Anfang dieser Woche habe ich eine Fortsetzung meines letzten Posts über STRING_SPLIT() gepostet in SQL Server 2016, indem Sie mehrere Kommentare adressieren, die im Beitrag hinterlassen und/oder direkt an mich gesendet wurden:
STRING_SPLIT()in SQL Server 2016:Follow-up Nr. 1
Nachdem dieser Beitrag größtenteils geschrieben war, gab es eine brandaktuelle Frage von Doug Ellner:
Wie lassen sich diese Funktionen mit Tabellenwertparametern vergleichen?
Jetzt stand das Testen von TVPs bereits auf meiner Liste zukünftiger Projekte, nach einem kürzlichen Twitter-Austausch mit @Nick_Craver drüben bei Stack Overflow. Er sagte, sie seien begeistert, dass STRING_SPLIT() schnitten gut ab, weil sie mit der Leistung beim Senden von ~7.000 Werten über einen Tabellenwertparameter unzufrieden waren.
Meine Tests
Für diese Tests habe ich SQL Server 2016 RC3 (13.0.1400.361) auf einer Windows 10-VM mit 8 Kernen, mit PCIe-Speicher und 32 GB RAM verwendet.
Ich habe eine einfache Tabelle erstellt, die nachahmt, was sie taten (Auswahl von etwa 10.000 Werten aus einer Tabelle mit mehr als 3 Millionen Zeilenposts), aber für meine Tests hat sie viel weniger Spalten und weniger Indizes:
CREATE TABLE dbo.Posts_Regular ( PostID int PRIMARY KEY, HitCount int NOT NULL DEFAULT 0 ); INSERT dbo.Posts_Regular(PostID) SELECT TOP (3000000) ROW_NUMBER() OVER (ORDER BY s1.[object_id]) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2;
Ich habe auch eine In-Memory-Version erstellt, weil ich neugierig war, ob irgendein Ansatz dort anders funktionieren würde:
CREATE TABLE dbo.Posts_InMemory ( PostID int PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 4000000), HitCount int NOT NULL DEFAULT 0 ) WITH (MEMORY_OPTIMIZED = ON);
Jetzt wollte ich eine C#-App erstellen, die 10.000 eindeutige Werte übergibt, entweder als kommagetrennte Zeichenfolge (mit einem StringBuilder erstellt) oder als TVP (übergeben von einer DataTable). Der Punkt wäre, eine Auswahl von Zeilen basierend auf einer Übereinstimmung abzurufen oder zu aktualisieren, entweder mit einem Element, das durch Aufteilen der Liste erzeugt wurde, oder mit einem expliziten Wert in einem TVP. Der Code wurde also so geschrieben, dass jeder 300. Wert an die Zeichenfolge oder DataTable angehängt wird (der C#-Code befindet sich unten in einem Anhang). Ich nahm die Funktionen, die ich im ursprünglichen Beitrag erstellt hatte, und änderte sie, um varchar(max) zu verarbeiten , und fügte dann zwei Funktionen hinzu, die einen TVP akzeptierten – eine davon speicheroptimiert. Hier sind die Tabellentypen (die Funktionen sind im Anhang unten):
CREATE TYPE dbo.PostIDs_Regular AS TABLE(PostID int PRIMARY KEY); GO CREATE TYPE dbo.PostIDs_InMemory AS TABLE ( PostID int NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1000000) ) WITH (MEMORY_OPTIMIZED = ON); GO
Ich musste auch die Numbers-Tabelle vergrößern, um Strings> 8K und mit> 8K Elementen zu verarbeiten (ich habe 1MM Zeilen gemacht). Dann habe ich sieben gespeicherte Prozeduren erstellt:fünf davon nehmen einen varchar(max) und Verbinden mit der Funktionsausgabe, um die Basistabelle zu aktualisieren, und dann zwei, um das TVP zu akzeptieren und direkt dagegen zu verbinden. Der C#-Code ruft jede dieser sieben Prozeduren mit der Liste von 10.000 auszuwählenden oder zu aktualisierenden Beiträgen 1.000 Mal auf. Diese Verfahren sind auch im Anhang unten aufgeführt. Um es kurz zusammenzufassen, die getesteten Methoden sind:
- Nativ (
STRING_SPLIT()) - XML
- CLR
- Zahlentabelle
- JSON (mit explizitem
intAusgabe) - Tabellenwertparameter
- Speicheroptimierter Tabellenwertparameter
Wir werden das Abrufen der 10.000 Werte 1.000 Mal mit einem DataReader testen – aber nicht über den DataReader iterieren, da dies den Test nur länger dauern würde und für die C#-Anwendung unabhängig von der Datenbank denselben Arbeitsaufwand bedeuten würde produzierte das Set. Wir testen auch die Aktualisierung der 10.000 Zeilen jeweils 1.000 Mal mit ExecuteNonQuery() . Und wir testen sowohl die reguläre als auch die speicheroptimierte Version der Posts-Tabelle, die wir sehr einfach wechseln können, ohne dass wir eine der Funktionen oder Prozeduren ändern müssen, indem wir ein Synonym verwenden:
CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular; -- to test memory-optimized version: DROP SYNONYM dbo.Posts; CREATE SYNONYM dbo.Posts FOR dbo.Posts_InMemory; -- to test the disk-based version again: DROP SYNONYM dbo.Posts; CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular;
Ich startete die Anwendung, führte sie mehrmals für jede Kombination aus, um sicherzustellen, dass Kompilierung, Caching und andere Faktoren nicht unfair gegenüber dem zuerst ausgeführten Stapel waren, und analysierte dann die Ergebnisse aus der Protokollierungstabelle (ich habe auch stichprobenartig sys. dm_exec_procedure_stats, um sicherzustellen, dass keiner der Ansätze einen signifikanten anwendungsbasierten Overhead hatte, und das taten sie auch nicht).
Ergebnisse – Disk-basierte Tabellen
Ich kämpfe manchmal mit der Datenvisualisierung – ich habe wirklich versucht, eine Möglichkeit zu finden, diese Metriken in einem einzigen Diagramm darzustellen, aber ich denke, es gab einfach viel zu viele Datenpunkte, um die hervorstechenden hervorzuheben.
Sie können jedes davon in einem neuen Tab/Fenster anklicken, um es zu vergrößern, aber selbst wenn Sie ein kleines Fenster haben, habe ich versucht, den Gewinner durch die Verwendung von Farbe deutlich zu machen (und der Gewinner war in jedem Fall derselbe). Und um das klarzustellen:Mit "durchschnittlicher Dauer" meine ich die durchschnittliche Zeit, die die Anwendung benötigt hat, um eine Schleife von 1.000 Vorgängen abzuschließen.
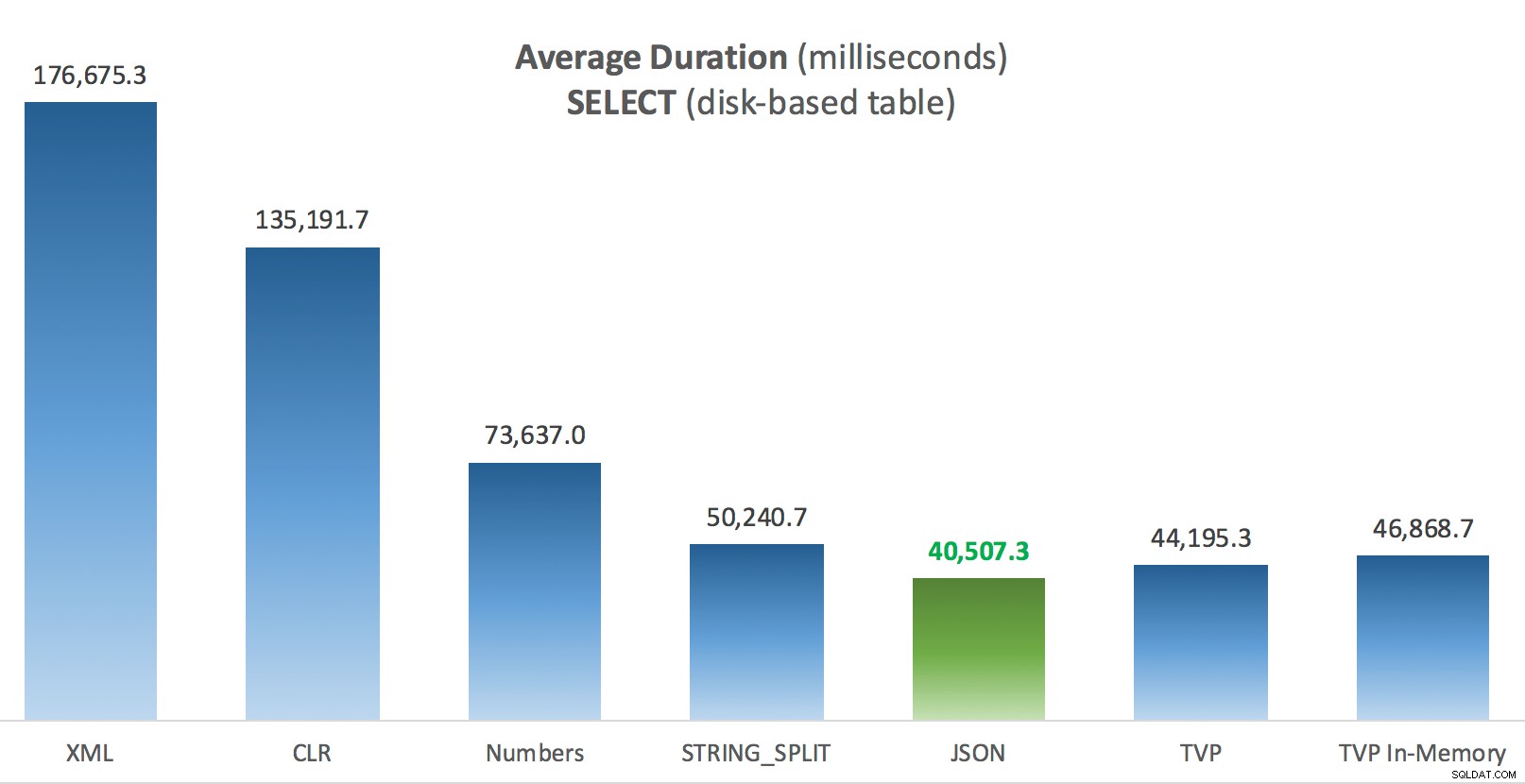 Durchschnittliche Dauer (Millisekunden) für SELECTs gegen festplattenbasierte Posts-Tabelle
Durchschnittliche Dauer (Millisekunden) für SELECTs gegen festplattenbasierte Posts-Tabelle
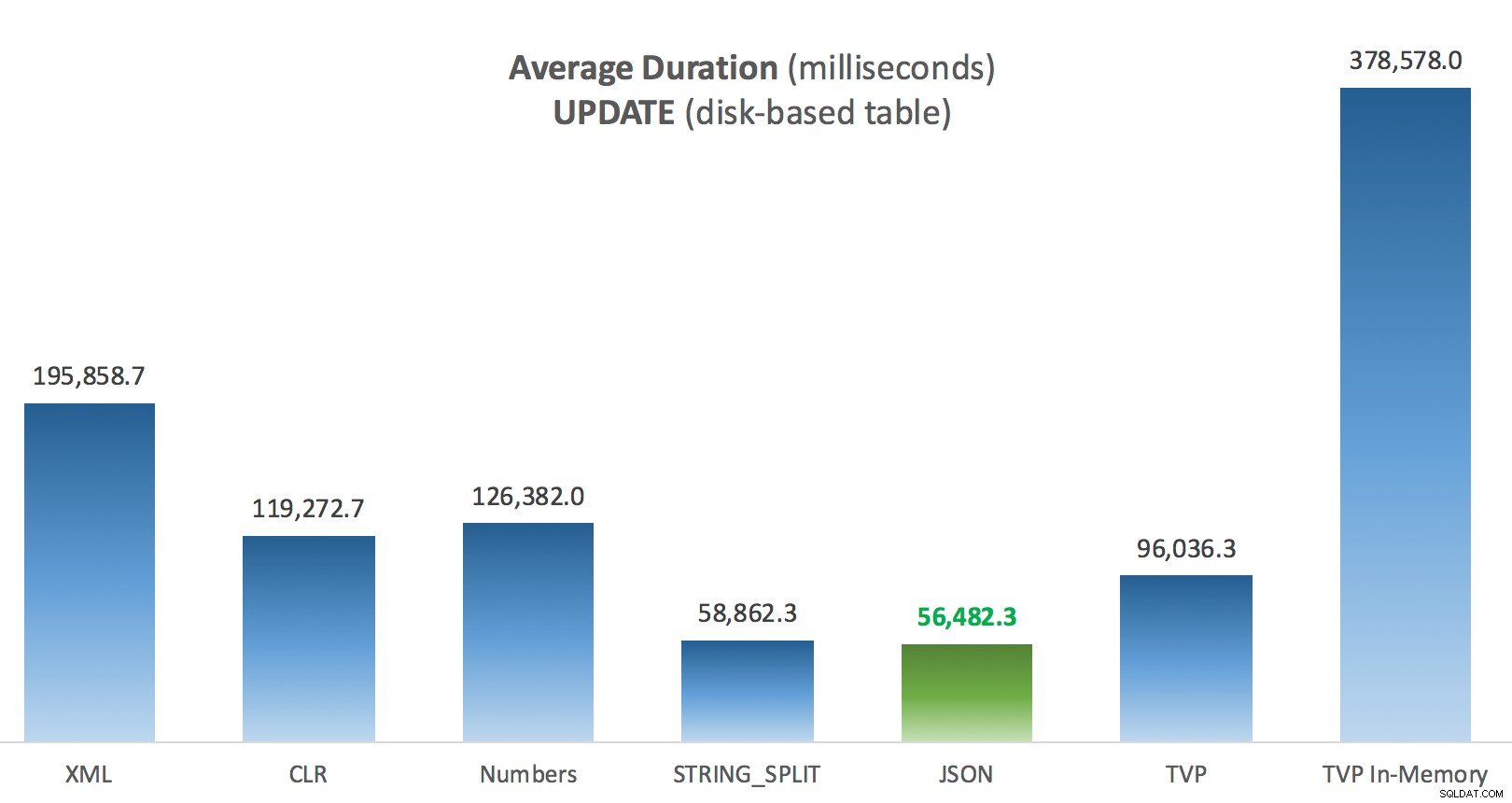 Durchschnittliche Dauer (Millisekunden) für UPDATEs für festplattenbasierte Posts-Tabelle
Durchschnittliche Dauer (Millisekunden) für UPDATEs für festplattenbasierte Posts-Tabelle
Das Interessanteste hier ist für mich, wie schlecht das speicheroptimierte TVP bei der Unterstützung bei einem UPDATE abgeschnitten hat . Es stellt sich heraus, dass parallele Scans derzeit zu aggressiv blockiert werden, wenn DML im Spiel ist; Microsoft hat dies als Funktionslücke erkannt und hofft, diese bald beheben zu können. Beachten Sie, dass paralleles Scannen derzeit mit SELECT möglich ist aber es ist gerade für DML gesperrt. (Es wird in SQL Server 2014 nicht behoben, da diese speziellen parallelen Scanvorgänge dort für keinen Vorgang verfügbar sind.) Wenn das behoben ist oder wenn Ihre TVPs kleiner sind und/oder Parallelität ohnehin nicht vorteilhaft ist, sollten Sie sehen dass speicheroptimierte TVPs eine bessere Leistung erbringen (das Muster funktioniert einfach nicht gut für diesen speziellen Anwendungsfall relativ großer TVPs).
Für diesen speziellen Fall sind hier die Pläne für SELECT (was ich dazu zwingen könnte, parallel zu gehen) und das UPDATE (was ich nicht konnte):
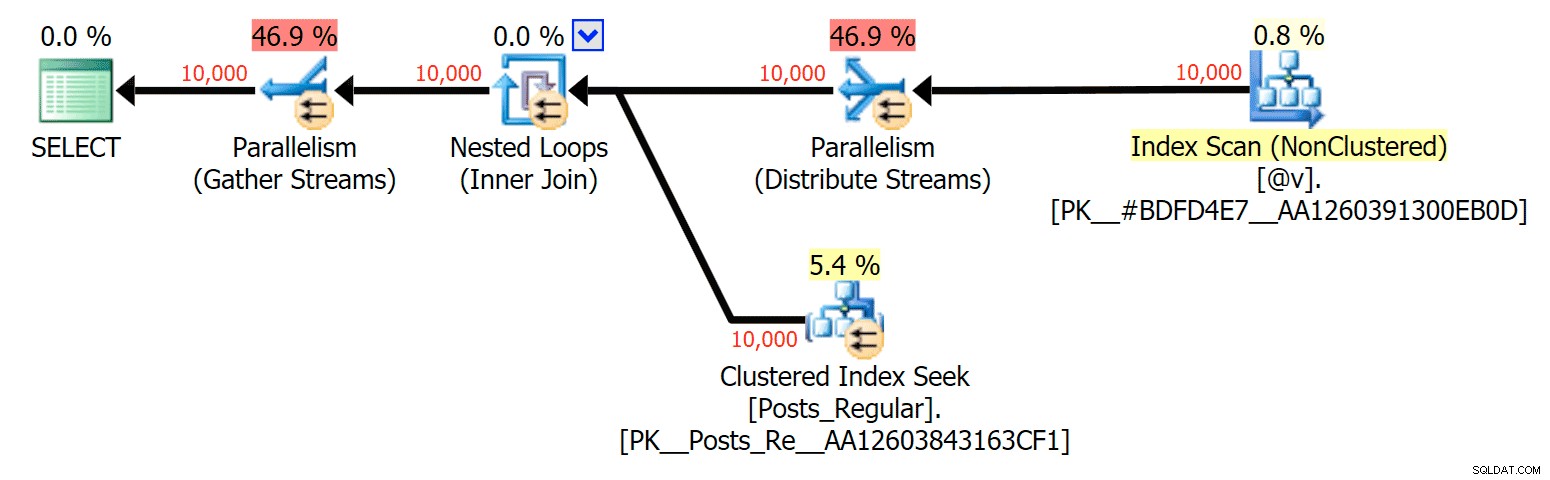 Parallelität in einem SELECT-Plan, der eine festplattenbasierte Tabelle mit einem In-Memory-TVP verbindet
Parallelität in einem SELECT-Plan, der eine festplattenbasierte Tabelle mit einem In-Memory-TVP verbindet
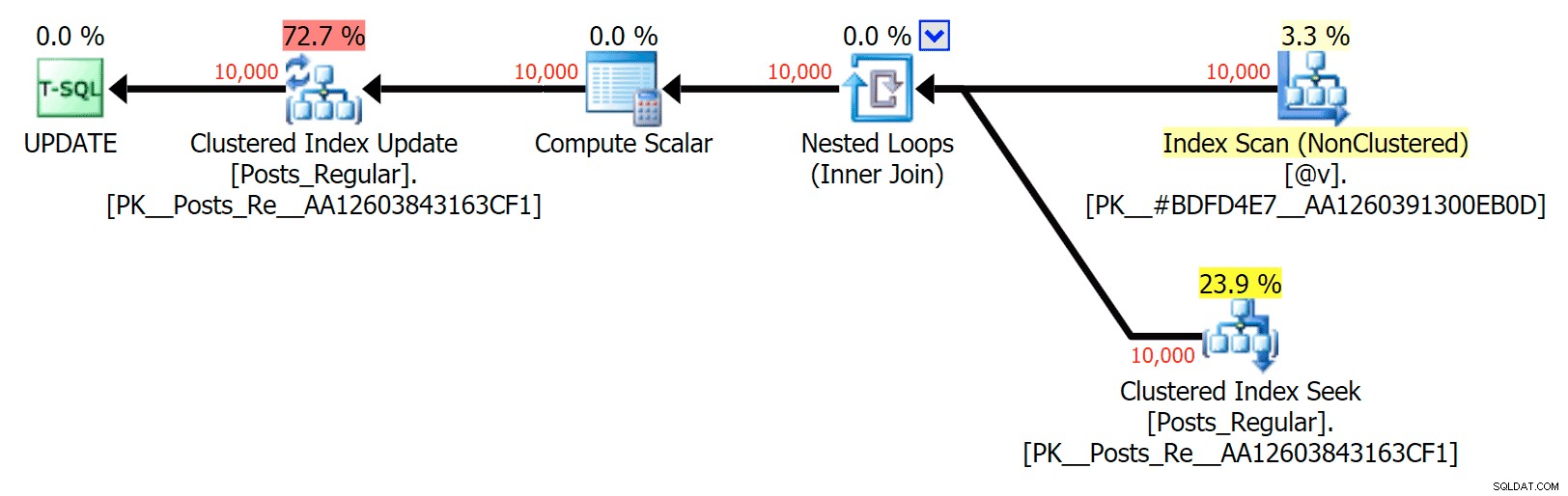 Keine Parallelität in einem UPDATE-Plan, der eine festplattenbasierte Tabelle mit einer In-Memory-Tabelle verbindet TVP
Keine Parallelität in einem UPDATE-Plan, der eine festplattenbasierte Tabelle mit einer In-Memory-Tabelle verbindet TVP
Ergebnisse – Speicheroptimierte Tabellen
Hier etwas mehr Konstanz – die vier Methoden rechts sind relativ gleichmäßig, während die drei links dagegen sehr unerwünscht wirken. Achten Sie auch besonders auf die absolute Skalierung im Vergleich zu den festplattenbasierten Tabellen – zum größten Teil erhalten Sie mit den gleichen Methoden und sogar ohne Parallelität viel schnellere Operationen gegen speicheroptimierte Tabellen, was zu einer geringeren Gesamt-CPU-Auslastung führt.
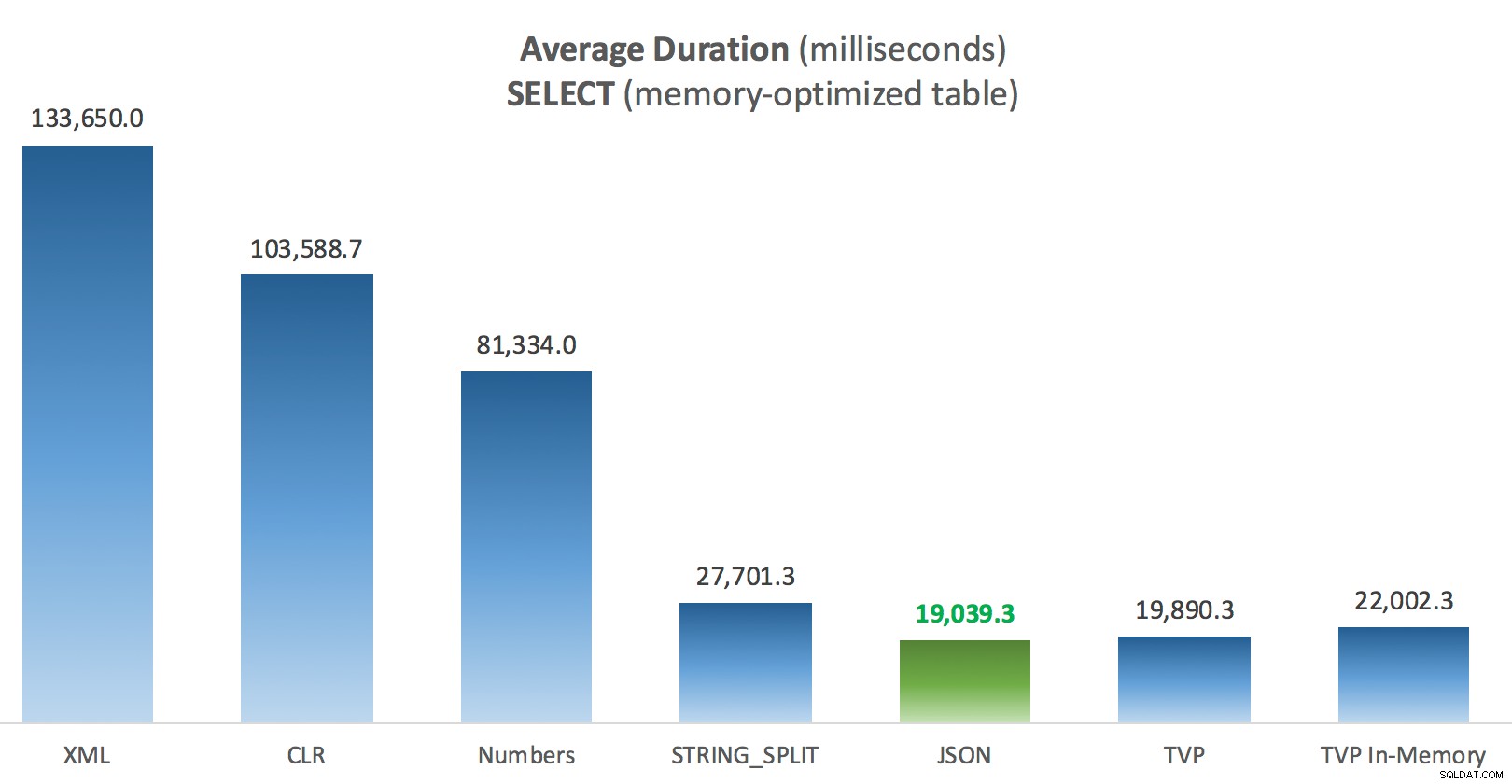 Durchschnittliche Dauer (Millisekunden) für SELECTs gegen speicheroptimierte Posts-Tabelle
Durchschnittliche Dauer (Millisekunden) für SELECTs gegen speicheroptimierte Posts-Tabelle
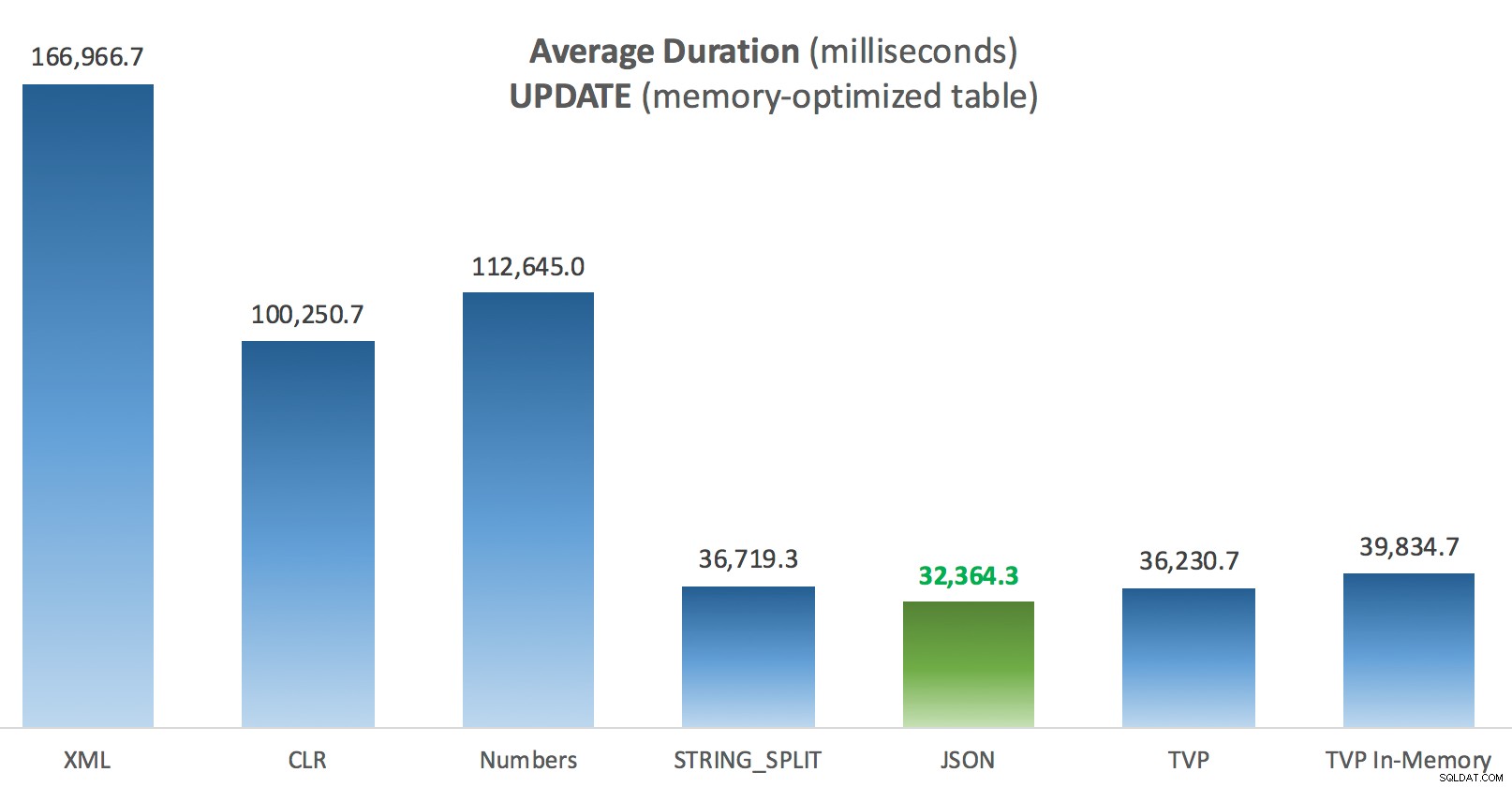 Durchschnittliche Dauer (Millisekunden) für UPDATEs anhand der speicheroptimierten Beitragstabelle
Durchschnittliche Dauer (Millisekunden) für UPDATEs anhand der speicheroptimierten Beitragstabelle
Schlussfolgerung
Für diesen speziellen Test mit einer bestimmten Datengröße, Verteilung und Anzahl von Parametern und auf meiner speziellen Hardware war JSON ein konsistenter Gewinner (wenn auch nur geringfügig). Bei einigen der anderen Tests in früheren Beiträgen schnitten andere Ansätze jedoch besser ab. Nur ein Beispiel dafür, wie das, was Sie tun und wo Sie es tun, einen dramatischen Einfluss auf die relative Effizienz verschiedener Techniken haben kann, hier sind die Dinge, die ich in dieser kurzen Serie getestet habe, mit meiner Zusammenfassung, welche Technik zu tun ist in diesem Fall verwenden und welche als zweite oder dritte Wahl verwenden (z. B. wenn Sie CLR aufgrund von Unternehmensrichtlinien nicht implementieren können oder weil Sie Azure SQL-Datenbank verwenden oder Sie JSON oder STRING_SPLIT() weil Sie noch nicht auf SQL Server 2016 sind). Beachten Sie, dass ich nicht zurückgegangen bin und die Variablenzuweisung und SELECT INTO erneut getestet habe Skripte mit TVPs – diese Tests wurden in der Annahme eingerichtet, dass Sie bereits vorhandene Daten im CSV-Format hatten, die ohnehin zuerst aufgelöst werden müssten. Im Allgemeinen, wenn Sie es vermeiden können, glätten Sie Ihre Sätze IMHO nicht von vornherein in kommaseparierte Strings.
| Ziel | 1. Wahl | 2. Wahl (und ggf. 3.) |
|---|---|---|
| Einfache Variablenzuweisung | STRING_SPLIT() | CLR wenn <2016 XML wenn kein CLR und <2016 |
| AUSWÄHLEN IN | CLR | XML, wenn kein CLR |
| AUSWÄHLEN IN (keine Spule) | CLR | Zahlentabelle, wenn kein CLR |
| AUSWÄHLEN IN (keine Spule + MAXDOP 1) | STRING_SPLIT() | CLR wenn <2016 Zahlentabelle wenn kein CLR und <2016 |
| WÄHLEN Sie den Beitritt zu einer großen Liste (festplattenbasiert) | JSON (int) | TVP wenn <2016 |
| WÄHLEN Sie den Beitritt zu einer großen Liste (speicheroptimiert) | JSON (int) | TVP wenn <2016 |
| UPDATE Beitritt zu großer Liste (festplattenbasiert) | JSON (int) | TVP wenn <2016 |
| UPDATE Beitritt zu großer Liste (speicheroptimiert) | JSON (int) | TVP wenn <2016 |
Für Dougs spezielle Frage:JSON, STRING_SPLIT() , und TVPs schnitten bei diesen Tests im Durchschnitt ziemlich ähnlich ab – nahe genug, dass TVPs die offensichtliche Wahl sind, wenn Sie nicht auf SQL Server 2016 arbeiten. Wenn Sie andere Anwendungsfälle haben, können diese Ergebnisse abweichen. Sehr .
Was uns zur Moral von diesem bringt Geschichte:Ich und andere können sehr spezifische Leistungstests durchführen, die sich um beliebige Funktionen oder Ansätze drehen, und zu einem Schluss kommen, welcher Ansatz am schnellsten ist. Aber es gibt so viele Variablen, dass ich mich nie trauen werde zu sagen:„Dieser Ansatz ist immer am schnellsten.“ In diesem Szenario habe ich mich sehr bemüht, die meisten der beitragenden Faktoren zu kontrollieren, und während JSON in allen vier Fällen gewonnen hat, können Sie sehen, wie sich diese verschiedenen Faktoren auf die Ausführungszeiten auswirkten (und bei einigen Ansätzen drastisch). So ist es Es lohnt sich immer, eigene Tests zu konstruieren, und ich hoffe, ich konnte Ihnen dabei helfen, zu veranschaulichen, wie ich an solche Dinge herangehe.
Anhang A:Konsolenanwendungscode
Bitte keine Spitzfindigkeiten über diesen Code; Es wurde buchstäblich als eine sehr einfache Möglichkeit zusammengeworfen, diese gespeicherten Prozeduren 1.000 Mal mit echten Listen und DataTables auszuführen, die in C # zusammengestellt wurden, und die Zeit zu protokollieren, die jede Schleife für eine Tabelle benötigte (um sicherzustellen, dass anwendungsbezogener Overhead bei der Handhabung enthalten ist entweder eine große Zeichenfolge oder eine Sammlung). Ich könnte eine Fehlerbehandlung hinzufügen, eine andere Schleife ausführen (z. B. die Listen innerhalb der Schleife erstellen, anstatt eine einzelne Arbeitseinheit wiederzuverwenden) und so weiter.
using System;
using System.Text;
using System.Configuration;
using System.Data;
using System.Data.SqlClient;
namespace SplitTesting
{
class Program
{
static void Main(string[] args)
{
string operation = "Update";
if (args[0].ToString() == "-Select") { operation = "Select"; }
var csv = new StringBuilder();
DataTable elements = new DataTable();
elements.Columns.Add("value", typeof(int));
for (int i = 1; i <= 10000; i++)
{
csv.Append((i*300).ToString());
if (i < 10000) { csv.Append(","); }
elements.Rows.Add(i*300);
}
string[] methods = { "Native", "CLR", "XML", "Numbers", "JSON", "TVP", "TVP_InMemory" };
using (SqlConnection con = new SqlConnection())
{
con.ConnectionString = ConfigurationManager.ConnectionStrings["primary"].ToString();
con.Open();
SqlParameter p;
foreach (string method in methods)
{
SqlCommand cmd = new SqlCommand("dbo." + operation + "Posts_" + method, con);
cmd.CommandType = CommandType.StoredProcedure;
if (method == "TVP" || method == "TVP_InMemory")
{
cmd.Parameters.Add("@PostList", SqlDbType.Structured).Value = elements;
}
else
{
cmd.Parameters.Add("@PostList", SqlDbType.VarChar, -1).Value = csv.ToString();
}
var timer = System.Diagnostics.Stopwatch.StartNew();
for (int x = 1; x <= 1000; x++)
{
if (operation == "Update") { cmd.ExecuteNonQuery(); }
else { SqlDataReader rdr = cmd.ExecuteReader(); rdr.Close(); }
}
timer.Stop();
long this_time = timer.ElapsedMilliseconds;
// log time - the logging procedure adds clock time and
// records memory/disk-based (determined via synonym)
SqlCommand log = new SqlCommand("dbo.LogBatchTime", con);
log.CommandType = CommandType.StoredProcedure;
log.Parameters.Add("@Operation", SqlDbType.VarChar, 32).Value = operation;
log.Parameters.Add("@Method", SqlDbType.VarChar, 32).Value = method;
log.Parameters.Add("@Timing", SqlDbType.Int).Value = this_time;
log.ExecuteNonQuery();
Console.WriteLine(method + " : " + this_time.ToString());
}
}
}
}
} Beispielnutzung:
SplitTesting.exe -SelectSplitTesting.exe -Aktualisieren
Anhang B:Funktionen, Prozeduren und Protokollierungstabelle
Hier wurden die Funktionen bearbeitet, um varchar(max) zu unterstützen (Die CLR-Funktion hat bereits nvarchar(max) akzeptiert und ich zögerte immer noch zu versuchen, es zu ändern):
CREATE FUNCTION dbo.SplitStrings_Native( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] FROM STRING_SPLIT(@List, @Delimiter));
GO
CREATE FUNCTION dbo.SplitStrings_XML( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = y.i.value('(./text())[1]', 'varchar(max)')
FROM (SELECT x = CONVERT(XML, '<i>' + REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')) AS a CROSS APPLY x.nodes('i') AS y(i));
GO
CREATE FUNCTION dbo.SplitStrings_Numbers( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
CREATE FUNCTION dbo.SplitStrings_JSON( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] FROM OPENJSON(CHAR(91) + @List + CHAR(93)) WITH (value int '$'));
GO Und die gespeicherten Prozeduren sahen so aus:
CREATE PROCEDURE dbo.UpdatePosts_Native @PostList varchar(max) AS BEGIN UPDATE p SET HitCount += 1 FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID = s.[value]; END GO CREATE PROCEDURE dbo.SelectPosts_Native @PostList varchar(max) AS BEGIN SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID = s.[value]; END GO -- repeat for the 4 other varchar(max)-based methods CREATE PROCEDURE dbo.UpdatePosts_TVP @PostList dbo.PostIDs_Regular READONLY -- switch _Regular to _InMemory AS BEGIN SET NOCOUNT ON; UPDATE p SET HitCount += 1 FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID = s.PostID; END GO CREATE PROCEDURE dbo.SelectPosts_TVP @PostList dbo.PostIDs_Regular READONLY -- switch _Regular to _InMemory AS BEGIN SET NOCOUNT ON; SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID = s.PostID; END GO -- repeat for in-memory
Und schließlich die Protokollierungstabelle und -prozedur:
CREATE TABLE dbo.SplitLog
(
LogID int IDENTITY(1,1) PRIMARY KEY,
ClockTime datetime NOT NULL DEFAULT GETDATE(),
OperatingTable nvarchar(513) NOT NULL, -- Posts_InMemory or Posts_Regular
Operation varchar(32) NOT NULL DEFAULT 'Update', -- or select
Method varchar(32) NOT NULL DEFAULT 'Native', -- or TVP, JSON, etc.
Timing int NOT NULL DEFAULT 0
);
GO
CREATE PROCEDURE dbo.LogBatchTime
@Operation varchar(32),
@Method varchar(32),
@Timing int
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.SplitLog(OperatingTable, Operation, Method, Timing)
SELECT base_object_name, @Operation, @Method, @Timing
FROM sys.synonyms WHERE name = N'Posts';
END
GO
-- and the query to generate the graphs:
;WITH x AS
(
SELECT OperatingTable,Operation,Method,Timing,
Recency = ROW_NUMBER() OVER
(PARTITION BY OperatingTable,Operation,Method
ORDER BY ClockTime DESC)
FROM dbo.SplitLog
)
SELECT OperatingTable,Operation,Method,AverageDuration = AVG(1.0*Timing)
FROM x WHERE Recency <= 3
GROUP BY OperatingTable,Operation,Method;