Ich sehe viele Ratschläge da draußen, die etwas in der Art sagen:"Ändern Sie Ihren Cursor in eine satzbasierte Operation; das wird es schneller machen." Obwohl das oft der Fall sein kann, ist es nicht immer wahr. Ein Anwendungsfall, den ich sehe, bei dem ein Cursor den typischen satzbasierten Ansatz wiederholt übertrifft, ist die Berechnung laufender Summen. Dies liegt daran, dass der satzbasierte Ansatz normalerweise einen Teil der zugrunde liegenden Daten mehr als einmal betrachten muss, was eine exponentiell schlechte Sache sein kann, wenn die Daten größer werden; wohingegen ein Cursor – so schmerzhaft es auch klingen mag – jede Zeile/jeden Wert genau einmal durchlaufen kann.
Dies sind unsere grundlegenden Optionen in den gängigsten Versionen von SQL Server. In SQL Server 2012 wurden jedoch mehrere Verbesserungen an Windowing-Funktionen und der OVER-Klausel vorgenommen, die größtenteils auf mehrere großartige Vorschläge zurückgehen, die von MVP-Kollege Itzik Ben-Gan eingereicht wurden (hier ist einer seiner Vorschläge). Tatsächlich hat Itzik ein neues MS-Press-Buch mit dem Titel „Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions“ herausgebracht, das all diese Verbesserungen viel ausführlicher behandelt.
Also war ich natürlich neugierig; Würde die neue Fensterfunktionalität den Cursor und die Self-Join-Techniken überflüssig machen? Wären sie einfacher zu codieren? Wären sie in allen (egal welchen) Fällen schneller? Welche anderen Ansätze könnten gültig sein?
Die Einrichtung
Lassen Sie uns zum Testen eine Datenbank einrichten:
USE [master];
GO
IF DB_ID('RunningTotals') IS NOT NULL
BEGIN
ALTER DATABASE RunningTotals SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE RunningTotals;
END
GO
CREATE DATABASE RunningTotals;
GO
USE RunningTotals;
GO
SET NOCOUNT ON;
GO Und dann füllen Sie eine Tabelle mit 10.000 Zeilen, die wir verwenden können, um einige laufende Summen zu berechnen. Nichts zu kompliziertes, nur eine zusammenfassende Tabelle mit einer Zeile für jedes Datum und einer Zahl, die angibt, wie viele Strafzettel ausgestellt wurden. Ich habe seit ein paar Jahren keinen Strafzettel mehr bekommen, daher weiß ich nicht, warum dies meine unbewusste Wahl für ein vereinfachtes Datenmodell war, aber da ist es.
CREATE TABLE dbo.SpeedingTickets ( [Date] DATE NOT NULL, TicketCount INT ); GO ALTER TABLE dbo.SpeedingTickets ADD CONSTRAINT pk PRIMARY KEY CLUSTERED ([Date]); GO ;WITH x(d,h) AS ( SELECT TOP (250) ROW_NUMBER() OVER (ORDER BY [object_id]), CONVERT(INT, RIGHT([object_id], 2)) FROM sys.all_objects ORDER BY [object_id] ) INSERT dbo.SpeedingTickets([Date], TicketCount) SELECT TOP (10000) d = DATEADD(DAY, x2.d + ((x.d-1)*250), '19831231'), x2.h FROM x CROSS JOIN x AS x2 ORDER BY d; GO SELECT [Date], TicketCount FROM dbo.SpeedingTickets ORDER BY [Date]; GO
Gekürzte Ergebnisse:
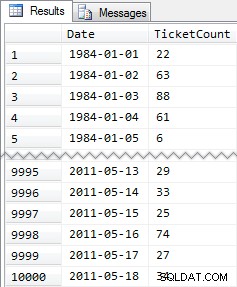
Also wieder 10.000 Zeilen mit ziemlich einfachen Daten – kleine INT-Werte und eine Reihe von Daten von 1984 bis Mai 2011.
Die Ansätze
Jetzt ist meine Aufgabe relativ einfach und typisch für viele Anwendungen:Geben Sie eine Ergebnismenge zurück, die alle 10.000 Daten enthält, zusammen mit der kumulierten Summe aller Strafzettel für zu schnelles Fahren bis einschließlich dieses Datums. Die meisten Leute würden zuerst so etwas ausprobieren (wir nennen das die "innere Verknüpfung". "-Methode):
SELECT st1.[Date], st1.TicketCount, RunningTotal = SUM(st2.TicketCount) FROM dbo.SpeedingTickets AS st1 INNER JOIN dbo.SpeedingTickets AS st2 ON st2.[Date] <= st1.[Date] GROUP BY st1.[Date], st1.TicketCount ORDER BY st1.[Date];
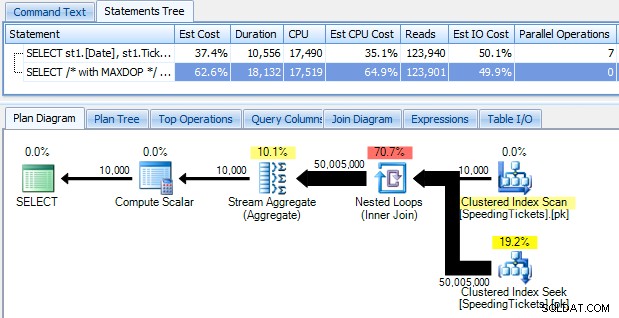
…und seien Sie schockiert, wenn Sie feststellen, dass es fast 10 Sekunden dauert, um zu laufen. Lassen Sie uns schnell untersuchen, warum, indem Sie den grafischen Ausführungsplan mit dem SQL Sentry Plan Explorer anzeigen:

Die großen dicken Pfeile sollten einen sofortigen Hinweis darauf geben, was vor sich geht:Die verschachtelte Schleife liest eine Zeile für die erste Aggregation, zwei Zeilen für die zweite, drei Zeilen für die dritte und so weiter und weiter durch den gesamten Satz von 10.000 Zeilen. Dies bedeutet, dass ungefähr ((10000 * (10000 + 1)) / 2) Zeilen verarbeitet werden sollten, sobald der gesamte Satz durchlaufen wurde, und das scheint mit der Anzahl der im Plan angezeigten Zeilen übereinzustimmen.
Beachten Sie, dass das Ausführen der Abfrage ohne Parallelität (unter Verwendung des Abfragehinweises OPTION (MAXDOP 1)) die Planform ein wenig einfacher macht, aber weder bei der Ausführungszeit noch bei der E/A hilft; Wie im Plan gezeigt, verdoppelt sich die Dauer tatsächlich fast und die Messwerte nehmen nur um einen sehr kleinen Prozentsatz ab. Im Vergleich zum vorherigen Plan:
Es gibt viele andere Ansätze, die Menschen versucht haben, um effiziente laufende Summen zu erhalten. Ein Beispiel ist die "subquery method ", die nur eine korrelierte Unterabfrage ähnlich wie die oben beschriebene innere Join-Methode verwendet:
SELECT [Date], TicketCount, RunningTotal = TicketCount + COALESCE( ( SELECT SUM(TicketCount) FROM dbo.SpeedingTickets AS s WHERE s.[Date] < o.[Date]), 0 ) FROM dbo.SpeedingTickets AS o ORDER BY [Date];
Vergleich dieser beiden Pläne:
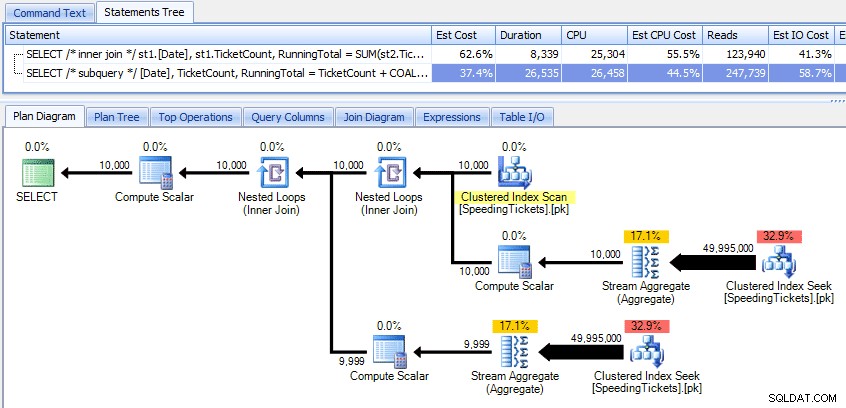
Während die Subquery-Methode einen effizienteren Gesamtplan zu haben scheint, ist sie dort, wo es darauf ankommt, schlechter:Dauer und I/O. Wir können sehen, was dazu beiträgt, wenn wir etwas tiefer in die Pläne eintauchen. Wenn wir zur Registerkarte „Top-Operationen“ wechseln, können wir sehen, dass in der Inner-Join-Methode die Clustered-Index-Suche 10.000 Mal ausgeführt wird und alle anderen Operationen nur wenige Male ausgeführt werden. Einige Operationen werden jedoch 9.999 oder 10.000 Mal in der Subquery-Methode ausgeführt:
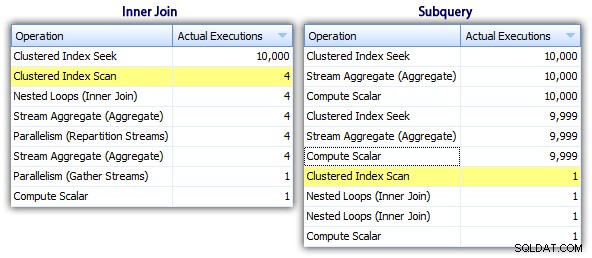
Der Unterabfrage-Ansatz scheint also schlechter zu sein, nicht besser. Die nächste Methode, die wir ausprobieren werden, nenne ich das "skurrile Update "-Methode. Es ist nicht unbedingt garantiert, dass dies funktioniert, und ich würde es niemals für Produktionscode empfehlen, aber ich füge es der Vollständigkeit halber hinzu. Grundsätzlich nutzt das schrullige Update die Tatsache aus, dass Sie während eines Updates Zuweisungen und Mathematik umleiten können dass die Variable hinter den Kulissen inkrementiert wird, wenn jede Zeile aktualisiert wird.
DECLARE @st TABLE ( [Date] DATE PRIMARY KEY, TicketCount INT, RunningTotal INT ); DECLARE @RunningTotal INT = 0; INSERT @st([Date], TicketCount, RunningTotal) SELECT [Date], TicketCount, RunningTotal = 0 FROM dbo.SpeedingTickets ORDER BY [Date]; UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st; SELECT [Date], TicketCount, RunningTotal FROM @st ORDER BY [Date];
Ich möchte noch einmal sagen, dass ich nicht glaube, dass dieser Ansatz für die Produktion sicher ist, unabhängig von den Aussagen, die Sie von Leuten hören werden, die darauf hinweisen, dass er „nie fehlschlägt“. Sofern das Verhalten nicht dokumentiert und garantiert ist, versuche ich mich von Annahmen fernzuhalten, die auf beobachtetem Verhalten beruhen. Sie wissen nie, wann eine Änderung am Entscheidungspfad des Optimierers (basierend auf einer Statistikänderung, Datenänderung, Service Pack, Trace-Flag, Abfragehinweis, was haben Sie) den Plan drastisch ändern und möglicherweise zu einer anderen Reihenfolge führen wird. Wenn Ihnen dieser nicht intuitive Ansatz wirklich gefällt, können Sie sich ein wenig besser fühlen, indem Sie die Abfrageoption FORCE ORDER verwenden (und dies versucht, einen geordneten Scan des PK zu verwenden, da dies der einzige geeignete Index für die Tabellenvariable ist):
UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st OPTION (FORCE ORDER);
Für etwas mehr Vertrauen bei etwas höheren E/A-Kosten können Sie die ursprüngliche Tabelle wieder ins Spiel bringen und sicherstellen, dass der PK der Basistabelle verwendet wird:
UPDATE st SET @RunningTotal = st.RunningTotal = @RunningTotal + t.TicketCount FROM dbo.SpeedingTickets AS t WITH (INDEX = pk) INNER JOIN @st AS st ON t.[Date] = st.[Date] OPTION (FORCE ORDER);
Ich persönlich glaube nicht, dass es so viel garantierter ist, da der SET-Teil der Operation möglicherweise den Optimierer unabhängig vom Rest der Abfrage beeinflussen könnte. Auch hier empfehle ich diesen Ansatz nicht, ich füge den Vergleich nur der Vollständigkeit halber hinzu. Hier ist der Plan aus dieser Abfrage:
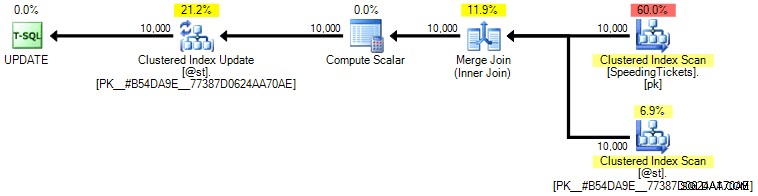
Basierend auf der Anzahl der Ausführungen, die wir auf der Registerkarte Top-Operationen sehen (ich erspare Ihnen den Screenshot; es ist 1 für jede Operation), ist es klar, dass selbst wenn wir einen Join durchführen, um uns beim Bestellen besser zu fühlen, das Skurrile ist update ermöglicht die Berechnung der laufenden Summen in einem einzigen Durchlauf der Daten. Im Vergleich zu den vorherigen Abfragen ist es viel effizienter, obwohl es zuerst Daten in eine Tabellenvariable ausgibt und in mehrere Operationen aufgeteilt wird:

Dies bringt uns zu einem "rekursiven CTE "-Methode. Diese Methode verwendet den Datumswert und beruht auf der Annahme, dass es keine Lücken gibt. Da wir diese Daten oben ausgefüllt haben, wissen wir, dass es sich um eine vollständig zusammenhängende Reihe handelt, aber in vielen Szenarien ist dies nicht möglich Annahme. Also, obwohl ich es der Vollständigkeit halber aufgenommen habe, wird dieser Ansatz nicht immer gültig sein. In jedem Fall verwendet dies einen rekursiven CTE mit dem ersten (bekannten) Datum in der Tabelle als Anker und dem rekursiven Teil, der durch Hinzufügen eines Tages bestimmt wird (Hinzufügen der Option MAXRECURSION, da wir genau wissen, wie viele Zeilen wir haben):
;WITH x AS ( SELECT [Date], TicketCount, RunningTotal = TicketCount FROM dbo.SpeedingTickets WHERE [Date] = '19840101' UNION ALL SELECT y.[Date], y.TicketCount, x.RunningTotal + y.TicketCount FROM x INNER JOIN dbo.SpeedingTickets AS y ON y.[Date] = DATEADD(DAY, 1, x.[Date]) ) SELECT [Date], TicketCount, RunningTotal FROM x ORDER BY [Date] OPTION (MAXRECURSION 10000);
Diese Abfrage funktioniert ungefähr so effizient wie die schrullige Update-Methode. Wir können es mit den Unterabfrage- und Inner-Join-Methoden vergleichen:

Wie die schrullige Aktualisierungsmethode würde ich diesen CTE-Ansatz in der Produktion nicht empfehlen, es sei denn, Sie können absolut garantieren, dass Ihre Schlüsselspalte keine Lücken aufweist. Wenn Sie möglicherweise Lücken in Ihren Daten haben, können Sie etwas Ähnliches mit ROW_NUMBER() konstruieren, aber es wird nicht effizienter sein als die obige Self-Join-Methode.
Und dann haben wir den "Cursor " Vorgehensweise:
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
DECLARE
@Date DATE,
@TicketCount INT,
@RunningTotal INT = 0;
DECLARE c CURSOR
LOCAL STATIC FORWARD_ONLY READ_ONLY
FOR
SELECT [Date], TicketCount
FROM dbo.SpeedingTickets
ORDER BY [Date];
OPEN c;
FETCH NEXT FROM c INTO @Date, @TicketCount;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @RunningTotal = @RunningTotal + @TicketCount;
INSERT @st([Date], TicketCount, RunningTotal)
SELECT @Date, @TicketCount, @RunningTotal;
FETCH NEXT FROM c INTO @Date, @TicketCount;
END
CLOSE c;
DEALLOCATE c;
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date]; … was viel mehr Code ist, aber entgegen der landläufigen Meinung in 1 Sekunde zurückkehrt. Wir können aus einigen der obigen Plandetails ersehen, warum:Die meisten anderen Ansätze lesen dieselben Daten immer und immer wieder, während der Cursor-Ansatz jede Zeile einmal liest und die laufende Summe in einer Variablen hält, anstatt die Summe zu berechnen und immer wieder. Wir können dies sehen, indem wir uns die Aussagen ansehen, die durch die Generierung eines tatsächlichen Plans im Plan Explorer erfasst wurden:
Wir können sehen, dass über 20.000 Anweisungen gesammelt wurden, aber wenn wir absteigend nach geschätzten oder tatsächlichen Zeilen sortieren, stellen wir fest, dass es nur zwei Operationen gibt, die mehr als eine Zeile verarbeiten. Das ist weit entfernt von einigen der oben genannten Methoden, die exponentielle Lesevorgänge verursachen, da dieselben vorherigen Zeilen für jede neue Zeile immer und immer wieder gelesen werden.
Werfen wir nun einen Blick auf die neuen Windowing-Verbesserungen in SQL Server 2012. Insbesondere können wir jetzt SUM OVER() berechnen und eine Reihe von Zeilen relativ zur aktuellen Zeile angeben. Also zum Beispiel:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] RANGE UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date]; SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] ROWS UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date];
Diese beiden Abfragen geben zufällig die gleiche Antwort mit korrekten laufenden Summen. Aber funktionieren sie genau gleich? Die Pläne deuten darauf hin, dass dies nicht der Fall ist. Die Version mit ROWS hat einen zusätzlichen Operator, ein 10.000-Zeilen-Sequenzprojekt:
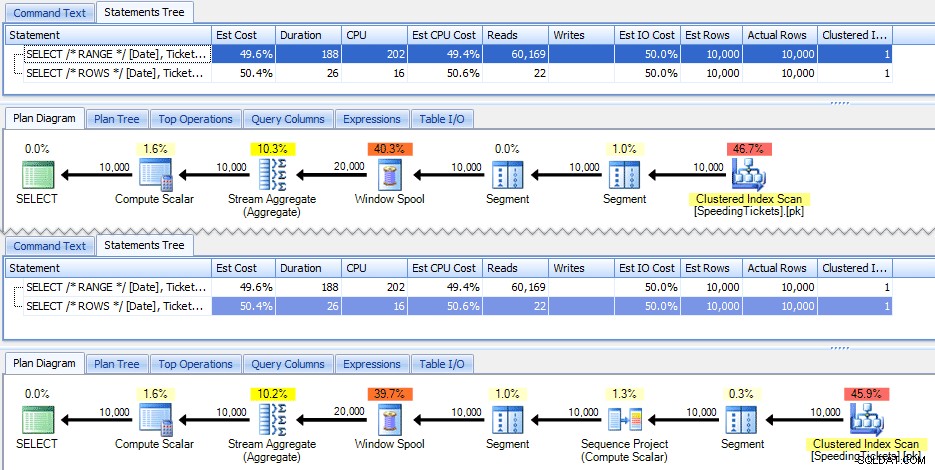
Und das ist ungefähr das Ausmaß des Unterschieds im grafischen Plan. Aber wenn Sie sich die tatsächlichen Laufzeitmetriken etwas genauer ansehen, sehen Sie geringfügige Unterschiede bei Dauer und CPU und einen großen Unterschied bei den Lesevorgängen. Warum ist das? Nun, das liegt daran, dass RANGE einen Spool auf der Festplatte verwendet, während ROWS einen Spool im Speicher verwendet. Bei kleinen Sets ist der Unterschied wahrscheinlich vernachlässigbar, aber die Kosten für die Spule auf der Festplatte können sicherlich deutlicher werden, wenn die Sets größer werden. Ich möchte das Ende nicht verderben, aber Sie könnten vermuten, dass eine dieser Lösungen in einem gründlicheren Test besser abschneidet als die andere.
Abgesehen davon liefert die folgende Version der Abfrage die gleichen Ergebnisse, funktioniert aber wie die langsamere RANGE-Version oben:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date]) FROM dbo.SpeedingTickets ORDER BY [Date];
Wenn Sie also mit den neuen Fensterfunktionen spielen, sollten Sie solche kleinen Leckerbissen im Hinterkopf behalten:Die abgekürzte Version einer Abfrage oder diejenige, die Sie zufällig zuerst geschrieben haben, ist nicht unbedingt die gewünschte zur Produktion zu pushen.
Die eigentlichen Tests
Um faire Tests durchzuführen, habe ich für jeden Ansatz eine gespeicherte Prozedur erstellt und die Ergebnisse gemessen, indem ich Anweisungen auf einem Server erfasst habe, auf dem ich bereits mit SQL Sentry überwacht habe (wenn Sie unser Tool nicht verwenden, können Sie SQL:BatchCompleted-Ereignisse sammeln auf ähnliche Weise mit SQL Server Profiler).
Mit „fairen Tests“ meine ich, dass zum Beispiel die schrullige Update-Methode eine tatsächliche Aktualisierung statischer Daten erfordert, was bedeutet, dass das zugrunde liegende Schema geändert oder eine temporäre Tabelle / Tabellenvariable verwendet wird. Also habe ich die gespeicherten Prozeduren so strukturiert, dass jede ihre eigene Tabellenvariable erstellt und entweder die Ergebnisse dort speichert oder die Rohdaten dort speichert und dann das Ergebnis aktualisiert. Das andere Problem, das ich beseitigen wollte, war die Rückgabe der Daten an den Client – daher haben die Prozeduren jeweils einen Debug-Parameter, der angibt, ob keine Ergebnisse (Standardeinstellung), top/bottom 5 oder alle zurückgegeben werden sollen. In den Leistungstests habe ich es so eingestellt, dass keine Ergebnisse zurückgegeben werden, aber ich habe natürlich alle validiert, um sicherzustellen, dass sie die richtigen Ergebnisse zurückgeben.
Die gespeicherten Prozeduren sind alle auf diese Weise modelliert (ich habe ein Skript angehängt, das die Datenbank und die gespeicherten Prozeduren erstellt, also füge ich der Kürze halber hier nur eine Vorlage ein):
CREATE PROCEDURE [dbo].[RunningTotals_]
@debug TINYINT = 0
-- @debug = 1 : show top/bottom 3
-- @debug = 2 : show all 50k
AS
BEGIN
SET NOCOUNT ON;
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
INSERT @st([Date], TicketCount, RunningTotal)
-- one of seven approaches used to populate @t
IF @debug = 1 -- show top 3 and last 3 to verify results
BEGIN
;WITH d AS
(
SELECT [Date], TicketCount, RunningTotal,
rn = ROW_NUMBER() OVER (ORDER BY [Date])
FROM @st
)
SELECT [Date], TicketCount, RunningTotal
FROM d
WHERE rn < 4 OR rn > 9997
ORDER BY [Date];
END
IF @debug = 2 -- show all
BEGIN
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date];
END
END
GO Und ich habe sie in einem Batch wie folgt aufgerufen:
EXEC dbo.RunningTotals_DateCTE @debug = 0; GO EXEC dbo.RunningTotals_Cursor @debug = 0; GO EXEC dbo.RunningTotals_Subquery @debug = 0; GO EXEC dbo.RunningTotals_InnerJoin @debug = 0; GO EXEC dbo.RunningTotals_QuirkyUpdate @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Range @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; GO
Mir wurde schnell klar, dass einige dieser Aufrufe nicht in Top SQL auftauchten, da der Standardschwellenwert 5 Sekunden beträgt. Ich habe das wie folgt auf 100 Millisekunden geändert (etwas, das Sie niemals auf einem Produktionssystem tun möchten!):
Ich wiederhole:Dieses Verhalten wird für Produktionssysteme nicht geduldet!
Ich habe immer noch festgestellt, dass einer der oben genannten Befehle nicht vom oberen SQL-Schwellenwert abgefangen wurde. es war die Windowed_Rows-Version. Also habe ich nur diesem Stapel Folgendes hinzugefügt:
EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; WAITFOR DELAY '00:00:01'; GO
Und jetzt bekam ich alle 7 Zeilen in Top SQL zurückgegeben. Hier sind sie absteigend nach CPU-Auslastung geordnet:
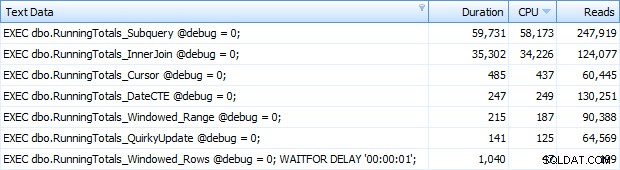
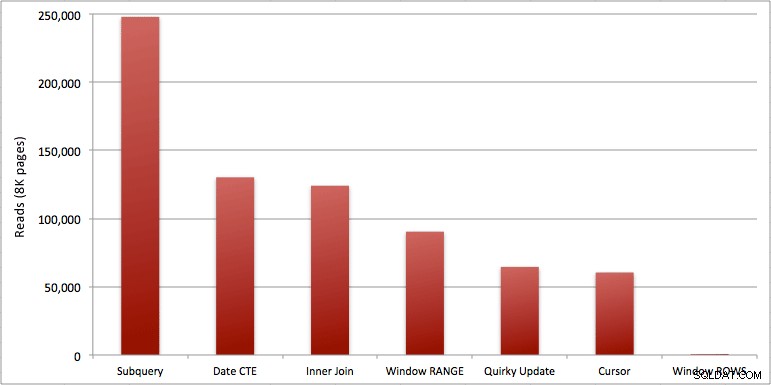
Sie können die zusätzliche Sekunde sehen, die ich dem Batch Windowed_Rows hinzugefügt habe; Es wurde nicht von der Top-SQL-Schwelle erfasst, da es in nur 40 Millisekunden abgeschlossen war! Dies ist eindeutig unsere beste Leistung, und wenn wir SQL Server 2012 zur Verfügung haben, sollte dies die Methode sein, die wir verwenden. Der Cursor ist auch nicht halb so schlecht, entweder angesichts der Leistung oder anderer Probleme mit den verbleibenden Lösungen. Die Dauer in einem Diagramm darzustellen, ist ziemlich bedeutungslos – zwei Höhepunkte und fünf ununterscheidbare Tiefpunkte. Aber wenn E/A Ihr Engpass ist, finden Sie vielleicht die Visualisierung von Lesevorgängen interessant:
Schlussfolgerung
Aus diesen Ergebnissen können wir einige Schlussfolgerungen ziehen:
- Windowed-Aggregate in SQL Server 2012 machen Leistungsprobleme bei laufenden Summenberechnungen (und viele andere Probleme mit der/den nächsten Zeile(n)/vorherigen Zeile(n)) alarmierend effizienter. Als ich die geringe Anzahl von Lesevorgängen sah, dachte ich, dass es sich um einen Fehler handelte, dass ich vergessen haben musste, tatsächlich eine Arbeit auszuführen. Aber nein, Sie erhalten die gleiche Anzahl von Lesevorgängen, wenn Ihre gespeicherte Prozedur nur ein gewöhnliches SELECT aus der SpeedingTickets-Tabelle ausführt. (Sie können dies gerne selbst mit STATISTICS IO testen.)
- Die Probleme, auf die ich zuvor in Bezug auf RANGE vs. ROWS hingewiesen habe, führen zu leicht unterschiedlichen Laufzeiten (Dauerunterschied von etwa dem 6-fachen – denken Sie daran, den zweiten zu ignorieren, den ich mit WAITFOR hinzugefügt habe), aber die Leseunterschiede sind aufgrund des Spools auf der Festplatte astronomisch. Wenn Ihr gefenstertes Aggregat mit ROWS gelöst werden kann, vermeiden Sie RANGE, aber Sie sollten testen, ob beide das gleiche Ergebnis liefern (oder zumindest, dass ROWS die richtige Antwort liefert). Sie sollten auch beachten, dass, wenn Sie eine ähnliche Abfrage verwenden und weder RANGE noch ROWS angeben, der Plan so funktioniert, als ob Sie RANGE angegeben hätten).
- Die Unterabfrage- und Inner-Join-Methoden sind relativ miserabel. 35 Sekunden bis eine Minute, um diese laufenden Summen zu generieren? Und dies auf einem einzigen, mageren Tisch, ohne Ergebnisse an den Kunden zurückzugeben. Diese Vergleiche können verwendet werden, um Menschen zu zeigen, warum eine rein satzbasierte Lösung nicht immer die beste Antwort ist.
- Von den schnelleren Ansätzen, vorausgesetzt, Sie sind noch nicht bereit für SQL Server 2012, und vorausgesetzt, Sie verwerfen sowohl die eigenartige Aktualisierungsmethode (nicht unterstützt) als auch die CTE-Datumsmethode (kann keine zusammenhängende Sequenz garantieren), funktioniert nur der Cursor akzeptabel. Es hat die höchste Dauer der "schnelleren" Lösungen, aber die wenigsten Lesevorgänge.
Ich hoffe, dass diese Tests dazu beitragen, die Windows-Verbesserungen, die Microsoft SQL Server 2012 hinzugefügt hat, besser einschätzen zu können. Bitte danken Sie Itzik, wenn Sie ihn online oder persönlich sehen, da er die treibende Kraft hinter diesen Änderungen war. Außerdem hoffe ich, dass dies dazu beiträgt, einige da draußen dafür zu sensibilisieren, dass ein Cursor nicht immer die böse und gefürchtete Lösung ist, als die er oft dargestellt wird.
(Als Ergänzung habe ich die von Pavel Pawlowski angebotene CLR-Funktion getestet, und die Leistungsmerkmale waren nahezu identisch mit der SQL Server 2012-Lösung mit ROWS. Die Lesevorgänge waren identisch, die CPU war 78 vs. 47 und die Gesamtdauer war 73 statt 40. Wenn Sie also nicht in naher Zukunft zu SQL Server 2012 wechseln, möchten Sie vielleicht Pavels Lösung zu Ihren Tests hinzufügen.)
Anhänge:RunningTotals_Demo.sql.zip (2kb)