Das SQLskills-Team liebt Wartestatistiken. Wenn Sie Beiträge in diesem Blog (siehe Pauls Beiträge zu Knee-Jerk Wait Statistics) und auf der SQLskills-Site durchsehen, werden Sie Beiträge von uns allen sehen, in denen der Wert von Wartestatistiken diskutiert wird, wonach wir suchen und warum genau Warten ist ein Problem. Paul schreibt am häufigsten darüber, aber wir alle beginnen normalerweise mit Wartestatistiken, wenn wir ein Leistungsproblem beheben. Was bedeutet das in Bezug auf proaktives Handeln?
Um sich ein vollständiges Bild davon zu machen, was Wartestatistiken während eines Leistungsproblems bedeuten, müssen Sie Ihre normalen Wartezeiten kennen. Das bedeutet, diese Informationen proaktiv zu erfassen und diese Baseline als Referenz zu verwenden. Wenn Sie diese Daten nicht haben und ein Leistungsproblem auftritt, wissen Sie nicht, ob PAGELATCH-Wartezeiten in Ihrer Umgebung typisch sind (durchaus möglich) oder ob Sie plötzlich ein Problem im Zusammenhang mit tempdb aufgrund von neu hinzugefügtem Code haben .
Die Wartestatistikdaten
Ich habe zuvor ein Skript veröffentlicht, mit dem ich Wartestatistiken erfasse, und es ist ein Skript, das ich seit langem für Kunden verwende. Ich habe jedoch kürzlich Änderungen an meinem Skript vorgenommen und meine Methode leicht angepasst. Lassen Sie mich erklären, warum…
Die Grundvoraussetzung hinter Wartestatistiken ist, dass SQL Server jedes Mal nachverfolgt, wenn ein Thread auf „etwas“ warten muss. Warten Sie darauf, eine Seite von der Festplatte zu lesen? PAGEIOLATCH_XX warten. Warten Sie darauf, eine Sperre zu erhalten, damit Sie Daten ändern können? LCX_M_XXX warten. Warten auf eine Speicherzuteilung, damit eine Abfrage ausgeführt werden kann? RESOURCE_SEMAPHORE warten. Alle diese Wartezeiten werden in der DMV sys.dm_os_wait_stats nachverfolgt, und die Daten häufen sich einfach im Laufe der Zeit an … sie sind ein kumulativer Repräsentant der Wartezeiten.
Ich habe beispielsweise eine SQL Server 2014-Instanz in einer meiner VMs, die seit ungefähr 9:30 Uhr heute Morgen in Betrieb ist:
SELECT [sqlserver_start_time] FROM [sys].[dm_os_sys_info];
 SQL Server-Startzeit
SQL Server-Startzeit
Wenn ich nun mit Pauls Skript nachschaue, wie meine Wartestatistik aussieht (erinnern Sie sich, bis jetzt kumulativ), sehe ich, dass TRACEWRITE meine aktuelle „Standard“-Wartezeit ist:
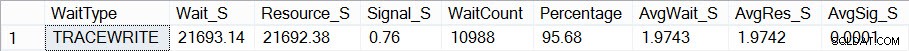 Aktuelle Gesamtwartezeiten
Aktuelle Gesamtwartezeiten
Ok, lassen Sie uns jetzt fünf Minuten tempdb-Konflikte einführen und sehen, wie sich das auf meine gesamten Wartestatistiken auswirkt. Ich habe ein Skript, das Jonathan zuvor verwendet hat, um tempdb-Konflikte zu erstellen, und ich habe es so eingerichtet, dass es 5 Minuten lang ausgeführt wird:
USE AdventureWorks2012;
GO
SET NOCOUNT ON;
GO
DECLARE @CurrentTime SMALLDATETIME = SYSDATETIME(), @EndTime SMALLDATETIME = DATEADD(MINUTE, 5, SYSDATETIME());
WHILE @CurrentTime < @EndTime
BEGIN
IF OBJECT_ID('tempdb..#temp') IS NOT NULL
BEGIN
DROP TABLE #temp;
END
CREATE TABLE #temp
(
ProductID INT PRIMARY KEY,
OrderQty INT,
TotalDiscount MONEY,
LineTotal MONEY,
Filler NCHAR(500) DEFAULT(N'') NOT NULL
);
INSERT INTO #temp(ProductID, OrderQty, TotalDiscount, LineTotal)
SELECT
sod.ProductID,
SUM(sod.OrderQty),
SUM(sod.LineTotal),
SUM(sod.OrderQty + sod.UnitPriceDiscount)
FROM Sales.SalesOrderDetail AS sod
GROUP BY ProductID;
DECLARE
@ProductNumber NVARCHAR(25),
@Name NVARCHAR(50),
@TotalQty INT,
@SalesTotal MONEY,
@TotalDiscount MONEY;
SELECT
@ProductNumber = p.ProductNumber,
@Name = p.Name,
@TotalQty = t1.OrderQty,
@SalesTotal = t1.LineTotal,
@TotalDiscount = t1.TotalDiscount
FROM Production.Product AS p
JOIN #temp AS t1 ON p.ProductID = t1.ProductID;
SET @CurrentTime = SYSDATETIME()
END Ich habe eine Eingabeaufforderung verwendet, um 10 Sitzungen zu starten, die dieses Skript ausgeführt haben, und gleichzeitig ein Skript ausgeführt, das meine Gesamtwartestatistik, einen Schnappschuss der Wartezeiten über einen Zeitraum von 5 Minuten und dann erneut die Gesamtwartestatistik erfasst hat. Zunächst ein kleines Geheimnis:Da wir gutartige Wartezeiten die ganze Zeit ignorieren, kann es nützlich sein, sie in eine Tabelle zu stopfen, damit Sie auf ein Objekt verweisen können, anstatt ständig eine Liste von Ausschlusszeichenfolgen in einer Abfrage hartcodieren zu müssen. Also:
USE SQLskills_WaitStats; GO CREATE TABLE dbo.WaitsToIgnore(WaitType SYSNAME PRIMARY KEY); INSERT dbo.WaitsToIgnore(WaitType) VALUES(N'BROKER_EVENTHANDLER'), (N'BROKER_RECEIVE_WAITFOR'), (N'BROKER_TASK_STOP'), (N'BROKER_TO_FLUSH'), (N'BROKER_TRANSMITTER'), (N'CHECKPOINT_QUEUE'), (N'CHKPT'), (N'CLR_AUTO_EVENT'), (N'CLR_MANUAL_EVENT'), (N'CLR_SEMAPHORE'), (N'DBMIRROR_DBM_EVENT'), (N'DBMIRROR_EVENTS_QUEUE'), (N'DBMIRROR_WORKER_QUEUE'), (N'DBMIRRORING_CMD'), (N'DIRTY_PAGE_POLL'), (N'DISPATCHER_QUEUE_SEMAPHORE'), (N'EXECSYNC'), (N'FSAGENT'), (N'FT_IFTS_SCHEDULER_IDLE_WAIT'), (N'FT_IFTSHC_MUTEX'), (N'HADR_CLUSAPI_CALL'), (N'HADR_FILESTREAM_IOMGR_IOCOMPLETIO(N'), (N'HADR_LOGCAPTURE_WAIT'), (N'HADR_NOTIFICATION_DEQUEUE'), (N'HADR_TIMER_TASK'), (N'HADR_WORK_QUEUE'), (N'KSOURCE_WAKEUP'), (N'LAZYWRITER_SLEEP'), (N'LOGMGR_QUEUE'), (N'ONDEMAND_TASK_QUEUE'), (N'PWAIT_ALL_COMPONENTS_INITIALIZED'), (N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP'), (N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP'), (N'REQUEST_FOR_DEADLOCK_SEARCH'), (N'RESOURCE_QUEUE'), (N'SERVER_IDLE_CHECK'), (N'SLEEP_BPOOL_FLUSH'), (N'SLEEP_DBSTARTUP'), (N'SLEEP_DCOMSTARTUP'), (N'SLEEP_MASTERDBREADY'), (N'SLEEP_MASTERMDREADY'), (N'SLEEP_MASTERUPGRADED'), (N'SLEEP_MSDBSTARTUP'), (N'SLEEP_SYSTEMTASK'), (N'SLEEP_TASK'), (N'SLEEP_TEMPDBSTARTUP'), (N'SNI_HTTP_ACCEPT'), (N'SP_SERVER_DIAGNOSTICS_SLEEP'), (N'SQLTRACE_BUFFER_FLUSH'), (N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP'), (N'SQLTRACE_WAIT_ENTRIES'), (N'WAIT_FOR_RESULTS'), (N'WAITFOR'), (N'WAITFOR_TASKSHUTDOW(N'), (N'WAIT_XTP_HOST_WAIT'), (N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG'), (N'WAIT_XTP_CKPT_CLOSE'), (N'XE_DISPATCHER_JOIN'), (N'XE_DISPATCHER_WAIT'), (N'XE_TIMER_EVENT');
Jetzt sind wir bereit, unsere Wartezeiten festzuhalten:
/* Capture the instance start time
(in this case, time since waits have been accumulating) */
SELECT [sqlserver_start_time] FROM [sys].[dm_os_sys_info];
GO
/* Get the current time */
SELECT SYSDATETIME() AS [Before Test 1];
/* Get aggregate waits until now */
WITH [Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_Waits.WaitsToIgnore)
AND [waiting_tasks_count] > 0
)
SELECT
MAX ([W1].[wait_type]) AS [WaitType],
CAST (MAX ([W1].[WaitS]) AS DECIMAL (16,2)) AS [Wait_S],
CAST (MAX ([W1].[ResourceS]) AS DECIMAL (16,2)) AS [Resource_S],
CAST (MAX ([W1].[SignalS]) AS DECIMAL (16,2)) AS [Signal_S],
MAX ([W1].[WaitCount]) AS [WaitCount],
CAST (MAX ([W1].[Percentage]) AS DECIMAL (5,2)) AS [Percentage],
CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgWait_S],
CAST ((MAX ([W1].[ResourceS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgRes_S],
CAST ((MAX ([W1].[SignalS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum]
HAVING SUM ([W2].[Percentage]) - MAX ([W1].[Percentage]) < 95; -- percentage threshold
GO
/* Get the current time */
SELECT SYSDATETIME() AS [Before Test 2];
/* Capture a snapshot of waits over a 5 minute period */
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
GO
WAITFOR DELAY '00:05:00';
GO
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
GO
WITH [DiffWaits] AS
(
SELECT -- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT -- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0
),
[Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
SELECT
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
-- Cleanup
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
/* Get the current time */
SELECT SYSDATETIME() AS [After Test 1];
/* Get aggregate waits again */
WITH [Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
AND [waiting_tasks_count] > 0
)
SELECT
MAX ([W1].[wait_type]) AS [WaitType],
CAST (MAX ([W1].[WaitS]) AS DECIMAL (16,2)) AS [Wait_S],
CAST (MAX ([W1].[ResourceS]) AS DECIMAL (16,2)) AS [Resource_S],
CAST (MAX ([W1].[SignalS]) AS DECIMAL (16,2)) AS [Signal_S],
MAX ([W1].[WaitCount]) AS [WaitCount],
CAST (MAX ([W1].[Percentage]) AS DECIMAL (5,2)) AS [Percentage],
CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgWait_S],
CAST ((MAX ([W1].[ResourceS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgRes_S],
CAST ((MAX ([W1].[SignalS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum]
HAVING SUM ([W2].[Percentage]) - MAX ([W1].[Percentage]) < 95; -- percentage threshold
GO
/* Get the current time */
SELECT SYSDATETIME() AS [After Test 2]; Wenn wir uns die Ausgabe ansehen, können wir sehen, dass SOS_SCHEDULER_YIELD unser am weitesten verbreiteter Wartetyp war, während die 10 Instanzen des Skripts zum Erstellen von tempdb-Konflikten ausgeführt wurden, und wir hatten wie erwartet auch PAGELATCH_XX-Wartezeiten:
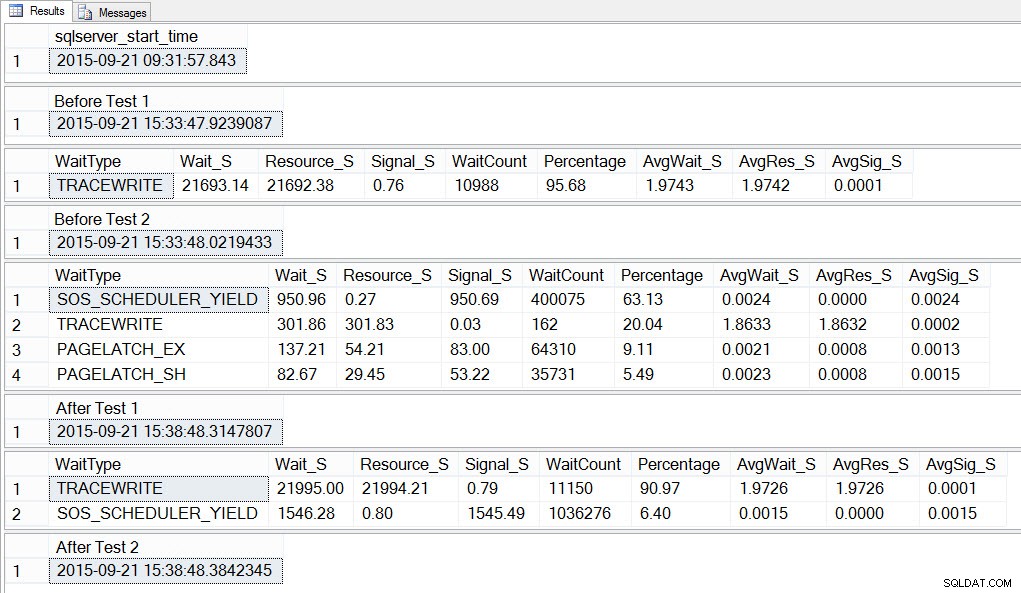
Wenn wir uns die durchschnittlichen Wartezeiten NACH Abschluss des Tests ansehen, sehen wir wieder TRACEWRITE als die höchste Wartezeit, und wir sehen SOS_SCHEDULER_YIELD als Wartezeit. Abhängig davon, was sonst noch in der Umgebung läuft, kann diese Wartezeit in unseren Top-Wartezeiten lange bestehen bleiben oder nicht, und sie kann als zu untersuchender Wartetyp auftauchen oder nicht.
Proaktive Erfassung von Wartestatistiken
Standardmäßig sind Wartestatistiken kumulativ . Ja, Sie können sie jederzeit mit DBCC SQLPERF löschen, aber ich finde, dass die meisten Leute das nicht regelmäßig tun, sie lassen sie einfach akkumulieren. Und das ist in Ordnung, aber verstehen Sie, wie sich das auf Ihre Daten auswirkt. Wenn Sie Ihre Instanz nur neu starten, wenn Sie sie patchen oder wenn ein Problem auftritt (was hoffentlich selten vorkommt), können sich diese Daten monatelang ansammeln. Je mehr Daten Sie haben, desto schwieriger ist es, kleine Abweichungen zu erkennen … Dinge, die Leistungsprobleme sein könnten. Selbst wenn Sie ein „großes Problem“ haben, das mehrere Minuten lang Ihren gesamten Server betrifft, wie wir es hier mit tempdb getan haben, führt es möglicherweise nicht zu einer ausreichenden Änderung Ihrer Daten, um in den kumulierten Daten erkannt zu werden. Vielmehr müssen Sie die Daten schnappen (erfassen, ein paar Minuten warten, erneut erfassen und dann die Daten vergleichen), um zu sehen, was jetzt wirklich vor sich geht .
Wenn Sie also nur alle paar Stunden eine Momentaufnahme der Wartestatistik erstellen, zeigen die von Ihnen gesammelten Daten nur die fortgesetzte Aggregation im Laufe der Zeit. Sie können Vergleichen Sie diese Snapshots, um die Leistung zwischen den Snapshots zu verstehen, aber ich kann Ihnen sagen, dass es mühsam ist, diesen Code für einen großen Datensatz zu schreiben (aber ich bin kein Entwickler, also ist es vielleicht ein Kinderspiel für Sie ).
Meine herkömmliche Methode zum Erfassen von Wartestatistiken bestand darin, einfach alle paar Stunden einen Snapshot von sys.dm_os_wait_stats mit Pauls ursprünglichem Skript zu erstellen:
USE [BaselineData];
GO
IF NOT EXISTS (SELECT * FROM [sys].[tables] WHERE [name] = N'SQLskills_WaitStats_OldMethod')
BEGIN
CREATE TABLE [dbo].[SQLskills_WaitStats_OldMethod]
(
[RowNum] [bigint] IDENTITY(1,1) NOT NULL,
[CaptureDate] [datetime] NULL,
[WaitType] [nvarchar](120) NULL,
[Wait_S] [decimal](14, 2) NULL,
[Resource_S] [decimal](14, 2) NULL,
[Signal_S] [decimal](14, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](4, 2) NULL,
[AvgWait_S] [decimal](14, 4) NULL,
[AvgRes_S] [decimal](14, 4) NULL,
[AvgSig_S] [decimal](14, 4) NULL
);
CREATE CLUSTERED INDEX [CI_SQLskills_WaitStats_OldMethod]
ON [dbo].[SQLskills_WaitStats_OldMethod] ([CaptureDate],[RowNum]);
END
GO
/* Query to use in scheduled job */
USE [BaselineData];
GO
INSERT INTO [dbo].[SQLskills_WaitStats_OldMethod]
(
[CaptureDate] ,
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
EXEC ('WITH [Waits] AS (SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
SELECT
GETDATE(),
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL(14, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL(14, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL(14, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL(4, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS], [W1].[ResourceS],
[W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95;'
); Ich würde dann durchgehen und auf die oberste Wartezeit für jeden Schnappschuss schauen, zum Beispiel:
SELECT [w].[CaptureDate] , [w].[WaitType] , [w].[Percentage] , [w].[Wait_S] , [w].[WaitCount] , [w].[AvgWait_S] FROM [dbo].[SQLskills_WaitStats_OldMethod] w JOIN ( SELECT MIN([RowNum]) AS [RowNumber] , [CaptureDate] FROM [dbo].[SQLskills_WaitStats_OldMethod] WHERE [CaptureDate] IS NOT NULL AND [CaptureDate] > GETDATE() - 60 GROUP BY [CaptureDate] ) m ON [w].[RowNum] = [m].[RowNumber] ORDER BY [w].[CaptureDate];
Meine neue, alternative Methode besteht darin, etwa jede Stunde ein paar Schnappschüsse von Wartestatistiken (mit zwei bis drei Minuten zwischen den Schnappschüssen) zu unterscheiden. Diese Information sagt mir dann genau, worauf das System zu diesem Zeitpunkt gewartet hat:
USE [BaselineData];
GO
IF NOT EXISTS ( SELECT * FROM [sys].[tables] WHERE [name] = N'SQLskills_WaitStats')
BEGIN
CREATE TABLE [dbo].[SQLskills_WaitStats]
(
[RowNum] [bigint] IDENTITY(1,1) NOT NULL,
[CaptureDate] [datetime] NOT NULL DEFAULT (sysdatetime()),
[WaitType] [nvarchar](60) NOT NULL,
[Wait_S] [decimal](16, 2) NULL,
[Resource_S] [decimal](16, 2) NULL,
[Signal_S] [decimal](16, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](5, 2) NULL,
[AvgWait_S] [decimal](16, 4) NULL,
[AvgRes_S] [decimal](16, 4) NULL,
[AvgSig_S] [decimal](16, 4) NULL
) ON [PRIMARY];
CREATE CLUSTERED INDEX [CI_SQLskills_WaitStats]
ON [dbo].[SQLskills_WaitStats] ([CaptureDate],[RowNum]);
END
/* Query to use in scheduled job */
USE [BaselineData];
GO
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
/* Capture wait stats */
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
GO
/* Wait some amount of time */
WAITFOR DELAY '00:02:00';
GO
/* Capture wait stats again */
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
GO
/* Diff the waits */
WITH [DiffWaits] AS
(
SELECT -- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT -- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0
),
[Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
INSERT INTO [BaselineData].[dbo].[SQLskills_WaitStats]
(
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
SELECT
[W1].[wait_type],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) ,
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) ,
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) ,
[W1].[WaitCount] ,
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) ,
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) ,
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) ,
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4))
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS], [W1].[ResourceS],
[W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
/* Clean up the temp tables */
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2]; Ist meine neue Methode besser? Ich denke schon, da es eine bessere Darstellung dessen darstellt, wie die Wartezeiten zum Zeitpunkt der Erfassung aussehen, und es wird immer noch in regelmäßigen Abständen abgetastet. Bei beiden Methoden schaue ich normalerweise nach, was die längste Wartezeit zum Zeitpunkt der Erfassung war:
SELECT [w].[CaptureDate] , [w].[WaitType] , [w].[Percentage] , [w].[Wait_S] , [w].[WaitCount] , [w].[AvgWait_S] FROM [dbo].[SQLskills_WaitStats] w JOIN ( SELECT MIN([RowNum]) AS [RowNumber], [CaptureDate] FROM [dbo].[SQLskills_WaitStats] WHERE [CaptureDate] > GETDATE() - 30 GROUP BY [CaptureDate] ) m ON [w].[RowNum] = [m].[RowNumber] ORDER BY [w].[CaptureDate];
Ergebnisse:
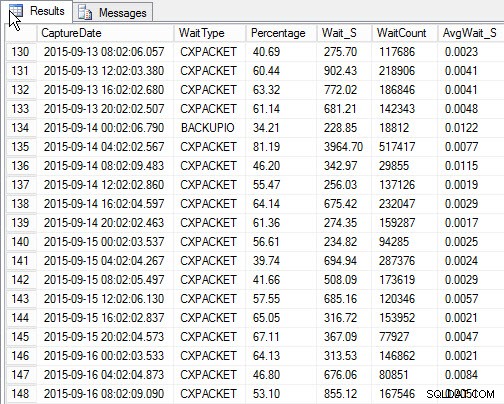 Top auf jeden Snapshot warten (Beispielausgabe)
Top auf jeden Snapshot warten (Beispielausgabe)
Der Nachteil, der bei meinem ursprünglichen Skript bestand, ist, dass es immer noch nur eine Momentaufnahme ist . Ich kann die höchsten Wartezeiten im Laufe der Zeit ermitteln, aber wenn zwischen Snapshots ein Problem auftritt, wird es nicht angezeigt. Was können Sie also tun?
Sie könnten die Häufigkeit Ihrer Aufnahmen erhöhen. Anstatt jede Stunde Wartestatistiken zu erfassen, erfassen Sie sie vielleicht alle 15 Minuten. Oder vielleicht alle 10. Je häufiger Sie die Daten erfassen, desto größer ist die Chance, dass Sie ein Leistungsproblem erkennen.
Ihre andere Option wäre die Verwendung einer Drittanbieteranwendung wie SQL Sentry Performance Advisor, um Wartezeiten zu überwachen. Der Leistungsratgeber ruft genau dieselben Informationen aus der DMV sys.dm_os_wait_stats ab. Es fragt sys.dm_os_wait_stats alle 10 Sekunden mit einer sehr einfachen Abfrage ab:
SELECT * FROM sys.dm_os_wait_stats WHERE wait_time_ms > 0;
Hinter den Kulissen übernimmt Performance Advisor diese Daten und fügt sie seiner Überwachungsdatenbank hinzu. Wenn Sie die Daten sehen, werden harmlose Wartezeiten entfernt und die Deltas für Sie berechnet. Darüber hinaus hat Performance Advisor ein fantastisches Display (ein Blick auf das Dashboard ist viel schöner als die Textausgabe oben) und Sie können die Sammlung anpassen, wenn Sie möchten. Wenn wir uns den Leistungsratgeber und die Daten des ganzen Tages ansehen, kann ich leicht erkennen, wo ich im Bereich „SQL Server-Wartezeiten“ ein Problem hatte:
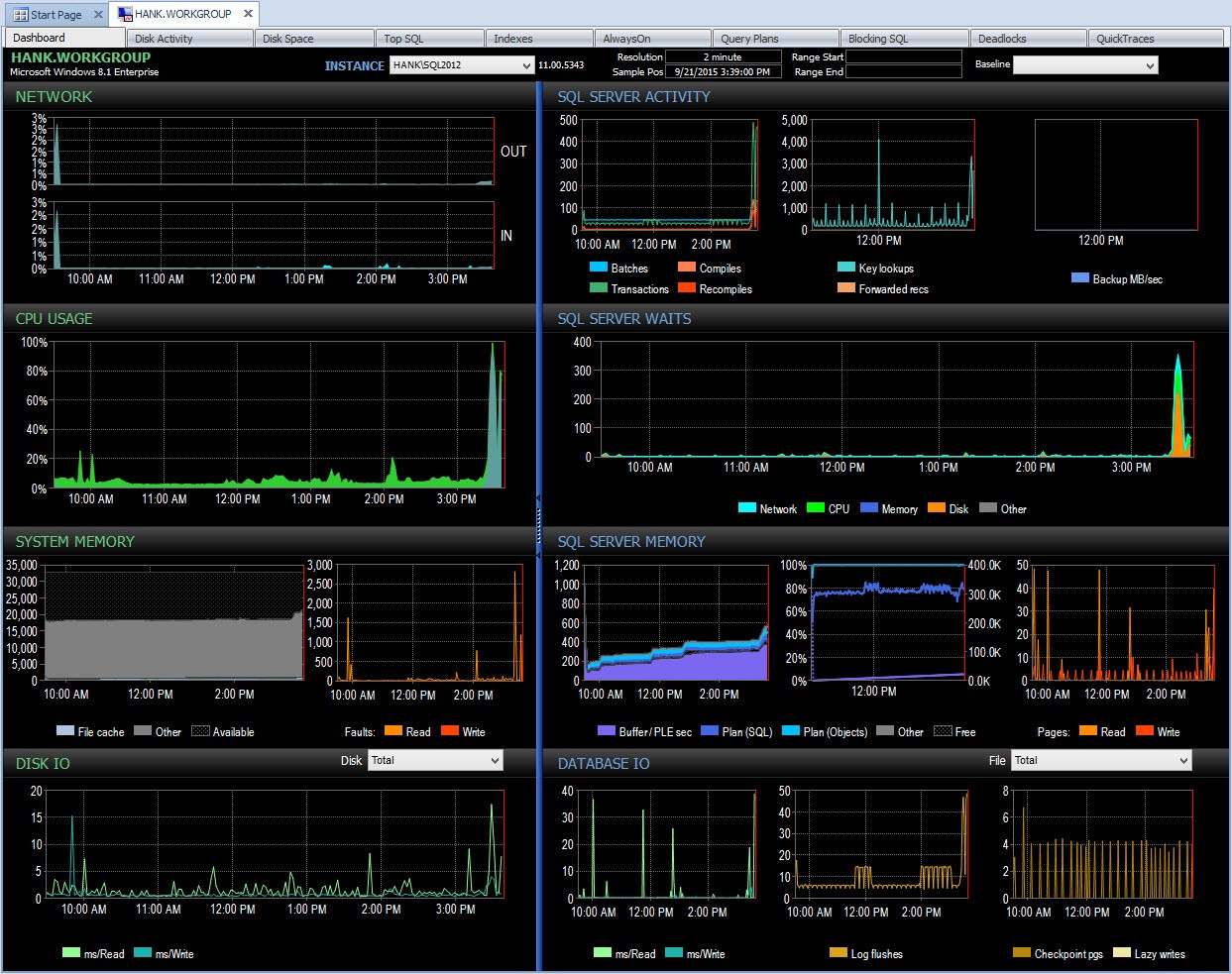 Leistungsberater-Dashboard für den Tag
Leistungsberater-Dashboard für den Tag
Und ich kann dann nach 15:00 Uhr in diesen Zeitraum eintauchen, um weiter zu untersuchen, was passiert ist:
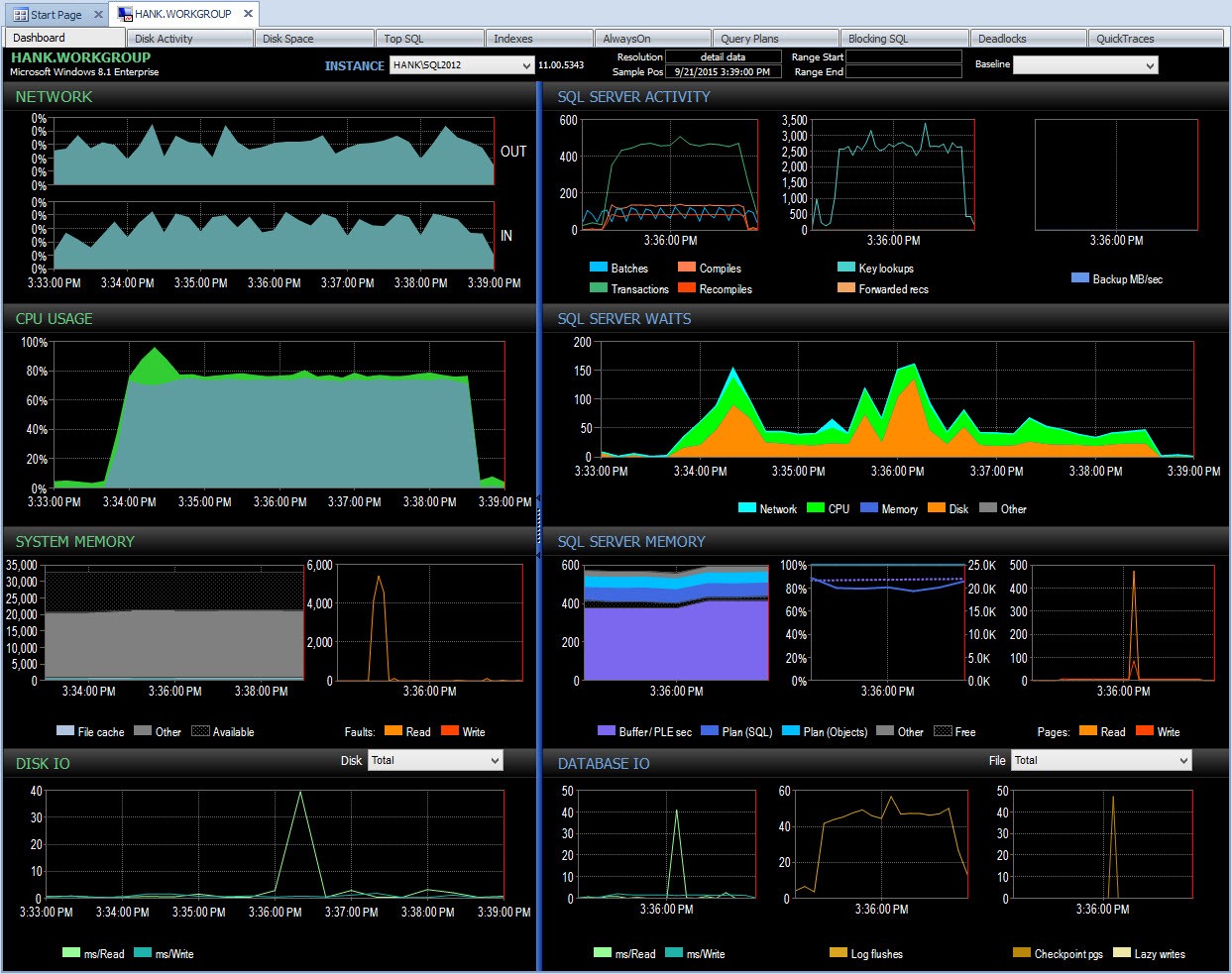 Drilldown in PA bei Leistungsproblem
Drilldown in PA bei Leistungsproblem
Eigene Überwachung, es sei denn, ich habe gleichzeitig mit einem Skript eine Momentaufnahme der Wartestatistik erstellt, ich habe es versäumt, Daten zu diesem Leistungsproblem zu erfassen. Da Performance Advisor die Informationen über einen längeren Zeitraum speichert, tun Sie, wenn Sie einen Leistungseinbruch haben Halten Sie die Wartestatistikdaten (zusammen mit vielen anderen Informationen) bereit, um das Problem zu untersuchen, und Sie haben auch historische Daten, damit Sie verstehen, welche normalen Wartezeiten in Ihrer Umgebung bestehen.
Zusammenfassung
Welche Methode Sie auch wählen, um Wartezeiten zu überwachen, es ist zunächst wichtig zu verstehen, wie SQL Server speichert Warteinformationen, damit Sie die angezeigten Daten verstehen, wenn Sie sie regelmäßig erfassen. Wenn Sie Ihre eigenen Skripts erstellen müssen, um Wartezeiten zu erfassen, sind Sie dahingehend eingeschränkt, dass Sie Abweichungen möglicherweise nicht so einfach erfassen können wie mit Software von Drittanbietern. Aber das ist in Ordnung – eine gewisse Menge an Basisdaten zu haben, damit Sie anfangen zu verstehen, was „normal“ ist, ist besser als gar nichts zu haben . Wenn Sie Ihr Repository erstellen und sich mit einer Umgebung vertraut machen, können Sie Ihre Erfassungsskripts nach Bedarf anpassen, um eventuell vorhandene Probleme zu lösen. Wenn Sie Software von Drittanbietern nutzen, nutzen Sie diese Informationen in vollem Umfang und stellen Sie sicher, dass Sie verstehen, wie Wartezeiten erfasst und gespeichert werden.