Kurze Zusammenfassung
- Die Leistung der Unterabfragemethode hängt von der Datenverteilung ab.
- Die Leistung der bedingten Aggregation hängt nicht von der Datenverteilung ab.
Die Methode der Unterabfragen kann schneller oder langsamer sein als die bedingte Aggregation, dies hängt von der Datenverteilung ab.
Wenn die Tabelle über einen geeigneten Index verfügt, profitieren Unterabfragen natürlich davon, da der Index es ermöglichen würde, nur den relevanten Teil der Tabelle anstelle des vollständigen Scans zu durchsuchen. Es ist unwahrscheinlich, dass ein geeigneter Index für die bedingte Aggregationsmethode von großem Nutzen ist, da sie sowieso den vollständigen Index scannt. Der einzige Vorteil wäre, wenn der Index schmaler als die Tabelle wäre und die Engine weniger Seiten in den Speicher lesen müsste.
Wenn Sie dies wissen, können Sie entscheiden, welche Methode Sie wählen.
Erster Test
Ich habe eine größere Testtabelle mit 5 Millionen Zeilen erstellt. Es gab keine Indizes in der Tabelle. Ich habe die IO- und CPU-Statistiken mit SQL Sentry Plan Explorer gemessen. Ich habe SQL Server 2014 SP1-CU7 (12.0.4459.0) Express 64-Bit für diese Tests verwendet.
Tatsächlich verhielten sich Ihre ursprünglichen Abfragen wie von Ihnen beschrieben, d. h. Unterabfragen waren schneller, obwohl die Lesevorgänge dreimal so hoch waren.
Nach einigen Versuchen an einer Tabelle ohne Index habe ich Ihr bedingtes Aggregat umgeschrieben und Variablen hinzugefügt, um den Wert von DATEADD zu halten Ausdrücke.
Die Gesamtzeit wurde deutlich schneller.
Dann habe ich SUM ersetzt mit COUNT und es wurde wieder etwas schneller.
Immerhin wurde die bedingte Aggregation so schnell wie Unterabfragen.
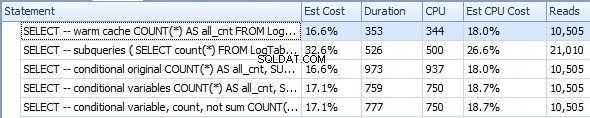
Cache aufwärmen (CPU=375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Unterabfragen (CPU=1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);
Ursprüngliche bedingte Aggregation (CPU=1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Bedingte Aggregation mit Variablen (CPU=1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Bedingte Aggregation mit Variablen und COUNT statt SUM (CPU=1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

Basierend auf diesen Ergebnissen vermute ich, dass CASE DATEADD aufgerufen für jede Zeile, während WHERE war klug genug, es einmal zu berechnen. Plus COUNT ist ein kleines bisschen effizienter als SUM .
Am Ende ist die bedingte Aggregation nur geringfügig langsamer als Unterabfragen (1062 vs. 1031), vielleicht weil WHERE ist etwas effizienter als CASE an sich und außerdem WHERE filtert ziemlich viele Zeilen heraus, also COUNT muss weniger Zeilen verarbeiten.
In der Praxis würde ich die bedingte Aggregation verwenden, weil ich denke, dass die Anzahl der Lesevorgänge wichtiger ist. Wenn Ihre Tabelle klein ist, um in den Pufferpool zu passen und dort zu bleiben, wird jede Abfrage für den Endbenutzer schnell sein. Aber wenn die Tabelle größer als der verfügbare Speicher ist, dann erwarte ich, dass das Lesen von der Festplatte Unterabfragen erheblich verlangsamen würde.
Zweiter Test
Andererseits ist es auch wichtig, die Zeilen so früh wie möglich herauszufiltern.
Hier ist eine leichte Variation des Tests, die es demonstriert. Hier setze ich den Schwellenwert auf GETDATE() + 100 Jahre, um sicherzustellen, dass keine Zeilen die Filterkriterien erfüllen.
Cache aufwärmen (CPU=344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Unterabfragen (CPU=500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);
Ursprüngliche bedingte Aggregation (CPU=937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Bedingte Aggregation mit Variablen (CPU=750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Bedingte Aggregation mit Variablen und COUNT statt SUM (CPU=750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Unten ist ein Plan mit Unterabfragen. Sie können sehen, dass 0 Zeilen in der zweiten Unterabfrage in das Stream-Aggregat gingen, alle wurden beim Tabellen-Scan-Schritt herausgefiltert.
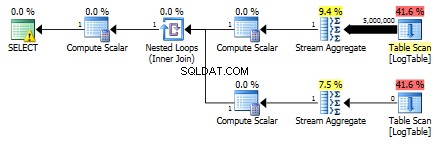
Dadurch sind Unterabfragen wieder schneller.
Dritter Test
Hier habe ich die Filterkriterien des vorherigen Tests geändert:alle > wurden durch < ersetzt . Als Ergebnis wird die Bedingung COUNT alle Zeilen statt keiner gezählt. Überraschung Überraschung! Die bedingte Aggregationsabfrage dauerte dieselben 750 ms, während Unterabfragen 813 statt 500 wurden.

Hier ist der Plan für Unterabfragen:
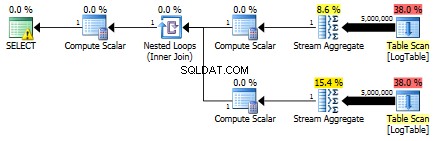
Können Sie mir ein Beispiel geben, wo die bedingte Aggregation die Unterabfragelösung deutlich übertrifft?
Hier ist es. Die Leistung der Unterabfragemethode hängt von der Datenverteilung ab. Die Leistung der bedingten Aggregation hängt nicht von der Datenverteilung ab.
Die Methode der Unterabfragen kann schneller oder langsamer sein als die bedingte Aggregation, dies hängt von der Datenverteilung ab.
Wenn Sie dies wissen, können Sie entscheiden, welche Methode Sie wählen.
Bonusdetails
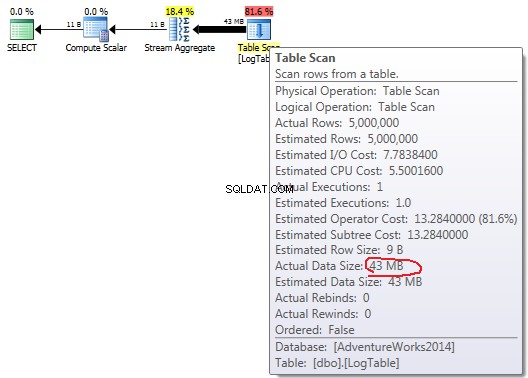
Wenn Sie mit der Maus über den Table Scan fahren Operator können Sie die Actual Data Size sehen in verschiedenen Varianten.
- Einfaches
COUNT(*):
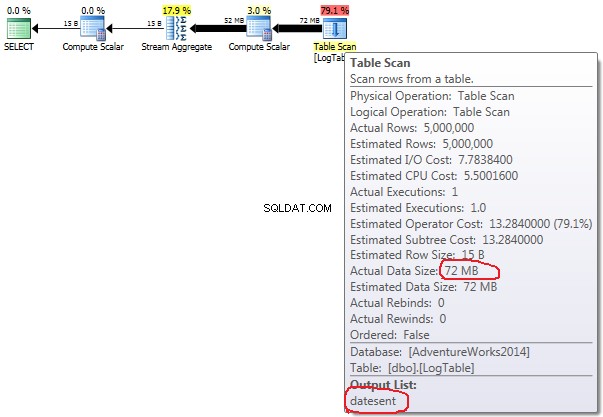
- Bedingte Aggregation:
- Unterabfrage in Test 2:
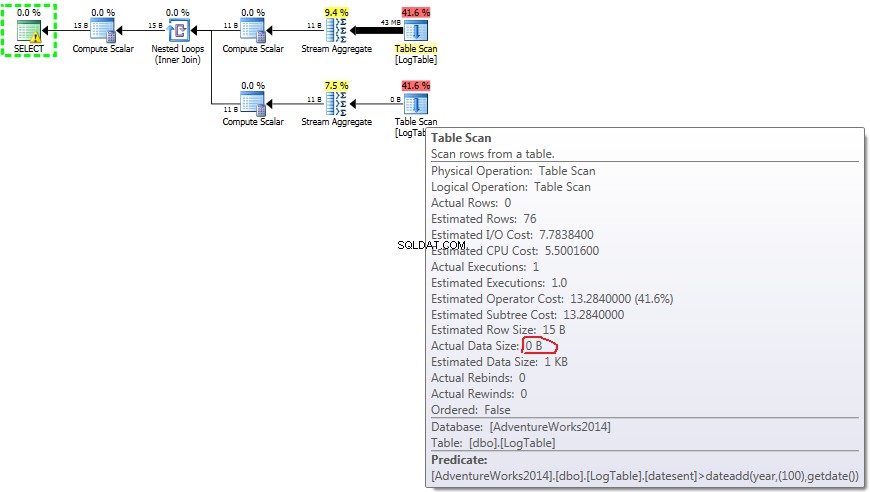
- Unterabfrage in Test 3:
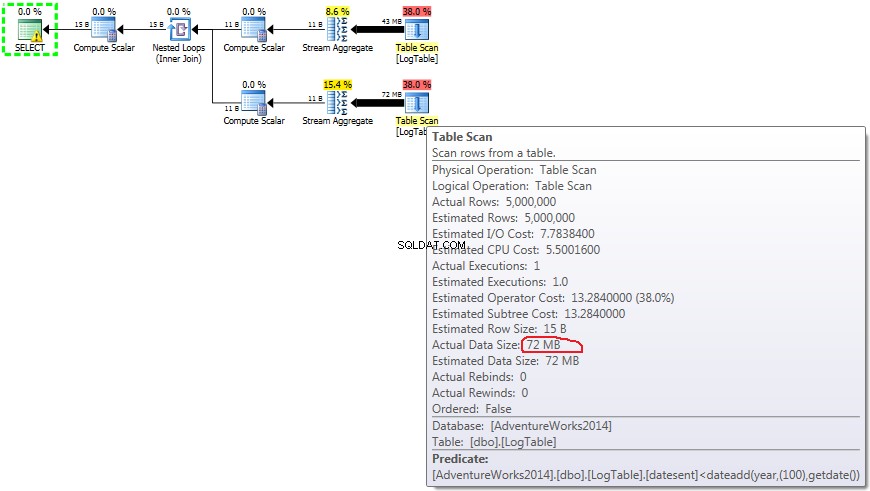
Nun wird deutlich, dass der Leistungsunterschied wahrscheinlich durch die unterschiedliche Datenmenge verursacht wird, die durch den Plan fließt.
Bei einfachem COUNT(*) es gibt keine Output list (es werden keine Spaltenwerte benötigt) und die Datengröße ist am kleinsten (43 MB).
Bei bedingter Aggregation ändert sich diese Menge zwischen den Tests 2 und 3 nicht, sie beträgt immer 72 MB. Output list hat eine Spalte datesent .
Bei Unterabfragen ist dieser Betrag ausreichend je nach Datenverteilung ändern.