Das „Don’t Repeat Yourself“-Prinzip schlägt vor, Wiederholungen zu reduzieren. Diese Woche bin ich auf einen Fall gestoßen, wo DRY aus dem Fenster geworfen werden sollte. Es gibt auch andere Fälle (z. B. Skalarfunktionen), aber dieser war interessant und beinhaltete die bitweise Logik.
Stellen wir uns folgende Tabelle vor:
CREATE TABLE dbo.CarOrders
(
OrderID INT PRIMARY KEY,
WheelFlag TINYINT,
OrderDate DATE
--, ... other columns ...
);
CREATE INDEX IX_WheelFlag ON dbo.CarOrders(WheelFlag); Die "WheelFlag"-Bits repräsentieren die folgenden Optionen:
0 = stock wheels 1 = 17" wheels 2 = 18" wheels 4 = upgraded tires
Mögliche Kombinationen sind also:
0 = no upgrade 1 = upgrade to 17" wheels only 2 = upgrade to 18" wheels only 4 = upgrade tires only 5 = 1 + 4 = upgrade to 17" wheels and better tires 6 = 2 + 4 = upgrade to 18" wheels and better tires
Lassen Sie uns Argumente, zumindest für den Moment, beiseite lassen, ob dies überhaupt in ein einzelnes TINYINT gepackt oder als separate Spalten gespeichert werden sollte oder ein EAV-Modell verwendet werden soll… Das Fixieren des Designs ist ein separates Problem. Hier geht es darum, mit dem zu arbeiten, was Sie haben.
Um die Beispiele nützlich zu machen, füllen wir diese Tabelle mit einer Reihe zufälliger Daten. (Und wir gehen der Einfachheit halber davon aus, dass diese Tabelle nur Bestellungen enthält, die noch nicht versandt wurden.) Dadurch werden 50.000 Zeilen mit ungefähr gleicher Verteilung zwischen den sechs Optionskombinationen eingefügt:
;WITH n AS
(
SELECT n,Flag FROM (VALUES(1,0),(2,1),(3,2),(4,4),(5,5),(6,6)) AS n(n,Flag)
)
INSERT dbo.CarOrders
(
OrderID,
WheelFlag,
OrderDate
)
SELECT x.rn, n.Flag, DATEADD(DAY, x.rn/100, '20100101')
FROM n
INNER JOIN
(
SELECT TOP (50000)
n = (ABS(s1.[object_id]) % 6) + 1,
rn = ROW_NUMBER() OVER (ORDER BY s2.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x
ON n.n = x.n; Wenn wir uns die Aufschlüsselung ansehen, können wir diese Verteilung sehen. Beachten Sie, dass Ihre Ergebnisse abhängig von den Objekten in Ihrem System leicht von meinen abweichen können:
SELECT WheelFlag, [Count] = COUNT(*) FROM dbo.CarOrders GROUP BY WheelFlag;
Ergebnisse:
WheelFlag Count --------- ----- 0 7654 1 8061 2 8757 4 8682 5 8305 6 8541
Nehmen wir an, es ist Dienstag und wir haben gerade eine Lieferung von 18-Zoll-Rädern erhalten, die zuvor nicht vorrätig waren. Das bedeutet, dass wir alle Bestellungen erfüllen können, die 18-Zoll-Räder erfordern – sowohl solche mit aufgerüsteten Reifen (6), und diejenigen, die dies nicht taten (2). Wir *könnten* also eine Abfrage wie die folgende schreiben:
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag IN (2,6); Im wirklichen Leben kann man das natürlich nicht wirklich machen; Was ist, wenn später weitere Optionen hinzugefügt werden, wie Radschlösser, lebenslange Radgarantie oder mehrere Reifenoptionen? Sie möchten nicht für jede mögliche Kombination eine Reihe von IN()-Werten schreiben müssen. Stattdessen können wir eine BITWISE AND-Operation schreiben, um alle Zeilen zu finden, in denen das 2. Bit gesetzt ist, wie zum Beispiel:
DECLARE @Flag TINYINT = 2;
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag & @Flag = @Flag; Dies bringt mir die gleichen Ergebnisse wie die IN()-Abfrage, aber wenn ich sie mit dem SQL Sentry Plan Explorer vergleiche, ist die Leistung ganz anders:

Es ist leicht zu verstehen, warum. Die erste verwendet eine Indexsuche, um die Zeilen zu isolieren, die die Abfrage erfüllen, mit einem Filter für die WheelFlag-Spalte:
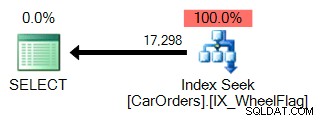

Die zweite verwendet einen Scan, gekoppelt mit einer impliziten Konvertierung und schrecklich ungenauen Statistiken. Alles aufgrund des BITWISE AND-Operators:
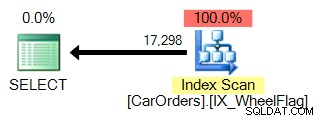


Was bedeutet das also? Im Kern sagt uns dies, dass die BITWISE AND-Operation nicht sargfähig ist .
Aber nicht alle Hoffnung ist verloren.
Wenn wir das DRY-Prinzip für einen Moment ignorieren, können wir eine etwas effizientere Abfrage schreiben, indem wir etwas redundant sind, um den Index in der WheelFlag-Spalte zu nutzen. Unter der Annahme, dass wir hinter einer WheelFlag-Option über 0 her sind (überhaupt kein Upgrade), können wir die Abfrage auf diese Weise umschreiben und SQL Server mitteilen, dass der WheelFlag-Wert mindestens derselbe Wert sein muss wie flag (wodurch 0 und 1 eliminiert werden ) und fügt dann die zusätzlichen Informationen hinzu, dass es auch dieses Flag enthalten muss (wodurch 5 eliminiert wird).
SELECT OrderID FROM dbo.CarOrders WHERE WheelFlag >= @Flag AND WheelFlag & @Flag = @Flag;
Der>=-Teil dieser Klausel wird offensichtlich vom BITWISE-Teil abgedeckt, also verletzen wir hier DRY. Da diese von uns hinzugefügte Klausel jedoch sargable ist, führt die Relegation der BITWISE AND-Operation zu einer sekundären Suchbedingung immer noch zum gleichen Ergebnis, und die Gesamtabfrage führt zu einer besseren Leistung. Wir sehen eine ähnliche Indexsuche wie bei der fest codierten Version der obigen Abfrage, und obwohl die Schätzungen noch weiter entfernt sind (etwas, das als separates Problem behandelt werden kann), sind die Lesevorgänge immer noch niedriger als bei der BITWISE AND-Operation allein:

Wir können auch sehen, dass ein Filter gegen den Index verwendet wird, was wir bei der alleinigen Verwendung der BITWISE AND-Operation nicht gesehen haben:

Schlussfolgerung
Scheuen Sie sich nicht, sich zu wiederholen. Es gibt Zeiten, in denen diese Informationen dem Optimierer helfen können; Auch wenn es nicht ganz intuitiv ist, Kriterien zu *hinzufügen*, um die Leistung zu verbessern, ist es wichtig zu verstehen, wann zusätzliche Klauseln dabei helfen, die Daten für das Endergebnis zu reduzieren, anstatt es dem Optimierer "einfach" zu machen, die genauen Zeilen zu finden allein.