Ich nehme an, der Grund dafür ist, dass sie dies einfach nicht als vorrangiges Feature angesehen haben, das es wert ist, implementiert zu werden. Es sieht so aus, als ob Postgres macht beides unterstützen
UNION und UNION ALL .
Wenn Sie starke Argumente für diese Funktion haben, können Sie unter Connect Feedback geben (oder was auch immer die URL des Ersatzes sein wird).
Es kann nützlich sein, das Hinzufügen von Duplikaten zu verhindern, da eine doppelte Zeile, die in einem späteren Schritt zu einer vorherigen hinzugefügt wird, fast immer eine Endlosschleife verursacht oder das maximale Rekursionslimit überschreitet.
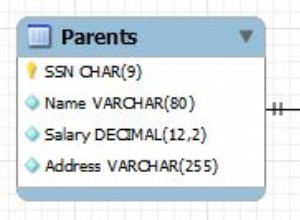
Es gibt einige Stellen in den SQL-Standards
wobei Code verwendet wird, der UNION demonstriert wie unten
Dieser Artikel erklärt, wie sie in SQL Server implementiert werden . Sie machen so etwas nicht "unter der Haube". Die Stapelspule löscht Zeilen, während sie fortfährt, sodass es nicht möglich wäre zu wissen, ob eine spätere Zeile ein Duplikat einer gelöschten ist. Unterstützung von UNION würde einen etwas anderen Ansatz erfordern.
In der Zwischenzeit können Sie das Gleiche ganz einfach in einem TVF mit mehreren Anweisungen erreichen.
Um unten ein dummes Beispiel zu nehmen (Postgres Fiddle ). )
WITH R
AS (SELECT 0 AS N
UNION
SELECT ( N + 1 )%10
FROM R)
SELECT N
FROM R
Änderung der UNION zu UNION ALL und Hinzufügen eines DISTINCT am Ende wird Sie nicht vor der unendlichen Rekursion bewahren.
Aber Sie können dies als
implementierenCREATE FUNCTION dbo.F ()
RETURNS @R TABLE(n INT PRIMARY KEY WITH (IGNORE_DUP_KEY = ON))
AS
BEGIN
INSERT INTO @R
VALUES (0); --anchor
WHILE @@ROWCOUNT > 0
BEGIN
INSERT INTO @R
SELECT ( N + 1 )%10
FROM @R
END
RETURN
END
GO
SELECT *
FROM dbo.F ()
Das obige verwendet IGNORE_DUP_KEY Duplikate zu verwerfen. Wenn die Spaltenliste zu breit ist, um indiziert zu werden, benötigen Sie DISTINCT und NOT EXISTS stattdessen. Sie möchten wahrscheinlich auch einen Parameter, um die maximale Anzahl von Rekursionen festzulegen und Endlosschleifen zu vermeiden.