Diese Tests (Datenbank AdventureWorks2008R2) zeigen, was passiert:
SET NOCOUNT ON;
SET STATISTICS IO ON;
PRINT 'Test #1';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE '%be%';
PRINT 'Test #2';
DECLARE @Pattern NVARCHAR(50);
SET @Pattern=N'%be%';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE @Pattern;
SET STATISTICS IO OFF;
SET NOCOUNT OFF;
Ergebnisse:
Test #1
Table 'Person'. Scan count 1, logical reads 106
Test #2
Table 'Person'. Scan count 1, logical reads 106
Die Ergebnisse von SET STATISTICS IO zeigt, dass LIO gleich sind .Aber die Ausführungspläne sind ganz andere: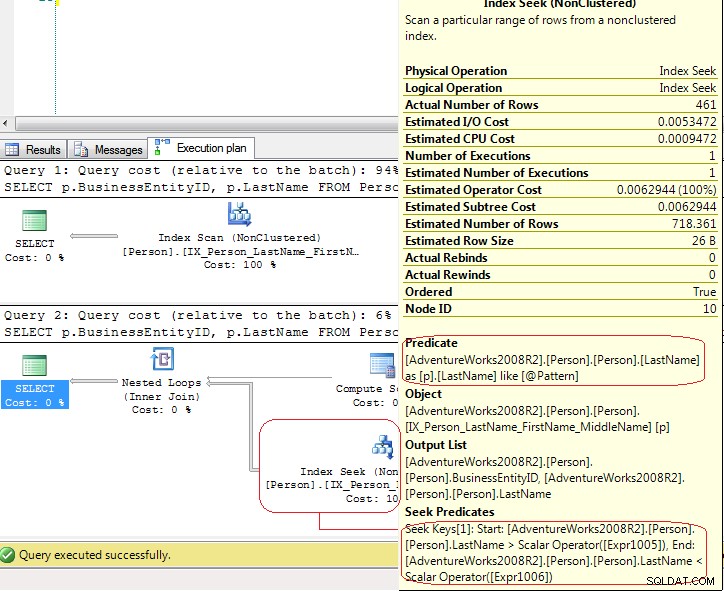
Im ersten Test verwendet SQL Server einen Index Scan explizit, aber im zweiten Test verwendet SQL Server einen Index Seek das ist ein Index Seek - range scan . Im letzten Fall verwendet SQL Server einen Compute Scalar Operator, um diese Werte zu generieren
[Expr1005] = Scalar Operator(LikeRangeStart([@Pattern])),
[Expr1006] = Scalar Operator(LikeRangeEnd([@Pattern])),
[Expr1007] = Scalar Operator(LikeRangeInfo([@Pattern]))
und die Index Seek Operator verwenden ein Seek Predicate (optimiert) für einen range scan (LastName > LikeRangeStart AND LastName < LikeRangeEnd ) plus ein weiteres nicht optimiertes Predicate (LastName LIKE @pattern ).
Meine Antwort:Es ist keine "echte" Index Seek . Es ist ein Index Seek - range scan was in diesem Fall die gleiche Leistung wie Index Scan hat .
Bitte beachten Sie auch den Unterschied zwischen Index Seek und Index Scan (ähnliche Debatte):Also … ist es ein Seek oder ein Scan?
.
Änderung 1: Der Ausführungsplan für OPTION(RECOMPILE) (siehe Aarons Empfehlung bitte) zeigt auch einen Index Scan (anstelle von Index Seek ):