Vor ein paar Wochen habe ich darüber geschrieben, wie überrascht ich von der Leistung einer neuen nativen Funktion in SQL Server 2016 war, STRING_SPLIT() :
- Leistungsüberraschungen und Annahmen:STRING_SPLIT()
Nachdem der Beitrag veröffentlicht wurde, erhielt ich einige Kommentare (öffentlich und privat) mit diesen Vorschlägen (oder Fragen, die ich in Vorschläge umwandelte):
- Festlegen eines expliziten Ausgabedatentyps für den JSON-Ansatz, damit diese Methode nicht unter potenziellem Leistungsaufwand aufgrund des Fallbacks von
nvarchar(max)leidet . - Testen eines etwas anderen Ansatzes, bei dem tatsächlich etwas mit den Daten gemacht wird – nämlich
SELECT INTO #temp. - Zeigen, wie geschätzte Zeilenzahlen im Vergleich zu bestehenden Methoden aussehen, insbesondere beim Verschachteln von Teilungsvorgängen.
Ich habe einigen Leuten offline geantwortet, dachte aber, dass es sich lohnen würde, hier ein Follow-up zu posten.
JSON gerechter sein
Die ursprüngliche JSON-Funktion sah wie folgt aus, ohne Spezifikation für den Ausgabedatentyp:
CREATE FUNCTION dbo.SplitStrings_JSON
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); Ich habe es umbenannt und zwei weitere mit den folgenden Definitionen erstellt:
CREATE FUNCTION dbo.SplitStrings_JSON_int
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] int '$'));
GO
CREATE FUNCTION dbo.SplitStrings_JSON_varchar
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] varchar(100) '$')); Ich dachte, dies würde die Leistung drastisch verbessern, aber leider war dies nicht der Fall. Ich habe die Tests erneut durchgeführt und die Ergebnisse waren wie folgt:
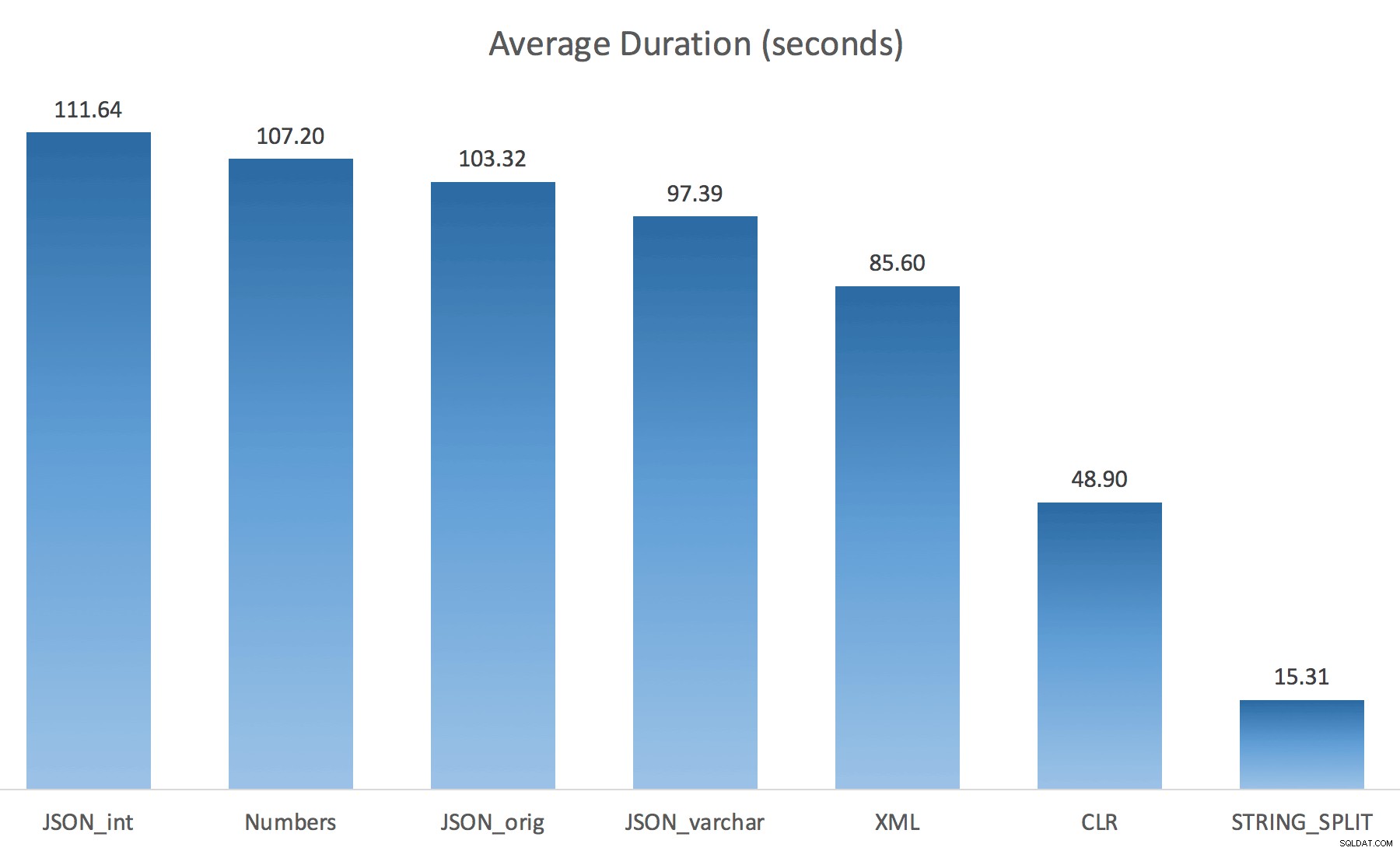
Die Wartezeiten, die während einer zufälligen Instanz des Tests beobachtet wurden (auf diese> 25 gefiltert):
| CLR | IO_COMPLETION | 1.595 |
| SOS_SCHEDULER_YIELD | 76 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 76 | |
| MEMORY_ALLOCATION_EXT | 28 | |
| JSON_int | MEMORY_ALLOCATION_EXT | 6.294 |
| SOS_SCHEDULER_YIELD | 95 | |
| JSON_original | MEMORY_ALLOCATION_EXT | 4.307 |
| SOS_SCHEDULER_YIELD | 83 | |
| JSON_varchar | MEMORY_ALLOCATION_EXT | 6.110 |
| SOS_SCHEDULER_YIELD | 87 | |
| Zahlen | SOS_SCHEDULER_YIELD | 96 |
| XML | MEMORY_ALLOCATION_EXT | 1.917 |
| IO_COMPLETION | 1.616 | |
| SOS_SCHEDULER_YIELD | 147 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 73 |
Beobachtete Wartezeiten> 25 (beachten Sie, dass es keinen Eintrag für STRING_SPLIT gibt )
Beim Wechsel von der Voreinstellung zu varchar(100) hat die Leistung ein wenig verbessert, der Gewinn war vernachlässigbar und der Wechsel zu int hat es eigentlich noch schlimmer gemacht. Hinzu kommt, dass Sie wahrscheinlich STRING_ESCAPE() hinzufügen müssen in einigen Szenarien in die eingehende Zeichenfolge, nur für den Fall, dass sie Zeichen enthalten, die das JSON-Parsing durcheinander bringen. Meine Schlussfolgerung ist immer noch, dass dies eine nette Art ist, die neue JSON-Funktionalität zu nutzen, aber meistens eine Neuheit, die für einen vernünftigen Maßstab ungeeignet ist.
Materialisierung der Ausgabe
Jonathan Magnan machte diese scharfsinnige Beobachtung zu meinem vorherigen Beitrag:
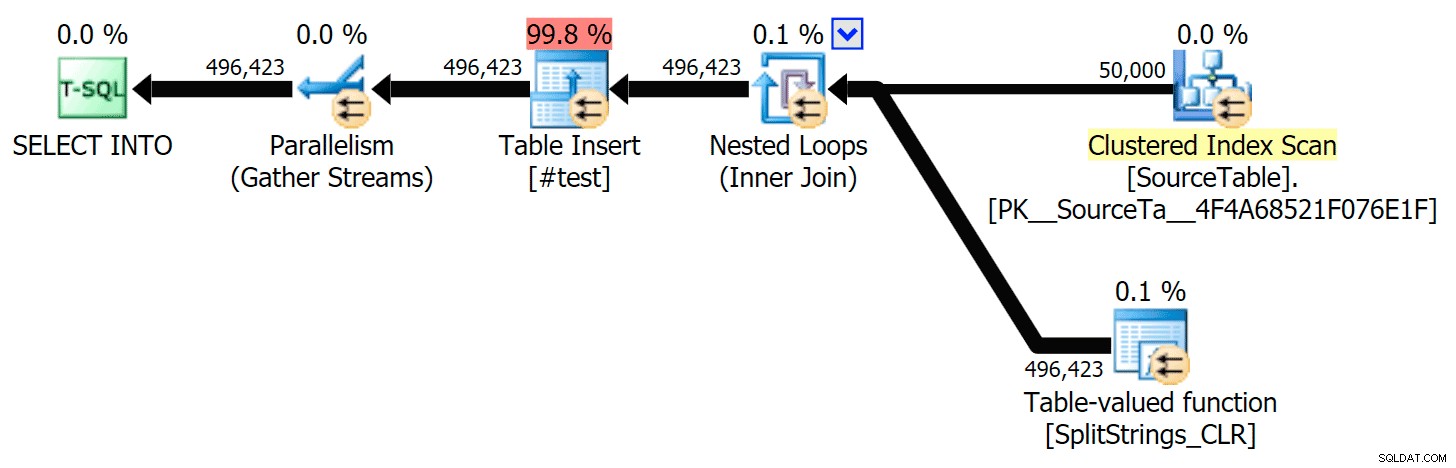
STRING_SPLIT ist in der Tat sehr schnell, aber auch höllisch langsam, wenn mit temporären Tabellen gearbeitet wird (es sei denn, es wird in einem zukünftigen Build behoben).SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY string_split(s.StringValue, ',') AS f
Wird VIEL langsamer sein als die SQL CLR-Lösung (15x und mehr!).
Also habe ich mich eingegraben. Ich habe Code erstellt, der jede meiner Funktionen aufruft und die Ergebnisse in eine #temp-Tabelle ausgibt und sie zeitlich einstellt:
SET NOCOUNT ON; SELECT N'SET NOCOUNT ON; TRUNCATE TABLE dbo.Timings; GO '; SELECT N'DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = ''' + name + ''', point = ''Start'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f; GO DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, '''+name+''', ''End'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; DROP TABLE #test; GO' FROM sys.objects WHERE name LIKE '%split%';
Ich habe jeden Test nur einmal ausgeführt (anstatt 100 Mal zu wiederholen), weil ich die E/A auf meinem System nicht vollständig durcheinander bringen wollte. Trotzdem hatte Jonathan nach durchschnittlich drei Testläufen absolut und zu 100 % recht. So dauerte es mit jeder Methode, eine #temp-Tabelle mit ~500.000 Zeilen zu füllen:
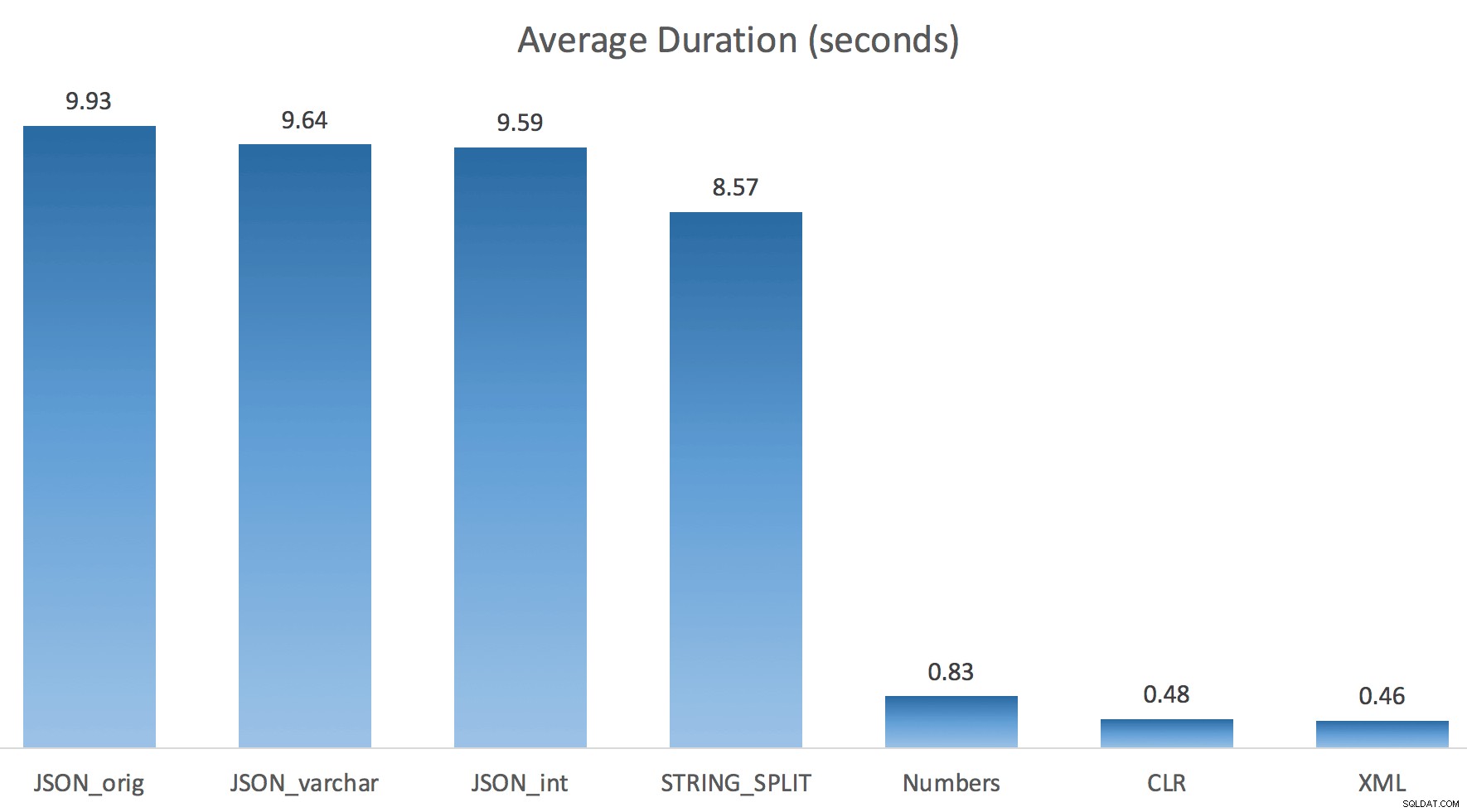
Also hier, JSON und STRING_SPLIT -Methoden dauerten jeweils etwa 10 Sekunden, während die Numbers-Tabellen-, CLR- und XML-Ansätze weniger als eine Sekunde dauerten. Verwirrt untersuchte ich die Wartezeiten, und tatsächlich verursachten die vier Methoden auf der linken Seite erhebliche LATCH_EX Wartezeiten (etwa 25 Sekunden), die bei den anderen drei nicht zu sehen waren, und es gab keine nennenswerten nennenswerten Wartezeiten.
Und da die Latch-Wartezeiten länger als die Gesamtdauer waren, gab es mir einen Hinweis darauf, dass dies mit Parallelität zu tun hatte (diese spezielle Maschine hat 4 Kerne). Also habe ich erneut Testcode generiert und nur eine Zeile geändert, um zu sehen, was ohne Parallelität passieren würde:
CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f OPTION (MAXDOP 1);
Jetzt STRING_SPLIT viel besser (ebenso wie die JSON-Methoden), aber immer noch mindestens doppelt so lange wie CLR:
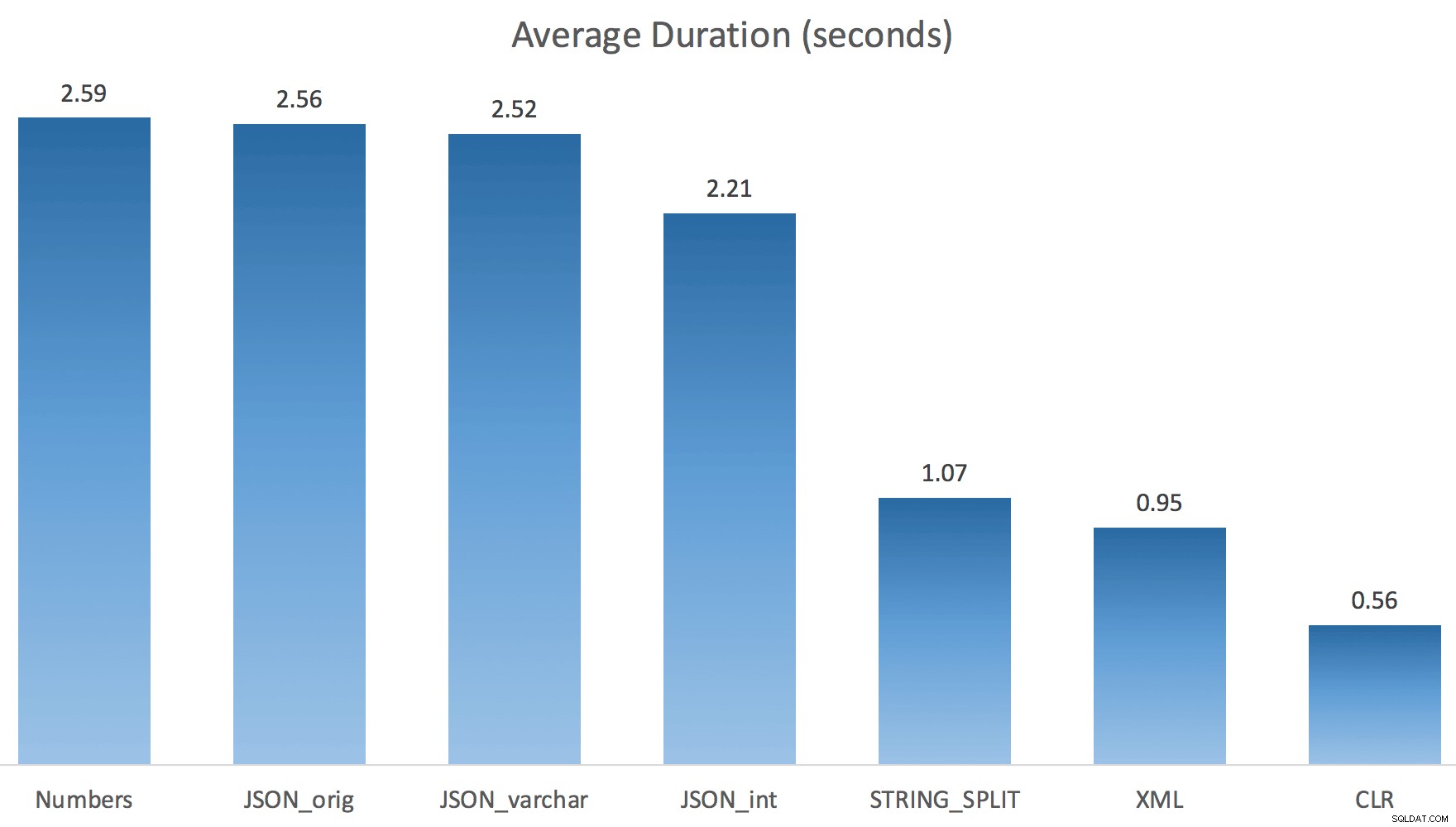
Es könnte also ein verbleibendes Problem bei diesen neuen Methoden geben, wenn es um Parallelität geht. Es war kein Thread-Verteilungsproblem (ich habe das überprüft), und CLR hatte tatsächlich schlechtere Schätzungen (100x tatsächlich gegenüber nur 5x für STRING_SPLIT ); nur ein zugrunde liegendes Problem mit der Koordinierung von Latches zwischen Threads, nehme ich an. Für den Moment könnte es sich lohnen, MAXDOP 1 zu verwenden wenn Sie wissen, dass Sie die Ausgabe auf neue Seiten schreiben.
Ich habe die grafischen Pläne eingefügt, die den CLR-Ansatz mit dem nativen Ansatz vergleichen, sowohl für die parallele als auch für die serielle Ausführung (ich habe auch eine Abfrageanalysedatei hochgeladen, die Sie im SQL Sentry Plan Explorer öffnen können, um selbst herumzuschnüffeln):
STRING_SPLIT
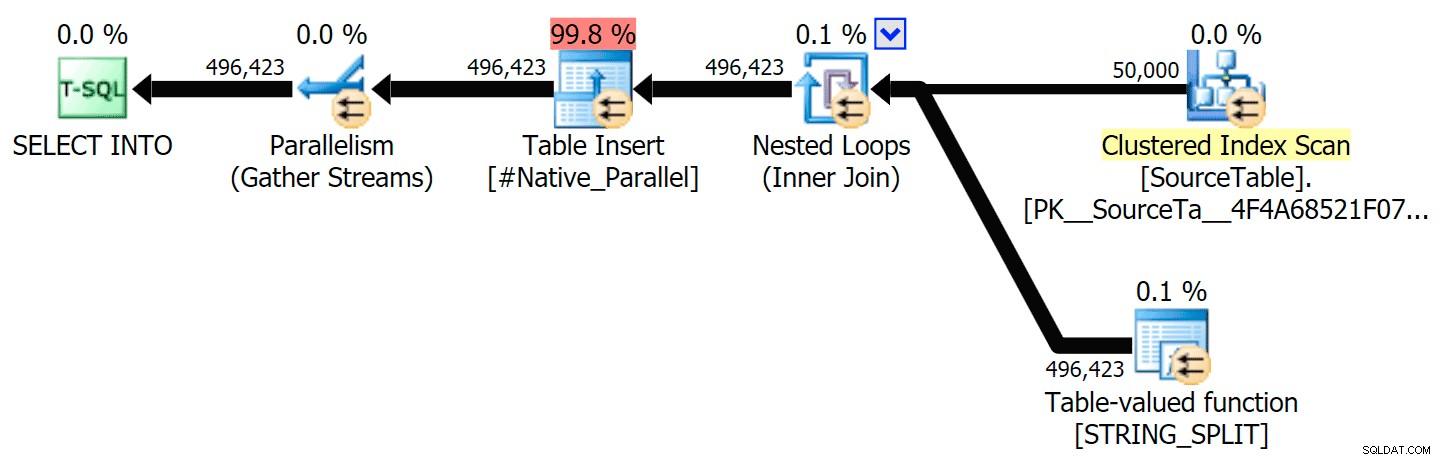
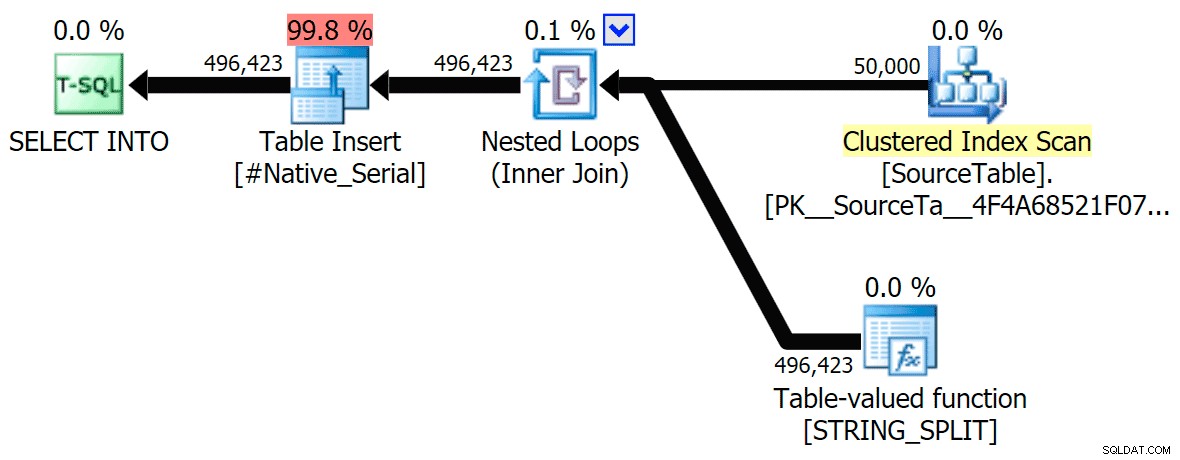
CLR
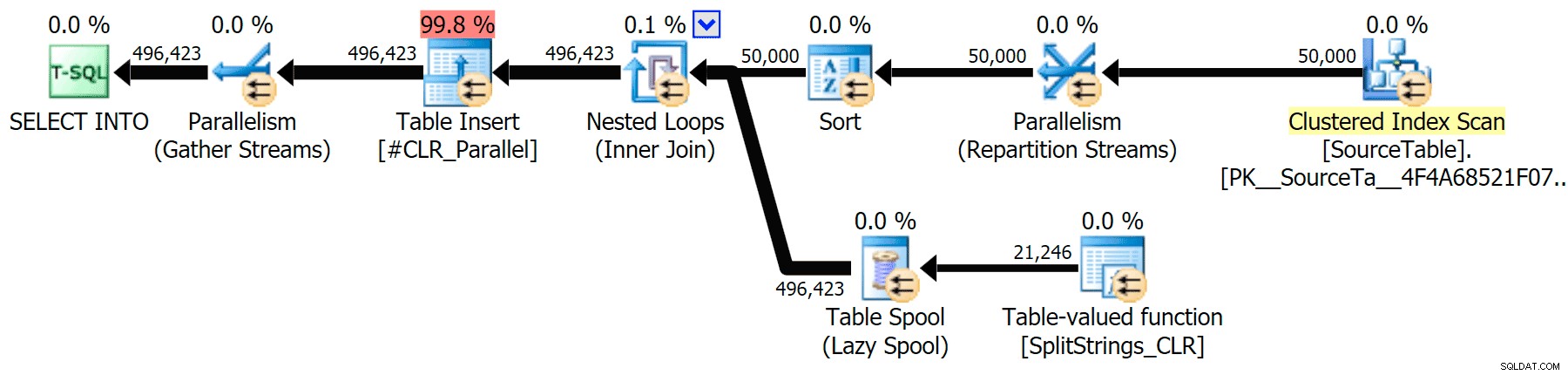
Die Sortierwarnung, FYI, war nicht allzu schockierend und hatte offensichtlich keine großen greifbaren Auswirkungen auf die Abfragedauer:

- StringSplit.queryanalysis.zip (25kb)
Spools Out für den Sommer
Als ich mir diese Pläne etwas genauer ansah, bemerkte ich, dass es im CLR-Plan eine faule Spule gibt. Dies wird eingeführt, um sicherzustellen, dass Duplikate zusammen verarbeitet werden (um Arbeit zu sparen, indem weniger tatsächlich aufgeteilt wird), aber diese Spule ist nicht immer in allen Planformen möglich und kann denjenigen, die sie verwenden können, einen kleinen Vorteil verschaffen ( B. der CLR-Plan), je nach Schätzung. Um ohne Spulen zu vergleichen, habe ich das Trace-Flag 8690 aktiviert und die Tests erneut ausgeführt. Hier ist zunächst der parallele CLR-Plan ohne Spool:
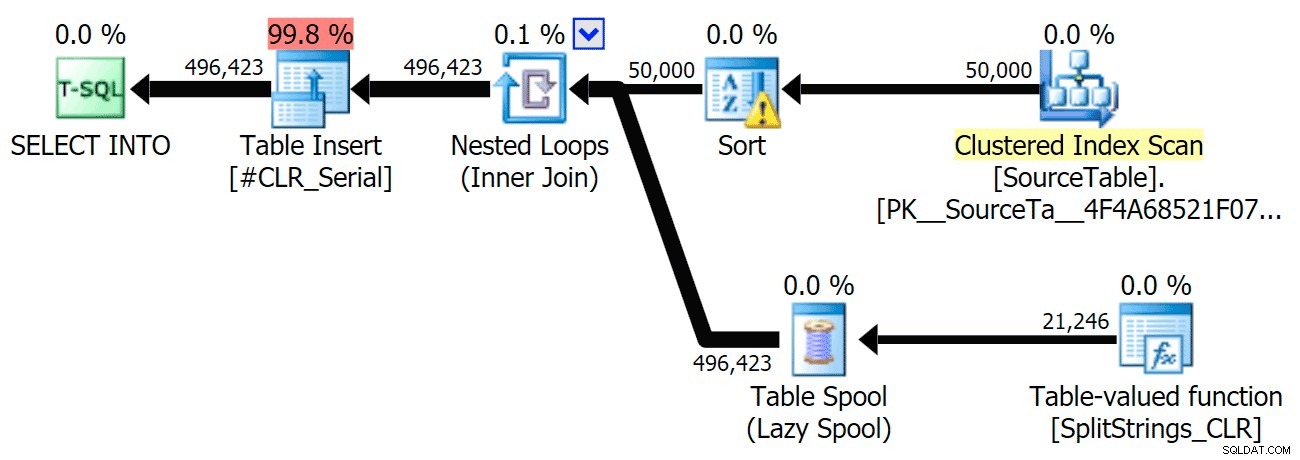
Und hier waren die neuen Dauern für alle Abfragen, die parallel mit aktiviertem TF 8690 laufen:
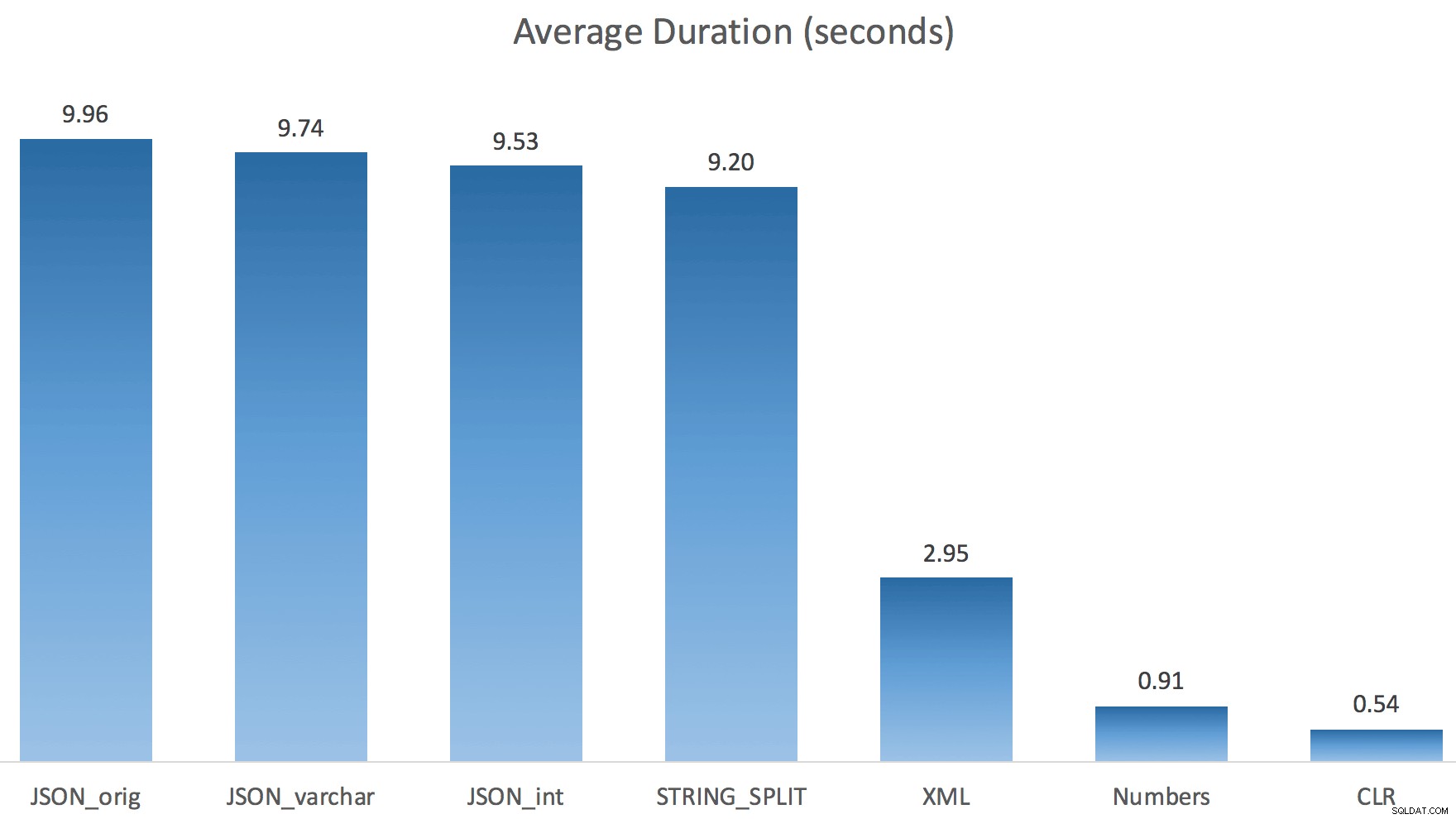
Hier ist nun der serielle CLR-Plan ohne die Spule:
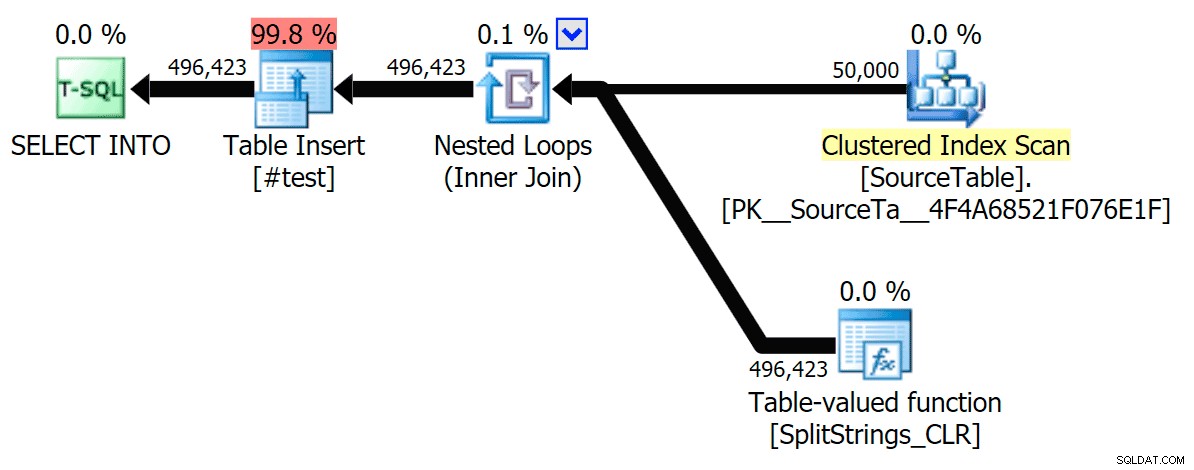
Und hier waren die Timing-Ergebnisse für Abfragen, die sowohl TF 8690 als auch MAXDOP 1 verwenden :
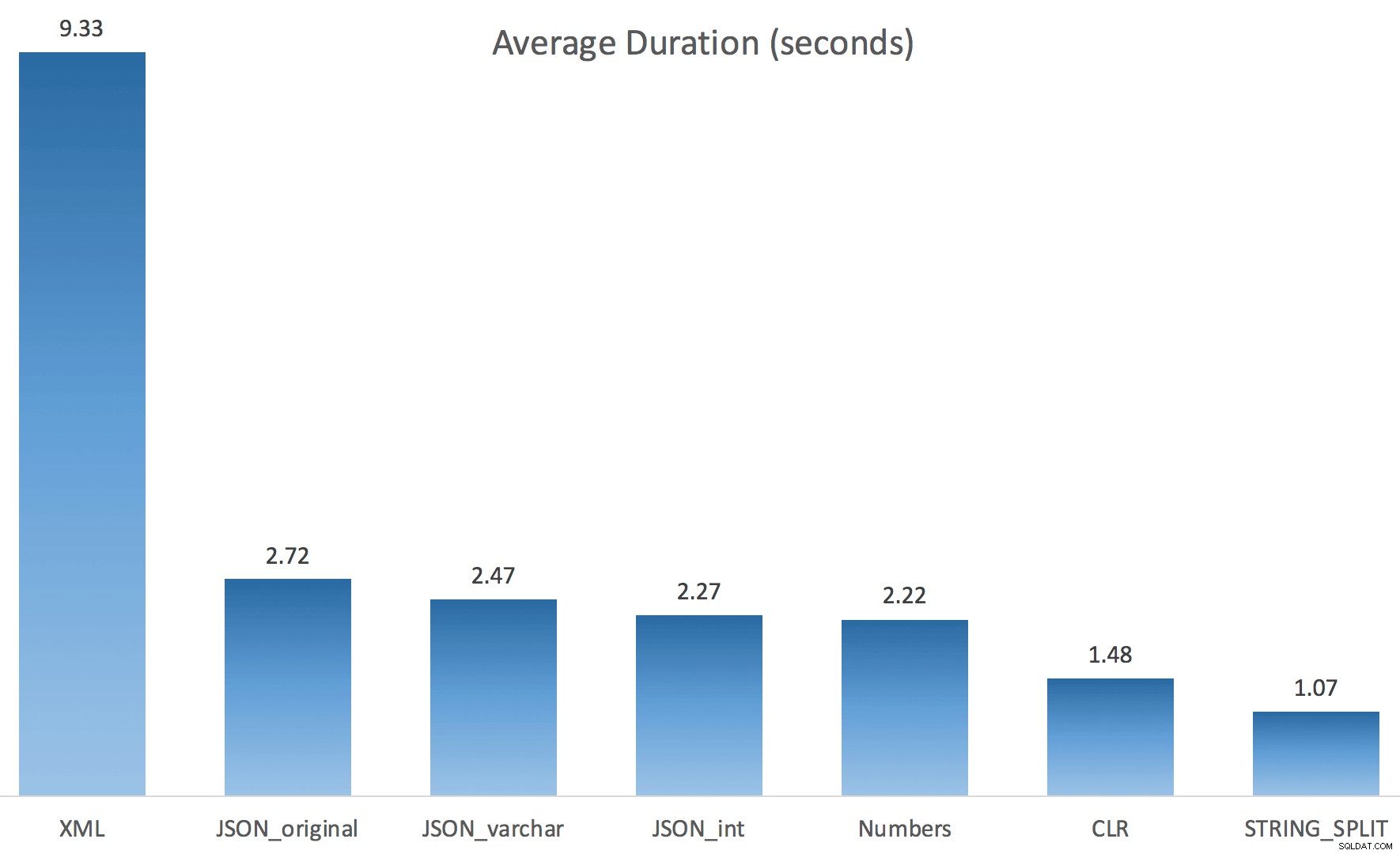
(Beachten Sie, dass sich außer dem XML-Plan die meisten anderen überhaupt nicht geändert haben, mit oder ohne Trace-Flag.)
Vergleich der geschätzten Zeilenanzahl
Dan Holmes stellte die folgende Frage:
Wie wird die Datengröße geschätzt, wenn sie mit einer anderen (oder mehreren) Teilungsfunktion verbunden wird? Der folgende Link ist eine Beschreibung einer CLR-basierten Split-Implementierung. Macht das Jahr 2016 einen „besseren“ Job mit Datenschätzungen? (Leider kann ich den RC noch nicht installieren).https://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and. html
Also habe ich den Code aus Dans Beitrag geklaut, geändert, um meine Funktionen zu verwenden, und ihn durch Plan Explorer laufen lassen:
DECLARE @s VARCHAR(MAX); SELECT * FROM dbo.SplitStrings_CLR(@s, ',') s CROSS APPLY dbo.SplitStrings_CLR(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_CLR(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_CLR(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Numbers(@s, ',') s CROSS APPLY dbo.SplitStrings_Numbers(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Numbers(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Numbers(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Native(@s, ',') s CROSS APPLY dbo.SplitStrings_Native(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Native(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Native(s2.value, '#') s3;
Der SPLIT_STRING Der Ansatz liefert sicherlich *bessere* Schätzungen als CLR, aber immer noch deutlich darüber (in diesem Fall, wenn die Zeichenfolge leer ist; dies ist möglicherweise nicht immer der Fall). Die Funktion hat einen eingebauten Standardwert, der schätzt, dass die eingehende Zeichenfolge 50 Elemente haben wird. Wenn Sie sie also verschachteln, erhalten Sie 50 x 50 (2.500); wenn Sie sie erneut verschachteln, 50 x 2.500 (125.000); und schließlich 50 x 125.000 (6.250.000):
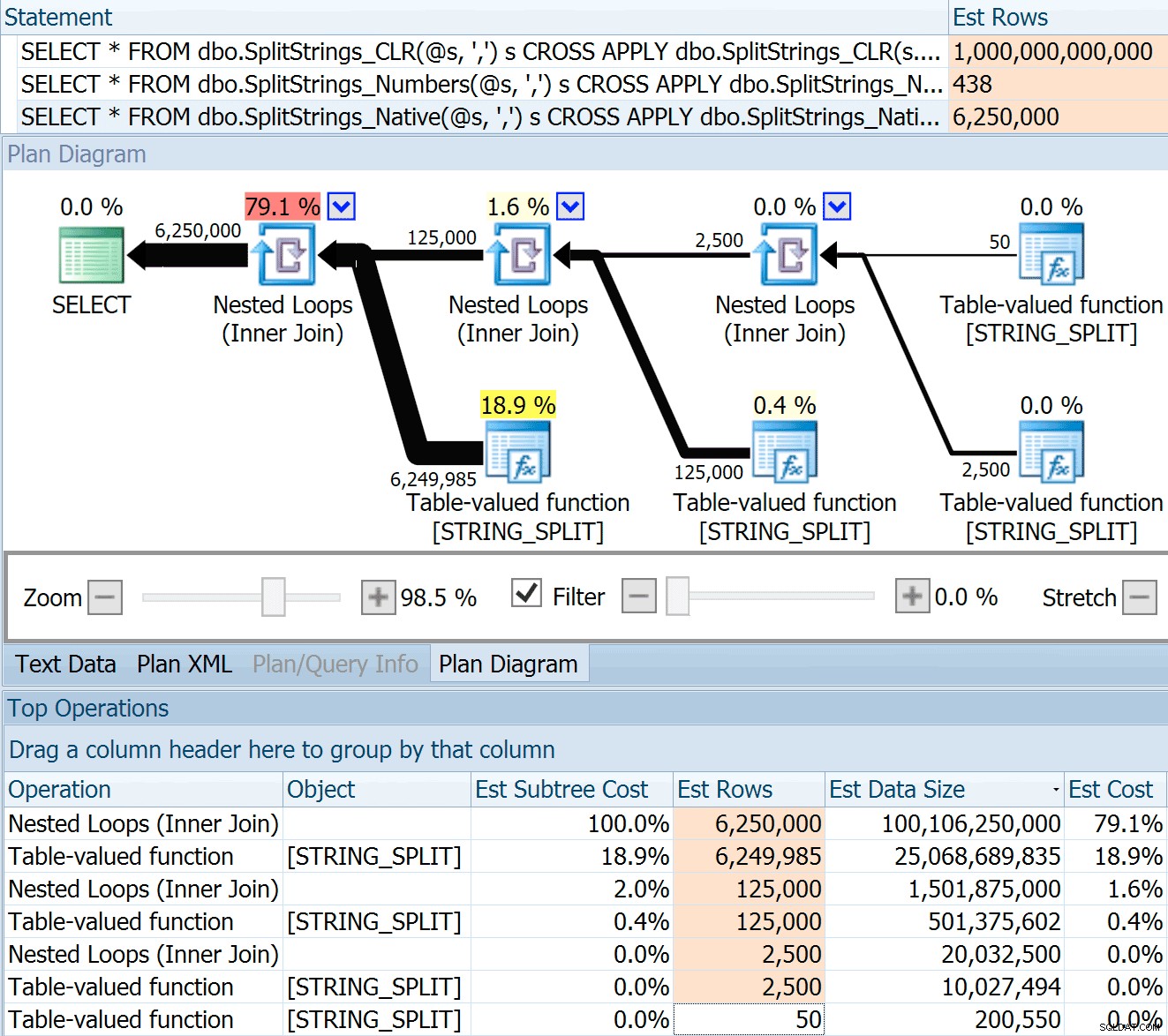
Hinweis:OPENJSON() verhält sich genauso wie STRING_SPLIT – Es wird ebenfalls davon ausgegangen, dass 50 Zeilen aus einer bestimmten Teilungsoperation stammen. Ich denke, dass es nützlich sein könnte, zusätzlich zu Trace-Flags wie 4137 (vor 2014), 9471 und 9472 (2014+) und natürlich 9481 … eine Möglichkeit zu haben, die Kardinalität für Funktionen wie diese anzuzeigen
Diese 6,25-Millionen-Zeilen-Schätzung ist nicht großartig, aber sie ist viel besser als der CLR-Ansatz, von dem Dan sprach, der EINE BILLION ZEILEN schätzt , und ich habe die Kommas zur Bestimmung der Datengröße verloren – 16 Petabyte? Exabyte?
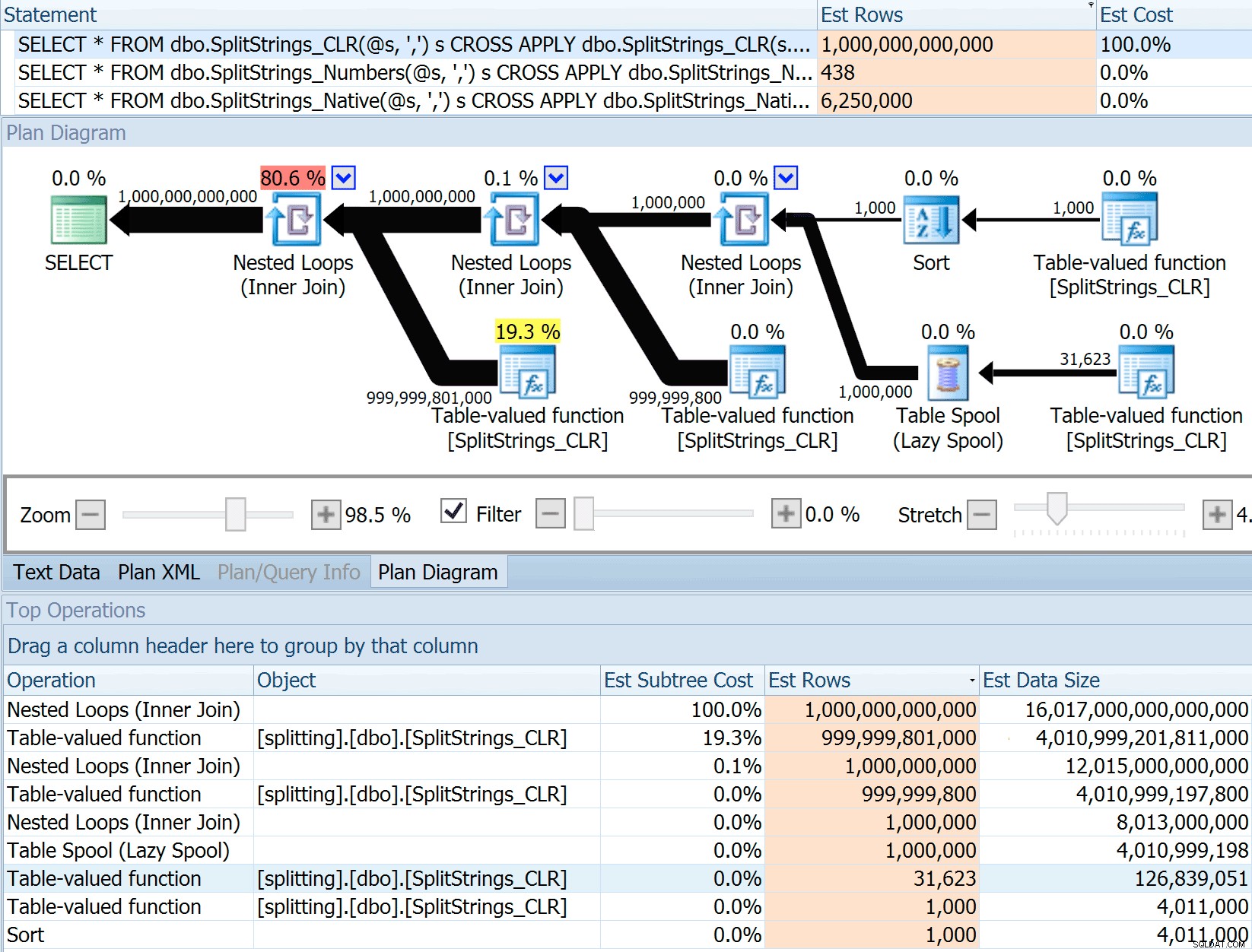
Einige der anderen Ansätze schneiden bei den Schätzungen offensichtlich besser ab. Die Numbers-Tabelle hat beispielsweise viel vernünftigere 438 Zeilen geschätzt (in SQL Server 2016 RC2). Woher kommt diese Zahl? Nun, die Tabelle enthält 8.000 Zeilen, und wenn Sie sich erinnern, hat die Funktion sowohl ein Gleichheits- als auch ein Ungleichheitsprädikat:
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter Also multipliziert SQL Server die Anzahl der Zeilen in der Tabelle mit 10 % (als Schätzung) für den Gleichheitsfilter, dann die Quadratwurzel von 30 % (wieder eine Schätzung) für den Ungleichheitsfilter. Die Quadratwurzel ist auf den exponentiellen Backoff zurückzuführen, den Paul White hier erklärt. Das gibt uns:
8000 * 0,1 * SQRT(0,3) =438,178Die XML-Variante umfasste schätzungsweise etwas mehr als eine Milliarde Zeilen (aufgrund eines Tabellenspools, der schätzungsweise 5,8 Millionen Mal ausgeführt wurde), aber ihr Plan war viel zu komplex, um ihn hier zu veranschaulichen. Denken Sie auf jeden Fall daran, dass Schätzungen natürlich nicht die ganze Geschichte erzählen – nur weil eine Abfrage genauere Schätzungen enthält, bedeutet das nicht, dass sie eine bessere Leistung erbringt.
Es gab ein paar andere Möglichkeiten, wie ich die Schätzungen ein wenig optimieren konnte:nämlich das Erzwingen des alten Kardinalitätsschätzungsmodells (das sowohl die XML- als auch die Numbers-Tabellenvariationen betraf) und die Verwendung der TFs 9471 und 9472 (die seitdem nur die Numbers-Tabellenvariation betrafen). beide kontrollieren die Kardinalität um mehrere Prädikate). Hier waren die Möglichkeiten, wie ich die Schätzungen nur ein wenig (oder SEHR) ändern konnte , im Falle einer Rückkehr zum alten CE-Modell):

Das alte CE-Modell hat die XML-Schätzungen um eine Größenordnung gesenkt, aber für die Numbers-Tabelle hat es sie komplett in die Luft gesprengt. Die Prädikat-Flags haben die Schätzungen für die Zahlentabelle geändert, aber diese Änderungen sind viel weniger interessant.
Keines dieser Trace-Flags hatte Auswirkungen auf die Schätzungen für CLR, JSON oder STRING_SPLIT Variationen.
Schlussfolgerung
Was habe ich hier gelernt? Eigentlich eine ganze Menge:
- Parallelität kann in manchen Fällen helfen, aber wenn sie nicht hilft, dann wirklich hilft nicht. Die JSON-Methoden waren ohne Parallelität ~5x schneller und
STRING_SPLITwar fast 10x schneller. - Der Spool hat tatsächlich dazu beigetragen, dass der CLR-Ansatz in diesem Fall besser funktioniert, aber TF 8690 könnte nützlich sein, um in anderen Fällen zu experimentieren, in denen Sie Spools sehen und versuchen, die Leistung zu verbessern. Ich bin mir sicher, dass es Situationen gibt, in denen das Weglassen der Spule insgesamt besser ist.
- Das Eliminieren des Spools hat dem XML-Ansatz wirklich geschadet (aber nur drastisch, wenn es gezwungen war, Single-Threaded zu sein).
- Bei Schätzungen können je nach Ansatz viele verrückte Dinge passieren, zusammen mit den üblichen Statistiken, Verteilungen und Trace-Flags. Nun, ich nehme an, das wusste ich bereits, aber hier gibt es definitiv ein paar gute, greifbare Beispiele.
Vielen Dank an die Leute, die Fragen gestellt oder mich aufgefordert haben, weitere Informationen hinzuzufügen. Und wie Sie vielleicht anhand des Titels erraten haben, gehe ich in einem zweiten Follow-up auf eine weitere Frage ein, diese über TVPs:
- STRING_SPLIT() in SQL Server 2016:Follow-up Nr. 2



