SQL Server 2008 führte Sparse-Spalten als Methode ein, um den Speicherplatz für Nullwerte zu reduzieren und erweiterbare Schemas bereitzustellen. Der Nachteil besteht darin, dass beim Speichern und Abrufen von Nicht-NULL-Werten zusätzlicher Aufwand entsteht. Ich war daran interessiert, die Kosten für das Speichern von Nicht-NULL-Werten zu verstehen, nachdem ich mit einem Kunden gesprochen hatte, der diesen Datentyp in einer Staging-Umgebung verwendete. Sie versuchen, die Schreibleistung zu optimieren, und ich habe mich gefragt, ob die Verwendung von Spalten mit geringer Dichte irgendwelche Auswirkungen hatte, da ihre Methode das Einfügen einer Zeile in die Tabelle und das anschließende Aktualisieren erforderte. Ich habe ein erfundenes Beispiel für diese Demo erstellt, das unten erklärt wird, um festzustellen, ob dies eine gute Methode für sie ist.
Überprüfung der Interna
Denken Sie als kurzen Überblick daran, dass beim Erstellen einer Spalte für eine Tabelle, die NULL-Werte zulässt, immer die gesamte Spaltenbreite auf der Seite verbraucht wird, wenn es sich um eine Spalte mit fester Länge handelt (z. B. ein INT). NULL. Wenn es sich um eine Spalte mit variabler Länge handelt (z. B. VARCHAR), verbraucht sie bei NULL mindestens zwei Bytes im Spalten-Offset-Array, es sei denn, die Spalten befinden sich nach der letzten gefüllten Spalte (siehe Kimberlys Blog-Beitrag Column order does not matter…general , aber – ES HÄNGT AB). Eine Sparse-Spalte benötigt keinen Platz auf der Seite für NULL-Werte, egal ob es sich um eine Spalte mit fester oder variabler Länge handelt und unabhängig davon, welche anderen Spalten in der Tabelle gefüllt sind. Der Kompromiss besteht darin, dass eine Spalte mit geringer Dichte vier (4) Bytes mehr Speicherplatz benötigt als eine Spalte ohne geringe Dichte. Zum Beispiel:
| Spaltentyp | Speicherbedarf |
|---|---|
| BIGINT-Spalte, Non-Sparse, mit no Wert | 8 Byte |
| BIGINT-Spalte, Non-Sparse, mit ein Wert | 8 Byte |
| BIGINT-Spalte, spärlich, mit nein Wert | 0 Bytes |
| BIGINT-Spalte, spärlich, mit ein Wert | 12 Byte |
Daher ist es wichtig zu bestätigen, dass der Speichervorteil die potenzielle Leistungseinbuße des Abrufs überwiegt – die aufgrund des Gleichgewichts von Lese- und Schreibvorgängen gegenüber den Daten vernachlässigbar sein kann. Die geschätzten Platzeinsparungen für verschiedene Datentypen sind im oben angegebenen Link "Online-Dokumentation" dokumentiert.
Testszenarien
Ich habe vier verschiedene Szenarien zum Testen eingerichtet, die unten beschrieben werden, und jede Tabelle hatte eine ID-Spalte (INT), eine Namensspalte (VARCHAR(100)) und eine Typspalte (INT) und dann 997 NULLABLE-Spalten.
| Test-ID | Tabellenbeschreibung | DML-Operationen |
|---|---|---|
| 1 | 997 Spalten des INT-Datentyps, NULLABLE, Non-Sparse | Eine Zeile nach der anderen einfügen, ID, Name, Typ und zehn (10) zufällige NULLABLE-Spalten füllen |
| 2 | 997 Spalten vom Datentyp INT, NULLABLE, spärlich | Eine Zeile nach der anderen einfügen, ID, Name, Typ und zehn (10) zufällige NULLABLE-Spalten füllen |
| 3 | 997 Spalten des INT-Datentyps, NULLABLE, Non-Sparse | Eine Zeile nach der anderen einfügen, nur ID, Name, Typ füllen, dann die Zeile aktualisieren und Werte für zehn (10) zufällige NULLABLE-Spalten hinzufügen |
| 4 | 997 Spalten vom Datentyp INT, NULLABLE, spärlich | Eine Zeile nach der anderen einfügen, nur ID, Name, Typ füllen, dann die Zeile aktualisieren und Werte für zehn (10) zufällige NULLABLE-Spalten hinzufügen |
| 5 | 997 Spalten vom Datentyp VARCHAR, NULLABLE, Non-Sparse | Eine Zeile nach der anderen einfügen, ID, Name, Typ und zehn (10) zufällige NULLABLE-Spalten füllen |
| 6 | 997 Spalten vom Datentyp VARCHAR, NULLABLE, spärlich | Eine Zeile nach der anderen einfügen, ID, Name, Typ und zehn (10) zufällige NULLABLE-Spalten füllen |
| 7 | 997 Spalten vom Datentyp VARCHAR, NULLABLE, Non-Sparse | Eine Zeile nach der anderen einfügen, nur ID, Name, Typ füllen, dann die Zeile aktualisieren und Werte für zehn (10) zufällige NULLABLE-Spalten hinzufügen |
| 8 | 997 Spalten vom Datentyp VARCHAR, NULLABLE, spärlich | Eine Zeile nach der anderen einfügen, nur ID, Name, Typ füllen, dann die Zeile aktualisieren und Werte für zehn (10) zufällige NULLABLE-Spalten hinzufügen |
Jeder Test wurde zweimal mit einem Datensatz von 10 Millionen Zeilen durchgeführt. Die beigefügten Skripte können verwendet werden, um Tests zu replizieren, und die Schritte waren für jeden Test wie folgt:
- Erstellen Sie eine neue Datenbank mit vordefinierten Daten und Protokolldateien
- Erstellen Sie die entsprechende Tabelle
- Snapshot-Wartestatistiken und Dateistatistiken
- Beachten Sie die Startzeit
- Führen Sie die DML (eine Einfügung oder eine Einfügung und eine Aktualisierung) für 10 Millionen Zeilen aus
- Haltezeit beachten
- Snapshot-Wartestatistiken und Dateistatistiken und Schreiben in eine Protokolltabelle in einer separaten Datenbank auf einem separaten Speicher
- Snapshot dm_db_index_physical_stats
- Löschen Sie die Datenbank
Die Tests wurden auf einem Dell PowerEdge R720 mit 64 GB Arbeitsspeicher und 12 GB, die der SQL Server 2014 SP1 CU4-Instanz zugewiesen wurden, durchgeführt. Für die Datenspeicherung der Datenbankdateien wurden Fusion-IO-SSDs verwendet.
Ergebnisse
Die Testergebnisse werden unten für jedes Testszenario präsentiert.
Dauer
In allen Fällen dauerte es weniger Zeit (durchschnittlich 11,6 Minuten), die Tabelle zu füllen, wenn Spalten mit geringer Dichte verwendet wurden, selbst wenn die Zeile zuerst eingefügt und dann aktualisiert wurde. Als die Zeile zum ersten Mal eingefügt und dann aktualisiert wurde, dauerte die Ausführung des Tests fast doppelt so lange wie beim Einfügen der Zeile, da doppelt so viele Datenänderungen ausgeführt wurden.
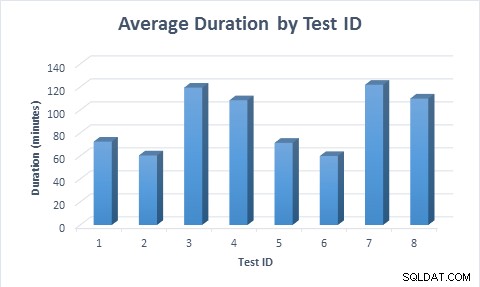 Durchschnittliche Dauer für jedes Testszenario
Durchschnittliche Dauer für jedes Testszenario
Wartestatistik
| Test-ID | Durchschnittlicher Prozentsatz | Durchschnittliche Wartezeit (Sekunden) |
|---|---|---|
| 1 | 16.47 | 0,0001 |
| 2 | 14.00 | 0,0001 |
| 3 | 16.65 | 0,0001 |
| 4 | 15.07 | 0,0001 |
| 5 | 12.80 | 0,0001 |
| 6 | 13,99 | 0,0001 |
| 7 | 14,85 | 0,0001 |
| 8 | 15.02 | 0,0001 |
Die Wartestatistiken waren für alle Tests konsistent, und auf der Grundlage dieser Daten können keine Schlussfolgerungen gezogen werden. Die Hardware hat den Ressourcenbedarf in allen Testfällen ausreichend erfüllt.
Dateistatistik
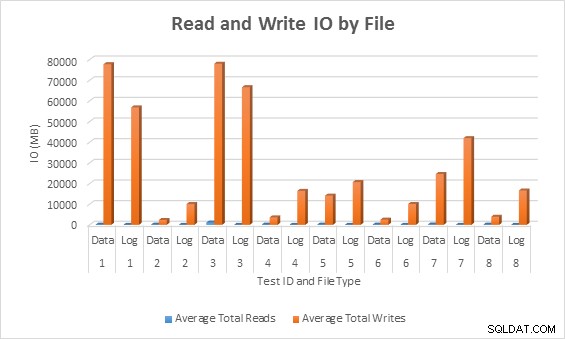 Durchschnittliche E/A (Lesen und Schreiben) pro Datenbankdatei
Durchschnittliche E/A (Lesen und Schreiben) pro Datenbankdatei
In allen Fällen generierten die Tests mit Sparse-Spalten weniger IO (insbesondere Schreibvorgänge) im Vergleich zu Nicht-Sparse-Spalten.
Physische Statistiken indizieren
| Testfall | Zeilenzahl | Gesamtseitenzahl (geclusterter Index) | Gesamtspeicherplatz (GB) | Durchschnittlicher Platzverbrauch für Blattseiten in CI (%) | Durchschnittliche Datensatzgröße (Byte) |
|---|---|---|---|---|---|
| 1 | 10.000.000 | 10.037.312 | 76 | 51,70 | 4.184,49 |
| 2 | 10.000.000 | 301.429 | 2 | 98,51 | 237,50 |
| 3 | 10.000.000 | 10.037.312 | 76 | 51,70 | 4.184,50 |
| 4 | 10.000.000 | 460.960 | 3 | 64.41 | 237,50 |
| 5 | 10.000.000 | 1.823.083 | 13 | 90.31 | 1.326,08 |
| 6 | 10.000.000 | 324.162 | 2 | 98,40 | 255.28 |
| 7 | 10.000.000 | 3.161.224 | 24 | 52.09 | 1.326,39 |
| 8 | 10.000.000 | 503.592 | 3 | 63.33 | 255.28 |
Es bestehen signifikante Unterschiede in der Platznutzung zwischen den Tabellen mit geringer Dichte und Tabellen mit geringer Dichte. Dies ist am deutlichsten, wenn man die Testfälle 1 und 3 betrachtet, in denen ein Datentyp mit fester Länge verwendet wurde (INT), im Vergleich zu den Testfällen 5 und 7, in denen ein Datentyp mit variabler Länge verwendet wurde (VARCHAR(255)). Die ganzzahligen Spalten verbrauchen Speicherplatz, selbst wenn sie NULL sind. Die Spalten mit variabler Länge verbrauchen weniger Speicherplatz, da nur zwei Bytes im Offset-Array für NULL-Spalten verwendet werden und keine Bytes für die NULL-Spalten, die nach der letzten gefüllten Spalte in der Zeile stehen.
Ferner verursacht der Vorgang des Einfügens einer Zeile und deren anschließender Aktualisierung eine Fragmentierung für den Spaltentest mit variabler Länge (Fall 7) im Vergleich zum einfachen Einfügen der Zeile (Fall 5). Die Tabellengröße verdoppelt sich fast, wenn auf die Einfügung die Aktualisierung folgt, aufgrund von Seitenteilungen, die auftreten, wenn die Zeilen aktualisiert werden, wodurch die Seiten halb voll bleiben (gegenüber 90 % voll).
Zusammenfassung
Zusammenfassend sehen wir eine deutliche Reduzierung des Speicherplatzes und der E/A, wenn Sparse-Spalten verwendet werden, und sie schneiden in unseren einfachen Datenänderungstests etwas besser ab als Nicht-Sparse-Spalten (beachten Sie, dass auch die Abrufleistung berücksichtigt werden sollte; vielleicht das Thema eines anderen Beitrag).
Sparse-Spalten haben ein sehr spezifisches Nutzungsszenario, und es ist wichtig, die Menge an eingespartem Speicherplatz basierend auf dem Datentyp für die Spalte und der Anzahl der Spalten, die normalerweise in der Tabelle ausgefüllt werden, zu untersuchen. In unserem Beispiel hatten wir 997 Spalten mit geringer Dichte, und wir haben nur 10 davon gefüllt. Wenn der verwendete Datentyp Integer war, würde eine Zeile auf der Blattebene des Clustered-Index höchstens 188 Byte verbrauchen (4 Byte für die ID, maximal 100 Byte für den Namen, 4 Byte für den Typ und dann 80 Bytes für 10 Spalten). Wenn 997 Spalten keine Sparse-Spalten waren, wurden jeder Spalte 4 Bytes zugewiesen, selbst wenn NULL, sodass jede Zeile auf Blattebene mindestens 4.000 Bytes umfasste. In unserem Szenario sind Spalten mit geringer Dichte absolut akzeptabel. Aber wenn wir 500 oder mehr Sparse-Spalten mit Werten für eine INT-Spalte füllen, geht die Platzersparnis verloren und die Änderungsleistung ist möglicherweise nicht mehr besser.
Abhängig vom Datentyp für Ihre Spalten und der erwarteten Anzahl der zu füllenden Spalten insgesamt möchten Sie möglicherweise ähnliche Tests durchführen, um sicherzustellen, dass bei der Verwendung von Spalten mit geringer Dichte die Einfügeleistung und der Speicher vergleichbar oder besser sind als bei der Verwendung von non -Spärliche Spalten. Für Fälle, in denen nicht alle Spalten gefüllt sind, sind Sparse-Spalten definitiv eine Überlegung wert.



