SQL Server 2014 CTP1 ist jetzt seit ein paar Wochen auf dem Markt, und Sie haben wahrscheinlich ziemlich viel Presse über speicheroptimierte Tabellen und aktualisierbare Columnstore-Indizes gesehen. Während diese sicherlich Aufmerksamkeit verdienen, wollte ich in diesem Beitrag die neue SELECT … INTO-Parallelitätsverbesserung untersuchen. Die Verbesserung ist eine dieser gebrauchsfertigen Änderungen, die, so wie es aussieht, keine wesentlichen Codeänderungen erfordern, um davon zu profitieren. Meine Untersuchungen wurden mit Version Microsoft SQL Server 2014 (CTP1) – 11.0.9120.5 (X64), Enterprise Evaluation Edition durchgeführt.
Parallele AUSWAHL … IN
SQL Server 2014 führt parallel aktiviertes SELECT ... INTO ein für Datenbanken und um diese Funktion zu testen, habe ich die AdventureWorksDW2012-Datenbank und eine Version der FactInternetSales-Tabelle mit 61.847.552 Zeilen verwendet (ich war für das Hinzufügen dieser Zeilen verantwortlich; sie werden standardmäßig nicht mit der Datenbank geliefert).
Da dieses Feature ab CTP1 den Datenbank-Kompatibilitätsgrad 110 erfordert, habe ich zu Testzwecken die Datenbank auf den Kompatibilitätsgrad 100 gesetzt und für meinen ersten Test die folgende Abfrage ausgeführt:
SELECT [ProductKey],
[OrderDateKey],
[DueDateKey],
[ShipDateKey],
[CustomerKey],
[PromotionKey],
[CurrencyKey],
[SalesTerritoryKey],
[SalesOrderNumber],
[SalesOrderLineNumber],
[RevisionNumber],
[OrderQuantity],
[UnitPrice],
[ExtendedAmount],
[UnitPriceDiscountPct],
[DiscountAmount],
[ProductStandardCost],
[TotalProductCost],
[SalesAmount],
[TaxAmt],
[Freight],
[CarrierTrackingNumber],
[CustomerPONumber],
[OrderDate],
[DueDate],
[ShipDate]
INTO dbo.FactInternetSales_V2
FROM dbo.FactInternetSales; Die Dauer der Abfrageausführung betrug auf meiner Test-VM 3 Minuten und 19 Sekunden, und der tatsächlich erstellte Abfrageausführungsplan lautete wie folgt:

SQL Server verwendete erwartungsgemäß einen seriellen Plan. Beachten Sie auch, dass meine Tabelle einen nicht gruppierten Columnstore-Index enthielt, der gescannt wurde (ich habe diesen nicht gruppierten Columnstore-Index zur Verwendung mit anderen Tests erstellt, aber ich werde Ihnen später auch den Abfrageausführungsplan für den gruppierten Columnstore-Index zeigen). Der Plan verwendete keine Parallelität und der Columnstore Index Scan verwendete den Zeilenausführungsmodus anstelle des Stapelausführungsmodus.
Also habe ich als Nächstes den Kompatibilitätsgrad der Datenbank geändert (und beachten Sie, dass es in CTP1 noch keinen Kompatibilitätsgrad für SQL Server 2014 gibt):
USE [master]; GO ALTER DATABASE [AdventureWorksDW2012] SET COMPATIBILITY_LEVEL = 110; GO
Ich habe die Tabelle FactInternetSales_V2 gelöscht und dann mein ursprüngliches SELECT ... INTO erneut ausgeführt Betrieb. Diesmal betrug die Dauer der Abfrageausführung 1 Minute und 7 Sekunden und der tatsächliche Abfrageausführungsplan lautete wie folgt:
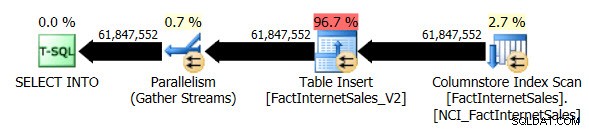
Wir haben jetzt einen parallelen Plan und die einzige Änderung, die ich vornehmen musste, war der Datenbankkompatibilitätsgrad für AdventureWorksDW2012. Meiner Test-VM sind vier vCPUs zugewiesen, und der Abfrageausführungsplan hat Zeilen auf vier Threads verteilt:

Der Nonclustered Columnstore Index Scan verwendete zwar Parallelität, aber keinen Batch-Ausführungsmodus. Stattdessen wurde der Zeilenausführungsmodus verwendet.
Hier ist eine Tabelle mit den bisherigen Testergebnissen:
| Scantyp | Kompatibilitätsstufe | Parallele AUSWAHL … IN | Ausführungsmodus | Dauer |
|---|---|---|---|---|
| Nonclustered Columnstore Index Scan | 100 | Nein | Zeile | 3:19 |
| Nonclustered Columnstore Index Scan | 110 | Ja | Zeile | 1:07 |
Als nächsten Test habe ich den nicht gruppierten Columnstore-Index gelöscht und SELECT ... INTO erneut ausgeführt Abfrage mit Datenbank-Kompatibilitätsgrad 100 und 110.
Die Ausführung des Kompatibilitätslevel-100-Tests dauerte 5 Minuten und 44 Sekunden, und der folgende Plan wurde erstellt:
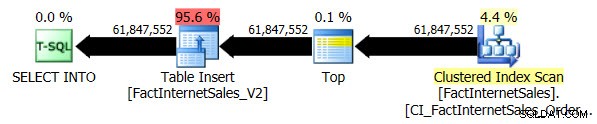
Der serielle Clustered Index Scan dauerte 2 Minuten und 25 Sekunden länger als der serielle Nonclustered Columnstore Index Scan.
Bei Verwendung des Kompatibilitätsgrads 110 dauerte die Ausführung der Abfrage 1 Minute und 55 Sekunden, und der folgende Plan wurde generiert:

Ähnlich wie beim parallelen Nonclustered-Columnstore-Index-Scan-Test verteilte der parallele Clustered-Index-Scan Zeilen auf vier Threads:
Die folgende Tabelle fasst diese beiden oben genannten Tests zusammen:
| Scantyp | Kompatibilitätsstufe | Parallele AUSWAHL … IN | Ausführungsmodus | Dauer |
|---|---|---|---|---|
| Clustered-Index-Scan | 100 | Nein | Zeile (N/A) | 5:44 |
| Clustered-Index-Scan | 110 | Ja | Zeile (N/A) | 1:55 |
Also habe ich mich über die Leistung eines gruppierten Columnstore-Index (neu in SQL Server 2014) gewundert, also habe ich die vorhandenen Indizes gelöscht und einen gruppierten Columnstore-Index für die Tabelle FactInternetSales erstellt. Außerdem musste ich die acht verschiedenen Fremdschlüsseleinschränkungen löschen, die für die Tabelle definiert waren, bevor ich den gruppierten Columnstore-Index erstellen konnte.
Die Diskussion wird etwas akademisch, da ich SELECT ... INTO vergleiche Leistung bei Datenbankkompatibilitätsstufen, die überhaupt keine gruppierten Columnstore-Indizes boten – und die früheren Tests für nicht gruppierte Columnstore-Indizes bei Datenbankkompatibilitätsstufe 100 auch nicht – und dennoch ist es interessant, die Gesamtleistungsmerkmale zu sehen und zu vergleichen.
CREATE CLUSTERED COLUMNSTORE INDEX [CCSI_FactInternetSales] ON [dbo].[FactInternetSales] WITH (DROP_EXISTING = OFF); GO
Abgesehen davon dauerte die Operation zum Erstellen des gruppierten Columnstore-Index auf einer Tabelle mit 61.847.552 Millionen Zeilen 11 Minuten und 25 Sekunden mit vier verfügbaren vCPUs (von denen die Operation alle nutzte), 4 GB RAM und virtuellem Gastspeicher auf OCZ Vertex SSDs. Während dieser Zeit waren die CPUs nicht die ganze Zeit gekoppelt, sondern zeigten Spitzen und Täler (eine Stichprobe von 60 Sekunden CPU-Aktivität wird unten gezeigt):
Nachdem der gruppierte Columnstore-Index erstellt wurde, habe ich die beiden SELECT ... INTO erneut ausgeführt Prüfungen. Die Ausführung des Kompatibilitätsgrad-100-Tests dauerte 3 Minuten und 22 Sekunden, und der Plan war erwartungsgemäß seriell (ich zeige die SQL Server Management Studio-Version des Plans seit dem gruppierten Columnstore-Index-Scan ab SQL Server 2014 CTP1 , wird von Plan Explorer noch nicht vollständig erkannt):

Als nächstes änderte ich den Kompatibilitätsgrad der Datenbank auf 110 und führte den Test erneut aus, wobei die Abfrage dieses Mal 1 Minute und 11 Sekunden dauerte und den folgenden tatsächlichen Ausführungsplan hatte:

Der Plan verteilte Zeilen auf vier Threads, und genau wie beim nicht gruppierten Columnstore-Index war der Ausführungsmodus des gruppierten Columnstore-Index-Scans Zeilen- und nicht Stapelverarbeitung.
Die folgende Tabelle fasst alle Tests in diesem Beitrag zusammen (in der Reihenfolge ihrer Dauer, niedrig bis hoch):
| Scantyp | Kompatibilitätsstufe | Parallele AUSWAHL … IN | Ausführungsmodus | Dauer |
|---|---|---|---|---|
| Nonclustered Columnstore Index Scan | 110 | Ja | Zeile | 1:07 |
| Clustered Columnstore Index Scan | 110 | Ja | Zeile | 1:11 |
| Clustered-Index-Scan | 110 | Ja | Zeile (N/A) | 1:55 |
| Nonclustered Columnstore Index Scan | 100 | Nein | Zeile | 3:19 |
| Clustered Columnstore Index Scan | 100 | Nein | Zeile | 3:22 |
| Clustered-Index-Scan | 100 | Nein | Zeile (N/A) | 5:44 |
Ein paar Beobachtungen:
- Ich bin mir nicht sicher, ob der Unterschied zwischen einem parallelen
SELECT ... INTODer Vorgang für einen nicht gruppierten Columnstore-Index im Vergleich zu einem gruppierten Columnstore-Index ist statistisch signifikant. Ich müsste noch mehr Tests machen, aber ich denke, ich würde damit warten bis RTM. - Ich kann mit Sicherheit sagen, dass das parallele
SELECT ... INTOhat die seriellen Äquivalente in einem Clustered-Index-, Nonclustered-Columnstore- und Clustered-Columnstore-Index-Test deutlich übertroffen.
Es ist erwähnenswert, dass diese Ergebnisse für eine CTP-Version des Produkts gelten und meine Tests als etwas angesehen werden sollten, das das Verhalten von RTM verändern könnte – daher interessierte mich weniger die Standalone-Dauer als der Vergleich dieser Dauer zwischen seriell und parallel Bedingungen.
Einige Leistungsmerkmale erfordern ein erhebliches Refactoring – aber für SELECT ... INTO Verbesserung, alles, was ich tun musste, war, den Kompatibilitätsgrad der Datenbank zu erhöhen, um die Vorteile zu sehen, was ich definitiv zu schätzen weiß.