Hallo,
Die Verwendung von Index in der SQL Server-Datenbank erfolgt in Umgebungen, die die meiste Leistung, Geschwindigkeit und Speichereinsparungen erfordern.
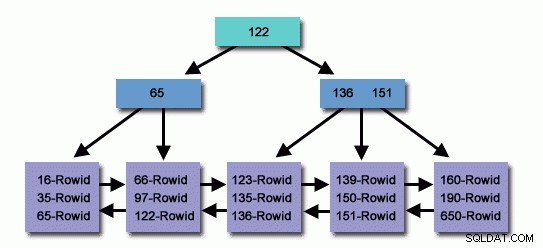
In einer Tabelle mit Millionen oder Milliarden von Datensätzen können wir einen Index verwenden, um weniger Datensätze zu lesen und weniger nach verwandten Datensätzen zu suchen.
Ein sorgfältig erstellter Index, Millionen von Datensätzen in der Datenbank, die wir innerhalb kürzester Zeit durchsucht haben, um den Datensatz für den Anrufer bequemer zu machen, während wir gleichzeitig den Datensatz weniger lesen, indem wir den Zieldatensatz erreichen, nutzen wir die Ressourcen des Betriebssystems effektiv.
Sie sollten einen Index für meist schreibgeschützte Abfragen in einer Tabelle erstellen. Wenn Lösch- und Aktualisierungsvorgänge mehr als schreibgeschützte Abfragen sind, sollten Sie diese Tabelle nicht indizieren.
Sie können sich die fehlende Indexempfehlung von SQL Server mit folgendem Skript ansehen. Sie können fehlende Indizes erstellen, aber Sie sollten diese Indizes überwachen. Wenn sie nicht nützlich sind, sollten Sie sie löschen.
SELECT MID.[statement] AS ObjectName
,MID.equality_columns AS EqualityColumns
,MID.inequality_columns AS InequalityColms
,MID.included_columns AS IncludedColumns
,MIGS.last_user_seek AS LastUserSeek
,MIGS.avg_total_user_cost
* MIGS.avg_user_impact
* (MIGS.user_seeks + MIGS.user_scans) AS Impact
,N'CREATE NONCLUSTERED INDEX <TYPE_Index_Name> ' +
N'ON ' + MID.[statement] +
N' (' + MID.equality_columns
+ ISNULL(', ' + MID.inequality_columns, N'') +
N') ' + ISNULL(N'INCLUDE (' + MID.included_columns + N');', ';')
AS CreateStatement
FROM sys.dm_db_missing_index_group_stats AS MIGS
INNER JOIN sys.dm_db_missing_index_groups AS MIG
ON MIGS.group_handle = MIG.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS MID
ON MIG.index_handle = MID.index_handle
WHERE database_id = DB_ID()
AND MIGS.last_user_seek >= DATEDIFF(month, GetDate(), -1)
ORDER BY Impact DESC;