Stimmen Sie @PaulStock vollkommen zu, dass Aggregate am besten den Quellsystemen überlassen werden. Ein Aggregat in SSIS ist eine vollständig blockierende Komponente, ähnlich wie eine Sortierung, und ich habe hatte bereits mein Argument zu diesem Punkt vorgebracht .
Aber es gibt Zeiten, in denen diese Vorgänge im Quellsystem einfach nicht funktionieren. Das Beste, was mir eingefallen ist, ist, die Daten im Grunde doppelt zu verarbeiten. Ja, ick, aber ich konnte nie einen Weg finden, eine Spalte unbeeinflusst durchzulassen. Für Min/Max-Szenarien würde ich das als Option wünschen, aber offensichtlich würde so etwas wie eine Summe es der Komponente erschweren, zu wissen, mit welcher "Quelle"-Zeile sie verknüpft ist.
2005
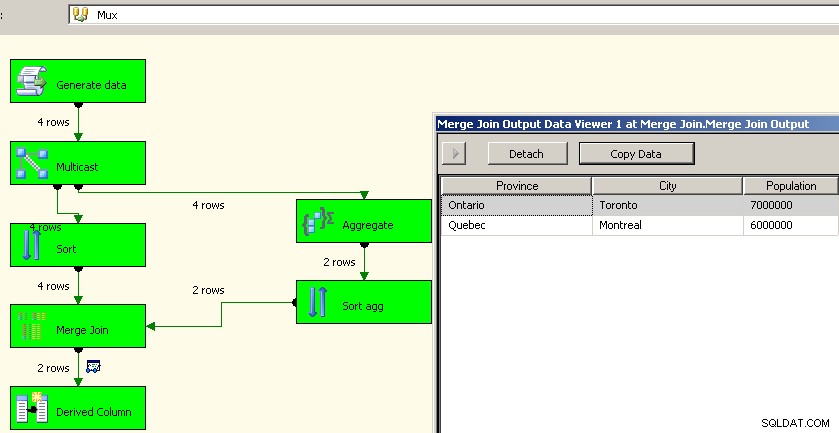
Eine Implementierung von 2005 würde so aussehen. Ihre Leistung wird nicht gut sein, in der Tat ein paar Größenordnungen von gut entfernt, da Sie all diese blockierenden Transformationen haben und Ihre Quelldaten erneut verarbeiten müssen.
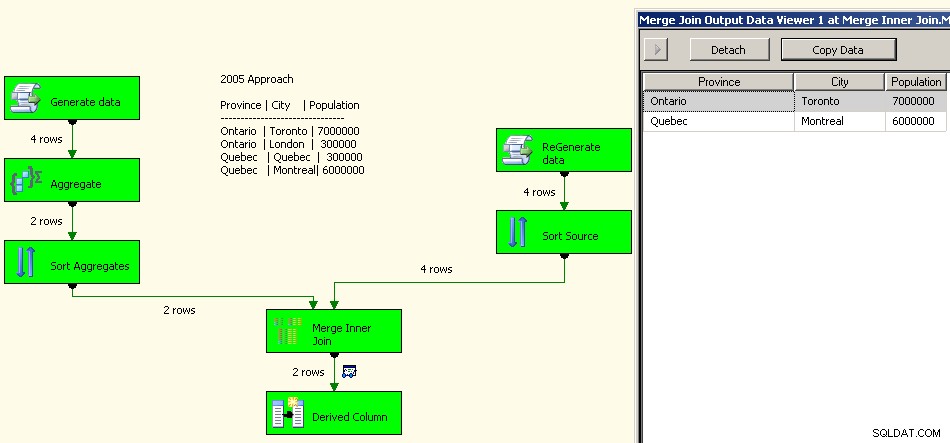
Beitreten zusammenführen 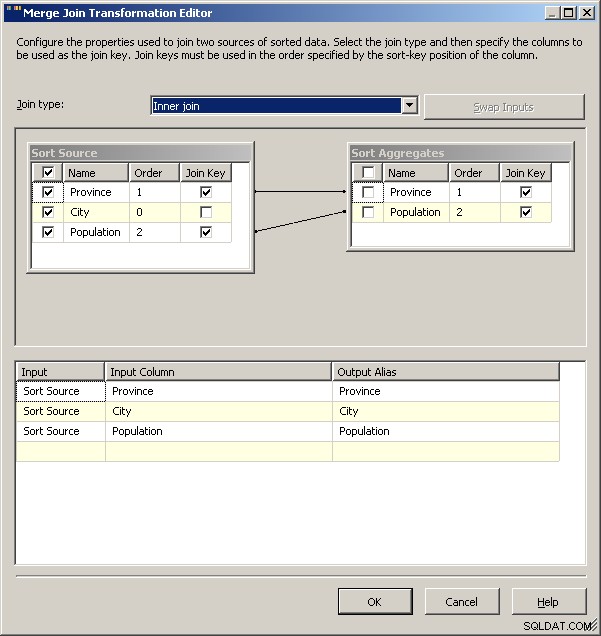
2008
2008 haben Sie die Möglichkeit, den Cache Connection Manager zu verwenden Dies würde helfen, die blockierenden Transformationen zu eliminieren, zumindest dort, wo es darauf ankommt, aber Sie müssen immer noch die Kosten für die doppelte Verarbeitung Ihrer Quelldaten tragen.
Ziehen Sie zwei Datenflüsse auf die Leinwand. Der erste füllt den Cache-Verbindungsmanager und sollte dort sein, wo die Aggregation stattfindet.
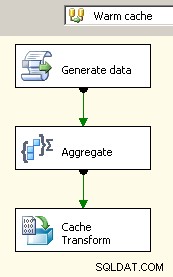
Nachdem der Cache nun die aggregierten Daten enthält, legen Sie eine Suchaufgabe in Ihrem Hauptdatenfluss ab und führen Sie eine Suche im Cache durch.
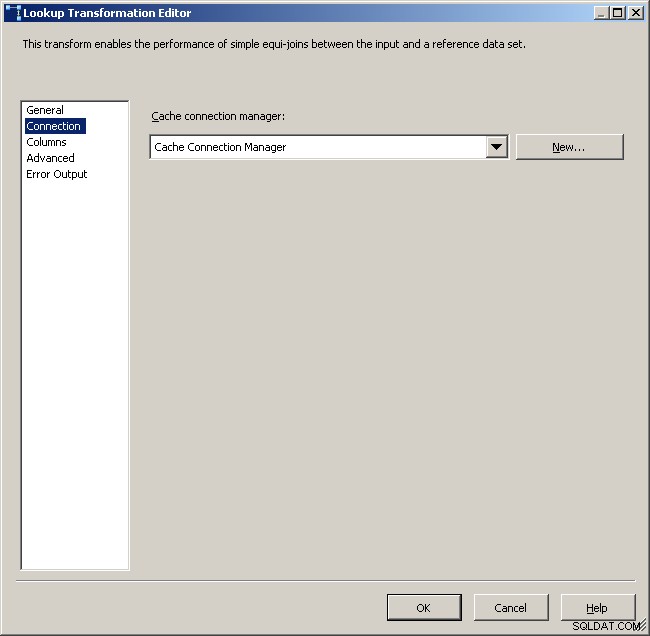
Registerkarte „Allgemeine Suche“
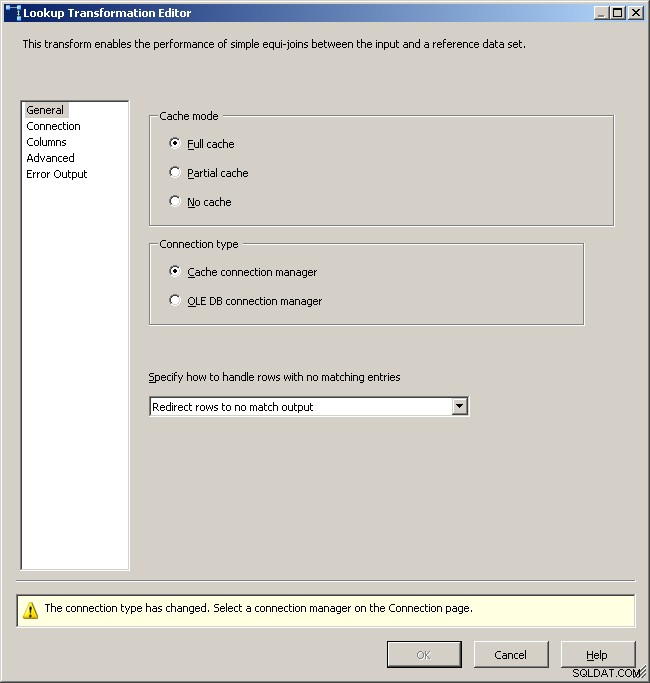
Wählen Sie den Cache-Verbindungsmanager aus
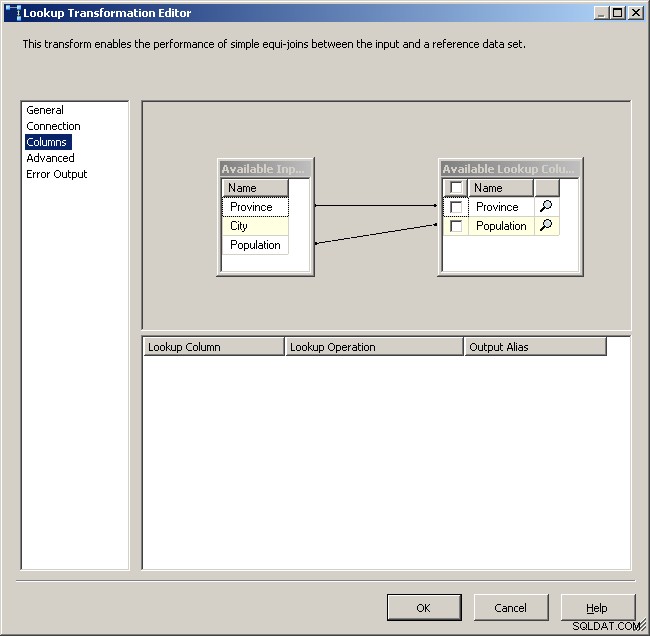
Ordnen Sie die entsprechenden Spalten zu
Großer Erfolg 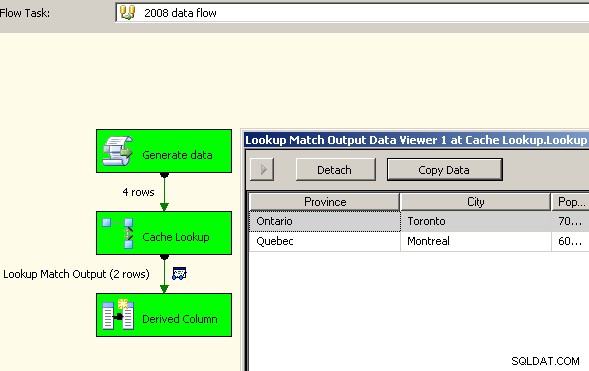
Skriptaufgabe
Der dritte Ansatz, der mir einfällt, 2005 oder 2008, ist, es selbst zu schreiben. Als allgemeine Regel versuche ich, die Skriptaufgaben zu vermeiden, aber in diesem Fall ist es wahrscheinlich sinnvoll. Sie müssen daraus einen asynchrone Skriptumwandlung aber verwalten Sie einfach Ihre Aggregationen dort. Mehr zu wartender Code, aber Sie können sich die Mühe ersparen, Ihre Quelldaten erneut zu verarbeiten.
Abschließend möchte ich als allgemeine Einschränkung untersuchen, welche Auswirkungen die Bindungen auf Ihre Lösung haben. Für diesen Datensatz würde ich erwarten, dass etwas wie Guelph plötzlich anschwillt und Toronto bindet, aber wenn ja, was sollte das Paket tun? Im Moment führt beides zu zwei Reihen für Ontario, aber ist das das beabsichtigte Verhalten? Mit Script können Sie natürlich definieren, was im Fall von Unentschieden passiert. Sie könnten die Lösung von 2008 wahrscheinlich auf den Kopf stellen, indem Sie die "normalen" Daten zwischenspeichern und diese als Suchbedingung verwenden und die Aggregate verwenden, um nur eine der Bindungen zurückzuziehen. 2005 kann wahrscheinlich dasselbe tun, indem es einfach das Aggregat als linke Quelle für den Merge-Join einsetzt
Änderungen
Jason Horner hatte in seinem Kommentar eine gute Idee. Ein anderer Ansatz wäre, eine Multicast-Transformation zu verwenden und die Aggregation in einem Stream durchzuführen und ihn wieder zusammenzubringen. Ich konnte nicht herausfinden, wie es mit einer Union funktioniert, aber wir könnten Sortierungen verwenden und Joins zusammenführen, ähnlich wie oben. Dies ist wahrscheinlich ein besserer Ansatz, da es uns die Mühe erspart, die Quelldaten erneut zu verarbeiten.