Wir werden Oracle-Indizes/Indextypen in Oracle anhand von Beispielen in diesem Beitrag diskutieren. Ich werde alle Optionen zum Erstellen von Indizes in Oracle beleuchten. Ich würde auch diskutieren, wie die Indexgröße in Oracle überprüft wird. Ich hoffe, Ihnen wird dieser Beitrag gefallen. Ich freue mich auf Feedback zu diesem Beitrag
Was sind Oracle-Indizes?
- So wie wir in den Lehrbüchern einen Index haben, der uns hilft, das bestimmte Thema im Buch zu finden, verhält sich der Oracle-Index genauso. Wir haben verschiedene Arten von Indexen in Oracle.
- Indizes werden verwendet, um die Zeilen in der Oracle-Tabelle schnell zu durchsuchen. Wenn der Index nicht vorhanden ist, muss die Auswahlabfrage die gesamte Tabelle lesen und die Zeilen zurückgeben. Mit Index können die Zeilen schnell abgerufen werden
- Wir sollten Indizes erstellen, wenn wir eine kleine Anzahl von Zeilen aus einer Tabelle abrufen. oder um den ersten Satz von Zeilen so schnell wie möglich aus einer Abfrage abzurufen, die letztendlich eine große Anzahl von Zeilen zurückgibt. Es hängt auch von der Datenverteilung ab, d. h. dem Clusterfaktor
- Indizes sind logisch und physisch unabhängig von den Daten in der zugeordneten Tabelle.
- Indizes sind optionale Strukturen, die Tabellen und Clustern zugeordnet sind. Sie können Indizes für eine oder mehrere Spalten einer Tabelle erstellen, um die Ausführung von SQL-Anweisungen für diese Tabelle zu beschleunigen.
- Indizes sind das primäre Mittel zur Reduzierung der Festplatten-E/A, wenn sie richtig verwendet werden.
- Die Abfrage entscheidet am Anfang ob index oder no verwendet wird
- Das Beste an Indizes ist, dass die Abrufleistung von indizierten Daten nahezu konstant bleibt, selbst wenn neue Zeilen eingefügt werden. Das Vorhandensein vieler Indizes in einer Tabelle verringert jedoch die Leistung von Aktualisierungen, Löschungen und Einfügungen, da Oracle auch die mit der Tabelle verknüpften Indizes aktualisieren muss.
- Wenn Sie Eigentümer einer Tabelle sind, können Sie einen Index erstellen, oder wenn Sie einen Index für eine Tabelle in einem anderen Schema erstellen möchten, sollten Sie entweder über das Systemprivileg CREATE ANY INDEX oder das Indexprivileg für diese Tabelle verfügen
Logischer Indextyp
Es definiert die Anwendungsmerkmale des Index
| Eindeutig oder nicht eindeutig | Ein Index kann eindeutig oder nicht eindeutig sein. Oracle erstellt einen eindeutigen Index für den Primärschlüssel und Einschränkungen für eindeutige Schlüssel Wenn in dieser Spalte bereits nicht eindeutige Indizes vorhanden sind, wird kein neuer eindeutiger Index für den Primärschlüssel in Oracle erstellt |
| Zusammengesetzt | Der Index kann aus einer oder mehreren Spalten bestehen. Zusammengesetzte Indizes können das Abrufen von Daten für SELECT-Anweisungen beschleunigen, in denen die WHERE-Klausel auf alle oder den führenden Teil der Spalten im zusammengesetzten Index verweist. |
| Funktionsbasierte Indizes | Die Daten der indizierten Spalte basieren auf einer Berechnung |
| Anwendungsdomänenindizes | Dieser Index wird in speziellen Anwendungen (Spatial, Text) verwendet.
|
Was ist die ROWID-Pseudospalte
ROWID gibt die Adresse jeder Zeile in der Tabelle zurück. Oracle weist jeder Zeile eine ROWID zu. ROWID besteht aus Folgendem
- Die Datenobjektnummer des Objekts
- Der Datenblock in der Datendatei, in der sich die Zeile befindet
- Die Position der Zeile im Datenblock (erste Zeile ist 0)
- Die Datendatei, in der sich die Zeile befindet (erste Datei ist 1). Die Dateinummer ist relativ zum Tablespace.
Oracle verwendet ROWID intern, um auf Zeilen zuzugreifen. Beispielsweise speichert Oracle ROWID im Index und verwendet sie, um auf die Zeile in der Tabelle zuzugreifen.
Sie können die ROWID von Zeilen mit dem SELECT-Befehl wie folgt anzeigen:
select rowid, emp_name from emp;
ROWID EMP_NAME
AAADC576474722aSAAA John
Oracle stellt ein Paket namens DBMS_ROWID bereit, um ROWID zu decodieren.
Sobald einer Zeile eine ROWID zugewiesen wurde, ändert Oracle die ROWID während der Lebensdauer der Zeile nicht. Aber es ändert sich, wenn die Tabelle neu erstellt wird, wenn Zeilen über die Partition verschoben werden oder die Tabelle verkleinert wird
Arten von Indizes in Oracle mit Beispiel
Es gibt 6 verschiedene Arten von Indizes in Oracle
(1) B-Baum
(2) Komprimierter B-Baum
(3) Bitmap
(4) Funktionsbasiert
(5) Umgekehrter Schlüssel (RKI)
(6) Indexorganisierte Tabelle (IOT).
Lassen Sie uns jeden von ihnen im Detail herausfinden und wie man einen Index in Oracle für jeden dieser Typen erstellt
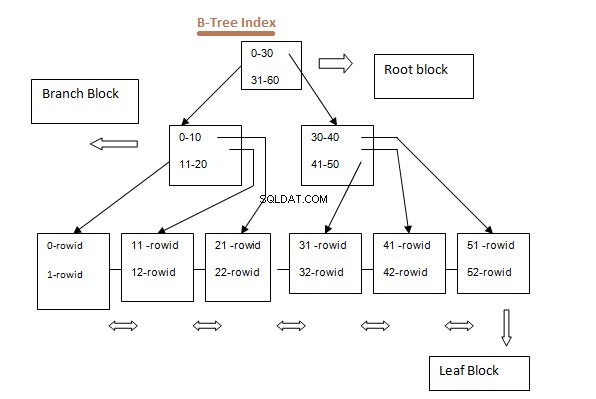
B – Baumindex:
- B-Tree-Indizes (ausgeglichener Baum) sind der häufigste Indextyp.
- B-Tree-Index speicherte die ROWID und den Indexschlüsselwert in einer Baumstruktur.
- Beim Erstellen eines Indexes wird ein ROOT-Block erstellt, dann werden BRANCH-Blöcke erstellt und schließlich LEAF-Blöcke.
- Jeder Zweig enthält den Datenbereich, den seine Blattblöcke enthalten, und jede Wurzel enthält den Datenbereich, den seine Zweige enthalten:
- B-Tree-Indizes sind am nützlichsten für Spalten, die in der where-Klausel erscheinen (SELECT … WHERE EMPNO=1).
- Der Oracle-Server hält den Baum im Gleichgewicht, indem er Indexblöcke aufteilt, wenn neue Daten in die Tabelle eingefügt werden.
- Wann immer eine DML-Anweisung für die Indextabelle ausgeführt wird, findet eine Indexaktivität statt, wodurch der Index wächst (Blatt und Zweige hinzufügen).
Vorteile
- Alle Blattblöcke des Baumes sind gleich tief.
- B-Tree-Indizes bleiben automatisch ausgeglichen.
- Alle Blöcke des B-Baums sind im Durchschnitt zu drei Vierteln gefüllt.
- B-Trees bieten eine hervorragende Abrufleistung für eine Vielzahl von Abfragen, einschließlich exakter Übereinstimmungen und Bereichssuchen.
- Einfügungen, Aktualisierungen und Löschungen sind effizient, wobei die Schlüsselreihenfolge für einen schnellen Abruf beibehalten wird.
- Die B-Tree-Leistung ist sowohl für kleine als auch für große Tabellen gut und nimmt nicht ab, wenn die Größe einer Tabelle zunimmt.
CREATE <UNIQUE|NON UNIQUE> INDEX <index_name> ON <table_name> (<column_name>,<column_name>…) TABLESPACE <tablespace_name>; Example Create index scott.exp_idx on table scott.example( name) Tablespace TOOLS;
Was sind komprimierte B-Tree-Indizes
- Komprimierte B-Tree-Indizes werden auf großen Tabellen in einer Data-Warehouse-Umgebung erstellt. Bei dieser Art von Index werden doppelte Vorkommen desselben Werts eliminiert, wodurch der Speicherplatz verringert wird, den der Index benötigt.
- In einem komprimierten B-Tree-Index wird für jeden Schlüsselwert eine Liste von ROWIDs geführt
- Die Angabe des Schlüsselworts COMPRESS beim Erstellen eines Indexes (CREATE INDEX … COMPRESS) erstellt einen komprimierten B-Tree-Index.
- Ein regulärer B-Tree-Index kann mit dem Schlüsselwort COMPRESS neu erstellt werden, um ihn zu komprimieren.
CREATE <UNIQUE|NON UNIQUE> INDEX <index_name> ON <table_name> (<column_name>,<column_name>…) PCTFREE <integer> TABLESPACE <tablespace_name> Compress <column number>
Was sind Bitmap-Indizes
- Bitmap-Indizes eignen sich am besten für Daten mit geringer unterschiedlicher Kardinalität (im Gegensatz zu B-Tree-Indizes).
- Diese Art von Index erstellt eine binäre Karte aller Indexwerte und speichert diese Karte in den Indexblöcken, das bedeutet, dass der Index weniger Platz benötigt als der B-Tree-Index.
- Jedes Bit in der Bitmap entspricht einer möglichen Zeilen-ID. Wenn das Bit gesetzt ist, bedeutet dies, dass die Zeile mit der entsprechenden Rowid den Schlüsselwert enthält. Eine Zuordnungsfunktion konvertiert die Bitposition in eine tatsächliche Zeilen-ID, sodass der Bitmap-Index die gleiche Funktionalität wie ein regulärer Index bietet, obwohl er intern eine andere Darstellung verwendet. Wenn die Anzahl unterschiedlicher Schlüsselwerte klein ist, dann sind Bitmap-Indizes sehr platzsparend
- Wenn es Bitmap-Indizes für Tabellen gibt, werden durch Aktualisierungen vollständige Tabellensperren entfernt. Bitmap-Indizes sind also für große Spalten mit niedriger DML-Aktivität (seltene Aktualisierungen) oder Nur-Lese-Tabellen nützlich. Aus diesem Grund werden Bitmap-Indizes häufig in der Data-Warehouse-Umgebung (DWH) verwendet.
- Die Bitmap-Indexstruktur enthält eine Map von Bits, die den Wert in der Spalte angeben, zum Beispiel enthält der Indexblock für die Spalte GENDER die Start-ROWID, die End-ROWID und die Bitmap:
- Bitmap-Indizes sind sehr nützlich, wenn sie für Spalten mit niedriger Kardinalität erstellt und mit dem AND &OR-Operator in der Abfragebedingung verwendet werden:
CREATE BITMAP INDEX <index_name> ON <table_name> (<column_name>,<column_name>…) PCTFREE <integer> TABLESPACE <tablespace_name>
Beispiel
CREATE BITMAP INDEX ON emp_data(gender); SELECT COUNT(*) FROM emp_data WHERE GENDER=’M”;
Vorteile von Bitmap-Indizes
- Reduzierte Antwortzeit für große Klassen von Abfragen
- Eine erhebliche Reduzierung des Speicherplatzverbrauchs im Vergleich zu anderen Indexierungstechniken
- Dramatische Leistungssteigerungen selbst auf sehr Low-End-Hardware
- Sehr effiziente parallele DML und Lasten
Funktionsbasierte Indizes
Funktionsbasierte Indizes sind Indizes, die auf Spalten erstellt werden, auf die normalerweise eine Funktion angewendet wird.
Wenn eine Funktion auf eine indizierte Spalte angewendet wird, wird der Index ignoriert, daher ist ein funktionsbasierter Index für diese Operationen sehr nützlich.
CREATE INDEX <index_name> ON <table_name> [ Function(<column_name>,<column_name.)] TABLESPACE <tablespace_name>; Example CREATE INDEX EMP_IDX on EMP(UPPER(ENAME)); SELECT * FROM Emp WHERE UPPER(Ename) like ‘JOHN`;
Was sind Reverse-Key-Indizes
- Sie sind spezielle Arten von B-Tree-Indizes und sehr nützlich, wenn sie für Spalten erstellt werden, die fortlaufende Nummern enthalten.
- Bei Verwendung eines regulären B-Baums wächst der Index auf viele Verzweigungen und möglicherweise mehrere Ebenen an, was zu Leistungseinbußen führt. Das RKI löst das Problem, indem es die Bytes jedes Spaltenschlüssels umkehrt und die neuen Daten indiziert. li>
- Diese Methode verteilt die Daten gleichmäßig im Index. Das Erstellen eines RKI erfolgt mit dem Schlüsselwort REVERSE:CREATE INDEX … ON … REVERSE;
CREATE INDEX <index_name> ON <table_name> (<column_name>) TABLESPACE <tablespace_name> REVERSE; Example CREATE INDEX emp_idx i ON emp_table (firstname,lastname) REVERSE;
Was sind indexorganisierte Tabellen (IOT) –
- Bei der Verwendung von B-Tree, Bitmap und Reverse Key werden Indizes für Tabellen verwendet, die Daten ungeordnet speichern (Heap-Tabellen).
- Diese Indizes enthalten die Position der ROWID der erforderlichen Tabellenzeile und ermöglichen so den direkten Zugriff auf die Zeilendaten
- Eine indexorganisierte Tabelle unterscheidet sich von einer gewöhnlichen Tabelle, da die Daten für die Tabelle in ihrem zugeordneten Index gespeichert werden. Änderungen an den Tabellendaten, wie das Hinzufügen neuer Zeilen, das Aktualisieren von Zeilen oder das Löschen von Zeilen, führen zu einer Aktualisierung des Index.
- Die indexorganisierte Tabelle ist wie eine gewöhnliche Tabelle mit einem Index für eine oder mehrere ihrer Spalten, aber anstatt zwei getrennte Speicher für die Tabelle und den B-Tree-Index beizubehalten, verwaltet das Datenbanksystem nur einen einzigen B-Baum-Index. Baumindex, der sowohl den verschlüsselten Schlüsselwert als auch die zugehörigen Spaltenwerte für die entsprechende Zeile enthält. Anstatt die Zeilen-ID einer Zeile als zweites Element des Indexeintrags zu haben, wird die eigentliche Datenzeile im B-Tree-Index gespeichert. Die Datenzeilen basieren auf dem Primärschlüssel für die Tabelle, und jeder B-Tree-Indexeintrag enthält
- Es gibt keine Duplizierung von Schlüsselwerten, da nur Spaltenwerte, die keine Schlüssel sind, mit dem Schlüssel gespeichert werden. Sie können sekundäre Indizes erstellen, um einen effizienten Zugriff durch andere Spalten bereitzustellen. Anwendungen bearbeiten die indexorganisierte Tabelle mithilfe von SQL-Anweisungen wie eine gewöhnliche Tabelle. Das Datenbanksystem führt jedoch alle Operationen aus, indem es den entsprechenden B-Tree-Index manipuliert.
Funktionen der nach Index organisierten Tabelle
- Der Primärschlüssel identifiziert eine Zeile eindeutig; Primärschlüssel muss angegeben werden
- Primärschlüsselbasierter Zugriff
- Logische Zeilen-ID in ROWID-Pseudospalte ermöglicht das Erstellen sekundärer Indizes
- UNIQUE-Einschränkung nicht erlaubt, aber Trigger sind erlaubt
- Kann nicht in einem Cluster gespeichert werden
- Kann LOB-Spalten enthalten, aber keine LONG-Spalten
- Verteilung und Replikation werden nicht unterstützt
CREATE TABLE command: CREATE TABLE … ORGANIZATION INDEX TABLESPACE … (specify this is an IOT) PCTTHRESHOLD … (specify % of block to hold in order to store row data, valid 0-50 (default 50)) INCLUDING … (specify which column to break a row when row length exceeds PCTTHRESHOLD) OVERFLOW TABLESPACE … (specify the tablespace where the second part of the row will be stored) MAPPING TABLE; (cause creation of a mapping table, needed when creating Bitmap index on IOT)
Die Zuordnungstabelle ordnet die physischen ROWIDs des Index den logischen ROWIDs im IOT zu. IOT verwendet logische ROWIDs, um den Tabellenzugriff nach Index zu verwalten, da physische ROWIDs geändert werden, wenn Daten zur Tabelle hinzugefügt oder daraus entfernt werden. Um den IOT von anderen Indizes zu unterscheiden, fragen Sie die Ansicht USER_INDEXES mit der Spalte pct_direct_access ab. Nur IOT hat einen Nicht-NULL-Wert für diese Spalte.
Anwendungsdomänenindizes
Oracle bietet erweiterbare Indizierung Indizes für komplexe Datentypen wie Dokumente, räumliche Daten, Bilder und Videoclips aufzunehmen und spezialisierte Indizierungstechniken zu verwenden.
Mit erweiterbarer Indexierung können Sie anwendungsspezifische Indexverwaltungsroutinen als Indextyp kapseln Schemaobjekt und definieren Sie einen Domänenindex (ein anwendungsspezifischer Index) auf Tabellenspalten oder Attribute eines Objekttyps. Die erweiterbare Indizierung bietet auch eine effiziente Verarbeitung des anwendungsspezifischen Operators s.
Die Anwendungssoftware, genannt Cartridge e, steuert die Struktur und den Inhalt eines Domain-Index. Der Oracle-Server interagiert mit der Anwendung, um den Domänenindex zu erstellen, zu verwalten und zu durchsuchen. Die Indexstruktur selbst kann in der Oracle-Datenbank als indexorganisierte Tabelle oder extern als Datei gespeichert werden.
Domain-Indizes verwenden
Domänenindizes werden mithilfe der Indizierungslogik erstellt, die von einem benutzerdefinierten Indextyp bereitgestellt wird. Ein Indextyp bietet einen effizienten Mechanismus für den Zugriff auf Daten, die bestimmte Operatorprädikate erfüllen. Typischerweise ist der benutzerdefinierte Indextyp Teil einer Oracle-Option, wie die Spatial-Option.
Beispielsweise ermöglicht der SpatialIndextype die effiziente Suche und den Abruf von räumlichen Daten, die einen bestimmten Begrenzungsrahmen überlappen.
Die Cartridge bestimmt die Parameter, die Sie beim Erstellen und Verwalten des Domänenindex angeben können. Ebenso werden die Leistungs- und Speichereigenschaften des Domänenindex in der spezifischen Cartridge-Dokumentation dargestellt.
Bisher haben wir verschiedene Arten von Indexen in Oracle anhand eines Beispiels behandelt. Sehen wir uns nun an, wie sie geändert/gelöscht/neu erstellt werden können
Wie man die Indizes neu erstellt/Index in Oracle neu erstellt
Wir können die Anweisung ALTER INDEX … REBUILD verwenden, um einen vorhandenen Index neu zu organisieren oder zu komprimieren oder seine Speichereigenschaften zu ändern
Die REBUILD-Anweisung verwendet den bestehenden Index als Basis für den neuen.
ALTER INDEX … REBUILD ist normalerweise schneller als das Löschen und Neuerstellen eines Index.
Es liest alle Indexblöcke mit Multiblock-I/O und verwirft dann die Verzweigungsblöcke.
Ein weiterer Vorteil dieses Ansatzes besteht darin, dass der alte Index während des Neuaufbaus weiterhin für Abfragen verfügbar ist.
Alter index <index name> rebuild ; Alter index <index name> rebuild tablespace <name>;
Wie man Anweisungen schreibt, die die Verwendung von Indizes vermeiden
- Sie können den Optimierungshinweis NO_INDEX verwenden, um dem CBO maximale Flexibilität zu geben und gleichzeitig die Verwendung eines bestimmten Index zu untersagen.
- Sie können den FULL-Hinweis verwenden, um den Optimierer zu zwingen, einen vollständigen Tabellenscan anstelle eines Indexscans zu wählen.
- Sie können die INDEX-, INDEX_COMBINE- oder AND_EQUAL-Hinweise verwenden, um den Optimierer zu zwingen, einen Index oder einen Satz aufgelisteter Indizes anstelle eines anderen zu verwenden.
Erstellen von Statistiken für Indizes
Indexstatistiken werden mit der Anweisung ANALYZE INDEX oder dbms_stats gesammelt.
Verfügbare Optionen sind COMPUTE/ESTIMATE STATISTICS oder VALIDATE STRUCTURE.
Ab 10 g werden beim Erstellen des Index automatisch Statistiken erstellt
Bei Verwendung der Validierungsstruktur füllt Oracle die Ansicht INDEX_STATS mit Statistiken zum analysierten Index. Die Statistik enthält die Anzahl der Blattreihen und -blöcke (LF_ROWS, LF_BLKS), die Anzahl der Verzweigungsreihen und -blöcke (BR_ROWS, BR_BLKS), die Anzahl der gelöschten Blattreihen (DEL_LF_ROWS), den belegten Speicherplatz (USED_SPACE), die Anzahl der eindeutigen Schlüssel (DISTINCT_KEYS) usw. Diese Statistiken können verwendet werden, um zu bestimmen, ob der Index neu erstellt werden sollte oder nicht
Wie entscheidet Oracle über die Verwendung des Index?
Oracle entscheidet automatisch, ob der Index von der Optimizer-Engine verwendet werden soll.
Oracle entscheidet abhängig von der Abfrage, ob ein Index verwendet wird oder nicht.
Oracle kann nachvollziehen, ob die Verwendung eines Index die Leistung in der angegebenen Abfrage verbessert. Wenn Oracle der Meinung ist, dass die Verwendung eines Index die Leistung verbessert, verwendet es den Index, andernfalls ignoriert es den Index.
Lassen Sie es uns anhand dieses Beispiels verstehen
Wir haben eine Tabelle emp die emp_name, Gehalt, Abt.-Nr., Emp_nr., Datum_des_Beitritts enthält, und wir haben einen Index für emp_name
Abfrage 1
select * from emp where emp_name = 'John';
Die obige Abfrage verwendet den Index, da wir versuchen, Informationen über einen Emp anhand des Namens zu erhalten.
Abfrage 2
select * from emp;
Die obige Abfrage verwendet den Index nicht, da wir versuchen, alle Zeilen in der Tabelle zu finden, und wir keine Where-Klausel in der Abfrage haben
Abfrage 3
select * from emp where dept_no =5;
Die obige Abfrage verwendet den Index nicht, da die where-Klausel nicht die Spalte auswählt, die einen Index hat
Abfrage 4
select * from emp where substr(emp_name,1,4) =’XYZW’;
Die obige Abfrage verwendet den Index nicht, da die where-Klausel die Funktion für die Spalte verwendet und wir keinen funktionalen Index für emp_name
habenWie erstelle ich den Index online oder erneuere ihn?
In älteren Versionen hat Oracle während des gesamten Erstellungsprozesses die Tabelle gesperrt, für die der Index erstellt wird. Dadurch wird die Tabelle für die Datenmanipulation während der Indexerstellung nicht verfügbar.
Mit 8i hat Oracle jetzt die Online-Neuerstellung des Index eingeführt, bei der Oracle die Tabelle, auf der der Index erstellt wird, nicht sperrt.
Die Online-Indexierung erfolgt über das Schlüsselwort ONLINE.
CREATE <UNIQUE|NON UNIQUE> INDEX <index_name> ON <table_name> (<column_name>,<column_name>…) PCTFREE <integer> TABLESPACE <tablespace_name> Online; Alter index <index name> rebuild online;
Grundsätzlich sperrt Oracle bei einem Online-Rebuild die Tabelle zu Beginn und am Ende der Indexerstellung. Es ermöglicht Transaktionen dazwischen. Der Mechanismus wurde mit 11g und 12c stark verbessert
Was sind die Nachteile der Indizes
Indizes erhöhen die Leistung einer ausgewählten Abfrage, sie können auch die Leistung der Datenmanipulation verringern.
Viele Indizes für eine Tabelle können INSERTS und DELETES drastisch verlangsamen
Je mehr Indizes in der Tabelle vorhanden sind, desto länger dauert das Einfügen und Löschen.
Ebenso erfordert jede Änderung an einer indizierten Spalte eine Änderung am Index.
Daher müssen wir den Index sehr sorgfältig auswählen und die nicht verwendeten löschen.
Obwohl der zusätzliche Speicherplatz, der von Indizes belegt wird, ebenfalls berücksichtigt werden muss, spielt dies möglicherweise keine große Rolle, da die Kosten für die Datenspeicherung erheblich gesunken sind.
Was sind unbrauchbare Indizes
Ein unbrauchbarer Index wird vom Optimierer bei der Entscheidung über den Explain-Plan ignoriert
Es wird auch nicht von DML gepflegt, d. h. update, insert, delete aktualisiert den Index
Es kann mehrere Gründe dafür geben, dass sich der Index in einem unbrauchbaren Zustand befindet. Sie haben die Tabelle neu erstellt, aber den Index nicht neu erstellt, dann befindet sich der Index in einem unbrauchbaren Zustand. Ein weiterer Grund, einen Index unbrauchbar zu machen, besteht darin, die Massenladeleistung zu verbessern. Ein weiterer Grund könnte sein, dass der Optimierer jedes Mal den falschen Index aufgreift und die Zeit kritisch ist, sodass Sie sich entscheiden können, ihn unbrauchbar zu machen
Ein nicht verwendbarer Index oder eine Indexpartition muss neu erstellt oder gelöscht und neu erstellt werden, bevor sie verwendet werden kann. Das Abschneiden einer Tabelle macht einen unbrauchbaren Index gültig.
Ab Oracle Database 11g Release 2 wird das Indexsegment gelöscht, wenn Sie einen vorhandenen Index unbrauchbar machen.
Die Funktionalität nicht verwendbarer Indizes hängt von der Einstellung des Initialisierungsparameters SKIP_UNUSABLE_INDEXES ab.
Wenn SKIP_UNUSABLE_INDEXES TRUE ist (Standard), dann:
DML-Anweisungen gegen die Tabelle werden fortgesetzt, aber unbrauchbare Indizes werden nicht beibehalten.
DML-Anweisungen werden mit einem Fehler beendet, wenn unbrauchbare Indizes vorhanden sind, die zur Durchsetzung der UNIQUE-Einschränkung verwendet werden.
Bei nicht partitionierten Indizes berücksichtigt der Optimierer beim Erstellen eines Zugriffsplans für SELECT-Anweisungen keine unbrauchbaren Indizes. Die einzige Ausnahme ist, wenn ein Index explizit mit dem INDEX()-Hinweis angegeben wird.
Wenn SKIP_UNUSABLE_INDEXES FALSE ist, dann:
Wenn unbrauchbare Indizes oder Indexpartitionen vorhanden sind, werden alle DML-Anweisungen, die dazu führen würden, dass diese Indizes oder Indexpartitionen aktualisiert werden, mit einem Fehler beendet.
Wenn bei SELECT-Anweisungen ein unbrauchbarer Index oder eine unbrauchbare Indexpartition vorhanden ist, der Optimierer sich jedoch nicht dafür entscheidet, ihn für den Zugriffsplan zu verwenden, fährt die Anweisung fort. Entscheidet sich der Optimierer jedoch dafür, den unbrauchbaren Index oder die unbrauchbare Indexpartition zu verwenden, wird die Anweisung mit einem Fehler beendet.
Datenwörterbuchansichten auf Indizes
| DBA_INDEXES ALL_INDEXES USER_INDEXES | DBA-Ansicht beschreibt Indizes für alle Tabellen in der Datenbank. Die ALL-Ansicht beschreibt Indizes für alle Tabellen, auf die der Benutzer zugreifen kann. Die USER-Ansicht ist auf Indizes beschränkt, die dem Benutzer gehören. Einige Spalten in diesen Ansichten enthalten Statistiken, die vom DBMS_STATS-Paket oder der ANALYZE-Anweisung generiert werden. |
| DBA_IND_COLUMNS ALL_IND_COLUMNS USER_IND_COLUMNS | Diese Ansichten beschreiben die Spalten von Indizes für Tabellen. Einige Spalten in diesen Ansichten enthalten Statistiken, die vom DBMS_STATS-Paket oder der ANALYZE-Anweisung generiert werden. |
| DBA_IND_EXPRESSIONS ALL_IND_EXPRESSIONS USER_IND_EXPRESSIONS | Diese Ansichten beschreiben die Ausdrücke von funktionsbasierten Indizes für Tabellen. |
| DBA_IND_STATISTICS ALL_IND_STATISTICS USER_IND_STATISTICS | Diese Ansichten enthalten Optimierungsstatistiken für Indizes. |
wie man Indizes in einer Tabelle findet
set pagesize 50000 verify off echo off
col table_name head 'Table Name' format a20
col index_name head 'Index Name' format a25
col column_name head 'Column Name' format a30
break on table_name on index_name
select table_name, index_name, column_name
from all_ind_columns
where table_name like upper('&Table_Name')
order by table_name, index_name, column_position
/
So bestimmen Sie die Indexgröße
Size of INDEX select segment_name,sum(bytes)/1024/1024/1024 as "SIZE in GB" from user_segments where segment_name='INDEX_NAME' group by segment_name; OR select owner,segment_name,sum(bytes)/1024/1024/1024 as "SIZE in GB" from dba_segments where owner='SCHEMA_NAME' and segment_name='INDEX_NAME' group by owner,segment_name; List of Size of all INDEXES of a USER select segment_name,sum(bytes)/1024/1024/1024 as "SIZE in GB" from user_segments where segment_type='INDEX' group by segment_name order by "SIZE in GB" desc; OR select owner,segment_name,sum(bytes)/1024/1024/1024 as "SIZE in GB" from dba_segments where owner='SCHEMA_NAME' and segment_type='INDEX' group by owner,segment_name order by "SIZE in GB" desc; Sum of sizes of all indexes select owner,sum(bytes)/1024/1024/1024 as "SIZE in GB" from dba_segments where owner='SCHEMA_NAME' and segment_type='INDEX' group by owner;
So bestimmen Sie den Index Definition
set long 4000
select dbms_metadata.get_ddl('INDEX','<INDEX Name>','<INDEX OWNER') from dual;
Ermitteln der Indexstatistik
set pages 250
set linesize 100
set verify off
col table_name format a24 heading 'TABLE NAME'
col index_name format a23 heading 'INDEX NAME'
col u format a1 heading 'U'
col blevel format 0 heading 'BL'
col leaf_blocks format 999990 heading 'LEAF|BLOCKS'
col distinct_keys format 9999990 heading 'DISTINCT|KEYS'
col avg_leaf_blocks_per_key format 9999990 heading 'LEAF|BLKS|/KEY'
col avg_data_blocks_per_key format 9999990 heading 'DATA|BLKS|/KEY'
rem
break on table_name
rem
select table_name, index_name,
decode( uniqueness, 'UNIQUE', 'U', null ) u,
blevel, leaf_blocks, distinct_keys,
avg_leaf_blocks_per_key, avg_data_blocks_per_key
from sys.dba_indexes
where table_owner like upper('&owner')
and table_name like upper('&table')
order by table_owner, table_name, index_name;
Verwandte Artikel
Externe Tabellen in Oracle :In diesem Beitrag finden Sie Informationen zur Verwendung der externen Tabellen in Oracle mit einem Beispiel, wie Sie eine externe Tabelle erstellen und verwenden
Oracle Tabelle erstellen :Tabellen sind die grundlegende Dateneinheit Speicherung in einer Oracle-Datenbank. Wir behandeln die Verwendung des Oracle-Befehls „Create Table“, um eine Tabelle mit einem Fremdschlüssel /Primärschlüssel zu erstellen br/>Indexstatus und zugewiesene Spalten für eine Tabelle finden
Virtual Index in Oracle:Was ist Virtual Index in Oracle? Verwendungen, Einschränkungen, Vorteile und Verwendung zur Überprüfung, um den Plan in der Oracle-Datenbank zu erklären, versteckter Parameter _USE_NOSEGMENT_INDEXES
Oracle-Index-Clustering-Faktor:Wie der Oracle-Index-Clustering-Faktor berechnet wird und wie er sich auf den Explain-Plan auswirkt
Oracle-Partition Index:Grundlegendes zum Oracle-Partitionsindex, Was sind globale, nicht partitionierte Indizes?, Was sind lokale Indizes mit Präfix, lokale Indizes ohne Präfix
Empfohlene Kurse
Hier ist der nette Udemy-Kurs für Oracle SQL
Oracle-Sql-Schritt-für-Schritt :Dieser Kurs behandelt grundlegendes SQL, Joins, Erstellen von Tabellen und Ändern ihrer Struktur, Erstellen von Ansichten, Union, Union -all und vieles mehr . Ein großartiger Kurs und ein Muss für SQL-Einsteiger
Der vollständige Oracle SQL-Zertifizierungskurs  :Dies ist ein guter Kurs für alle, die für SQL-Entwicklerfähigkeiten einsatzbereit werden möchten. Ein gut erklärter Kurs
:Dies ist ein guter Kurs für alle, die für SQL-Entwicklerfähigkeiten einsatzbereit werden möchten. Ein gut erklärter Kurs
Oracle SQL Developer:Grundlagen, Tipps und Tricks  :Das Oracle Sql-Entwicklertool wird von vielen Entwicklern verwendet. Dieser Kurs gibt uns Tricks und Lektionen, wie man es effektiv nutzt und ein produktiver SQL-Entwickler wird
:Das Oracle Sql-Entwicklertool wird von vielen Entwicklern verwendet. Dieser Kurs gibt uns Tricks und Lektionen, wie man es effektiv nutzt und ein produktiver SQL-Entwickler wird
Oracle SQL Performance Tuning Masterclass 2020  :Leistungsoptimierung ist eine der kritischsten und gefragtesten Fähigkeiten. Dies ist ein guter Kurs, um mehr darüber zu erfahren und mit der Optimierung der SQL-Leistung zu beginnen
:Leistungsoptimierung ist eine der kritischsten und gefragtesten Fähigkeiten. Dies ist ein guter Kurs, um mehr darüber zu erfahren und mit der Optimierung der SQL-Leistung zu beginnen