Skalare UDFs waren schon immer ein zweischneidiges Schwert – sie sind großartig für Entwickler, die langweilige Logik abstrahieren müssen, anstatt sie in ihren Abfragen zu wiederholen, aber sie sind schrecklich für die Laufzeitleistung in der Produktion, weil der Optimierer dies nicht tut. nicht gut mit ihnen umgehen. Im Wesentlichen passiert, dass die UDF-Ausführungen vom Rest des Ausführungsplans getrennt gehalten werden und daher einmal für jede Zeile aufgerufen werden und nicht basierend auf der geschätzten oder tatsächlichen Anzahl von Zeilen optimiert oder in den Rest des Plans gefaltet werden können.
Da wir trotz unserer Bemühungen seit SQL Server 2000 die Verwendung von skalaren UDFs nicht effektiv verhindern können, wäre es nicht toll, wenn SQL Server sie einfach besser handhaben könnte?
SQL Server 2019 führt ein neues Feature namens Scalar UDF Inlining ein. Anstatt die Funktion getrennt zu halten, wird sie in den Gesamtplan integriert. Dies führt zu einem viel besseren Ausführungsplan und damit zu einer besseren Laufzeitleistung.
Um die Ursache des Problems besser zu veranschaulichen, beginnen wir jedoch zunächst mit einem Paar einfacher Tabellen mit nur wenigen Zeilen in einer Datenbank, die auf SQL Server 2017 (oder auf 2019, aber mit einem niedrigeren Kompatibilitätsgrad) ausgeführt wird:
CREATE DATABASE Whatever; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 140; GO USE Whatever; GO CREATE TABLE dbo.Languages ( LanguageID int PRIMARY KEY, Name sysname ); CREATE TABLE dbo.Employees ( EmployeeID int PRIMARY KEY, LanguageID int NOT NULL FOREIGN KEY REFERENCES dbo.Languages(LanguageID) ); INSERT dbo.Languages(LanguageID, Name) VALUES(1033, N'English'), (45555, N'Klingon'); INSERT dbo.Employees(EmployeeID, LanguageID) SELECT [object_id], CASE ABS([object_id]%2) WHEN 1 THEN 1033 ELSE 45555 END FROM sys.all_objects;
Jetzt haben wir eine einfache Abfrage, in der wir jeden Mitarbeiter und den Namen seiner Hauptsprache anzeigen möchten. Angenommen, diese Abfrage wird an vielen Stellen und/oder auf unterschiedliche Weise verwendet. Anstatt also einen Join in die Abfrage einzubauen, schreiben wir eine skalare UDF, um diesen Join wegzuabstraktieren:
CREATE FUNCTION dbo.GetLanguage(@id int) RETURNS sysname AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END
Dann sieht unsere eigentliche Abfrage etwa so aus:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Wenn wir uns den Ausführungsplan für die Abfrage ansehen, fehlt seltsamerweise etwas:
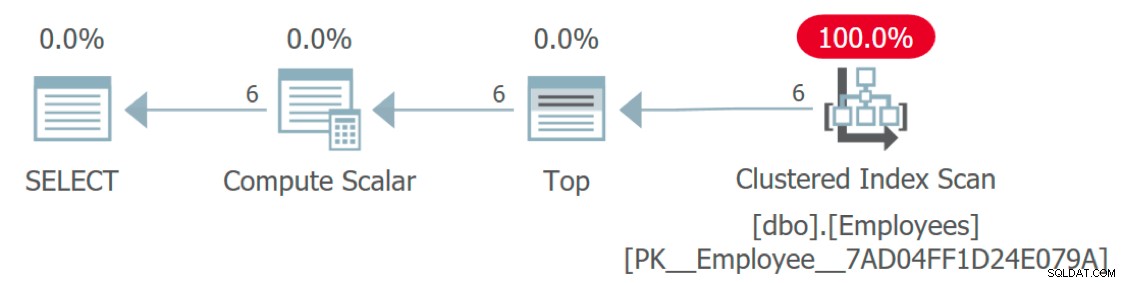 Ausführungsplan mit Zugriff auf Mitarbeiter, aber nicht auf Sprachen
Ausführungsplan mit Zugriff auf Mitarbeiter, aber nicht auf Sprachen
Wie wird auf die Sprachentabelle zugegriffen? Dieser Plan sieht sehr effizient aus, weil er – wie die Funktion selbst – einen Teil der damit verbundenen Komplexität abstrahiert. Tatsächlich ist dieser grafische Plan identisch mit einer Abfrage, die der Language lediglich eine Konstante oder Variable zuweist Spalte:
SELECT TOP (6) EmployeeID, Language = N'Sanskrit' FROM dbo.Employees;
Wenn Sie jedoch eine Ablaufverfolgung für die ursprüngliche Abfrage ausführen, werden Sie sehen, dass zusätzlich zur Hauptabfrage tatsächlich sechs Aufrufe der Funktion (einer für jede Zeile) vorhanden sind, diese Pläne jedoch nicht von SQL Server zurückgegeben werden.
Sie können dies auch überprüfen, indem Sie sys.dm_exec_function_stats überprüfen , aber dies ist keine Garantie :
SELECT [function] = OBJECT_NAME([object_id]), execution_count FROM sys.dm_exec_function_stats WHERE object_name(object_id) IS NOT NULL;
function execution_count ----------- --------------- GetLanguage 6
SentryOne Plan Explorer zeigt die Anweisungen an, wenn Sie einen tatsächlichen Plan innerhalb des Produkts generieren, aber wir können diese nur aus der Ablaufverfolgung abrufen, und es werden immer noch keine Pläne für die einzelnen Funktionsaufrufe gesammelt oder angezeigt:
 Trace-Anweisungen für einzelne skalare UDF-Aufrufe
Trace-Anweisungen für einzelne skalare UDF-Aufrufe
Dies alles macht die Fehlersuche sehr schwierig, da Sie sie jagen müssen, selbst wenn Sie bereits wissen, dass sie dort sind. Es kann auch ein echtes Chaos bei der Leistungsanalyse verursachen, wenn Sie zwei Pläne auf der Grundlage von Dingen wie geschätzten Kosten vergleichen, da sich nicht nur die relevanten Betreiber aus dem physischen Diagramm verstecken, sondern die Kosten auch nirgendwo im Plan enthalten sind.
Schneller Vorlauf zu SQL Server 2019
Nach all den Jahren problematischen Verhaltens und unklarer Ursachen haben sie es geschafft, dass einige Funktionen in den Gesamtausführungsplan optimiert werden können. Skalares UDF-Inlining macht die Objekte, auf die sie zugreifen, für die Fehlersuche sichtbar *und* ermöglicht, dass sie in die Strategie des Ausführungsplans eingebunden werden. Jetzt ermöglichen Kardinalitätsschätzungen (basierend auf Statistiken) Join-Strategien, die einfach nicht möglich waren, wenn die Funktion einmal für jede Zeile aufgerufen wurde.
Wir können dasselbe Beispiel wie oben verwenden, entweder denselben Satz von Objekten in einer SQL Server 2019-Datenbank erstellen oder den Plan-Cache löschen und den Kompatibilitätsgrad auf 150 erhöhen:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 150; GO
Wenn wir jetzt unsere sechszeilige Abfrage erneut ausführen:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Wir erhalten einen Plan, der die Sprachentabelle und die mit dem Zugriff verbundenen Kosten enthält:
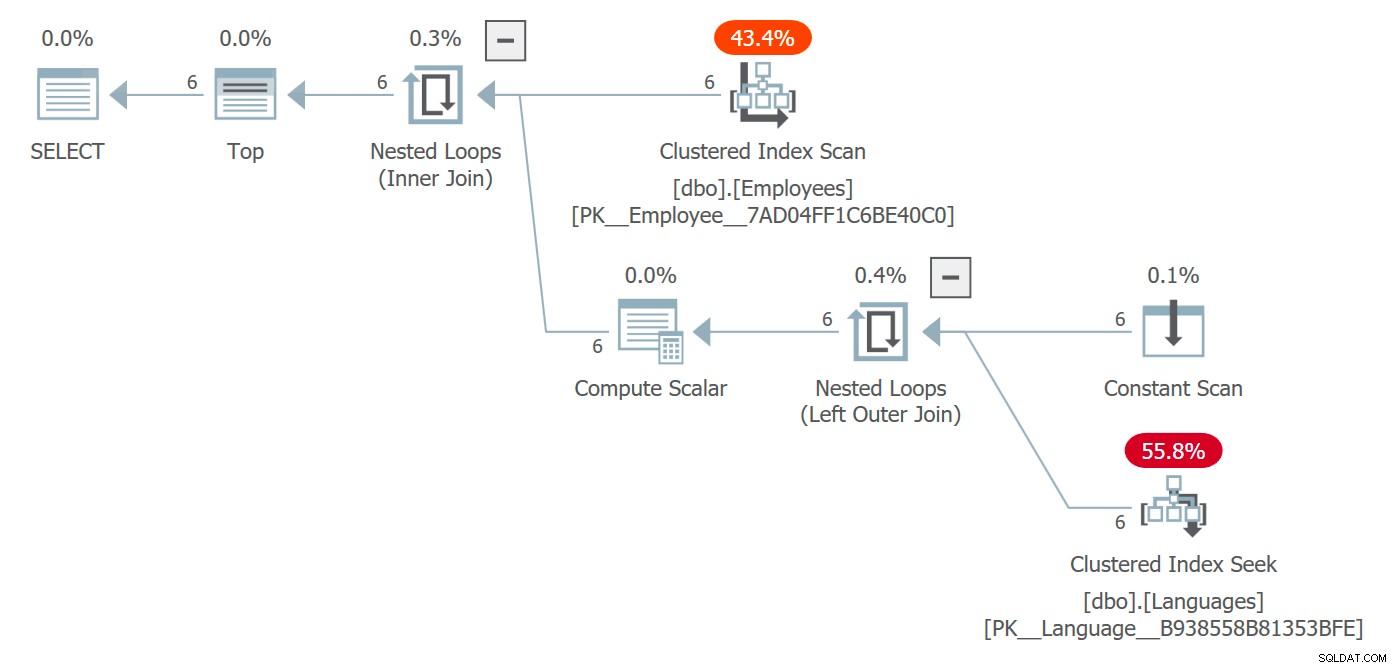 Planen Sie, der den Zugriff auf Objekte umfasst, auf die in der Skalar-UDF verwiesen wird
Planen Sie, der den Zugriff auf Objekte umfasst, auf die in der Skalar-UDF verwiesen wird
Hier wählte der Optimierer einen Join mit verschachtelten Schleifen, aber unter anderen Umständen hätte er eine andere Join-Strategie wählen, Parallelität in Betracht ziehen und im Wesentlichen frei sein können, die Planform vollständig zu ändern. Sie werden dies wahrscheinlich nicht in einer Abfrage sehen, die 6 Zeilen zurückgibt und in keiner Weise ein Leistungsproblem darstellt, aber in größeren Maßstäben könnte es sein.
Der Plan spiegelt wider, dass die Funktion nicht pro Zeile aufgerufen wird – während die Suche tatsächlich sechsmal ausgeführt wird, können Sie sehen, dass die Funktion selbst nicht mehr in sys.dm_exec_function_stats auftaucht . Ein Nachteil, den Sie mitnehmen können, ist, dass, wenn Sie diese DMV verwenden, um festzustellen, ob eine Funktion aktiv verwendet wird (wie wir es häufig für Prozeduren und Indizes tun), dies nicht mehr zuverlässig ist.
Warnhinweise
Nicht jede Skalarfunktion ist inlinefähig, und selbst wenn eine Funktion inlinefähig *ist*, ist sie nicht unbedingt in jedem Szenario inlinefähig. Dies hat oft entweder mit der Komplexität der Funktion, der Komplexität der betreffenden Abfrage oder der Kombination aus beidem zu tun. Ob eine Funktion inlineable ist, können Sie in den sys.sql_modules überprüfen Katalogansicht:
SELECT OBJECT_NAME([object_id]), definition, is_inlineable FROM sys.sql_modules;
Und wenn Sie aus irgendeinem Grund nicht möchten, dass eine bestimmte Funktion (oder irgendeine Funktion in einer Datenbank) inliniert wird, müssen Sie sich nicht auf den Kompatibilitätsgrad der Datenbank verlassen, um dieses Verhalten zu steuern. Ich habe diese lockere Kopplung noch nie gemocht, die dem Zimmerwechsel ähnelt, um eine andere Fernsehsendung zu sehen, anstatt einfach den Kanal zu wechseln. Sie können dies auf Modulebene mit der INLINE-Option steuern:
ALTER FUNCTION dbo.GetLanguage(@id int) RETURNS sysname WITH INLINE = OFF AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END GO
Und Sie können dies auf Datenbankebene steuern, aber getrennt von der Kompatibilitätsebene:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;
Obwohl Sie einen ziemlich guten Anwendungsfall haben müssten, um diesen Hammer zu schwingen, IMHO.
Schlussfolgerung
Nun, ich schlage nicht vor, dass Sie jeden Teil der Logik in eine skalare UDF abstrahieren und davon ausgehen können, dass SQL Server sich jetzt nur um alle Fälle kümmert. Wenn Sie eine Datenbank mit viel skalarer UDF-Nutzung haben, sollten Sie das neueste SQL Server 2019 CTP herunterladen, dort eine Sicherung Ihrer Datenbank wiederherstellen und die DMV überprüfen, um zu sehen, wie viele dieser Funktionen zu gegebener Zeit inlinefähig sein werden. Es könnte ein wichtiger Punkt sein, wenn Sie das nächste Mal für ein Upgrade argumentieren, da Sie im Wesentlichen die gesamte Leistung und die verschwendete Fehlerbehebungszeit zurückerhalten.
Wenn Sie in der Zwischenzeit unter der skalaren UDF-Leistung leiden und nicht in absehbarer Zeit auf SQL Server 2019 aktualisieren, gibt es möglicherweise andere Möglichkeiten, um das/die Problem(e) zu mindern.
Hinweis:Ich habe diesen Artikel geschrieben und in die Warteschlange gestellt, bevor mir klar wurde, dass ich bereits woanders einen anderen Artikel gepostet hatte.