Wie jeder erfahrene Produktions-DBA weiß, stehen Sie oft unter erheblichem Druck, Probleme mit der Datenbankleistung so schnell wie möglich zu diagnostizieren und zu beheben. Hier sind drei Dinge, die Sie je nach Workload und Infrastruktur nutzen können, um sich deutlich positiv auf die Leistung Ihrer Datenbank auszuwirken.
Grundlegende Zeilenspeicher-Indexoptimierung
Bei den meisten SQL Server-Instanzen, denen ich in meiner Karriere begegnet bin, gab es einige relativ einfache Möglichkeiten zur Optimierung des Zeilenspeicherindex. Eine nette Sache beim Row Store Index Tuning ist, dass es häufiger unter Ihrer direkten Kontrolle als DBA liegt, insbesondere im Vergleich zum Tuning von Abfragen oder gespeicherten Prozeduren, die oft unter der Kontrolle von Entwicklern oder Drittanbietern stehen.
Einige DBAs zögern, eine Indexoptimierung vorzunehmen (insbesondere bei Datenbanken von Drittanbietern), weil sie befürchten, etwas kaputt zu machen oder den Anbietersupport für die Datenbank oder Anwendung zu gefährden. Offensichtlich müssen Sie bei Datenbanken von Drittanbietern vorsichtiger sein und versuchen, den Anbieter zu erreichen, bevor Sie selbst Indexänderungen vornehmen, aber in manchen Situationen haben Sie möglicherweise keine andere praktikable Alternative (außer schnellere Hardware und Speicher auf das Problem zu werfen). ).
Sie können ein paar Schlüsselabfragen von meinen SQL Server-Diagnoseinformationsabfragen ausführen, um eine gute Vorstellung davon zu bekommen, ob Sie möglicherweise einige einfache Indexoptimierungsmöglichkeiten für Ihre Instanz oder Datenbank haben. Sie sollten nach fehlenden Indexanforderungen, fehlenden Indexwarnungen, zu wenig oder nicht verwendeten nicht geclusterten Indizes und möglichen Möglichkeiten zur Datenkomprimierung Ausschau halten.
Es erfordert etwas Erfahrung, gutes Urteilsvermögen und Kenntnisse Ihrer Arbeitsbelastung, um eine ordnungsgemäße Indexoptimierung durchzuführen. Es kommt nur allzu häufig vor, dass Menschen eine falsche Indexabstimmung vornehmen, indem sie vorschnell viele Indexänderungen vornehmen, ohne die richtige Analyse durchzuführen.
Hier sind einige Abfragen, die ich gerne auf Datenbankebene verwende:
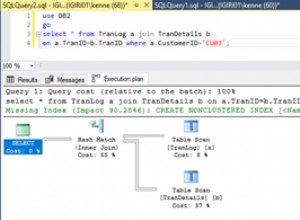
-- Missing Indexes for current database by Index Advantage (Query 1) (Missing Indexes)
SELECT DISTINCT CONVERT(decimal(18,2), user_seeks * avg_total_user_cost * (avg_user_impact * 0.01)) AS [index_advantage],
migs.last_user_seek, mid.[statement] AS [Database.Schema.Table],
mid.equality_columns, mid.inequality_columns, mid.included_columns,
migs.unique_compiles, migs.user_seeks, migs.avg_total_user_cost, migs.avg_user_impact,
OBJECT_NAME(mid.[object_id]) AS [Table Name], p.rows AS [Table Rows]
FROM sys.dm_db_missing_index_group_stats AS migs WITH (NOLOCK)
INNER JOIN sys.dm_db_missing_index_groups AS mig WITH (NOLOCK)
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid WITH (NOLOCK)
ON mig.index_handle = mid.index_handle
INNER JOIN sys.partitions AS p WITH (NOLOCK)
ON p.[object_id] = mid.[object_id]
WHERE mid.database_id = DB_ID()
AND p.index_id < 2
ORDER BY index_advantage DESC OPTION (RECOMPILE);
------
-- Look at index advantage, last user seek time, number of user seeks to help determine source and importance
-- SQL Server is overly eager to add included columns, so beware
-- Do not just blindly add indexes that show up from this query!!!
-- Find missing index warnings for cached plans in the current database (Query 2) (Missing Index Warnings)
-- Note: This query could take some time on a busy instance
SELECT TOP(25) OBJECT_NAME(objectid) AS [ObjectName],
cp.objtype, cp.usecounts, cp.size_in_bytes, query_plan
FROM sys.dm_exec_cached_plans AS cp WITH (NOLOCK)
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp
WHERE CAST(query_plan AS NVARCHAR(MAX)) LIKE N'%MissingIndex%'
AND dbid = DB_ID()
ORDER BY cp.usecounts DESC OPTION (RECOMPILE);
------
-- Helps you connect missing indexes to specific stored procedures or queries
-- This can help you decide whether to add them or not
-- Possible Bad NC Indexes (writes >= reads) (Query 3) (Bad NC Indexes)
SELECT OBJECT_NAME(s.[object_id]) AS [Table Name], i.name AS [Index Name], i.index_id,
i.is_disabled, i.is_hypothetical, i.has_filter, i.fill_factor,
s.user_updates AS [Total Writes], s.user_seeks + s.user_scans + s.user_lookups AS [Total Reads],
s.user_updates - (s.user_seeks + s.user_scans + s.user_lookups) AS [Difference]
FROM sys.dm_db_index_usage_stats AS s WITH (NOLOCK)
INNER JOIN sys.indexes AS i WITH (NOLOCK)
ON s.[object_id] = i.[object_id]
AND i.index_id = s.index_id
WHERE OBJECTPROPERTY(s.[object_id],'IsUserTable') = 1
AND s.database_id = DB_ID()
AND s.user_updates > (s.user_seeks + s.user_scans + s.user_lookups)
AND i.index_id > 1 AND i.[type_desc] = N'NONCLUSTERED'
AND i.is_primary_key = 0 AND i.is_unique_constraint = 0 AND i.is_unique = 0
ORDER BY [Difference] DESC, [Total Writes] DESC, [Total Reads] ASC OPTION (RECOMPILE);
------
-- Look for indexes with high numbers of writes and zero or very low numbers of reads
-- Consider your complete workload, and how long your instance has been running
-- Investigate further before dropping an index!
-- Breaks down buffers used by current database by object (table, index) in the buffer cache (Query 4) (Buffer Usage)
-- Note: This query could take some time on a busy instance
SELECT OBJECT_NAME(p.[object_id]) AS [Object Name], p.index_id,
CAST(COUNT(*)/128.0 AS DECIMAL(10, 2)) AS [Buffer size(MB)],
COUNT(*) AS [BufferCount], p.[Rows] AS [Row Count],
p.data_compression_desc AS [Compression Type]
FROM sys.allocation_units AS a WITH (NOLOCK)
INNER JOIN sys.dm_os_buffer_descriptors AS b WITH (NOLOCK)
ON a.allocation_unit_id = b.allocation_unit_id
INNER JOIN sys.partitions AS p WITH (NOLOCK)
ON a.container_id = p.hobt_id
WHERE b.database_id = CONVERT(int, DB_ID())
AND p.[object_id] > 100
AND OBJECT_NAME(p.[object_id]) NOT LIKE N'plan_%'
AND OBJECT_NAME(p.[object_id]) NOT LIKE N'sys%'
AND OBJECT_NAME(p.[object_id]) NOT LIKE N'xml_index_nodes%'
GROUP BY p.[object_id], p.index_id, p.data_compression_desc, p.[Rows]
ORDER BY [BufferCount] DESC OPTION (RECOMPILE);
------
-- Tells you what tables and indexes are using the most memory in the buffer cache
-- It can help identify possible candidates for data compression Verzögerte Haltbarkeit verwenden
Die verzögerte Haltbarkeitsfunktion wurde dem Produkt in SQL Server 2014 hinzugefügt, sodass sie schon seit geraumer Zeit verfügbar ist. Verzögerte dauerhafte Transaktionsfestschreibungen sind asynchron und melden eine Transaktionsfestschreibung als erfolgreich vorher die Protokolldatensätze für die Transaktion werden tatsächlich in das Speichersubsystem geschrieben. Verzögerte dauerhafte Transaktionen werden nicht wirklich dauerhaft, bis die Transaktionsprotokolleinträge auf die Festplatte geleert werden.
Dieses Feature ist in allen Editionen von SQL Server verfügbar. Trotzdem sehe ich selten, dass es verwendet wird, wenn ich mir Kundendatenbanken ansehe. Verzögerte Haltbarkeit eröffnet die Möglichkeit eines gewissen Datenverlusts, im schlimmsten Fall bis hin zu einem ganzen Protokollpuffer (wie von Paul Randal hier erklärt), daher ist es definitiv nicht für ein RPO-Szenario geeignet, bei dem absolut kein Datenverlust akzeptabel ist.
Die verzögerte Dauerhaftigkeit reduziert die Transaktionslatenz, da nicht darauf gewartet wird, dass die Protokoll-E/A beendet und die Kontrolle an den Client zurückgegeben wird, und sie reduziert auch Sperren und Festplattenkonflikte für gleichzeitige Transaktionen. Diese beiden Vorteile können sich oft sehr positiv auf Ihre Abfrage- und Anwendungsleistung mit der entsprechenden sehr schreibintensiven Arbeitslast auswirken.
Verzögerte Haltbarkeit hilft meistens bei schweren OLTP-Arbeitslasten mit sehr häufigen, kleinen Schreibtransaktionen, bei denen Sie eine hohe Schreiblatenz auf Dateiebene von sys.dm_io_virtual_file_stats in der Transaktionsprotokolldatei und/oder hohe WRITELOG-Wartezeiten von sys sehen. dm_os_wait_stats.
Sie können SQL Server 2014 oder neuer ganz einfach dazu zwingen, verzögerte Dauerhaftigkeit für alle Transaktionen (ohne Codeänderungen) zu verwenden, indem Sie den folgenden Befehl ausführen:
ALTER DATABASE AdventureWorks2014 SET DELAYED_DURABILITY = FORCED;
Ich hatte Kunden, die die verzögerte Dauerhaftigkeit programmgesteuert zu verschiedenen Tageszeiten ein- und ausschalten (z. B. während geplanter ETL- oder Wartungsaktivitäten). Ich hatte auch Kunden, die jederzeit verzögerte Haltbarkeit verwenden, da sie eine angemessene Arbeitsbelastung und Risikotoleranz für Datenverlust haben.
Schließlich hatte ich Kunden, die nie in Betracht gezogen hätten, eine verzögerte Haltbarkeit zu verwenden, oder die sie bei ihrer Arbeitsbelastung einfach nicht brauchten. Wenn Sie vermuten, dass Ihre Arbeitslast möglicherweise von der Verwendung der verzögerten Haltbarkeit profitieren, aber Sie sind besorgt über den möglichen Datenverlust, dann gibt es andere Alternativen, die Sie in Betracht ziehen können.
Eine Alternative ist die Pufferfunktion für persistente Protokolle in SQL Server 2016 SP1, mit der Sie eine zweite 20-MB-Transaktionsprotokolldatei auf einem DAX-Speichervolume (Direct Access Mode) erstellen können, das auf einem persistenten NV-DIMM-Speichergerät gehostet wird. Diese zusätzliche Transaktionsprotokolldatei wird verwendet, um das Ende des Protokolls zwischenzuspeichern, mit Zugriff auf Byteebene, der den herkömmlichen Speicherstapel auf Blockebene umgeht.
Wenn Sie der Meinung sind, dass Ihre Workload von der Verwendung des persistenten Protokollpuffers profitieren könnte, können Sie mit der vorübergehenden Verwendung der verzögerten Dauerhaftigkeit experimentieren, um zu sehen, ob es einen tatsächlichen Leistungsvorteil bei Ihrer Workload gibt, bevor Sie das Geld für den persistenten NV-DIMM-Speicher ausgeben müsste die dauerhafte Protokollpufferfunktion verwenden.
Tempdb auf Intel Optane DC P4800X Storage verschieben
Ich hatte großen Erfolg mit mehreren kürzlich erschienenen Kunden, die ihre tempdb-Datenbankdateien von einem anderen Speichertyp auf ein logisches Laufwerk verschoben haben, das von einigen Intel Optane DC P4800X PCIe NVMe-Speicherkarten (in einem Software-RAID-1-Array) unterstützt wurde.
Diese Speicherkarten sind mit Kapazitäten von 375 GB, 750 GB und 1,5 TB erhältlich (obwohl die Kapazität von 1,5 TB brandneu und immer noch schwer zu finden ist). Sie haben eine extrem niedrige Latenz (viel niedriger als jede Art von NAND-Flash-Speicher), eine hervorragende Random-I/O-Leistung bei geringer Warteschlangentiefe (viel besser als NAND-Flash-Speicher) mit konsistenten Lesereaktionszeiten bei sehr hoher Schreiblast. P>
Sie haben auch eine höhere Schreiblebensdauer als „schreibintensive“ Enterprise-NAND-Flash-Speicher, und ihre Leistung verschlechtert sich nicht, da sie fast voll sind. Aufgrund dieser Eigenschaften eignen sich diese Karten hervorragend für viele schwere tempdb-Arbeitslasten, insbesondere schwere OLTP-Arbeitslasten und Situationen, in denen Sie RCSI in Ihren Benutzerdatenbanken verwenden (wodurch die resultierende Versionsspeicher-Arbeitslast auf tempdb lastet).
Es ist auch sehr üblich, eine hohe Schreiblatenz auf Dateiebene bei tempdb-Datendateien aus der DMV sys.dm_io_virtual_file_stats zu sehen, sodass das Verschieben Ihrer tempdb-Datendateien in den Optane-Speicher eine Möglichkeit ist, dieses Problem direkt anzugehen, was möglicherweise schneller und einfacher als herkömmliche ist Workload-Tuning.
Eine weitere mögliche Verwendung für Optane-Speicherkarten ist die Speicherung Ihrer Transaktionsprotokolldatei(en). Sie können Optane-Speicher auch mit Legacy-Versionen von SQL Server verwenden (sofern Ihr Betriebssystem und Ihre Hardware dies unterstützen). Dies ist eine mögliche Alternative zur Verwendung von verzögerter Dauerhaftigkeit (für die SQL Server 2014 erforderlich ist) oder zur Verwendung der dauerhaften Protokollpufferfunktion (für die SQL Server 2016 SP1 erforderlich ist).
Schlussfolgerung
Ich habe drei Techniken besprochen, um mit SQL Server einen schnellen Leistungsgewinn zu erzielen:
- Konventionelles Row-Store-Index-Tuning gilt für alle Versionen von SQL Server und ist eines der besten Tools in Ihrem Arsenal.
- Verzögerte Dauerhaftigkeit ist in SQL Server 2014 und höher verfügbar und kann bei einigen Workload-Typen (und RPO-Anforderungen) sehr vorteilhaft sein. Der persistente Protokollpuffer ist in SQL Server 2016 SP1 verfügbar und bietet ähnliche Vorteile wie eine verzögerte Dauerhaftigkeit, ohne die Gefahr eines Datenverlusts.
- Das Verschieben bestimmter Arten von Datenbankdateien in den Intel Optane-Speicher kann dazu beitragen, Leistungsprobleme mit tempdb oder mit Transaktionsprotokolldateien der Benutzerdatenbank zu verringern. Sie können Optane-Speicher mit Legacy-Versionen von SQL Server verwenden, und es sind keine Code- oder Konfigurationsänderungen erforderlich.