Demonstration einer möglichen Erklärung.
Tabellenskript erstellen
SELECT *
INTO #T
FROM master.dbo.spt_values
CREATE NONCLUSTERED INDEX [IX_T] ON #T ([name] DESC,[number] DESC);
Abfrage eins (gibt 35 Ergebnisse zurück)
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Abfrage Zwei (Wie zuvor, aber durch Hinzufügen von c2.[type] zur Auswahlliste werden 0 Ergebnisse zurückgegeben);
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type] ,c2.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Warum?
row_number() für doppelte NAMES ist nicht angegeben, also wählt es einfach dasjenige aus, das in den besten Ausführungsplan für die erforderlichen Ausgabespalten passt. In der zweiten Abfrage ist dies für beide cte-Aufrufe gleich, in der ersten wählt sie einen anderen Zugriffspfad mit daraus resultierender unterschiedlicher row_numbering.
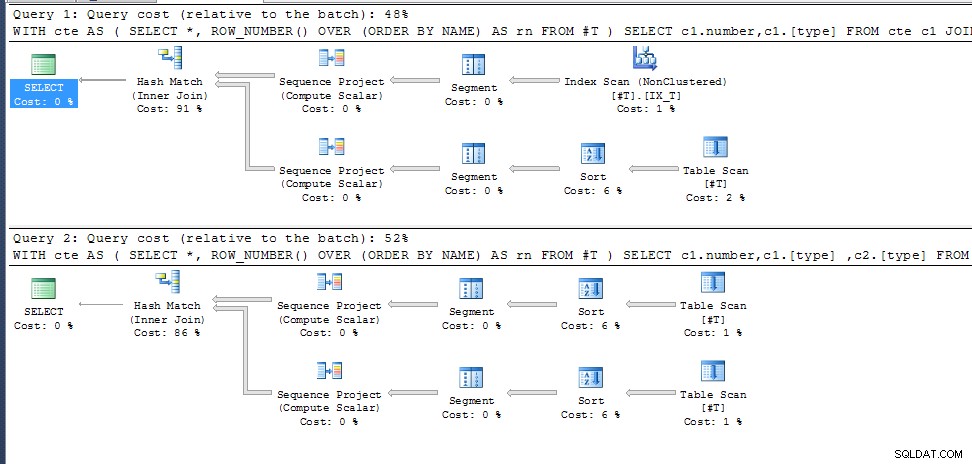
Lösungsvorschlag
Sie treten dem CTE am ROW_NUMBER() over (order by t.[Date]) selbst bei
Im Gegensatz zu dem, was vielleicht erwartet wurde, wird der CTE wahrscheinlich nicht verwirklicht werden
was die Konsistenz für den Self-Join sichergestellt hätte, und Sie gehen daher von einer Korrelation zwischen ROW_NUMBER() aus auf beiden Seiten, die für Datensätze mit einem doppelten [Date] möglicherweise nicht vorhanden sind in den Daten vorhanden ist.
Was passiert, wenn Sie versuchen, ROW_NUMBER() over (order by t.[Date], t.[id]) um sicherzustellen, dass bei gebundenen Daten die row_numbering in einer garantiert konsistenten Reihenfolge ist. (Oder eine andere Spalte/Kombination von Spalten, die Datensätze unterscheiden kann, wenn id es nicht tut)