Grund für das Problem :
TOKEN -Methode in SSIS verwendet die Implementierung von strtok Funktion in C++ . Ich habe diese Informationen beim Lesen des Buches Microsoft® SQL Server® 2012 Integration Services
. Es wird als Hinweis auf Seite 113 erwähnt (Ich mag dieses Buch! Viele nette Informationen. ).
Ich habe nach der Implementierung von strtok gesucht Funktion und ich habe die folgenden Links gefunden.
INFO:strtok():C Function -- Documentation Supplement - Das Codebeispiel in diesem Link zeigt, dass die Funktion aufeinanderfolgende Trennzeichen ignoriert.
Die Antworten auf die folgenden SO-Fragen weisen darauf hin, dass strtok Die Funktion wurde entwickelt, um aufeinanderfolgende Trennzeichen zu ignorieren.
Müssen wissen, wann keine Daten zwischen zwei Token-Trennzeichen mit strtok() erscheinen
strtok_s-Verhalten mit aufeinanderfolgenden Trennzeichen
Ich denke, dass der TOKEN und TOKENCOUNT Funktionen funktionieren wie vorgesehen, aber ob sich SSIS so verhalten sollte, könnte eine Frage an das Microsoft SSIS-Team sein.
Ursprünglicher Beitrag - Der obige Abschnitt ist ein Update:
Ich habe ein einfaches Paket in SSIS 2012 basierend auf Ihren Dateneingaben erstellt. Wie Sie in Ihrer Frage beschrieben hatten, ist der TOKEN Funktion verhält sich nicht wie vorgesehen. Ich stimme dir zu, dass die Funktion nicht zu funktionieren scheint. Dieser Beitrag ist nicht eine Antwort auf Ihr ursprüngliches Problem.
Hier ist eine alternative Möglichkeit, den Ausdruck relativ einfacher zu schreiben. Dies funktioniert nur, wenn das letzte Segment in Ihrem Eingabedatensatz immer einen Wert hat (z. B. A1 , B2 , C3 usw.).
Ausdruck kann umgeschrieben werden als :
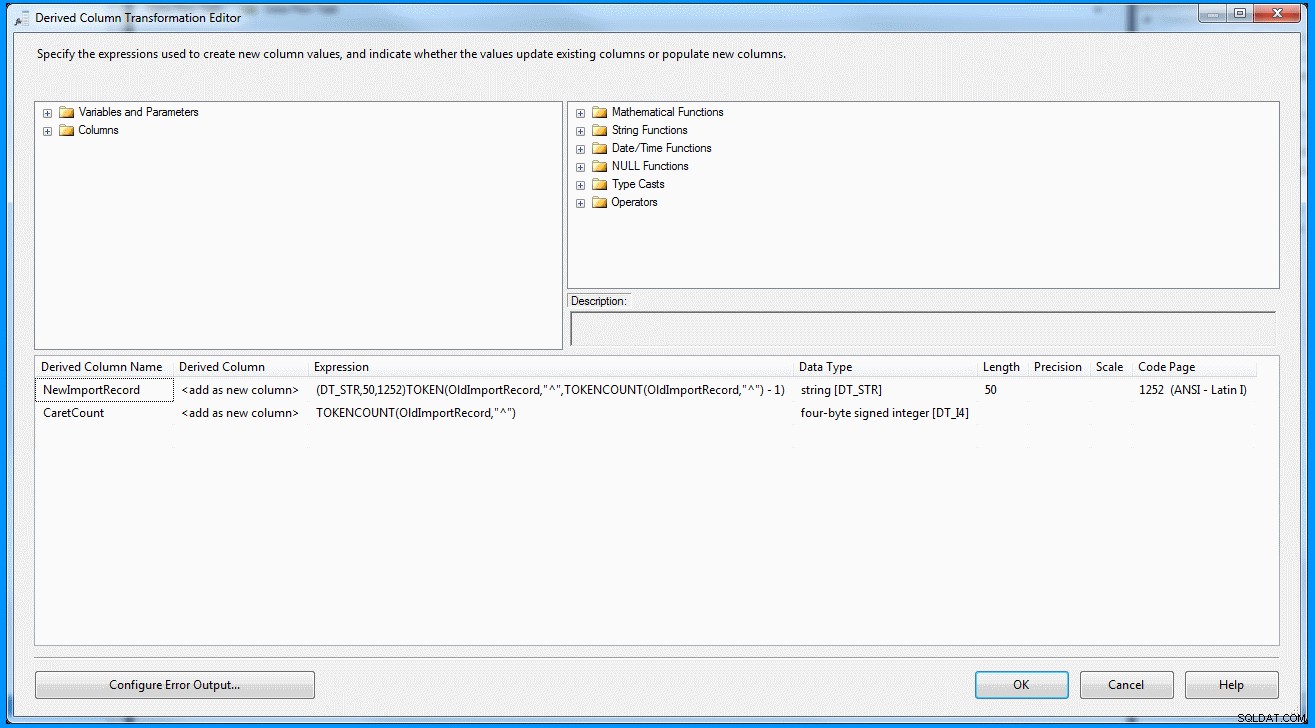
Diese Anweisung verwendet den Eingabedatensatz als Parameter und das Trennzeichen Caret (^) als zweiten Parameter. Der dritte Parameter berechnet die Gesamtzahl der Segmente in den Datensätzen, wenn sie durch das Trennzeichen geteilt werden. Wenn Sie Daten im letzten Segment haben, haben Sie garantiert zwei Segmente. Sie können dann 1 subtrahieren, um das vorletzte Segment abzurufen.
(DT_STR,50,1252)TOKEN(OldImportRecord,"^",TOKENCOUNT(OldImportRecord,"^") - 1)
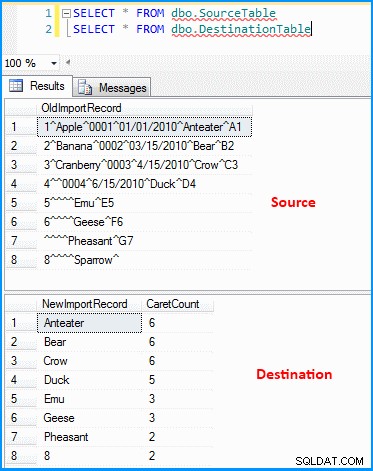
Ich habe ein einfaches Paket mit Datenflussaufgabe erstellt. Die OLE DB-Quelle ruft die Daten ab, und die abgeleitete Transformation analysiert und teilt die Daten wie im folgenden Screenshot. Die Ausgabe wird dann in die Zieltabelle eingefügt. Sie können die Quell- und Zieltabellen im letzten Screenshot sehen. Die Zieltabelle hat zwei Spalten. Die erste Spalte speichert die Daten des vorletzten Segments und die Anzahl der Segmente basierend auf dem Trennzeichen (was wiederum nicht korrekt ist). Sie können feststellen, dass der letzte Datensatz nicht die richtigen Ergebnisse abgerufen hat. Wenn der letzte Datensatz nicht den Wert 8 hatte , dann schlägt der obige Ausdruck fehl, weil der Ausdruck zu Null Index ausgewertet wird.
Ich hoffe, das hilft, Ihren Ausdruck zu vereinfachen.
Wenn Sie nichts von jemand anderem hören, würde ich empfehlen, dieses Problem auf der Microsoft Connect-Website .
Tabelle erstellen und Skripte füllen :
CREATE TABLE [dbo].[SourceTable](
[OldImportRecord] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DestinationTable](
[NewImportRecord] [varchar](50) NOT NULL,
[CaretCount] [int] NOT NULL
) ON [PRIMARY]
GO
INSERT INTO dbo.SourceTable (OldImportRecord) VALUES
('1^Apple^0001^01/01/2010^Anteater^A1'),
('2^Banana^0002^03/15/2010^Bear^B2'),
('3^Cranberry^0003^4/15/2010^Crow^C3'),
('4^^0004^6/15/2010^Duck^D4'),
('5^^^^Emu^E5'),
('6^^^^Geese^F6'),
('^^^^Pheasant^G7'),
('8^^^^Sparrow^');
GO
Abgeleitete Spaltenumwandlung innerhalb der Datenflussaufgabe :
Daten in Quell- und Zieltabellen :