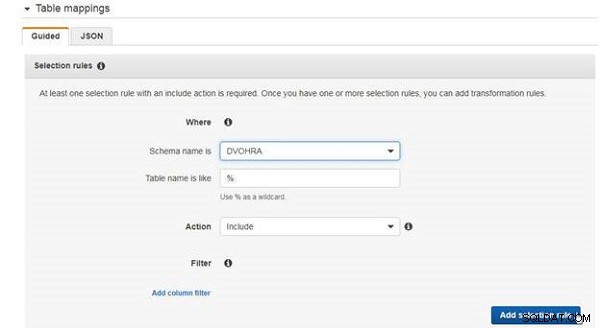
Abbildung 7: Hinzufügen einer Auswahlregel
Die hinzugefügte Auswahlregel ist in Abbildung 8 dargestellt.
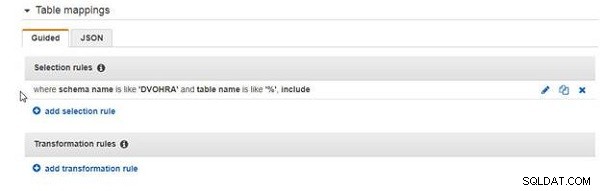
Abbildung 8: Auswahlregel
Klicken Sie auf Aufgabe erstellen um die Aufgabe zu erstellen, wie in Abbildung 9 gezeigt.
Abbildung 9: Aufgabe erstellen
Eine neue Aufgabe mit dem Status Wird erstellt wird hinzugefügt , wie in Abbildung 10 gezeigt.

Abbildung 10: Aufgabe hinzugefügt mit Status Wird erstellt
Wenn die Auswahl- und Transformationsregeln für alle vorhandenen Daten angewendet und Daten migriert wurden, lautet der Aufgabenstatus Laden abgeschlossen, Replikation läuft (siehe Abbildung 11).

Abbildung 11: Laden abgeschlossen, Replikation läuft
Die Tabellenstatistik tab listet keine Tabellen als migriert oder repliziert auf, wie in Abbildung 12 gezeigt.
Abbildung 12: Tabellenstatistik
Um die CloudWatch-Protokolle zu durchsuchen, klicken Sie auf Protokolle Registerkarte und klicken Sie auf den Link, wie in Abbildung 13 gezeigt.
Abbildung 13: Protokolle
Die CloudWatch-Protokolle werden angezeigt, wie in Abbildung 14 gezeigt. Der letzte Eintrag in den Protokollen betrifft das Starten der Replikation. Die laufende Replikationstask wird nach dem Laden vorhandener Daten, falls vorhanden, nicht beendet, sondern läuft weiter.
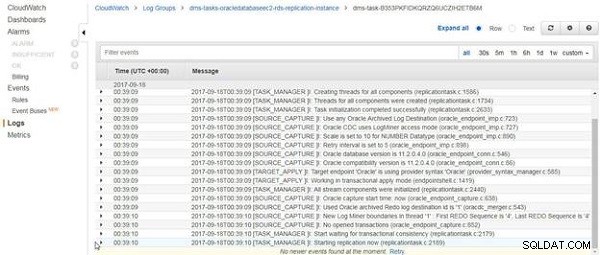
Abbildung 14: CloudWatch-Protokolle
Hinzufügen einer Tabelle zu einer Oracle-Datenbankinstanz auf EC2
Erstellen Sie als Nächstes eine Tabelle und fügen Sie Tabellendaten hinzu, um die fortlaufende Replikation zu demonstrieren. Führen Sie die folgenden beiden Anweisungen zusammen aus, damit die zusätzliche Protokollierung auf Tabellenebene festgelegt wird, wenn die Tabelle erstellt wird. Ändern Sie das Skript, um das Schema anders zu gestalten.
CREATE TABLE DVOHRA.wlslog(time_stamp VARCHAR2(255) PRIMARY KEY, category VARCHAR2(255),type VARCHAR2(255),servername VARCHAR2(255),code VARCHAR2(255),msg VARCHAR2(255)); alter table DVOHRA.WLSLOG add supplemental log data (ALL) columns;
Die zusätzliche Protokollierung auf Tabellenebene wird festgelegt, wenn die Tabelle erstellt wird.
SQL> CREATE TABLE DVOHRA.wlslog(time_stamp VARCHAR2(255) PRIMARY KEY,category VARCHAR2(255),type VARCHAR2(255),servername VARCHAR2(255),code VARCHAR2(255),msg VARCHAR2(255)); alter table DVOHRA.WLSLOG add supplemental log data (ALL) columns; Table created. SQL> Table altered.
Die Ausgabe wird in SQL*Plus in Abbildung 15 gezeigt.
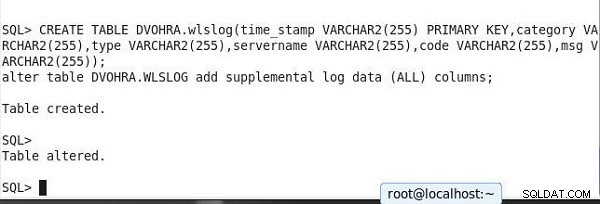
Abbildung 15: Tabelle erstellen und Zusatzprotokollierung einstellen
Bisher haben wir nur die Tabelle erstellt und keine Tabellendaten hinzugefügt. Die DDL für die Tabelle wird migriert, wie in den Tabellenstatistiken in Abbildung 16 angegeben.
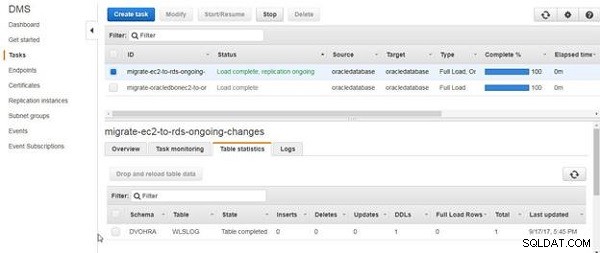
Abbildung 16: DDLs für migrierte Tabellen
Hinzufügen von Tabellendaten
Führen Sie als Nächstes das folgende SQL-Skript aus, um der erstellten Tabelle Daten hinzuzufügen. Ändern Sie das Skript, um das Schema anders zu gestalten.
SQL> INSERT INTO DVOHRA.wlslog(time_stamp,category,type,
servername,code,msg) VALUES('Apr-8-2014-7:06:16-PM-PDT',
'Notice','WebLogicServer','AdminServer','BEA-000365','Server
state changed to STANDBY');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,
code,msg) VALUES('Apr-8-2014-7:06:17-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to STARTING');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,
code,msg) VALUES('Apr-8-2014-7:06:18-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to ADMIN');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:19-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to RESUMING');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:20-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000361','Started WebLogic
AdminServer');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:21-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to RUNNING');
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
Führen Sie anschließend die Commit-Anweisung aus.
SQL> COMMIT; Commit complete.
Erkunden der replizierten Datenbanktabelle
Die Tabellenstatistik listet Einfügungen als Anzahl der hinzugefügten Datenzeilen auf, wie in Abbildung 17 gezeigt.
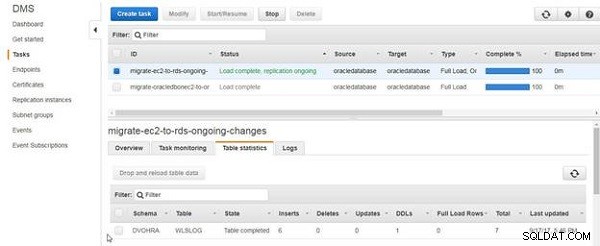
Abbildung 17: Tabellenstatistikliste 6 Einsätze
Die Aufgabe wird nach dem Replizieren laufender Änderungen weiter ausgeführt. Fügen Sie eine weitere Datenzeile hinzu.
SQL> INSERT INTO DVOHRA.wlslog(time_stamp,category,type,
servername,code,msg) VALUES('Apr-8-2014-7:06:22-PM-PDT',
'Notice','WebLogicServer','AdminServer','BEA-000360','Server
started in RUNNING mode');
1 row created.
SQL> COMMIT;
Commit complete.
SQL>
Klicken Sie auf Daten aktualisieren vom Server, wie in Abbildung 18 gezeigt.
Abbildung 18: Daten vom Server aktualisieren
Die Gesamtzahl der Inserts in Table-Statistiken beträgt 7, wie in Abbildung 19 gezeigt.
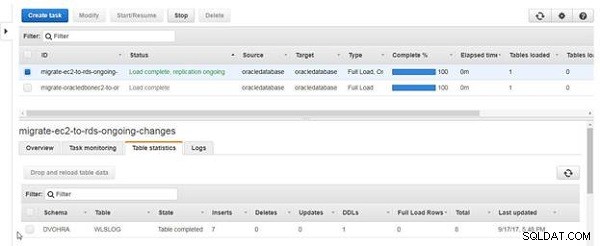
Abbildung 19: Tabellenstatistik mit Einfügungen als 7
Daten löschen und neu laden
Um Tabellendaten zu löschen und neu zu laden, klicken Sie auf Tabellendaten löschen und neu laden , wie in Abbildung 20 gezeigt.
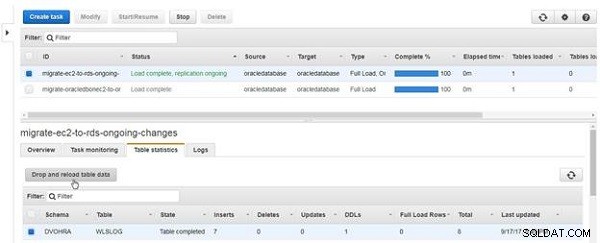
Abbildung 20: Tabellendaten löschen und neu laden
Klicken Sie auf Daten vom Server aktualisieren (siehe Abbildung 21).
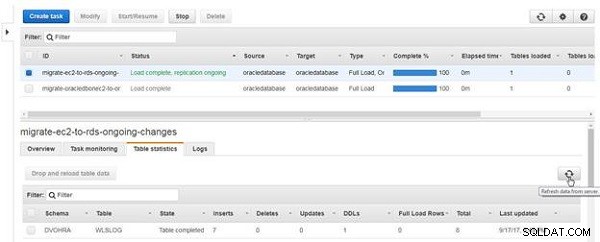
Abbildung 21: Daten vom Server aktualisieren
Das Symbol und Status Spalte für die Tabelle gibt an, dass die Tabelle neu geladen wird, wie in Abbildung 22 gezeigt.
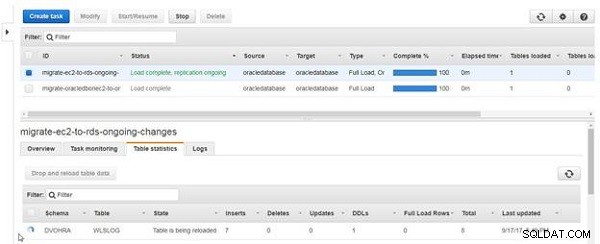
Abbildung 22: Tabelle wird neu geladen
Wenn das Neuladen der Tabelle abgeschlossen ist, wird die Statusspalte der Tabelle zu Tabelle abgeschlossen , wie in Abbildung 23 gezeigt. Nach dem erneuten Laden der Tabellendaten werden die Full Load Rows zeigt einen Wert von 7 und Inserts ist 0, da ein Reload keine fortlaufende Replikation ist, sondern ein vollständiger Ladevorgang.
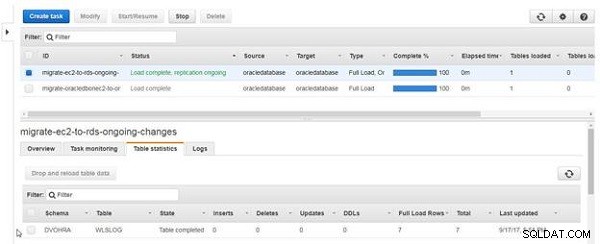
Abbildung 23: Neuladen der Tabelle abgeschlossen
Da die Tabellendaten gelöscht und neu geladen werden und sich die Quelltabellendaten nicht geändert haben, enthalten die CloudWatch-Protokolle eine Meldung „Einige Änderungen aus der Quelldatenbank hatten keine Auswirkungen, als sie auf die Zieldatenbank angewendet wurden“, wie in Abbildung 24 gezeigt. P>
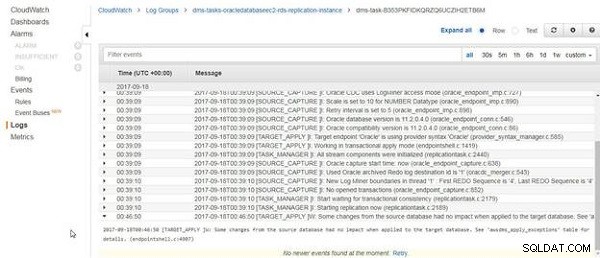
Abbildung 24: Einige Änderungen aus der Quelldatenbank hatten keine Auswirkungen, als sie auf die Zieldatenbank angewendet wurden
Beim Neuladen der DVOHRA.wlslog Tabelle abgeschlossen ist, wird die Meldung „Laden für Tabelle DVOHRA.wlslog abgeschlossen. 7 Zeilen empfangen“ wird angezeigt, wie in Abbildung 25 gezeigt.
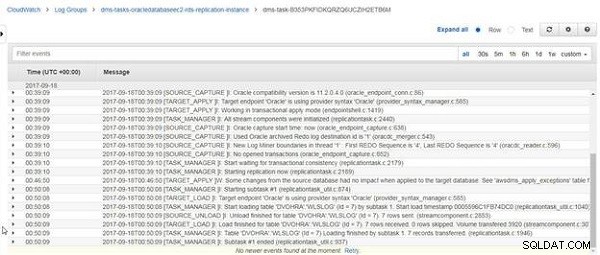
Abbildung 25: CloudWatch-Protokollnachricht für den Abschluss des Ladevorgangs
Stoppen und Starten einer Aufgabe
Eine Aufgabe des Typs, der eine laufende Replikation umfasst, wird nicht von selbst angehalten, es sei denn, es tritt ein Fehler auf. Um die Aufgabe zu stoppen, klicken Sie auf Stop (siehe Abbildung 26).
Abbildung 26: Anhalten einer Aufgabe
In der Aufgabe stoppen Klicken Sie im Dialogfeld auf Stopp , wie in Abbildung 27 gezeigt.
Abbildung 27: Bestätigungsdialog zum Beenden einer Aufgabe
Der Aufgabenstatus wird zu Wird gestoppt , wie in Abbildung 28 gezeigt.
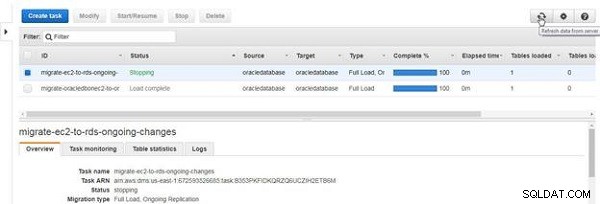
Abbildung 28: Stoppen einer Aufgabe
Wenn eine Aufgabe angehalten wird, ändert sich der Status zu Gestoppt , wie in Abbildung 29 gezeigt.
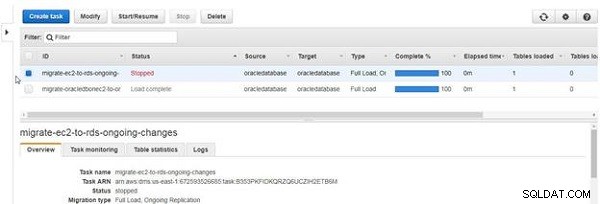
Abbildung 29: Aufgabe gestoppt
Um eine angehaltene Aufgabe zu starten, klicken Sie auf Starten/Fortsetzen , wie in Abbildung 30 gezeigt.
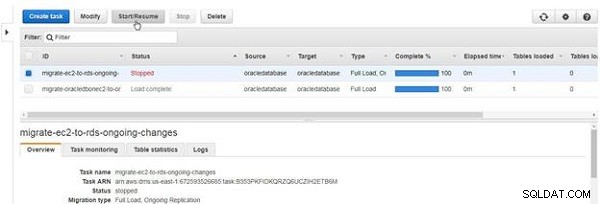
Abbildung 30: Eine Aufgabe starten oder fortsetzen
In der Aufgabe starten klicken Sie auf Start um die Aufgabe vom gestoppten Punkt aus zu starten (siehe Abbildung 31). Die andere Möglichkeit besteht darin, die Aufgabe neu zu starten.
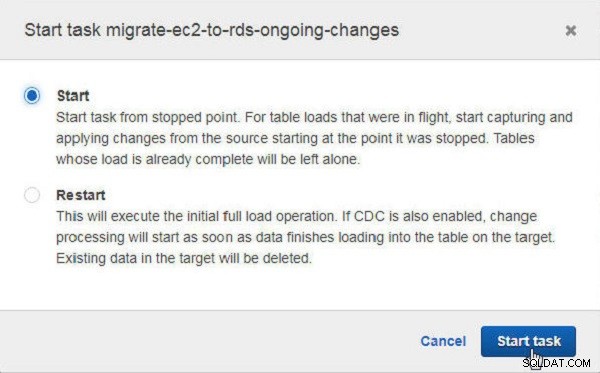
Abbildung 31: Starten der Aufgabe nach dem Stoppen
Der Aufgabenstatus wird zu Wird gestartet , wie in Abbildung 32 gezeigt.

Abbildung 32: Aufgabe starten
Wenn die Migration vorhandener Daten abgeschlossen ist, wird die Aufgabe mit dem Status Laden abgeschlossen, Replikation läuft weiter ausgeführt , wie in Abbildung 33 gezeigt.

Abbildung 33: Laden abgeschlossen, Replikation läuft
Datenbanken löschen
Die RDS-DB-Instance kann mit Instance Actions>Delete gelöscht werden Befehl. Die Oracle-Datenbank auf der EC2-Instance kann mit Actions>Instance State>Stop gestoppt werden , wie in Abbildung 34 gezeigt.

Abbildung 34: Anhalten der EC2-Instanz
Schlussfolgerung
In vier Artikeln haben wir die Migration einer Oracle-Datenbank von AWS EC2 zu AWS RDS besprochen.