Hier sind vier Methoden, die Sie verwenden können, um doppelte Zeilen in SQL Server zu finden.
Mit „doppelte Zeilen“ meine ich zwei oder mehr Zeilen, die in allen Spalten genau dieselben Werte aufweisen.
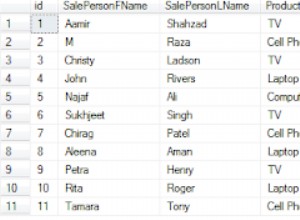
Beispieldaten
Angenommen, wir haben eine Tabelle mit den folgenden Daten:
SELECT * FROM Pets;Ergebnis:
+---------+-----------+-----------+ | PetId | PetName | PetType | |---------+-----------+-----------| | 1 | Wag | Dog | | 1 | Wag | Dog | | 2 | Scratch | Cat | | 3 | Tweet | Bird | | 4 | Bark | Dog | | 4 | Bark | Dog | | 4 | Bark | Dog | +---------+-----------+-----------+
Wir können sehen, dass die ersten beiden Zeilen Duplikate sind, ebenso wie die letzten drei Zeilen.
Option 1
Wir können die folgende Abfrage verwenden, um Informationen über doppelte Zeilen zurückzugeben:
SELECT
DISTINCT PetId,
COUNT(*) AS "Count"
FROM Pets
GROUP BY PetId
ORDER BY PetId;Ergebnis:
+---------+---------+ | PetId | Count | |---------+---------| | 1 | 2 | | 2 | 1 | | 3 | 1 | | 4 | 3 | +---------+---------+
Wir können SELECT erweitern Liste, um bei Bedarf weitere Spalten aufzunehmen:
SELECT
PetId,
PetName,
PetType,
COUNT(*) AS "Count"
FROM Pets
GROUP BY
PetId,
PetName,
PetType
ORDER BY PetId;Ergebnis:
+---------+-----------+-----------+---------+ | PetId | PetName | PetType | Count | |---------+-----------+-----------+---------| | 1 | Wag | Dog | 2 | | 2 | Scratch | Cat | 1 | | 3 | Tweet | Bird | 1 | | 4 | Bark | Dog | 3 | +---------+-----------+-----------+---------+
Wenn die Tabelle einen eindeutigen Bezeichner hat, können wir diese Spalte einfach aus der Abfrage entfernen. Nehmen wir beispielsweise an, dass die PetId Spalte tatsächlich eine Primärschlüsselspalte ist, die eine eindeutige ID enthält, könnten wir die folgende Abfrage ausführen, um alle Zeilen zurückzugeben, die Duplikate sind, wobei die Primärschlüsselspalte nicht mitgezählt wird:
SELECT
PetName,
PetType,
COUNT(*) AS "Count"
FROM Pets
GROUP BY
PetName,
PetType
ORDER BY PetName;Ergebnis:
+-----------+-----------+---------+ | PetName | PetType | Count | |-----------+-----------+---------| | Bark | Dog | 3 | | Scratch | Cat | 1 | | Tweet | Bird | 1 | | Wag | Dog | 2 | +-----------+-----------+---------+
Option 2
Wenn wir nur die tatsächlichen doppelten Zeilen zurückgeben möchten, können wir den HAVING hinzufügen Klausel:
SELECT
PetId,
PetName,
PetType,
COUNT(*) AS "Count"
FROM Pets
GROUP BY
PetId,
PetName,
PetType
HAVING COUNT(*) > 1
ORDER BY PetId;Ergebnis:
+---------+-----------+-----------+---------+ | PetId | PetName | PetType | Count | |---------+-----------+-----------+---------| | 1 | Wag | Dog | 2 | | 4 | Bark | Dog | 3 | +---------+-----------+-----------+---------+
Option 3
Eine andere Möglichkeit ist die Verwendung von ROW_NUMBER() Funktion mit dem PARTITION BY -Klausel, um die Ausgabe der Ergebnismenge zu nummerieren.
SELECT
*,
ROW_NUMBER() OVER (
PARTITION BY PetId, PetName, PetType
ORDER BY PetId, PetName, PetType
) AS Row_Number
FROM Pets;Ergebnis:
+---------+-----------+-----------+--------------+ | PetId | PetName | PetType | Row_Number | |---------+-----------+-----------+--------------| | 1 | Wag | Dog | 1 | | 1 | Wag | Dog | 2 | | 2 | Scratch | Cat | 1 | | 3 | Tweet | Bird | 1 | | 4 | Bark | Dog | 1 | | 4 | Bark | Dog | 2 | | 4 | Bark | Dog | 3 | +---------+-----------+-----------+--------------+
Die PARTITION BY -Klausel teilt die von FROM erzeugte Ergebnismenge -Klausel in Partitionen, auf die die Funktion angewendet wird. Wenn wir Partitionen für die Ergebnismenge angeben, bewirkt jede Partition, dass die Nummerierung wieder von vorne beginnt (d. h. die Nummerierung beginnt bei 1 für die erste Zeile in jeder Partition).
Option 4
Wenn wir möchten, dass nur überschüssige Zeilen aus den übereinstimmenden Duplikaten zurückgegeben werden, können wir die obige Abfrage wie folgt als allgemeinen Tabellenausdruck verwenden:
WITH CTE AS
(
SELECT
*,
ROW_NUMBER() OVER (
PARTITION BY PetId, PetName, PetType
ORDER BY PetId, PetName, PetType
) AS Row_Number
FROM Pets
)
SELECT * FROM CTE WHERE Row_Number <> 1;Ergebnis:
+---------+-----------+-----------+--------------+ | PetId | PetName | PetType | Row_Number | |---------+-----------+-----------+--------------| | 1 | Wag | Dog | 2 | | 4 | Bark | Dog | 2 | | 4 | Bark | Dog | 3 | +---------+-----------+-----------+--------------+
Einer der Vorteile dabei ist, dass wir doppelte Zeilen löschen können, indem wir einfach SELECT * wechseln zu DELETE (in der letzten Zeile).
Daher können wir den obigen Code verwenden, um zu sehen, welche Zeilen gelöscht werden, und wenn wir dann zufrieden sind, dass wir die richtigen Zeilen löschen werden, können wir ihn zu einem DELETE ändern Anweisung, sie tatsächlich zu löschen.
So:
WITH CTE AS
(
SELECT
*,
ROW_NUMBER() OVER (
PARTITION BY PetId, PetName, PetType
ORDER BY PetId, PetName, PetType
) AS Row_Number
FROM Pets
)
DELETE FROM CTE WHERE Row_Number <> 1;