Ist es nicht großartig, eine neue Version von SQL Server verfügbar zu haben? Dies geschieht nur alle paar Jahre, und diesen Monat haben wir gesehen, wie eines die allgemeine Verfügbarkeit erreicht hat. (Ok, ich weiß, dass wir fast ständig eine neue Version von SQL-Datenbank in Azure bekommen, aber ich zähle das als anders.) In Anerkennung dieser neuen Version dreht sich der diesmonatige T-SQL-Dienstag (veranstaltet von Michael Swart – @mjswart) um alles rund um SQL Server 2016!
Ist es nicht großartig, eine neue Version von SQL Server verfügbar zu haben? Dies geschieht nur alle paar Jahre, und diesen Monat haben wir gesehen, wie eines die allgemeine Verfügbarkeit erreicht hat. (Ok, ich weiß, dass wir fast ständig eine neue Version von SQL-Datenbank in Azure bekommen, aber ich zähle das als anders.) In Anerkennung dieser neuen Version dreht sich der diesmonatige T-SQL-Dienstag (veranstaltet von Michael Swart – @mjswart) um alles rund um SQL Server 2016!
Heute möchte ich mir also die Temporal Tables-Funktion von SQL 2016 ansehen und einen Blick auf einige Abfrageplansituationen werfen, die Sie am Ende sehen könnten. Ich liebe Temporal Tables, bin aber auf ein kleines Problem gestoßen, das Sie vielleicht beachten sollten.
Obwohl SQL Server 2016 jetzt in RTM ist, verwende ich jetzt AdventureWorks2016CTP3, das Sie hier herunterladen können – aber laden Sie nicht einfach AdventureWorks2016CTP3.bak herunter , holen Sie sich auch SQLServer2016CTP3Samples.zip von derselben Seite.
Wie Sie sehen, gibt es im Samples-Archiv einige nützliche Skripts zum Ausprobieren neuer Funktionen, einschließlich einiger für Temporal Tables. Es ist eine Win-Win-Situation – Sie können eine Reihe neuer Funktionen ausprobieren, und ich muss in diesem Beitrag nicht so viel Skript wiederholen. Wie auch immer, gehen Sie und holen Sie sich die beiden Skripte über Temporal Tables, führen Sie AW 2016 CTP3 Temporal Setup.sql aus , gefolgt von Temporal System-Versioning Sample.sql .
Diese Skripte richten zeitliche Versionen einiger Tabellen ein, einschließlich HumanResources.Employee . Es erstellt HumanResources.Employee_Temporal (obwohl es technisch gesehen alles hätte heißen können). Am Ende des CREATE TABLE -Anweisung erscheint dieses Bit, das zwei verborgene Spalten hinzufügt, die verwendet werden, um anzugeben, wann die Zeile gültig ist, und angibt, dass eine Tabelle mit dem Namen HumanResources.Employee_Temporal_History erstellt werden soll um die alten Versionen zu speichern.
... ValidFrom datetime2(7) GENERATED ALWAYS AS ROW START HIDDEN NOT NULL, ValidTo datetime2(7) GENERATED ALWAYS AS ROW END HIDDEN NOT NULL, PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo) ) WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = [HumanResources].[Employee_Temporal_History]) );
In diesem Beitrag möchte ich untersuchen, was mit Abfrageplänen passiert, wenn der Verlauf verwendet wird.
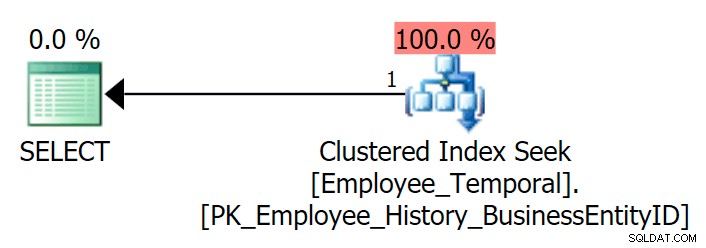
Wenn ich die Tabelle abfrage, um die neueste Zeile für eine bestimmte BusinessEntityID anzuzeigen , erhalte ich wie erwartet einen Clustered Index Seek.
SELECT e.BusinessEntityID, e.ValidFrom, e.ValidTo FROM HumanResources.Employee_Temporal AS e WHERE e.BusinessEntityID = 4;
Ich bin sicher, ich könnte diese Tabelle mit anderen Indizes abfragen, falls vorhanden. Aber in diesem Fall nicht. Lassen Sie uns eine erstellen.
CREATE UNIQUE INDEX rf_ix_Login on HumanResources.Employee_Temporal(LoginID);
Jetzt kann ich die Tabelle nach LoginID abfragen , und es wird eine Schlüsselsuche angezeigt, wenn ich nach anderen Spalten als Loginid frage oder BusinessEntityID . Nichts davon ist überraschend.
SELECT * FROM HumanResources.Employee_Temporal e WHERE e.LoginID = N'adventure-works\rob0';
Lassen Sie uns für eine Minute SQL Server Management Studio verwenden und uns ansehen, wie diese Tabelle im Objekt-Explorer aussieht.

Wir können die unter HumanResources.Employee_Temporal erwähnte Verlaufstabelle sehen , und die Spalten und Indizes sowohl aus der Tabelle selbst als auch aus der Verlaufstabelle. Aber während die Indizes auf der richtigen Tabelle der Primärschlüssel sind (auf BusinessEntityID ) und dem Index, den ich gerade erstellt hatte, hat die Verlaufstabelle keine übereinstimmenden Indizes.
Der Index der Verlaufstabelle ist auf ValidTo und ValidFrom . Wir können mit der rechten Maustaste auf den Index klicken und Eigenschaften auswählen, und wir sehen diesen Dialog:
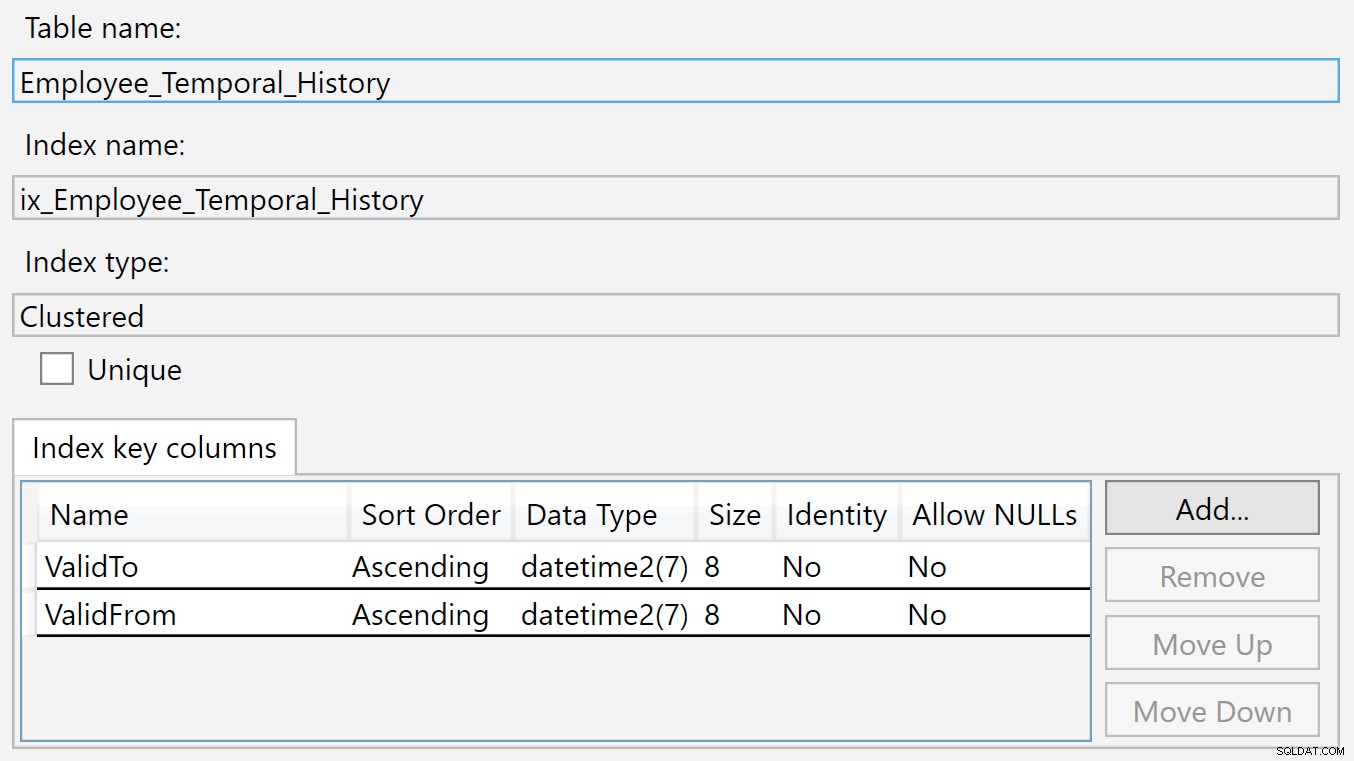
In diese History-Tabelle wird eine neue Zeile eingefügt, wenn sie in der Haupttabelle nicht mehr gültig ist, weil sie gerade gelöscht oder geändert wurde. Die Werte in ValidTo Spalte werden natürlich mit der aktuellen Uhrzeit gefüllt, also ValidTo fungiert als aufsteigender Schlüssel, wie eine Identitätsspalte, sodass neue Einfügungen am Ende der B-Baumstruktur erscheinen.
Aber wie funktioniert das, wenn Sie die Tabelle abfragen möchten?
Wenn wir unsere Tabelle danach abfragen wollen, was zu einem bestimmten Zeitpunkt aktuell war, dann sollten wir eine Abfragestruktur verwenden wie:
SELECT * FROM HumanResources.Employee_Temporal FOR SYSTEM_TIME AS OF '20160612 11:22';
Diese Abfrage muss die entsprechenden Zeilen aus der Haupttabelle mit den entsprechenden Zeilen aus der Verlaufstabelle verketten.
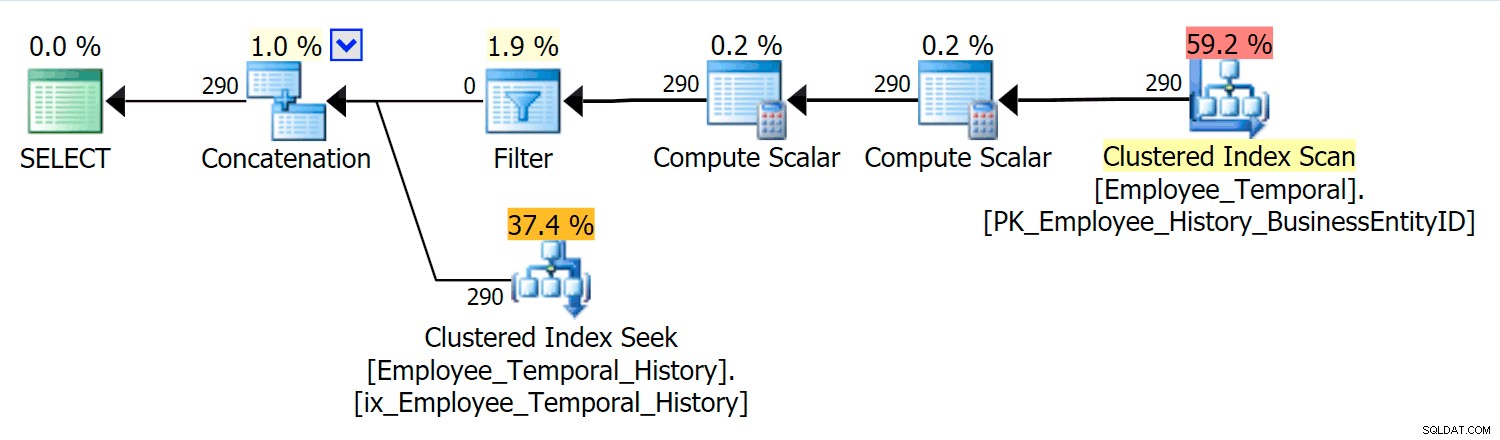
In diesem Szenario stammten die Zeilen, die für den von mir ausgewählten Moment gültig waren, alle aus der Verlaufstabelle, aber wir sehen trotzdem einen Clustered Index Scan gegen die Haupttabelle, die durch einen Filteroperator gefiltert wurde. Das Prädikat dieses Filters ist:
[HumanResources].[Employee_Temporal].[ValidFrom] <= '2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal].[ValidTo] > '2016-06-12 11:22:00.0000000'
Lassen Sie uns gleich darauf zurückkommen.
Die Clustered-Index-Suche in der Verlaufstabelle muss eindeutig ein Seek-Prädikat für ValidTo nutzen. Der Beginn des Bereichsscans von Seek ist HumanResources.Employee_Temporal_History.ValidTo > Skalaroperator('2016-06-12 11:22:00') , aber es gibt kein End, weil jede Zeile, die ein ValidTo hat nach der Zeit, die uns wichtig ist, ist eine Kandidatenzeile und muss auf ein geeignetes ValidFrom getestet werden Wert durch das Restprädikat, das HumanResources.Employee_Temporal_History.ValidFrom ist <= '2016-06-12 11:22:00' .
Jetzt sind Intervalle schwer zu indizieren; das ist eine bekannte Sache, die in vielen Blogs diskutiert wurde. Die meisten effektiven Lösungen ziehen kreative Möglichkeiten zum Schreiben von Abfragen in Betracht, aber in Temporal Tables wurden keine derartigen Smarts eingebaut. Sie können jedoch auch Indizes auf andere Spalten setzen, z. B. auf ValidFrom, oder sogar Indizes haben, die den Abfragetypen entsprechen, die Sie möglicherweise in der Haupttabelle haben. Mit einem gruppierten Index, der ein zusammengesetzter Schlüssel auf beiden ValidTo ist und ValidFrom , werden diese beiden Spalten in jede andere Spalte aufgenommen, was eine gute Gelegenheit für einige Residual Predicate-Tests bietet.
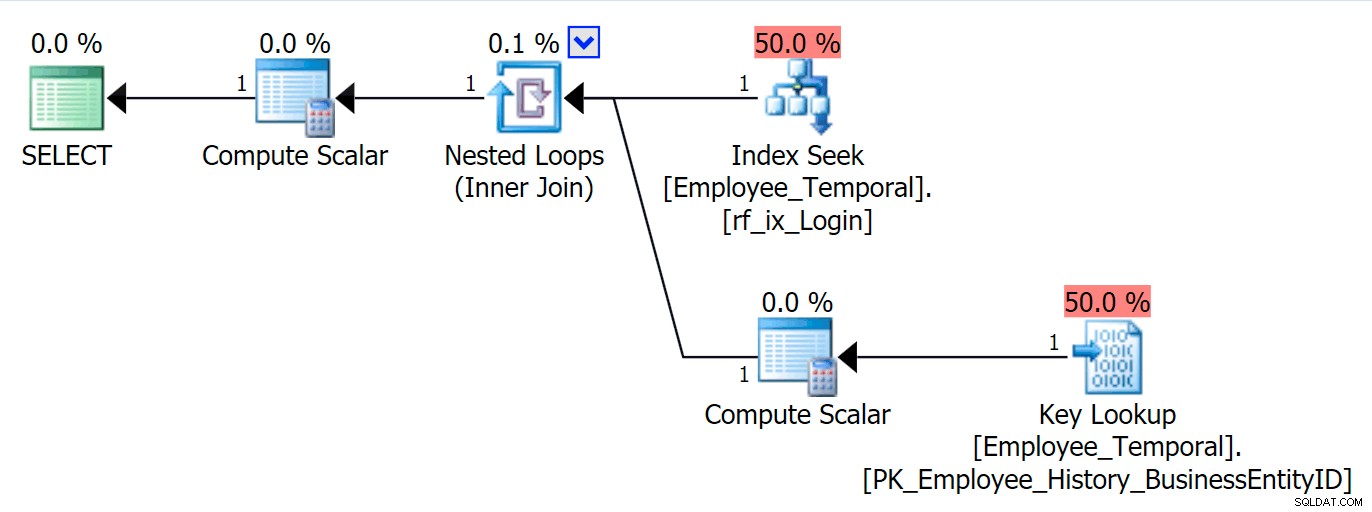
Wenn ich weiß, an welcher Login-ID ich interessiert bin, hat mein Plan eine andere Form.
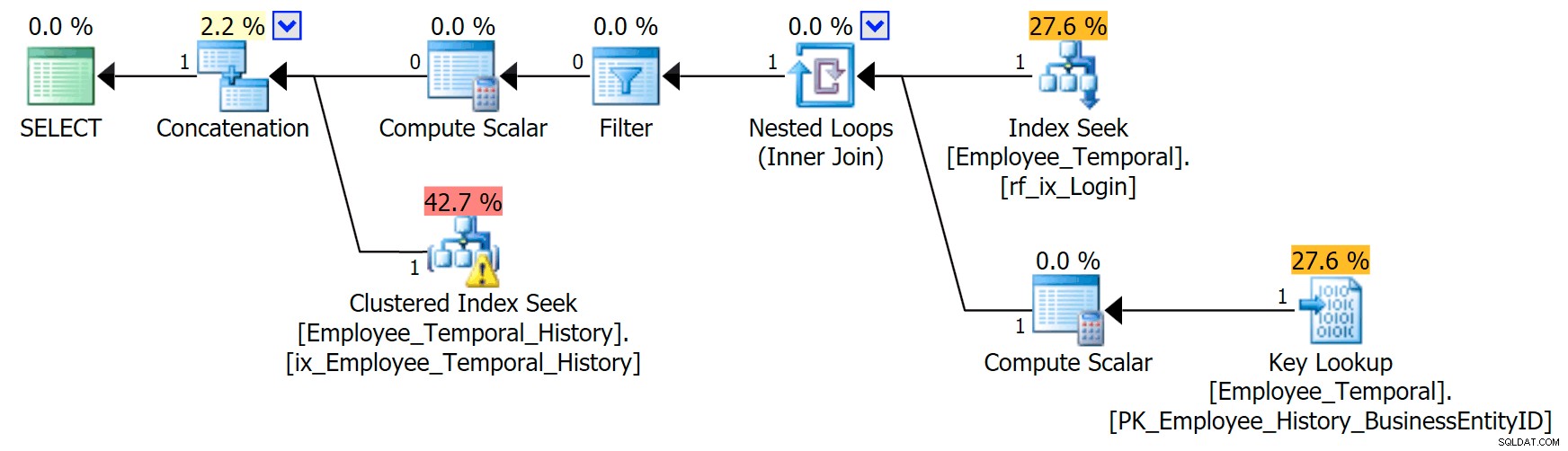
Der obere Zweig des Concatenation-Operators sieht ähnlich aus wie zuvor, obwohl dieser Filter-Operator in den Kampf eingetreten ist, um alle ungültigen Zeilen zu entfernen, aber der Clustered Index Seek im unteren Zweig hat eine Warnung. Dies ist eine Restprädikat-Warnung, wie die Beispiele in einem früheren Beitrag von mir. Es ist in der Lage, nach Einträgen zu filtern, die bis zu einem bestimmten Zeitpunkt nach der uns interessierenden Zeit gültig sind, aber das Residual Predicate filtert jetzt nach der LoginID sowie ValidFrom .
[HumanResources].[Employee_Temporal_History].[ValidFrom] <= '2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal_History].[LoginID] = N'adventure-works\rob0'
Änderungen an den Zeilen von rob0 werden nur einen winzigen Teil der Zeilen im Verlauf ausmachen. Diese Spalte ist nicht eindeutig wie in der Haupttabelle, da die Zeile möglicherweise mehrmals geändert wurde, aber es gibt immer noch einen guten Kandidaten für die Indizierung.
CREATE INDEX rf_ixHist_loginid ON HumanResources.Employee_Temporal_History(LoginID);
Dieser neue Index hat erhebliche Auswirkungen auf unseren Plan.
Es hat jetzt unseren Clustered Index Seek in einen Clustered Index Scan geändert!!
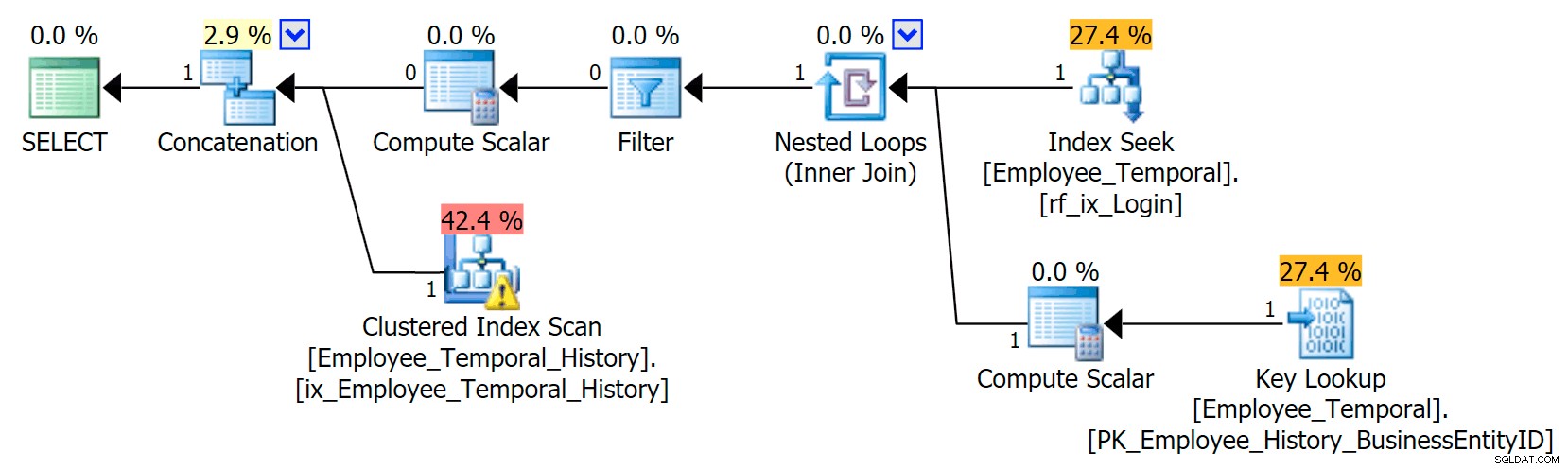
Sie sehen, der Abfrageoptimierer hat jetzt herausgefunden, dass es am besten wäre, den neuen Index zu verwenden. Aber es entscheidet auch, dass der Aufwand, Suchvorgänge durchführen zu müssen, um alle anderen Spalten zu erhalten (weil ich nach allen Spalten gefragt habe), einfach zu viel Arbeit wäre. Der Wendepunkt wurde erreicht (in diesem Fall leider eine falsche Annahme) und stattdessen ein Clustered Index SCAN gewählt. Auch wenn ohne den Non-Clustered-Index die beste Option gewesen wäre, eine Clustered-Index-Suche zu verwenden, entscheidet er sich für den Scan, wenn der Non-Clustered-Index berücksichtigt und aus Gründen des Wendepunkts abgelehnt wurde.
Frustrierenderweise habe ich diesen Index gerade erst erstellt und seine Statistiken sollten gut sein. Es sollte wissen, dass ein Seek, der genau eine Suche erfordert, besser sein sollte als ein Clustered Index Scan (nur nach Statistik – wenn Sie dachten, es sollte dies wissen, weil LoginID in der Haupttabelle eindeutig ist, denken Sie daran, dass dies möglicherweise nicht immer der Fall war). Daher vermute ich, dass Nachschlagen in Verlaufstabellen vermieden werden sollte, obwohl ich das noch nicht ausreichend erforscht habe.
Wenn wir jetzt nur Spalten abfragen würden, die in unserem nicht gruppierten Index erscheinen, würden wir ein viel besseres Verhalten erhalten. Jetzt, da keine Suche erforderlich ist, wird unser neuer Index für die Verlaufstabelle gerne verwendet. Es muss immer noch ein Residual Predicate angewendet werden, basierend darauf, dass nur nach LoginID gefiltert werden kann und ValidTo , aber es verhält sich viel besser, als in einen Clustered Index Scan zu fallen.
SELECT LoginID, ValidFrom, ValidTo FROM HumanResources.Employee_Temporal FOR SYSTEM_TIME AS OF '20160612 11:22' WHERE LoginID = N'adventure-works\rob0'
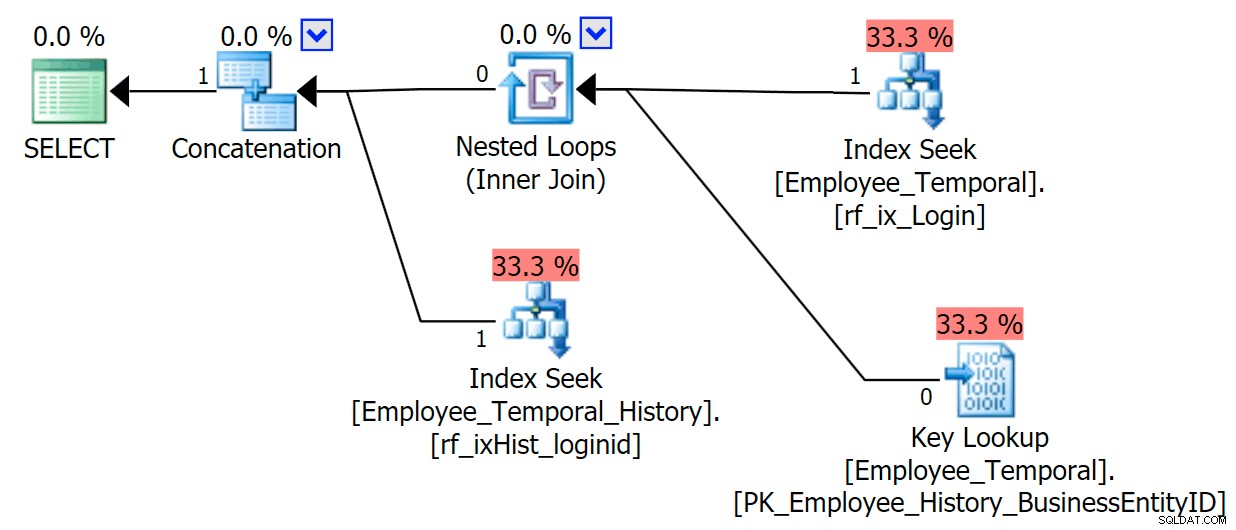
Indizieren Sie Ihre Verlaufstabellen also auf zusätzliche Weise, je nachdem, wie Sie sie abfragen werden. Schließen Sie die erforderlichen Spalten ein, um Suchvorgänge zu vermeiden, da Sie wirklich Scans vermeiden.
Diese Verlaufstabellen können sehr umfangreich werden, wenn sich Daten häufig ändern. Achten Sie also darauf, wie sie behandelt werden. Dieselbe Situation tritt auf, wenn der andere FOR SYSTEM_TIME verwendet wird Konstrukte, daher sollten Sie (wie immer) die Pläne überprüfen, die Ihre Abfragen produzieren, und indizieren, um sicherzustellen, dass Sie gut positioniert sind, um diese sehr leistungsstarke Funktion von SQL Server 2016 zu nutzen.