Sie brauchen Datenmodellierung, um sich selbst oder Ihrem Unternehmen viel Geld, Stunden und Probleme zu ersparen. Lesen Sie weiter, um herauszufinden, wie Datenmodelle ihre Wirkung entfalten.
Bei der Datenmodellierung wird eine konzeptionelle Ansicht der Informationen erstellt, die eine Datenbank enthält oder enthalten sollte. Als Ergebnis dieses Prozesses wird ein Datenmodell erstellt, das Datenobjekten (all jenen Entitäten, für die Informationen gespeichert werden sollen), den Assoziationen oder Beziehungen zwischen ihnen und den Regeln oder Einschränkungen, die die in die Datenbank eingegebenen Informationen regeln, Form gibt .
Sehr schön, aber muss man wirklich mit Datenmodellen arbeiten? Können wir diesen Schritt nicht einfach überspringen, etwas Zeit sparen und direkt mit dem Erstellen von Objekten in der Datenbank fortfahren? Ein Kurs in Datenbankmodellierung wird diese Fragen beantworten, aber wenn Sie eine Zusammenfassung wünschen, gebe ich Ihnen genügend Gründe, ein Datenmodell zur Hand zu haben, wann immer Sie mit in einer Datenbank gespeicherten Informationen arbeiten müssen. Wenn Sie diesen Artikel zu Ende gelesen haben, werden Sie mir zustimmen, dass die Arbeit mit einer Datenbank ohne ein geeignetes Modell dem Bau eines Hauses – oder sogar eines Wolkenkratzers – ohne ein geeignetes Fundament entspricht.
Betrachten wir zunächst zwei Kontexte, in denen Datenmodellierung hauptsächlich durchgeführt wird:
- Strategische Modellierung, die als Teil der allgemeinen Informationssystemstrategie in einer Organisation durchgeführt wird.
- Datenbankdesign, das Teil der Designphase im Softwareentwicklungsprozess ist.
In beiden Situationen gibt es viele Gründe, Datenmodellierung durchzuführen. Zuerst werden wir diejenigen sehen, die mit der Strategie von Informationssystemen zu tun haben, dann diejenigen, die sich auf die Softwareentwicklung beziehen.
Höhere Informationsqualität
Ein Datenmodell ist unerlässlich, um Klarheit und Konsistenz in den Metadaten zu gewährleisten , die Definitionen der Objekte, aus denen eine Datenbank besteht. Dies trägt zur Erhöhung der Informationsqualität bei. Beispielsweise kann ein Datenmodell sicherstellen, dass die richtigen Formate für Datenelemente wie Telefonnummern und Postleitzahlen verwendet werden, und in einer Datenbank, in der Kundendaten gespeichert sind, kann es sicherstellen, dass jeder Kunde mindestens eine Adresse hat.
Sie können auch die Qualität der in einer Datenbank gespeicherten Informationen sicherstellen, indem Sie Regeln auferlegen, damit nur gültige Daten in die Tabellen gelangen. Dazu legen Sie beim Entwerfen des Datenmodells die Wertedomäne für jedes Feld fest und unterscheiden die Felder, die Werte enthalten müssen, von denen, die leer bleiben können.
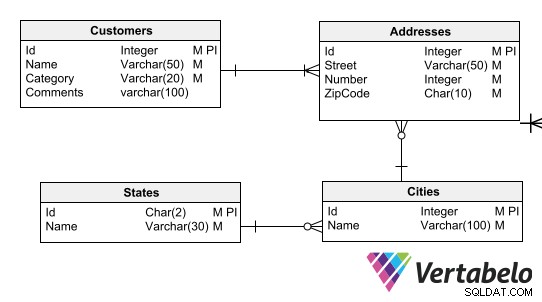
Datenmodelldefinitionen stellen die Datenkonformität sicher Geschäftsregeln. Beispielsweise möchten Sie möglicherweise erzwingen, dass jeder Client eine Adresse mit dem richtigen Postleitzahlenformat hat, oder dass jede Adresse einer Stadt und jede Stadt einem Bundesland zugeordnet wird.
Die Informationsqualität wird auch verbessert, indem Einschränkungen auferlegt werden, die die referenzielle Integrität sicherstellen und die beabsichtigte Kardinalität in den Beziehungen zwischen Entitäten aufrechterhalten. Diese Einschränkungen können nur aus einem geeigneten Datenmodell abgeleitet werden.
Wiederverwendung von Datenbeständen
Bei der Entwicklung eines neuen Systems oder beim Hinzufügen neuer Funktionen zu einem bestehenden System ist es üblich, dass einige der für die Neuentwicklung erforderlichen Datenentitäten bereits in einer Datenbank vorhanden sind und daher wiederverwendet werden können. Die einzige Möglichkeit herauszufinden, welche Entitäten bereits existieren, besteht darin, aktuelle Datenmodelle zu durchsuchen, die die Strukturen der von der Organisation verwendeten Datenbanken angemessen beschreiben.
Konzeptionelle, logische und physische Datenmodelle sollten beibehalten werden, um Ansichten mit unterschiedlichen Abstraktionsebenen bereitzustellen, damit Sie wiederverwendbare Datenbestände einfach erkennen können. Sie können ein spezialisiertes Designtool wie die Vertabelo-Plattform nutzen, um die Erstellung verschiedener Arten von Datenmodellen zu vereinfachen und sogar voneinander abzuleiten.
Diese gute Praxis vermeidet die Generierung redundanter Daten in verschiedenen Schemas, was früher oder später zu inkonsistenten Informationen führt (mehr dazu weiter unten).
Migration zu Cloud-Umgebungen
Bei DaaS (Data as a Service)-Infrastrukturen oder Datenbanken in der Cloud gelten bestimmte Anforderungen, wie z. B. Datenbank-Datenschutz , dynamische Skalierbarkeit und Effizienz bei der Verwaltung mehrerer Mandanten , kritischer werden.
Datenmodelle sind ein unschätzbares Werkzeug, um diese Anforderungen zu erfüllen, da sie die Verifizierung erleichtern, dass ein Schemaentwurf ihnen entspricht. Sie ermöglichen es Ihnen wiederum, die Partitionen der Schemas und ihre Speicheranforderungen zu definieren, was für die richtige Dimensionierung des erforderlichen Service-Levels und des erwarteten Speicherwachstums unerlässlich ist, wenn sich Datenbanken in privaten oder öffentlichen Clouds befinden.
Datenbankdesignartefakte wie ER-Diagramme sind die Werkzeuge der Wahl bei der Vorbereitung einer Migration in eine Cloud-Umgebung. Eine Anleitung zur Verwendung von ER-Diagrammen kann Ihnen einen Einblick in ihre Nützlichkeit bei der Datenbankmigration geben.
Datenbankmodellierung für Big Data und NoSQL
Nicht-relationale Datenbanken wie NoSQL und dimensionale Schemas können uns zwingen, unsere traditionelle relationale Denkweise (zumindest für einen Moment) beiseite zu legen. Das heißt aber nicht, dass wir auf Datenmodelle verzichten können. Im Gegenteil, die Datenmodellierung wird sogar noch wichtiger.
Wenn Sie mit Big Data arbeiten müssen, sehen Sie sich häufig riesigen Informationssilos gegenüber, die aufgeschlüsselt, verfeinert und so strukturiert werden müssen, dass Sie oder ein Datenanalyst daraus strategische Erkenntnisse gewinnen können. Ein sorgfältiges Schemadesign ist erforderlich, sowohl für verfeinerte Informationsrepositories oder Data Warehouses als auch für Staging-Repositories, die für Datenbereinigungs- und Datenstrukturierungsprozesse verwendet werden.
Es gibt ein Missverständnis, hauptsächlich unter Programmierern, dass NoSQL-Datenbanken keine Schemata verwenden und daher keine Datenmodelle benötigen. Nichts könnte weiter von der Wahrheit entfernt sein. Da NoSQL-Technologien keine standardisierte Methode zum Anzeigen der Metadaten bieten (etwas, das jedes RDBMS tut), werden Datenmodelle unerlässlich, damit Benutzer die in der Datenbank gespeicherten Informationen verwenden und teilen können.
Fusionen und Übernahmen
Jede Fusion zwischen zwei Organisationen stellt die jeweiligen IT-Abteilungen vor eine gigantische Herausforderung. Ein wesentlicher Teil dieser Herausforderung liegt in der Datenbankkonsolidierung. Wenn beide Organisationen über aktuelle Datenmodelle verfügen, kann diese Konsolidierung in den Modellen statt direkt in den Datenbanken erfolgen, wodurch der Aufwand für diese Aufgabe erheblich reduziert wird.
Bisher haben wir die Vorteile der Datenmodellierung im Zusammenhang mit der strategischen IT-Planung einer Organisation gesehen. Wenn diese Gründe nicht ausreichen, um Sie von der Bedeutung der Datenmodellierung zu überzeugen, schauen wir uns auch die Vorteile an, die sie für die Softwareentwicklung bringt.
Reduzierte Entwicklungskosten
In den frühen Phasen eines Entwicklungsprojekts, wenn das Budget analysiert wird, kann die Notwendigkeit, sich um den Aufbau eines Datenmodells zu bemühen, in Frage gestellt werden. Wenn die Projektleiter und Manager schlau genug sind, werden sie die Kosten für den Aufbau und die Pflege eines Datenmodells mit den eingesparten Kosten vergleichen und sich für den Aufbau des Modells entscheiden.
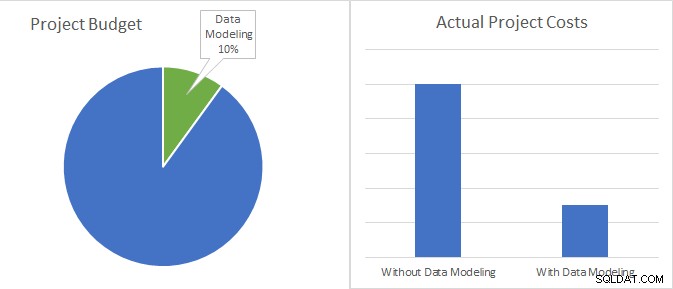
Datenmodellierung macht nur 10 % aus eines Entwicklungsprojektbudgets und hat das Potenzial, die tatsächlichen Projektkosten auf weniger als ein Drittel zu reduzieren.
Bedenken Sie einfach Folgendes. In den meisten Fällen betragen die Kosten für die Datenmodellierung (d. h. die Kosten für den Aufwand zum Erstellen und Pflegen des Modells) weniger als 10 % des Gesamtbudgets für ein Softwareprojekt. Im Vergleich dazu belaufen sich die mit der Verwendung von Datenmodellen verbundenen Kosteneinsparungen auf bis zu 70 %, was alles auf die Reduzierung der Stunden für Codierung und Wartung zurückzuführen ist.
Der erste und wichtigste Grund für die Datenmodellierung in der Softwareentwicklung ist also der unbestreitbare ROI (Return on Investment), den Projektleiter in den frühen Phasen jedes Projekts berücksichtigen müssen.
Bessere Definitionen von Anforderungen
In der Softwareentwicklung können Sie ein besseres Verständnis des zu entwickelnden Systems gewährleisten, wenn Datenmodellierungsaktivitäten parallel zur Anforderungserhebung durchgeführt werden. Die Anforderungen werden vollständiger und korrekter.
Die Datenmodellierung hilft dabei, Geschäftsregeln aufzudecken und während des Requirements Engineering Fragen zu stellen, während gleichzeitig die Datenintegrität sichergestellt wird. Es ist effektiver als Prozessmodellierungsaktivitäten wie Anwendungsfalldesign oder Workflowdesign und offensichtlich aussagekräftiger und weniger ausführlich als die Kurzbeschreibung der Geschäftsregeln.
Schnellere Entwicklung
Wenn Entwickler über geeignete Datenmodelle verfügen, können sie ihre Arbeit mit weniger Fehlern erledigen. Datenmodellierungstools generieren und verwalten automatisch Datenbankschemata und erstellen DDL-Skripte (Data Definition Language), die für Entwickler oft zu lang, komplex und chaotisch sind, um sie manuell zu generieren.
Diese Tools wiederum fördern die Zusammenarbeit, indem sie die gemeinsame Nutzung von Modellen zwischen Entwicklern ermöglichen. Wenn Änderungen erforderlich sind, können Sie diese im Datenmodell vornehmen und sicherstellen, dass alle Entwickler informiert werden und dass sie auf die Datenbanken angewendet werden, ohne etwas zu beschädigen.
All dies ermöglicht es, die Systeme früher und mit weniger Fehlern auszuliefern.
Agile Methoden fördern
Agile Methoden zielen darauf ab, den Entwicklungsprozess zu beschleunigen, indem sie sich auf die Bereitstellung funktionierender Software konzentrieren und Bürokratie, übermäßige Dokumentation und nacheinander ausgeführte Phasen vermeiden.
Die Datenbankmodellierung steht bei der Arbeit in agilen Umgebungen vor einer großen Herausforderung, da der Designer in der Lage sein muss, am „großen Ganzen“ zu arbeiten, während Entwickler nur die Datenobjekte benötigen, die für jede User Story erforderlich sind. Um einen Konsens zwischen Datenmodellierern und Entwicklern zu erreichen, verwenden agile Methoden Techniken wie Sandboxing und Verzweigung .
Eine Sandbox ist die Arbeitsumgebung jedes Entwicklers. Der Designer kann mit den Zweigen des Hauptdatenmodells in der Sandbox jedes Entwicklers arbeiten, der Feedback gibt, um es zu verfeinern. Am Ende jeder Phase (oder jedes Sprints) führt der Datenbankdesigner die verschiedenen Zweige zusammen, um das vollständige Modell auf dem neuesten Stand zu halten.
Sie könnten denken, dass die Datenmodellierung agile Teams verlangsamt und dass Entwickler warten müssen, bis die Modelle bereit sind, ihre Arbeit zu beginnen. Aber in Wirklichkeit werden durch die Verwendung von Techniken wie Sandboxing und Branching die Prinzipien der Agilität beibehalten und gleichzeitig die oben erwähnten Geschwindigkeitsverbesserungen erzielt.
Was ist, wenn ich keine Datenmodelle verwende?
Man könnte meinen, dass man auch ohne die bisher erwähnten Vorteile von Datenmodellen auskommen kann, um Zeit zu sparen. Aber wenn Sie sich gegen die Datenmodellierung entscheiden, riskieren Sie ernsthafte Probleme wie:
- Unnötige Redundanz:Da es kein Modell gibt, um die Datenobjekte klar zu sehen, erscheinen verschiedene Versionen derselben Objekte mit unterschiedlichen Informationen. Beispielsweise kann ein Inventarsystem melden, dass 500 Einheiten eines Artikels im letzten Monat verkauft wurden, während ein Logistiksystem melden kann, dass 1000 Einheiten desselben Artikels im selben Zeitraum versandt wurden. Was ist richtig? Wer weiß.
- Träge Apps:Das Fehlen eines Datenmodells erschwert Optimierungsaufgaben, was die Reaktionsfähigkeit der Anwendungen verringert.
- Unfähigkeit, Qualitätsstandards zu erfüllen:Wenn kein Datenmodell vorhanden ist, werden Ihre Datenbanken nicht dokumentiert, was in Szenarien wie Datenbankmigrationen obligatorisch ist.
- Schlechte Softwarequalität:Die Anforderungen an die Softwareentwicklung sind gering und die Benutzer haben nicht die Anwendungen, die sie benötigen oder wünschen.
- Höhere Entwicklungskosten:Ich habe bereits die erheblichen Kosteneinsparungen erwähnt, die in einem Entwicklungsprojekt durch den Einsatz von Datenmodellen erzielt werden können. Wenn Sie sich entscheiden, sie nicht zu verwenden, müssen Sie entscheiden, wer für die zusätzlichen Entwicklungs- und Wartungskosten aufkommt. Und wer entschuldigt sich, wenn die Fristen nicht eingehalten werden.
Immer noch nicht überzeugt?
Wenn das, was Sie bisher gelesen haben, nicht ausreicht, um Sie von der Bedeutung der Datenmodellierung zu überzeugen, denken Sie daran, dass Daten für alle Arten von Organisationen zu einem immer wertvolleren Gut werden. Die Modellierung der Strukturen zur Nutzung von Informationen ist heute von beispielloser Bedeutung.
Bedenken Sie Folgendes:Während des Goldrausches verdienten nicht die Leute, die nach Goldnuggets gruben, das meiste Geld, sondern diejenigen, die die Werkzeuge zur Verfügung stellten, um das Gold zu extrahieren. Im Jahr 2021 kommen Goldnuggets in Form von aufschlussreichen Informationen, und die Bergleute, die solch wertvolles Material fördern, müssen mit Datenmodellen versorgt werden.