Benjamin Nevarez ist ein unabhängiger Berater mit Sitz in Los Angeles, Kalifornien, der sich auf die Optimierung und Optimierung von SQL Server-Abfragen spezialisiert hat. Er ist Autor von „SQL Server 2014 Query Tuning &Optimization“ und „Inside the SQL Server Query Optimizer“ und Co-Autor von „SQL Server 2012 Internals“. Mit mehr als 20 Jahren Erfahrung in relationalen Datenbanken war Benjamin auch Redner auf vielen SQL Server-Konferenzen, darunter PASS Summit, SQL Server Connections und SQLBits. Benjamins Blog ist unter https://www.benjaminnevarez.com zu finden und er kann auch per E-Mail unter admin at benjaminnevarez dot com und auf Twitter unter @BenjaminNevarez erreicht werden.
Haben Sie jemals eine Planregression nach einem SQL Server-Upgrade gefunden und wollten wissen, wie der vorherige Ausführungsplan war? Hatten Sie jemals ein Problem mit der Abfrageleistung, weil eine Abfrage unerwartet einen neuen Ausführungsplan erhielt? Auf dem letzten PASS Summit hat Conor Cunningham eine neue SQL Server-Funktion entdeckt, die bei der Lösung von Leistungsproblemen im Zusammenhang mit diesen und anderen Änderungen in Ausführungsplänen hilfreich sein kann.
Dieses als Abfragespeicher bezeichnete Feature kann Ihnen bei Leistungsproblemen im Zusammenhang mit Planänderungen helfen und wird in Kürze in SQL Azure und später in der nächsten Version von SQL Server verfügbar sein. Obwohl erwartet wird, dass es in der Enterprise Edition von SQL Server verfügbar ist, ist noch nicht bekannt, ob es in Standard oder anderen Editionen verfügbar sein wird. Um die Vorteile des Abfragespeichers zu verstehen, möchte ich kurz auf den Fehlerbehebungsprozess bei Abfragen eingehen.
Warum ist eine Abfrage langsam?
Sobald Sie festgestellt haben, dass ein Leistungsproblem auf eine langsame Abfrage zurückzuführen ist, besteht der nächste Schritt darin, den Grund dafür herauszufinden. Natürlich hängt nicht jedes Problem mit Planänderungen zusammen. Es kann mehrere Gründe geben, warum eine Abfrage, die eine gute Leistung erbracht hat, plötzlich langsam ist. Manchmal kann dies mit Blockierungen oder einem Problem mit anderen Systemressourcen zusammenhängen. Möglicherweise hat sich noch etwas anderes geändert, aber die Herausforderung besteht möglicherweise darin, herauszufinden, was. Oft haben wir keine Basisdaten über die Nutzung von Systemressourcen, Statistiken zur Abfrageausführung oder den Leistungsverlauf. Und normalerweise haben wir keine Ahnung, was der alte Plan war. Es kann vorkommen, dass einige Änderungen, z. B. Daten, Schemas oder Abfrageparameter, dazu geführt haben, dass der Abfrageprozessor einen neuen Plan erstellt hat.
Planänderungen
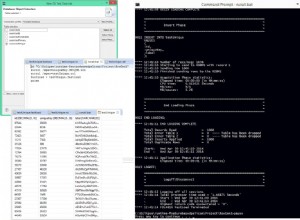
Bei der Sitzung verwendete Conor das Picasso Database Query Optimizer Visualizer-Tool, obwohl er es nicht namentlich erwähnte, um zu zeigen, warum sich die Pläne in derselben Abfrage geändert haben, und erklärte die Tatsache, dass verschiedene Pläne für dieselbe Abfrage basierend auf ausgewählt werden könnten die Selektivität ihrer Prädikate. Er erwähnte sogar, dass das Abfrageoptimierungsteam dieses Tool verwendet, das vom Indian Institute of Science entwickelt wurde. Ein Beispiel der Visualisierung (zum Vergrößern anklicken):
 Picasso Database Query Optimizer Visualizer
Picasso Database Query Optimizer Visualizer
Jede Farbe im Diagramm ist ein anderer Plan, und jeder Plan wird basierend auf der Selektivität der Prädikate ausgewählt. Eine wichtige Tatsache ist, dass beim Überschreiten einer Grenze im Diagramm und Auswählen eines anderen Plans die Kosten und die Leistung beider Pläne in den meisten Fällen ähnlich sein sollten, da sich die Selektivität oder die geschätzte Anzahl von Zeilen nur geringfügig geändert hat. Dies könnte beispielsweise passieren, wenn einer Tabelle eine neue Zeile hinzugefügt wird, die für das verwendete Prädikat geeignet ist. In einigen Fällen jedoch, hauptsächlich aufgrund von Einschränkungen im Kostenmodell des Abfrageoptimierers, in denen etwas nicht korrekt modelliert werden kann, kann der neue Plan einen großen Leistungsunterschied im Vergleich zum vorherigen Plan aufweisen, wodurch ein Problem für Ihre Anwendung entsteht. Übrigens sind die im Diagramm gezeigten Pläne die endgültigen Pläne, die vom Abfrageoptimierer ausgewählt wurden. Verwechseln Sie dies nicht mit den vielen Alternativen, die der Optimierer in Betracht ziehen muss, um nur eine auszuwählen.
Eine meiner Meinung nach wichtige Tatsache, die Conor nicht direkt behandelt hat, war die Planänderung aufgrund von Regressionen nach Änderungen an kumulativen Updates (CUs), Service Packs oder Versions-Upgrades. Ein wichtiges Problem, das bei Änderungen im Abfrageoptimierer in den Sinn kommt, sind Planregressionen. Die Angst vor Planregressionen wurde als das größte Hindernis für Verbesserungen des Abfrageoptimierers angesehen. Regressionen sind Probleme, die auftreten, nachdem eine Korrektur auf den Abfrageoptimierer angewendet wurde, und manchmal als das klassische „zwei oder mehr Falsche ergeben ein Richtiges“ bezeichnet werden. Das kann zum Beispiel passieren, wenn sich zwei schlechte Schätzungen, von denen die eine einen Wert überschätzt und die zweite unterschätzt, gegenseitig aufheben und glücklicherweise eine gute Schätzung ergeben. Das Korrigieren nur eines dieser Werte kann nun zu einer schlechten Schätzung führen, was sich negativ auf die Wahl der Planauswahl auswirken und eine Regression verursachen kann.
Was macht der Abfragespeicher?
Conor erwähnte, dass der Abfragespeicher Folgendes leistet und helfen kann:
- Speichern Sie den Verlauf der Abfragepläne im System;
- Erfassen Sie die Leistung jedes Abfrageplans im Laufe der Zeit;
- Suchanfragen identifizieren, die „in letzter Zeit langsamer geworden sind“;
- Sie können Pläne schnell erzwingen; und,
- Stellen Sie sicher, dass dies bei Serverneustarts, Upgrades und Neukompilierungen von Abfragen funktioniert.
Diese Funktion speichert also nicht nur die Pläne und zugehörigen Informationen zur Abfrageleistung, sondern kann Ihnen auch dabei helfen, einen alten Abfrageplan einfach zu erzwingen, was in vielen Fällen ein Leistungsproblem lösen kann.
Verwendung des Abfragespeichers
Sie müssen den Abfragespeicher aktivieren, indem Sie ALTER DATABASE CURRENT SET QUERY_STORE = ON; verwenden Erklärung. Ich habe es in meinem aktuellen SQL Azure-Abonnement ausprobiert, aber die Anweisung hat einen Fehler zurückgegeben, da die Funktion anscheinend noch nicht verfügbar ist. Ich habe Conor kontaktiert und er hat mir gesagt, dass die Funktion bald verfügbar sein wird.
Sobald der Abfragespeicher aktiviert ist, beginnt er mit dem Sammeln der Pläne und der Abfrageleistungsdaten, und Sie können diese Daten analysieren, indem Sie sich die Tabellen des Abfragespeichers ansehen. Ich kann diese Tabellen derzeit in SQL Azure sehen, aber da ich den Abfragespeicher nicht aktivieren konnte, haben die Kataloge keine Daten zurückgegeben.
Sie können die gesammelten Informationen entweder proaktiv analysieren, um die Änderungen der Abfrageleistung in Ihrer Anwendung zu verstehen, oder rückwirkend, falls Sie ein Leistungsproblem haben. Sobald Sie das Problem identifiziert haben, können Sie versuchen, das Problem mit herkömmlichen Techniken zur Abfrageoptimierung zu beheben, oder Sie können den sp_query_store_force_plan verwenden gespeicherte Prozedur, um einen vorherigen Plan zu erzwingen. Der Plan muss im Abfragespeicher erfasst werden, um erzwungen zu werden, was offensichtlich bedeutet, dass es sich um einen gültigen Plan handelt (zumindest zum Zeitpunkt der Erfassung; dazu später mehr) und zuvor vom Abfrageoptimierer generiert wurde. Um einen Plan zu erzwingen, benötigen Sie die plan_id , verfügbar im sys.query_store_plan Katalog. Sehen Sie sich einmal die verschiedenen gespeicherten Metriken an, die denen sehr ähnlich sind, die zum Beispiel in sys.dm_exec_query_stats gespeichert sind , können Sie die Entscheidung treffen, für eine bestimmte Metrik wie CPU, E/A usw. zu optimieren. Dann können Sie einfach eine Anweisung wie diese verwenden:
EXEC sys.sp_query_store_force_plan @query_id = 1, @plan_id = 1;
Dies weist SQL Server an, Plan 1 für Abfrage 1 zu erzwingen. Technisch gesehen könnten Sie dasselbe mit einer Planhinweisliste tun, aber es wäre komplizierter und Sie müssten den erforderlichen Plan zunächst manuell erfassen und finden.
Wie funktioniert der Abfragespeicher?
Um einen Plan tatsächlich zu erzwingen, werden im Hintergrund Planhilfslinien verwendet. Conor erwähnte, dass „wenn Sie eine Abfrage kompilieren, fügen wir implizit einen USE PLAN-Hinweis mit dem Fragment des XML-Plans hinzu, der dieser Anweisung zugeordnet ist.“ Sie müssen also keine Planhilfe mehr verwenden. Denken Sie auch daran, dass es genau wie bei der Verwendung einer Plananleitung nicht garantiert ist, genau den erzwungenen Plan zu haben, aber zumindest etwas Ähnliches. Eine Erinnerung an die Funktionsweise von Planleitfäden finden Sie in diesem Artikel. Darüber hinaus sollten Sie sich darüber im Klaren sein, dass das Erzwingen eines Plans in einigen Fällen nicht funktioniert. Ein typisches Beispiel ist, wenn sich das Schema geändert hat, d. h. wenn ein gespeicherter Plan einen Index verwendet, der Index jedoch nicht mehr vorhanden ist. In diesem Fall kann SQL Server den Plan nicht erzwingen, führt eine normale Optimierung durch und zeichnet die Tatsache auf, dass das Erzwingen des Plans in sys.query_store_plan fehlgeschlagen ist Katalog.
Architektur
Jedes Mal, wenn SQL Server eine Abfrage kompiliert oder ausführt, wird eine Nachricht an den Abfragespeicher gesendet. Dies wird als nächstes angezeigt.
 Übersicht zum Abfragespeicher-Workflow
Übersicht zum Abfragespeicher-Workflow
Die Kompilier- und Ausführungsinformationen werden zunächst im Arbeitsspeicher gehalten und dann je nach Konfiguration des Abfragespeichers auf der Festplatte gespeichert (die Daten werden gemäß INTERVAL_LENGTH_MINUTES aggregiert Parameter, der standardmäßig auf eine Stunde eingestellt ist, und gemäß DATA_FLUSH_INTERVAL_SECONDS auf die Festplatte geschrieben Parameter). Die Daten können auch auf die Festplatte geschrieben werden, wenn im System Speichermangel herrscht. In jedem Fall können Sie auf alle Daten zugreifen, sowohl im Arbeitsspeicher als auch auf der Festplatte, wenn Sie sys.query_store_runtime_stats ausführen Katalog.
Kataloge
Die gesammelten Daten werden auf der Festplatte gespeichert und in der Benutzerdatenbank gespeichert, in der der Abfragespeicher aktiviert ist (und die Einstellungen in sys.database_query_store_options gespeichert sind). . Die Kataloge des Abfragespeichers sind:
sys.query_store_query_text | Textinformationen abfragen |
sys.query_store_query | Abfragetext plus verwendeter Plan, der sich auf SET-Optionen auswirkt |
sys.query_store_plan | Ausführungspläne, einschließlich Verlauf |
sys.query_store_runtime_stats | Laufzeitstatistiken abfragen |
sys.query_store_runtime_stats_interval | Start- und Endzeit für Intervalle |
sys.query_context_settings | Kontexteinstellungen abfragen |
Speicheransichten abfragen
Laufzeitstatistiken erfassen eine ganze Reihe von Metriken, einschließlich Durchschnitt, letzte, minimale, maximale und Standardabweichung. Hier ist der vollständige Satz von Spalten für sys.query_store_runtime_stats :
runtime_stats_id | plan_id | runtime_stats_interval_id | ||
execution_type | execution_type_desc | first_execution_time | last_execution_time | count_executions |
avg_duration | last_duration | min_duration | max_duration | stdev_duration |
avg_cpu_time | last_cpu_time | min_cpu_time | max_cpu_time | stdev_cpu_time |
avg_logical_io_reads | last_logical_io_reads | min_logical_io_reads | max_logical_io_reads | stdev_logical_io_reads |
avg_logical_io_writes | last_logical_io_writes | min_logical_io_writes | max_logical_io_writes | stdev_logical_io_writes |
avg_physical_io_reads | last_physical_io_reads | min_physical_io_reads | max_physical_io_reads | stdev_physical_io_reads |
avg_clr_time | last_clr_time | min_clr_time | max_clr_time | stdev_clr_time |
avg_dop | last_dop | min_dop | max_dop | stdev_dop |
avg_query_max_used_memory | last_query_max_used_memory | min_query_max_used_memory | max_query_max_used_memory | stdev_query_max_used_memory |
avg_rowcount | last_rowcount | min_rowcount | max_rowcount | stdev_rowcount |
Spalten in sys.query_store_runtime_stats
Diese Daten werden nur erfasst, wenn die Abfrageausführung beendet ist. Der Abfragespeicher berücksichtigt auch den SET der Abfrage Optionen, die sich auf die Wahl eines Ausführungsplans auswirken können, da sie Dinge wie die Ergebnisse der Auswertung konstanter Ausdrücke während des Optimierungsprozesses beeinflussen. Ich habe dieses Thema in einem früheren Beitrag behandelt.
Schlussfolgerung
Dies wird definitiv ein großartiges Feature sein und etwas, das ich so schnell wie möglich ausprobieren möchte (übrigens zeigt Conors Demo „SQL Server 15 CTP1“, aber diese Bits sind nicht öffentlich verfügbar). Der Abfragespeicher kann für Upgrades nützlich sein, bei denen es sich um eine CU-, Service Pack- oder SQL Server-Version handeln kann, da Sie die vom Abfragespeicher gesammelten Informationen vorher und nachher analysieren können, um festzustellen, ob eine Abfrage zurückgegangen ist. (Und wenn die Funktion in niedrigeren Editionen verfügbar ist, könnten Sie dies sogar in einem SKU-Upgrade-Szenario tun.) Wenn Sie dies wissen, können Sie je nach Problem bestimmte Maßnahmen ergreifen, und eine dieser Lösungen könnte darin bestehen, den vorherigen Plan zu erzwingen wie zuvor erklärt.