Der SQL Server-Optimierer enthält Logik zum Entfernen redundanter Joins, aber es gibt Einschränkungen, und die Joins müssen nachweislich redundant . Zusammenfassend kann ein Join vier Effekte haben:
- Es kann zusätzliche Spalten (aus der verknüpften Tabelle) hinzufügen
- Es können zusätzliche Zeilen hinzugefügt werden (die verbundene Tabelle kann mehr als einmal mit einer Quellzeile übereinstimmen)
- Es kann Zeilen entfernen (die verbundene Tabelle hat möglicherweise keine Übereinstimmung)
- Es kann
NULLeinführen s (für einRIGHToderFULL JOIN)
Um einen redundanten Join erfolgreich zu entfernen, muss die Abfrage (oder Ansicht) alle vier Möglichkeiten berücksichtigen. Wenn dies richtig gemacht wird, kann der Effekt erstaunlich sein. Zum Beispiel:
USE AdventureWorks2012;
GO
CREATE VIEW dbo.ComplexView
AS
SELECT
pc.ProductCategoryID, pc.Name AS CatName,
ps.ProductSubcategoryID, ps.Name AS SubCatName,
p.ProductID, p.Name AS ProductName,
p.Color, p.ListPrice, p.ReorderPoint,
pm.Name AS ModelName, pm.ModifiedDate
FROM Production.ProductCategory AS pc
FULL JOIN Production.ProductSubcategory AS ps ON
ps.ProductCategoryID = pc.ProductCategoryID
FULL JOIN Production.Product AS p ON
p.ProductSubcategoryID = ps.ProductSubcategoryID
FULL JOIN Production.ProductModel AS pm ON
pm.ProductModelID = p.ProductModelID
Der Optimierer kann die folgende Abfrage erfolgreich vereinfachen:
SELECT
c.ProductID,
c.ProductName
FROM dbo.ComplexView AS c
WHERE
c.ProductName LIKE N'G%';
An:

Rob Farley hat ausführlich über diese Ideen im original MVP Deep Dives book geschrieben , und es gibt eine Aufzeichnung seiner Präsentation zu diesem Thema bei SQLBits.
Die Haupteinschränkungen bestehen darin, dass Fremdschlüsselbeziehungen muss auf einem einzigen Schlüssel basieren um zum Vereinfachungsprozess beizutragen, und die Kompilierungszeit für die Abfragen einer solchen Ansicht kann ziemlich lang werden, insbesondere wenn die Anzahl der Verknüpfungen zunimmt. Es könnte eine ziemliche Herausforderung sein, eine 100-Tabellen-Ansicht zu schreiben, die die gesamte Semantik genau richtig wiedergibt. Ich wäre geneigt, eine alternative Lösung zu finden, vielleicht mit dynamischem SQL .
Allerdings können die besonderen Qualitäten Ihrer denormalisierten Tabelle bedeuten, dass die Ansicht recht einfach zusammenzubauen ist und nur erzwungene FOREIGN KEYs erfordert Nicht-NULL referenzierte Spalten und entsprechende UNIQUE Einschränkungen, damit diese Lösung so funktioniert, wie Sie es sich erhoffen, ohne den Overhead von 100 physischen Join-Operatoren im Plan.
Beispiel
Zehn statt hundert Tabellen verwenden:
-- Referenced tables
CREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref03 (col03 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref04 (col04 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref05 (col05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
Die übergeordnete Tabellendefinition (mit Seitenkomprimierung):
CREATE TABLE dbo.Normalized
(
pk integer IDENTITY NOT NULL,
col01 tinyint NOT NULL REFERENCES dbo.Ref01,
col02 tinyint NOT NULL REFERENCES dbo.Ref02,
col03 tinyint NOT NULL REFERENCES dbo.Ref03,
col04 tinyint NOT NULL REFERENCES dbo.Ref04,
col05 tinyint NOT NULL REFERENCES dbo.Ref05,
col06 tinyint NOT NULL REFERENCES dbo.Ref06,
col07 tinyint NOT NULL REFERENCES dbo.Ref07,
col08 tinyint NOT NULL REFERENCES dbo.Ref08,
col09 tinyint NOT NULL REFERENCES dbo.Ref09,
col10 tinyint NOT NULL REFERENCES dbo.Ref10,
CONSTRAINT PK_Normalized
PRIMARY KEY CLUSTERED (pk)
WITH (DATA_COMPRESSION = PAGE)
);
Die Aussicht:
CREATE VIEW dbo.Denormalized
WITH SCHEMABINDING AS
SELECT
item01 = r01.item,
item02 = r02.item,
item03 = r03.item,
item04 = r04.item,
item05 = r05.item,
item06 = r06.item,
item07 = r07.item,
item08 = r08.item,
item09 = r09.item,
item10 = r10.item
FROM dbo.Normalized AS n
JOIN dbo.Ref01 AS r01 ON r01.col01 = n.col01
JOIN dbo.Ref02 AS r02 ON r02.col02 = n.col02
JOIN dbo.Ref03 AS r03 ON r03.col03 = n.col03
JOIN dbo.Ref04 AS r04 ON r04.col04 = n.col04
JOIN dbo.Ref05 AS r05 ON r05.col05 = n.col05
JOIN dbo.Ref06 AS r06 ON r06.col06 = n.col06
JOIN dbo.Ref07 AS r07 ON r07.col07 = n.col07
JOIN dbo.Ref08 AS r08 ON r08.col08 = n.col08
JOIN dbo.Ref09 AS r09 ON r09.col09 = n.col09
JOIN dbo.Ref10 AS r10 ON r10.col10 = n.col10;
Hacken Sie die Statistiken, damit der Optimierer denkt, die Tabelle sei sehr groß:
UPDATE STATISTICS dbo.Normalized WITH ROWCOUNT = 100000000, PAGECOUNT = 5000000;
Beispiel für eine Benutzerabfrage:
SELECT
d.item06,
d.item07
FROM dbo.Denormalized AS d
WHERE
d.item08 = 'Banana'
AND d.item01 = 'Green';
Gibt uns diesen Ausführungsplan:
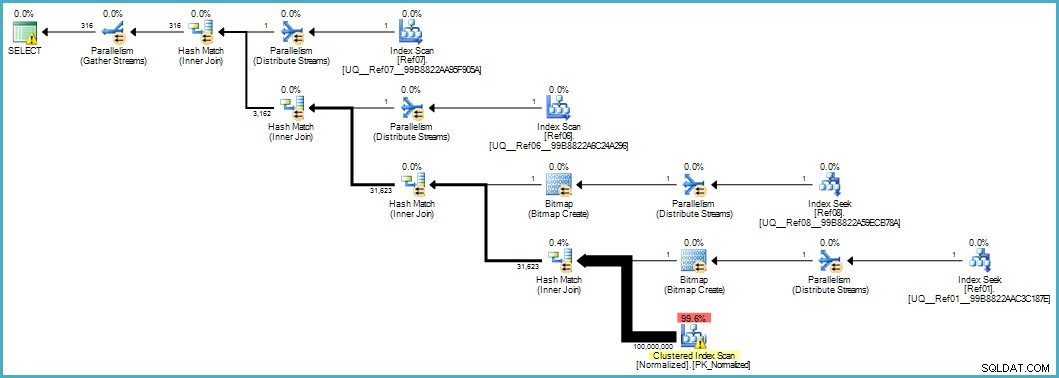
Der Scan der normalisierten Tabelle sieht schlecht aus, aber beide Bloom-Filter-Bitmaps werden während des Scans von der Speicher-Engine angewendet (so dass Zeilen, die nicht übereinstimmen, nicht einmal bis zum Abfrageprozessor auftauchen). Dies kann in Ihrem Fall ausreichen, um eine akzeptable Leistung zu erzielen, und sicherlich besser, als die ursprüngliche Tabelle mit ihren überlaufenden Spalten zu scannen.
Wenn Sie irgendwann ein Upgrade auf SQL Server 2012 Enterprise durchführen können, haben Sie eine andere Option:Erstellen eines Column-Store-Index für die normalisierte Tabelle:
CREATE NONCLUSTERED COLUMNSTORE INDEX cs
ON dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10);
Der Ausführungsplan ist:
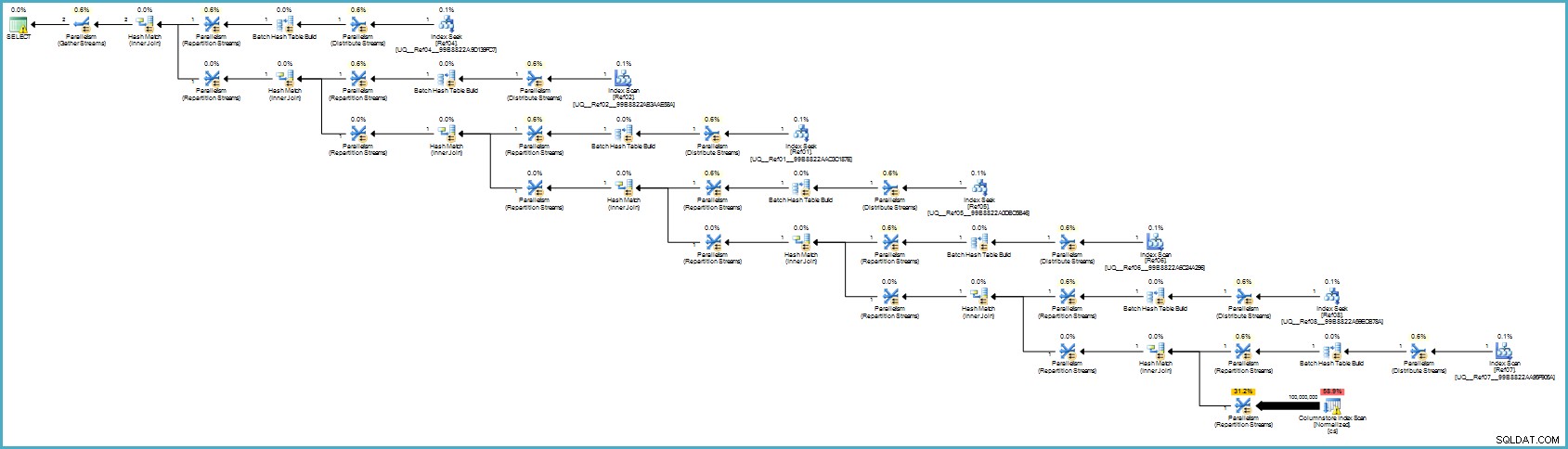
Das sieht für Sie wahrscheinlich schlimmer aus, aber die Spaltenspeicherung bietet eine außergewöhnliche Komprimierung, und der gesamte Ausführungsplan wird im Stapelmodus mit Filtern für alle beitragenden Spalten ausgeführt. Wenn der Server ausreichend Threads und Speicher zur Verfügung hat, könnte diese Alternative wirklich fliegen.
Letztendlich bin ich mir nicht sicher, ob diese Normalisierung der richtige Ansatz ist, wenn man die Anzahl der Tabellen und die Wahrscheinlichkeit berücksichtigt, dass Sie einen schlechten Ausführungsplan erhalten oder eine übermäßige Kompilierungszeit benötigen. Ich würde wahrscheinlich zuerst das Schema der denormalisierten Tabelle korrigieren (korrekte Datentypen usw.), möglicherweise Datenkomprimierung anwenden ... die üblichen Dinge.
Wenn die Daten wirklich in ein Sternschema gehören, ist wahrscheinlich mehr Designarbeit erforderlich, als sich wiederholende Datenelemente einfach in separate Tabellen aufzuteilen.