Das Analysieren von Daten aus XML mit XQuery ist eine Routinepraxis. Um dies am effektivsten zu tun, ist nur wenig Aufwand erforderlich.
Angenommen, wir müssen Daten aus der Festplattendatei mit der folgenden Struktur parsen:
<tables> <table name="Accounting" schema="Production" object="Accounting"> <column name="Date" order="3" visible="1" /> <column name="DateFrom" order="5" visible="1" /> <column name="DateTo" order="6" visible="1" /> <column name="Description" order="4" visible="1" /> <column name="DocumentUID" order="1" visible="0" /> <column name="Number" order="2" visible="1" /> <column name="Warehouse" order="7" visible="1" /> </table> </tables>
Verwenden Sie BULK INSERT, wenn Sie Daten aus einer Datei lesen müssen:
SELECT BulkColumn FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x sample xml file
Eine Beispiel-XML-Datei finden Sie hier.
Beachten Sie jedoch eine bestimmte Sache… Versuchen Sie, die Daten nicht direkt auszulesen:
;WITH cte AS
(
SELECT x = CAST(BulkColumn AS XML)
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
)
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM cte
CROSS APPLY x.nodes('tables/table') t(c) Daten einer Variablen zuweisen. Auf diese Weise erhalten Sie einen effizienteren Ausführungsplan:
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM @xml.nodes('tables/table') t(c) Vergleichen Sie die Ergebnisse:
Table 'Worktable'. Scan count 0, logical reads 729, physical reads 0, read-ahead reads 0, lob logical reads 62655,... SQL Server Execution Times: CPU time = 1203 ms, elapsed time = 1214 ms. Table 'Worktable'. Scan count 0, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 202,.... SQL Server Execution Times: CPU time = 16 ms, elapsed time = 4 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
Wie Sie sehen können, ist die zweite Option wesentlich schneller.
Ein weiteres wichtiges Feature von SQL Server bei der Arbeit mit XQuery ist, dass das Lesen eines übergeordneten Elements zu schlechter Leistung führen kann. Betrachten Sie das folgende Beispiel:
SET STATISTICS PROFILE OFF
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SET STATISTICS PROFILE ON
SELECT
t.c.value('@name', 'SYSNAME')
, t.c.value('@order', 'INT')
, t.c.value('@visible', 'BIT')
, t.c.value('../@name', 'SYSNAME')
, t.c.value('../@schema', 'SYSNAME')
, t.c.value('../@object', 'SYSNAME')
FROM @xml.nodes('tables/table/*') t(c) Schauen wir uns die tatsächliche Anzahl der vom Operator empfangenen Zeilen an. Der Wert ist ungewöhnlich groß:
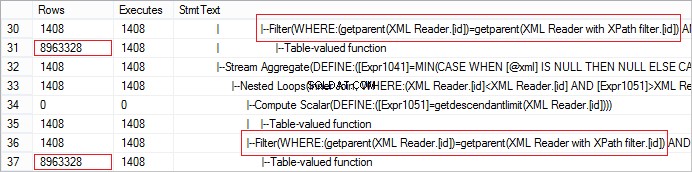
Mit CROSS APPLY kann die Anfrage einfach optimiert werden:
SELECT
t2.c2.value('@name', 'SYSNAME')
, t2.c2.value('@order', 'INT')
, t2.c2.value('@visible', 'BIT')
, t.c.value('@name', 'SYSNAME')
, t.c.value('@schema', 'SYSNAME')
, t.c.value('@object', 'SYSNAME')
FROM @xml.nodes('tables/table') t(c)
CROSS APPLY t.c.nodes('column') t2(c2) Vergleichen wir die Ausführungszeit:
(1408 row(s) affected) SQL Server Execution Times: CPU time = 10125 ms, elapsed time = 10135 ms. (1408 row(s) affected) SQL Server Execution Times: CPU time = 78 ms, elapsed time = 156 ms.
Wie Sie dem Beispiel entnehmen können, funktioniert die Anfrage mit CROSS APPLY auf Anhieb.
Danke für Ihre Aufmerksamkeit. Ich hoffe, dieser Artikel war nützlich. Fühlen Sie sich frei, Fragen zu stellen, Kommentare und Vorschläge zu diesem Artikel zu hinterlassen.