Ansatz
Der folgende Ansatz kann verwendet werden, um eine begrenzte Werteliste zu deduplizieren.
- Verwenden Sie
REPLACE()Funktion, um verschiedene Trennzeichen in dasselbe Trennzeichen umzuwandeln. - Verwenden Sie
REPLACE()Funktion zum Einfügen von schließenden und öffnenden XML-Tags, um ein XML-Fragment zu erstellen - Verwenden Sie den
CAST(expr AS XML)Funktion, um das obige Fragment in den XML-Datentyp
zu konvertieren - Verwenden Sie
OUTER APPLYum die Tabellenwertfunktionnodes()anzuwenden um das XML-Fragment in seine einzelnen XML-Tags aufzuteilen. Dadurch wird jedes XML-Tag in einer separaten Zeile zurückgegeben. - Extrahieren Sie mithilfe von
value()nur den Wert aus dem XML-Tag -Funktion und gibt den Wert mit dem angegebenen Datentyp zurück. - Hängen Sie nach dem oben genannten Wert ein Komma an.
- Beachten Sie, dass diese Werte in separaten Zeilen zurückgegeben werden. Die Verwendung des
DISTINCTSchlüsselwort entfernt jetzt doppelte Zeilen (d. h. Werte). - Verwenden Sie den
FOR XML PATH('')-Klausel, um die Werte über mehrere Zeilen hinweg zu einer einzigen Zeile zu verketten.
Abfrage
Setzen Sie den obigen Ansatz in Abfrageform:
SELECT DISTINCT PivotedTable.PivotedColumn.value('.','nvarchar(max)') + ','
FROM (
-- This query returns the following in theDataXml column:
-- <tag>test1</tag><tag>test2</tag><tag>test1</tag><tag>test2</tag><tag>test3</tag><tag>test4</tag><tag>test4</tag><tag>test4</tag>
-- i.e. it has turned the original delimited data into an XML fragment
SELECT
DataTable.DataColumn AS DataRaw
, CAST(
'<tag>'
-- First replace commas with pipes to have only a single delimiter
-- Then replace the pipe delimiters with a closing and opening tag
+ replace(replace(DataTable.DataColumn, ',','|'), '|','</tag><tag>')
-- Add a final set of closing tags
+ '</tag>'
AS XML) AS DataXml
FROM ( SELECT 'test1,test2,test1|test2,test3|test4,test4|test4' AS DataColumn) AS DataTable
) AS x
OUTER APPLY DataXml.nodes('tag') AS PivotedTable(PivotedColumn)
-- Running the query without the following line will return the data in separate rows
-- Running the query with the following line returns the rows concatenated, i.e. it returns:
-- test1,test2,test3,test4,
FOR XML PATH('')
Eingabe &Ergebnis
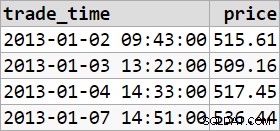
Angesichts der Eingabe:
Die obige Abfrage gibt das Ergebnis zurück:
Beachten Sie das abschließende Komma am Ende. Ich überlasse es Ihnen als Übung, das zu entfernen.
BEARBEITEN:Anzahl der Duplikate
OP in einem Kommentar angefordert "wie bekomme ich auch die Anzahl der Duplikate? in einer separaten Spalte ".
Der einfachste Weg wäre, die obige Abfrage zu verwenden, aber die letzte Zeile FOR XML PATH('') zu entfernen . Zählen Sie dann alle Werte und eindeutigen Werte, die von SELECT zurückgegeben werden Ausdruck in der obigen Abfrage (z. B. PivotedTable.PivotedColumn.value('.','nvarchar(max)') ). Die Differenz zwischen der Anzahl aller Werte und der Anzahl unterschiedlicher Werte ist die Anzahl der doppelten Werte.
SELECT
COUNT(PivotedTable.PivotedColumn.value('.','nvarchar(max)')) AS CountOfAllValues
, COUNT(DISTINCT PivotedTable.PivotedColumn.value('.','nvarchar(max)')) AS CountOfUniqueValues
-- The difference of the previous two counts is the number of duplicate values
, COUNT(PivotedTable.PivotedColumn.value('.','nvarchar(max)'))
- COUNT(DISTINCT PivotedTable.PivotedColumn.value('.','nvarchar(max)')) AS CountOfDuplicateValues
FROM (
-- This query returns the following in theDataXml column:
-- <tag>test1</tag><tag>test2</tag><tag>test1</tag><tag>test2</tag><tag>test3</tag><tag>test4</tag><tag>test4</tag><tag>test4</tag>
-- i.e. it has turned the original delimited data into an XML fragment
SELECT
DataTable.DataColumn AS DataRaw
, CAST(
'<tag>'
-- First replace commas with pipes to have only a single delimiter
-- Then replace the pipe delimiters with a closing and opening tag
+ replace(replace(DataTable.DataColumn, ',','|'), '|','</tag><tag>')
-- Add a final set of closing tags
+ '</tag>'
AS XML) AS DataXml
FROM ( SELECT 'test1,test2,test1|test2,test3|test4,test4|test4' AS DataColumn) AS DataTable
) AS x
OUTER APPLY DataXml.nodes('tag') AS PivotedTable(PivotedColumn)
Für die oben gezeigte Eingabe lautet die Ausgabe dieser Abfrage:
CountOfAllValues CountOfUniqueValues CountOfDuplicateValues
---------------- ------------------- ----------------------
8 4 4