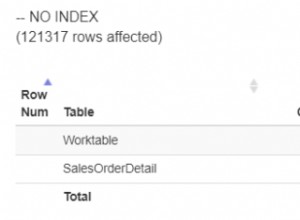
Soweit es grafische Ausführungspläne betrifft, gibt es in SQL Server nur ein Symbol für eine physische Sortierung:

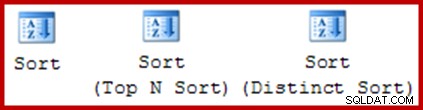
Dasselbe Symbol wird für die drei logischen Sortieroperatoren verwendet:Sort, Top N Sort und Distinct Sort:
Um eine Ebene tiefer zu gehen, gibt es vier verschiedene Implementierungen von Sort in der Ausführungs-Engine (ohne die Batch-Sortierung für optimierte Loop-Joins zu zählen, die keine vollständige Sortierung ist und sowieso nicht in Plänen sichtbar ist). Wenn Sie SQL Server 2014 verwenden, erhöht sich die Anzahl der Sort-Implementierungen der Ausführungs-Engine auf sieben:
- CQScanSortNeu
- CQScanTopSortNew
- CQScanIndexSortNeu
- CQScanPartitionSortNew (nur SQL Server 2014)
- CQScanInMemSortNeu
- In-Memory OLTP (Hekaton) nativ kompilierte Prozedur Top N Sort (nur SQL Server 2014)
- In-Memory OLTP (Hekaton) nativ kompilierte Prozedur General Sort (nur SQL Server 2014)
Dieser Artikel befasst sich mit diesen Sortierimplementierungen und wann sie in SQL Server verwendet werden. Teil eins behandelt die ersten vier Punkte auf der Liste.
1. CQScanSortNew
Dies ist die allgemeinste Sortierklasse, die verwendet wird, wenn keine der anderen verfügbaren Optionen anwendbar ist. Die allgemeine Sortierung verwendet eine Arbeitsbereichsspeicherzuweisung, die unmittelbar vor Beginn der Abfrageausführung reserviert wird. Diese Gewährung ist proportional zu Kardinalitätsschätzungen und Erwartungen an die durchschnittliche Zeilengröße und kann nicht erhöht werden nach Beginn der Abfrageausführung.
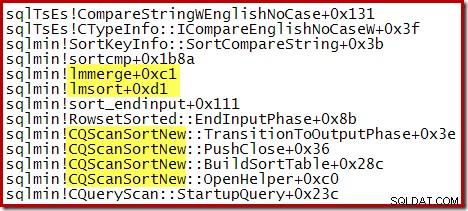
Die aktuelle Implementierung scheint eine Vielzahl von internen Merge-Sortierungen (möglicherweise binäre Merge-Sortierungen) zu verwenden und zu externer Merge-Sortierung (mit mehreren Durchgängen, falls erforderlich) überzugehen, wenn sich herausstellt, dass der reservierte Speicher nicht ausreicht. Externe Zusammenführungssortierung verwendet physische tempdb Speicherplatz für Sortierläufe, die nicht in den Speicher passen (allgemein bekannt als Sortierüberlauf). Die allgemeine Sortierung kann auch so konfiguriert werden, dass während des Sortiervorgangs Unterscheidbarkeit angewendet wird.
Der folgende Teil-Stack-Trace zeigt ein Beispiel für CQScanSortNew Klasse, die Strings mit einer internen Merge-Sortierung sortiert:
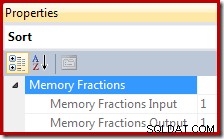
In Ausführungsplänen stellt Sort Informationen über den Bruchteil der gesamten Arbeitsspeicherzuweisung des Abfragearbeitsbereichs bereit, der für Sort beim Lesen von Datensätzen verfügbar ist (die Eingabephase), und den Bruchteil, der verfügbar ist, wenn die sortierte Ausgabe von Operatoren des übergeordneten Plans verbraucht wird (die Ausgabephase). ).
Der Speicherzuteilungsanteil ist eine Zahl zwischen 0 und 1 (wobei 1 =100 % des zugeteilten Speichers) und in SSMS sichtbar ist, indem Sie die Sortierung hervorheben und im Eigenschaftenfenster nachsehen. Das folgende Beispiel wurde aus einer Abfrage mit nur einem einzigen Sort-Operator entnommen, sodass sowohl während der Eingabe- als auch der Ausgabephase der volle Arbeitsspeicher des Abfrage-Workspace verfügbar ist:
Die Speicheranteile spiegeln die Tatsache wider, dass Sort während seiner Eingabephase die gesamte Abfragespeicherzuweisung mit gleichzeitig ausgeführten speicherverbrauchenden Operatoren unterhalb davon im Ausführungsplan teilen muss. In ähnlicher Weise muss Sort während der Ausgabephase den gewährten Speicher mit gleichzeitig ausführenden speicherverbrauchenden Operatoren darüber im Ausführungsplan teilen.
Der Abfrageprozessor ist intelligent genug, um zu wissen, dass einige Operatoren blockieren (Stop-and-Go) und effektiv Grenzen markieren, an denen die Speicherzuteilung recycelt und wiederverwendet werden kann. In parallelen Plänen wird der für eine allgemeine Sortierung verfügbare Speicherzuteilungsanteil gleichmäßig auf die Threads aufgeteilt und kann zur Laufzeit im Falle einer Verzerrung nicht neu ausgeglichen werden (eine häufige Ursache für Überläufe in parallelen Sortierplänen).
SQL Server 2012 und höher enthält zusätzliche Informationen über die minimale Arbeitsspeicherzuweisung für den Arbeitsbereich, die zum Initialisieren von speicherverbrauchenden Planoperatoren erforderlich ist, und über die erwünschten Speicherbewilligung (die "ideale" Menge an Speicher, die geschätzt wird, um die gesamte Operation im Speicher abzuschließen). In einem Ausführungsplan nach der Ausführung ("tatsächlich") gibt es auch neue Informationen über Verzögerungen beim Abrufen der Speicherzuteilung, die maximal tatsächlich verwendete Speichermenge und wie die Speicherreservierung auf NUMA-Knoten verteilt wurde.
Die folgenden AdventureWorks-Beispiele verwenden alle ein CQScanSortNew Allgemeine Sortierung:
-- An Ordinary Sort (CQScanSortNew)
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Distinct Sort (also CQScanSortNew)
SELECT DISTINCT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Same query expressed using GROUP BY
-- Same Distinct Sort (CQScanSortNew) execution plan
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
GROUP BY
P.FirstName,
P.MiddleName,
P.LastName
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Die erste Abfrage (eine nicht eindeutige Sortierung) erzeugt den folgenden Ausführungsplan:
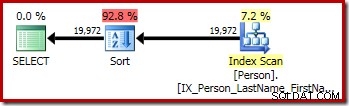
Die zweite und dritte (äquivalente) Abfrage erzeugen diesen Plan:
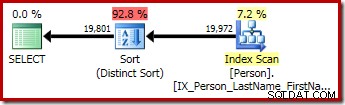
CQScanSortNew kann sowohl für die logische allgemeine Sortierung als auch für die logische eindeutige Sortierung verwendet werden.
2. CQScanTopSortNew
CQScanTopSortNew ist eine Unterklasse von CQScanSortNew Wird verwendet, um eine Top-N-Sortierung zu implementieren (wie der Name schon sagt). CQScanTopSortNew delegiert einen Großteil der Kernarbeit an CQScanSortNew , ändert aber das detaillierte Verhalten auf unterschiedliche Weise, abhängig vom Wert von N.
Für N> 100 CQScanTopSortNew ist im Wesentlichen nur ein normales CQScanSortNew sort, das automatisch aufhört, sortierte Zeilen nach N Zeilen zu produzieren. Für N <=100, CQScanTopSortNew behält nur die aktuellen Top-N-Ergebnisse während des Sortiervorgangs bei und verfolgt den niedrigsten Schlüsselwert, der derzeit qualifiziert ist.
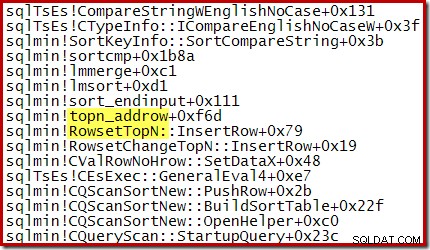
Beispielsweise weist der Call-Stack während einer optimierten Top-N-Sortierung (wobei N <=100) RowsetTopN auf wohingegen wir bei der allgemeinen Sortierung in Abschnitt 1 RowsetSorted gesehen haben :
Für eine Top-N-Sortierung, bei der N> 100 ist, ist der Aufrufstapel in der gleichen Ausführungsphase derselbe wie bei der zuvor gesehenen allgemeinen Sortierung:
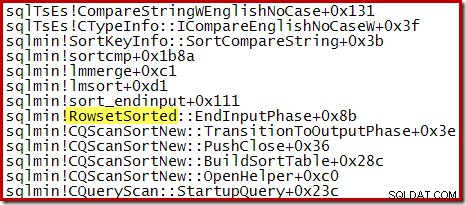
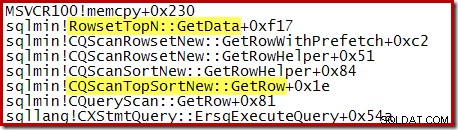
Beachten Sie, dass CQScanTopSortNew Der Klassenname wird in keinem dieser Stacktraces angezeigt. Das liegt einfach an der Funktionsweise der Unterklassifizierung. An anderen Stellen während der Ausführung dieser Abfragen wird CQScanTopSortNew Methoden (z. B. Open, GetRow und CreateTopNTable) erscheinen explizit in der Aufrufliste. Als Beispiel wurde das Folgende zu einem späteren Zeitpunkt in der Abfrageausführung genommen und zeigt CQScanTopSortNew Klassenname:
Top N Sort und der Abfrageoptimierer
Der Abfrageoptimierer weiß nichts über Top N Sort, das nur ein Ausführungsmaschinenoperator ist. Wenn der Optimierer einen Ausgabebaum mit einem physischen Top-Operator unmittelbar über einem (nicht eindeutigen) physischen Sort erzeugt, kann ein Umschreiben nach der Optimierung die beiden physischen Operationen zu einem einzigen Top-N-Sort-Operator zusammenfassen. Selbst im Fall von N> 100 bedeutet dies eine Einsparung gegenüber dem iterativen Übergeben von Zeilen zwischen einer Sort-Ausgabe und einer Top-Eingabe.
Die folgende Abfrage verwendet ein paar undokumentierte Trace-Flags, um die Ausgabe des Optimierers und das Umschreiben nach der Optimierung in Aktion zu zeigen:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName
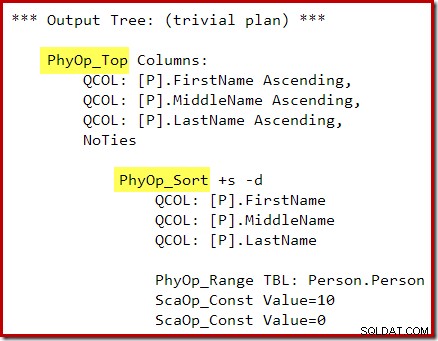
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 7352); Der Ausgabebaum des Optimierers zeigt separate physikalische Top- und Sort-Operatoren:
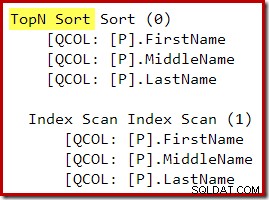
Nach der Umschreibung nach der Optimierung wurden „Top“ und „Sort“ zu einem einzigen Top-N-Sort zusammengefasst:
Der grafische Ausführungsplan für die obige T-SQL-Abfrage zeigt den einzelnen Top-N-Sort-Operator:
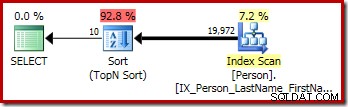
Breaking the Top N Sort Rewrite
Das Neuschreiben der Top-N-Sortierung nach der Optimierung kann nur eine benachbarte Top- und nicht unterschiedliche Sortierung in eine Top-N-Sortierung kollabieren. Das Hinzufügen von DISTINCT (oder der entsprechenden GROUP BY-Klausel) zur obigen Abfrage verhindert das Neuschreiben von Top N Sort:
SELECT DISTINCT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Der endgültige Ausführungsplan für diese Abfrage enthält separate Top- und Sort-Operatoren (Distinct Sort):
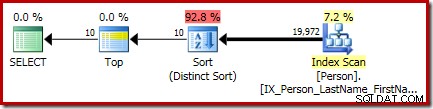
Die Sortierung dort ist die allgemeine CQScanSortNew Klasse, die im Distinct-Modus ausgeführt wird, wie in Abschnitt 1 zuvor gesehen.
Eine zweite Möglichkeit, das Umschreiben in eine Top-N-Sortierung zu verhindern, besteht darin, einen oder mehrere zusätzliche Operatoren zwischen Top und Sort einzufügen. Zum Beispiel:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName,
rn = RANK() OVER (ORDER BY P.FirstName)
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Die Ausgabe des Abfrageoptimierers hat jetzt eine Operation zwischen Top und Sort, sodass während der Umschreibungsphase nach der Optimierung keine Top-N-Sortierung generiert wird:
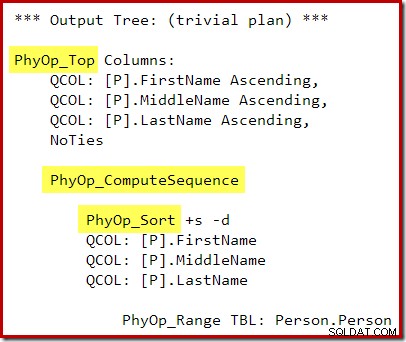
Der Ausführungsplan ist:

Die Berechnungssequenz (implementiert als zwei Segmente und ein Sequenzprojekt) zwischen Top und Sort verhindert, dass Top und Sort auf einen einzigen Top-N-Sort-Operator reduziert werden. Mit diesem Plan werden natürlich immer noch korrekte Ergebnisse erzielt, aber die Ausführung ist möglicherweise etwas weniger effizient als mit dem kombinierten Top-N-Sort-Operator.
3. CQScanIndexSortNew
CQScanIndexSortNew wird nur zum Sortieren in DDL-Indexbauplänen verwendet. Es verwendet einige der allgemeinen Sortierfunktionen, die wir bereits gesehen haben, wieder, fügt jedoch spezifische Optimierungen für Indexeinfügungen hinzu. Es ist auch die einzige Sortierklasse, die dynamisch mehr Speicher anfordern kann nachdem die Ausführung begonnen hat.
Die Kardinalitätsschätzung ist für einen Plan zur Indexerstellung häufig genau, da die Gesamtzahl der Zeilen in der Tabelle normalerweise eine bekannte Größe ist. Das soll nicht heißen, dass Speicherzuteilungen für Sortierungen von Indexerstellungsplänen immer genau sind; es macht es nur ein bisschen weniger einfach zu demonstrieren. Das folgende Beispiel verwendet also eine nicht dokumentierte, aber einigermaßen bekannte Erweiterung des UPDATE STATISTICS-Befehls, um den Optimierer zu täuschen, dass die Tabelle, für die wir einen Index erstellen, nur eine Zeile hat:
-- Test table
CREATE TABLE dbo.People
(
FirstName dbo.Name NOT NULL,
LastName dbo.Name NOT NULL
);
GO
-- Copy rows from Person.Person
INSERT dbo.People WITH (TABLOCKX)
(
FirstName,
LastName
)
SELECT
P.FirstName,
P.LastName
FROM Person.Person AS P;
GO
-- Pretend the table only has 1 row and 1 page
UPDATE STATISTICS dbo.People
WITH ROWCOUNT = 1, PAGECOUNT = 1;
GO
-- Index building plan
CREATE CLUSTERED INDEX cx
ON dbo.People (LastName, FirstName);
GO
-- Tidy up
DROP TABLE dbo.People; Der Ausführungsplan nach der Ausführung ("tatsächlich") für die Indexerstellung zeigt trotz der 1-Zeilen-Schätzung und der tatsächlich sortierten 19.972 Zeilen keine Warnung für eine verschüttete Sortierung (bei Ausführung auf SQL Server 2012 oder höher):
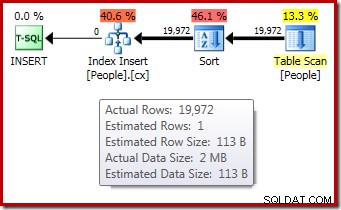
Die Bestätigung, dass die anfängliche Speicherzuweisung dynamisch erweitert wurde, ergibt sich aus einem Blick auf die Eigenschaften des Root-Iterators. Der Abfrage wurden anfangs 1024 KB Arbeitsspeicher gewährt, verbrauchte aber letztendlich 1576 KB:
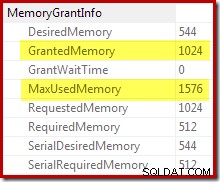
Die dynamische Erhöhung des gewährten Arbeitsspeichers kann auch mithilfe des erweiterten Ereignisses sort_memory_grant_adjustment. des Debug-Kanals nachverfolgt werden Dieses Ereignis wird jedes Mal generiert, wenn die Speicherzuweisung dynamisch erhöht wird. Wenn dieses Ereignis überwacht wird, können wir einen Stack-Trace erfassen, wenn es veröffentlicht wird, entweder über Extended Events (mit einer umständlichen Konfiguration und einem Trace-Flag) oder von einem angeschlossenen Debugger, wie unten gezeigt:
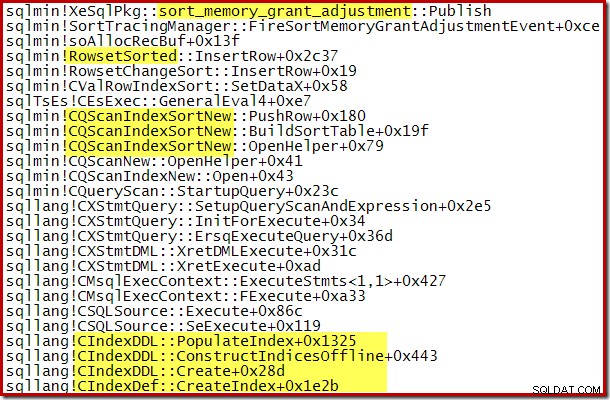
Die dynamische Speicherzuweisungserweiterung kann auch bei parallelen Indexerstellungsplänen hilfreich sein, bei denen die Verteilung von Zeilen auf Threads ungleichmäßig ist. Die Speichermenge, die auf diese Weise verbraucht werden kann, ist jedoch nicht unbegrenzt. SQL Server prüft jedes Mal, wenn eine Erweiterung erforderlich ist, um festzustellen, ob die Anforderung angesichts der zu diesem Zeitpunkt verfügbaren Ressourcen angemessen ist.
Einen Einblick in diesen Prozess erhalten Sie, indem Sie das undokumentierte Ablaufverfolgungsflag 1504 zusammen mit 3604 (für die Meldungsausgabe an die Konsole) oder 3605 (Ausgabe an das SQL Server-Fehlerprotokoll) aktivieren. Wenn der Indexerstellungsplan parallel ist, ist nur 3605 wirksam, da parallele Worker keine Trace-Meldungen Thread-übergreifend an die Konsole senden können.
Der folgende Abschnitt der Ablaufverfolgungsausgabe wurde erfasst, während ein mäßig großer Index auf einer SQL Server 2014-Instanz mit begrenztem Arbeitsspeicher erstellt wurde:
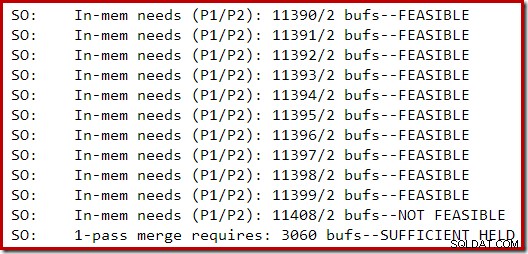
Die Speichererweiterung für die Sortierung wurde fortgesetzt, bis die Anforderung als nicht realisierbar angesehen wurde. An diesem Punkt wurde festgestellt, dass bereits genügend Speicher vorhanden war, um eine Sortierung in einem Durchgang abzuschließen.
4. CQScanPartitionSortNew
Dieser Klassenname könnte darauf hindeuten, dass diese Art der Sortierung für partitionierte Tabellendaten oder beim Erstellen von Indizes für partitionierte Tabellen verwendet wird, aber beides ist nicht der Fall. Das Sortieren partitionierter Daten verwendet CQScanSortNew oder CQScanTopSortNew wie normal; Das Sortieren von Zeilen zum Einfügen in einen partitionierten Index verwendet im Allgemeinen CQScanIndexSortNew wie in Abschnitt 3 zu sehen.
Die CQScanPartitionSortNew sort-Klasse ist nur in SQL Server 2014 vorhanden. Sie wird nur beim Sortieren von Zeilen nach Partitions-ID vor dem Einfügen in einen partitionierten gruppierten Columnstore-Index verwendet . Beachten Sie, dass es nur für partitionierte verwendet wird gruppierter Columnstore; reguläre (nicht partitionierte) geclusterte Columnstore-Einfügepläne profitieren nicht von einer Sortierung.
Einfügungen in einen partitionierten gruppierten Columnstore-Index weisen nicht immer eine Sortierung auf. Es handelt sich um eine kostenbasierte Entscheidung, die von der geschätzten Anzahl einzufügender Zeilen abhängt. Wenn der Optimierer schätzt, dass es sich lohnt, die Einfügungen nach Partition zu sortieren, um die E/A zu optimieren, hat der Columnstore-Einfügungsoperator den DMLRequestSort auf true gesetzte Eigenschaft und ein CQScanPartitionSortNew sort kann im Ausführungsplan erscheinen.
Die Demo in diesem Abschnitt verwendet eine permanente Tabelle mit fortlaufenden Nummern. Wenn Sie keines davon haben, kann das folgende Skript verwendet werden, um eines zu erstellen:
-- Itzik Ben-Gan's row generator
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM Nums AS N
WHERE N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Die Demo selbst umfasst das Erstellen einer partitionierten gruppierten Columnstore-Indextabelle und das Einfügen von genügend Zeilen (aus der Zahlentabelle oben), um den Optimierer davon zu überzeugen, eine Partitionssortierung vor dem Einfügen zu verwenden:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES (1000, 2000, 3000);
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
-- A partitioned heap
CREATE TABLE dbo.Partitioned
(
col1 integer NOT NULL,
col2 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID())),
col3 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID()))
)
ON PS (col1);
GO
-- Convert heap to partitioned clustered columnstore
CREATE CLUSTERED COLUMNSTORE INDEX ccsi
ON dbo.Partitioned
ON PS (col1);
GO
-- Add rows to the partitioned clustered columnstore table
INSERT dbo.Partitioned (col1)
SELECT N.n
FROM dbo.Numbers AS N
WHERE N.n BETWEEN 1 AND 4000; Der Ausführungsplan für die Einfügung zeigt die Sortierung, die verwendet wird, um sicherzustellen, dass Zeilen beim gruppierten Columnstore-Einfügungsiterator in der Reihenfolge der Partitions-IDs ankommen:

Eine während CQScanPartitionSortNew erfasste Aufrufliste Das Sortieren war im Gange, wird unten angezeigt:
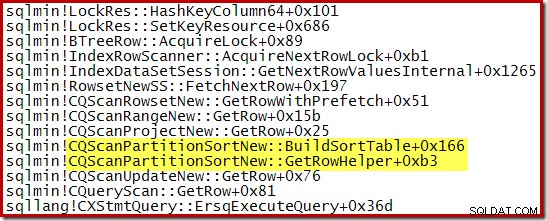
Es gibt noch etwas Interessantes an dieser Art-Klasse. Sortierungen verbrauchen normalerweise ihre gesamte Eingabe in ihrem Open-Methodenaufruf. Nach dem Sortieren geben sie die Kontrolle an ihren Mutterbetreiber zurück. Später beginnt die Sortierung sortierte Ausgabezeilen nacheinander auf die übliche Weise über GetRow-Aufrufe zu erzeugen. CQScanPartitionSortNew ist anders, wie Sie in der Aufrufliste oben sehen können:Es verbraucht seine Eingabe nicht während seiner Open-Methode – es wartet, bis GetRow zum ersten Mal von seinem Elternelement aufgerufen wird.
Nicht jede Sortierung nach Partitions-ID, die in einem Ausführungsplan erscheint, der Zeilen in einen partitionierten gruppierten Columnstore-Index einfügt, ist ein CQScanPartitionSortNew Sortieren. Wenn die Sortierung unmittelbar rechts neben dem Operator zum Einfügen des Columnstore-Index angezeigt wird, stehen die Chancen sehr gut, dass es sich um CQScanPartitionSortNew handelt sortieren.
Schließlich CQScanPartitionSortNew ist eine von nur zwei Sortierklassen, die die Soft-Sort-Eigenschaft verfügbar machen, wenn Ausführungsplaneigenschaften des Sort-Operators mit aktiviertem undokumentiertem Ablaufverfolgungsflag 8666 generiert werden:
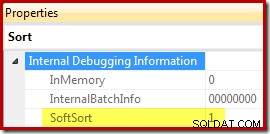
Die Bedeutung von „Soft Sort“ in diesem Zusammenhang ist unklar. Es wird als Eigenschaft im Framework des Abfrageoptimierers nachverfolgt und scheint wahrscheinlich mit optimierten partitionierten Dateneinfügungen zusammenzuhängen, aber um genau zu bestimmen, was es bedeutet, bedarf es weiterer Forschung. In der Zwischenzeit kann diese Eigenschaft verwendet werden, um darauf zu schließen, dass eine Sortierung mit CQScanPartitionSortNew implementiert ist ohne einen Debugger anzuhängen. Die Bedeutung des oben gezeigten InMemory-Eigenschaftsflags wird in Teil 2 behandelt. Dies ist nicht der Fall geben an, ob eine reguläre Sortierung im Speicher durchgeführt wurde oder nicht.
Zusammenfassung von Teil Eins
- CQScanSortNew ist die allgemeine Sortierklasse, die verwendet wird, wenn keine andere Option anwendbar ist. Es scheint, dass eine Vielzahl von internen Merge-Sortierungen im Speicher verwendet werden, wobei der Übergang zu externer Merge-Sortierung mit tempdb erfolgt wenn sich herausstellt, dass der gewährte Arbeitsspeicher nicht ausreicht. Diese Klasse kann für General Sort und Distinct Sort verwendet werden.
- CQScanTopSortNew implementiert Top N Sort. Wo N <=100 ist, wird eine interne Merge-Sortierung im Arbeitsspeicher durchgeführt, die niemals in tempdb übergeht . Nur die aktuellen Top-n-Elemente werden während des Sortierens im Speicher gehalten. Für N> 100 CQScanTopSortNew entspricht einem CQScanSortNew Sortieren, das automatisch stoppt, nachdem N Zeilen ausgegeben wurden. Eine N> 100-Sortierung kann zu tempdb überlaufen wenn nötig.
- Die Top-N-Sortierung, die in Ausführungsplänen zu sehen ist, ist eine Umschreibung nach der Abfrageoptimierung. Wenn der Abfrageoptimierer einen Ausgabebaum mit einem angrenzenden Top- und nicht unterschiedlichen Sort-Operator erzeugt, kann diese Umschreibung die beiden physischen Operatoren zu einem einzigen Top-N-Sort-Operator zusammenfassen.
- CQScanIndexSortNew wird nur in DDL-Plänen zur Indexerstellung verwendet. Es ist die einzige Standard-Sortierklasse, die während der Ausführung dynamisch mehr Speicher erwerben kann. Indexerstellungssortierungen können unter bestimmten Umständen immer noch auf die Festplatte übertragen werden, einschließlich wenn SQL Server entscheidet, dass eine angeforderte Speichererweiterung nicht mit der aktuellen Arbeitslast kompatibel ist.
- CQScanPartitionSortNew ist nur in SQL Server 2014 vorhanden und wird nur zum Optimieren von Einfügungen in einen partitionierten gruppierten Columnstore-Index verwendet. Es liefert eine "weiche Sorte".
Der zweite Teil dieses Artikels befasst sich mit CQScanInMemSortNew , und die beiden nativ kompilierten In-Memory-OLTP-Sortierungen für gespeicherte Prozeduren.