Dieser Beitrag ist Teil des Oracle SQL-Tutorials und wir würden analytische Funktionen in Oracle (Over by Partition) mit Beispielen und einer detaillierten Erklärung diskutieren .
Wir haben uns bereits mit Oracle Aggregate-Funktionen wie avg ,sum ,count beschäftigt. Nehmen wir ein Beispiel
Lassen Sie uns zuerst die Beispieldaten erstellen
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
SQL> desc emp
Name Null? Type
---- ---- -----
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
SQL> desc dept
Name Null? Type
---- ----- ----
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
commit;
insert into emp values( 7839, 'Allen', 'MANAGER', 7839, to_date('17-11-1981','dd-mm-yyyy'), 20, null, 10 );
insert into emp values( 7782, 'CLARK', 'MANAGER', 7839, to_date('9-06-1981','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7934, 'MILLER', 'MANAGER', 7839, to_date('23-01-1982','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7788, 'SMITH', 'ANALYST', 7788, to_date('17-12-1980','dd-mm-yyyy'), 800, null, 20 );
insert into emp values( 7902, 'ADAM, 'ANALYST', 7832, to_date('23-05-1987','dd-mm-yyyy'), 1100, null, 20 );
insert into emp values( 7876, 'FORD', 'ANALYST', 7566, to_date('3-12-1981','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7369, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7698, 'JAMES', 'ANALYST', 7788, to_date('03-12-1981','dd-mm-yyyy'), 950, null, 30 );
insert into emp values( 7499, 'MARTIN', 'ANALYST', 7698, to_date('28-09-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7844, 'WARD', 'ANALYST', 7698, to_date('22-02-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7654, 'TURNER', 'ANALYST', 7698, to_date('08-09-1981','dd-mm-yyyy'), 1500, null, 30 );
insert into emp values( 7521, 'ALLEN', 'ANALYST', 7698, to_date('20-02-1981','dd-mm-yyyy'), 1600, null, 30 );
insert into emp values( 7900, 'BLAKE', 'ANALYST', 77698, to_date('01-05-1981','dd-mm-yyyy'), 2850, null, 30 );
commit;
Nun wird das Beispiel von Aggregatfunktionen wie folgt gegeben
select count(*) from EMP; --------- 13 select sum (bytes) from dba_segments where tablespace_name='TOOLS'; ----- 100 SQL> select deptno ,count(*) from emp group by deptno; DEPTNO COUNT(*) ---------- ---------- 30 6 20 4 10 3
Hier können wir sehen, dass es die Anzahl der Zeilen in jeder der Abfragen reduziert. Jetzt kommt die Frage, was zu tun ist, wenn wir alle Zeilen auch mit count(*) zurückgeben müssen
Dafür hat das Orakel eine Reihe von Analysefunktionen bereitgestellt. Um das letzte Problem zu lösen, können wir also schreiben als
select empno ,deptno , count(*) over (partition by deptno) from emp group by deptno;
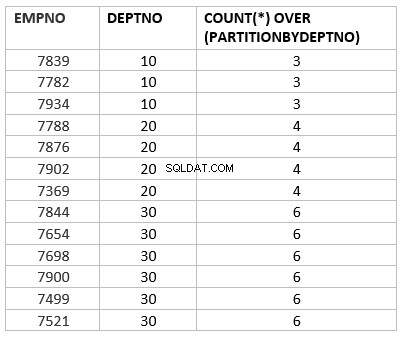
Hier ist count(*) over (partition by dept_no) die analytische Version der count-Aggregatfunktion. Die wichtigste Schlüsselarbeit, die sich je nach Aggregatfunktion unterscheidet, ist die Partitionierung nach
Analysefunktionen berechnen einen Aggregatwert basierend auf einer Gruppe von Zeilen. Sie unterscheiden sich von Aggregatfunktionen dadurch, dass sie mehrere Zeilen für jede Gruppe zurückgeben. Die Gruppe von Zeilen wird als Fenster bezeichnet und durch die analytische_Klausel definiert.
Hier ist die allgemeine Syntax
analytic_function([ arguments ]) OVER ([ query_partition_clause ] [ order_by_clause [ windowing_clause ] ])
Beispiel
count(*) over (partition by deptno) avg(Sal) over (partition by deptno)
Lassen Sie uns jeden Teil durchgehen
query_partition_clause
Es definiert die Gruppe von Zeilen. Es kann unten gefallen
partition by deptno :Gruppe von Zeilen derselben deptno
oder
() :Alle Zeilen
SQL> select empno ,deptno , count(*) over () from emp;
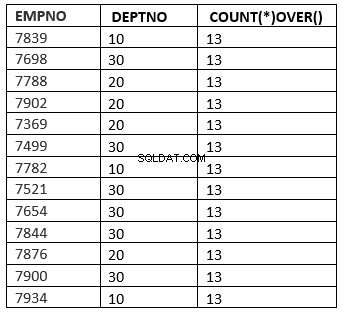
[ order_by_clause [ windowing_clause ] ]
Diese Klausel wird verwendet, wenn Sie die Zeilen in der Partition ordnen möchten. Dies ist besonders nützlich, wenn Sie möchten, dass die analytische Funktion die Reihenfolge der Zeilen berücksichtigt.
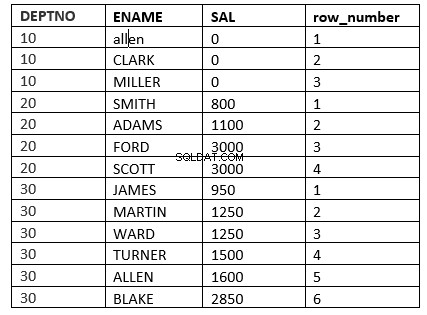
Beispiel ist die row_number-Funktion
SQL> select deptno, ename, sal, row_number() over (partition by deptno order by sal) "row_number" from emp;
Ein anderes Beispiel wäre
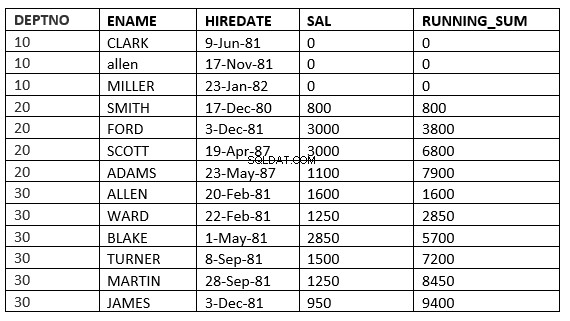
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Windowing_clause
Dies wird immer mit der order by-Klausel verwendet und gibt mehr Kontrolle über die Menge der Zeilen in der Gruppe
Mit der Windowing-Klausel wird für jede Zeile ein gleitendes Zeilenfenster definiert. Das Fenster bestimmt den Zeilenbereich, der verwendet wird, um die Berechnungen für die aktuelle Zeile durchzuführen. Fenstergrößen können entweder auf einer physischen Anzahl von Zeilen oder auf einem logischen Intervall wie der Zeit basieren.
Wenn die order by-Klausel verwendet wird und für windowing_clause nichts angegeben ist, wird der untere Standardwert der windowing_clause genommen partition sind die Zeilen, die in der Berechnung verwendet werden sollen“
Das folgende Beispiel zeigt dies deutlich. Dies ist der laufende Durchschnitt in der Abteilung
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Jetzt kann windowing_clause auf verschiedene Arten definiert werden
Lasst uns zuerst die Terminologie verstehen
ZEILEN gibt das Fenster in physikalischen Einheiten (Zeilen) an.
BEREICH gibt das Fenster als logischen Offset an. Die RANGE-Windowing-Klausel kann nur mit ORDER BY-Klauseln verwendet werden, die Spalten oder Ausdrücke numerischer oder Datumsdatentypen enthalten
PRECEDING – Zeilen vor der aktuellen erhalten.
FOLGEN – Zeilen nach der aktuellen abrufen.
UNBOUNDED – Bei Verwendung mit PRECEDING oder FOLLOWING wird alles davor oder danach zurückgegeben. AKTUELLE REIHE
Daher wird es allgemein als
definiertZEILEN UNBEGRENZT VORHER :Die aktuellen und vorherigen Zeilen in der aktuellen Partition sind die Zeilen, die in der Berechnung verwendet werden sollen
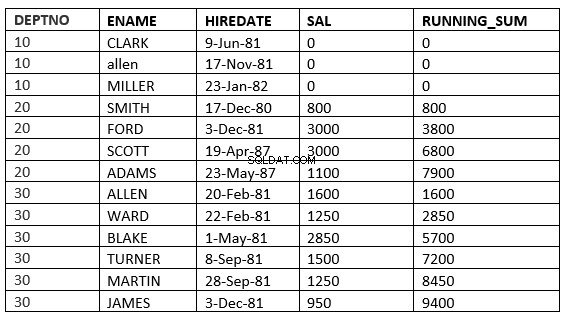
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS UNBOUNDED PRECEDING) running_sum from emp;
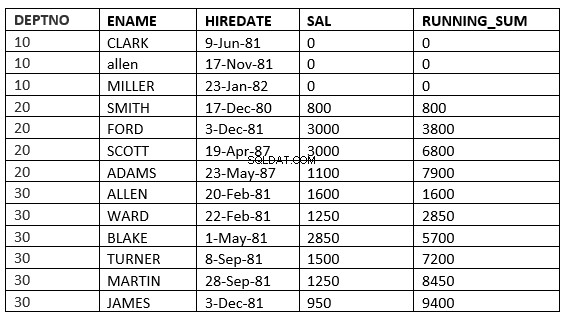
REIHE UNBEGRENZT VORHER :Die aktuellen und vorherigen Zeilen in der aktuellen Partition sind die Zeilen, die in der Berechnung verwendet werden sollten. Da auch der Bereich angegeben ist, nimmt alles die Werte an, die gleich den aktuellen Zeilen sind.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE UNBOUNDED PRECEDING) running_sum from emp;
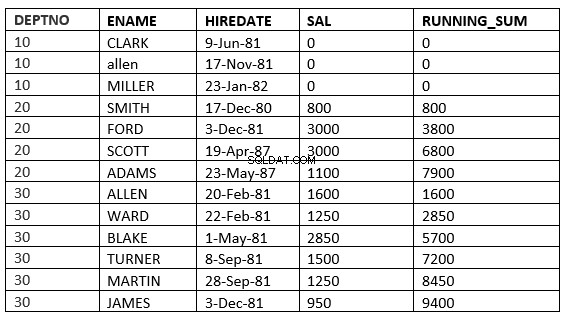
Möglicherweise sehen Sie den Unterschied zwischen range und rows nicht, da rental_date für alle unterschiedlich ist. Der Unterschied wird deutlicher, wenn wir sal als order by-Klausel verwenden
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal RANGE UNBOUNDED PRECEDING) running_sum from emp;
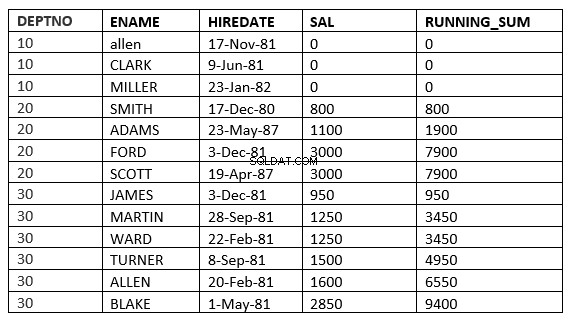
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal ROWS UNBOUNDED PRECEDING) running_sum from emp;
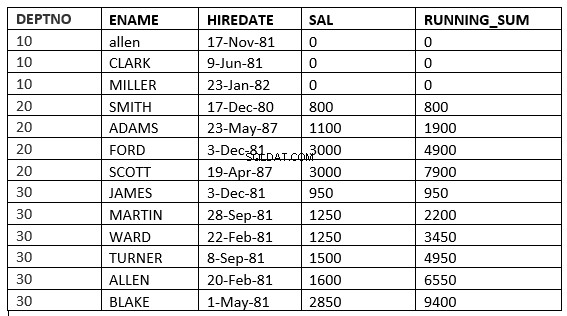
Den Unterschied finden Sie in Zeile 6
RANGE value_expr PRECEDING :Das Fenster beginnt mit der Zeile, deren ORDER BY-Wert numerische Ausdruckszeilen kleiner als oder vor der aktuellen Zeile ist, und endet mit der aktuellen Zeile, die verarbeitet wird.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE 365 PRECEDING) running_sum from emp;
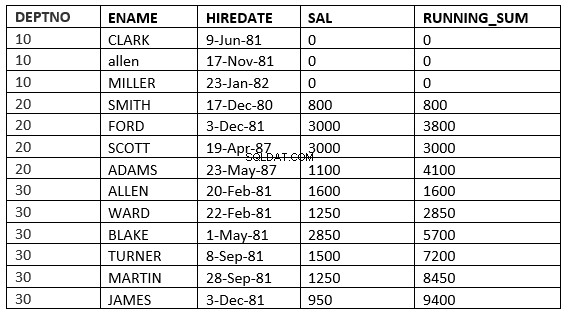
Hier werden alle Zeilen verwendet, in denen der Wert für das Einstellungsdatum innerhalb von 365 Tagen vor dem Wert für das Einstellungsdatum der aktuellen Zeile liegt
ROWS value_expr PRECEDING :Das Fenster beginnt mit der angegebenen Zeile und endet mit der aktuellen verarbeiteten Zeile
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS 2 PRECEDING) running_sum from emp;
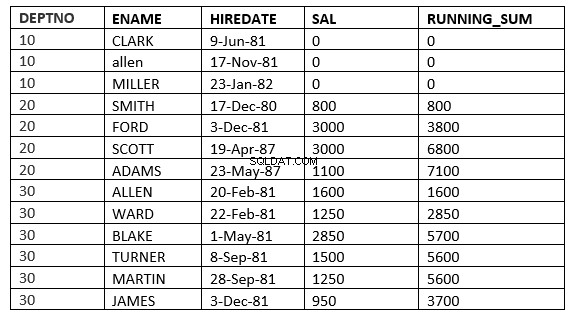
Hier beginnt das Fenster mit 2 Zeilen vor der aktuellen Zeile
RANGE BETWEEN CURRENT ROW and value_expr FOLLOWING :Das Fenster beginnt mit der aktuellen Zeile und endet mit der Zeile, deren ORDER BY-Wert ein numerischer Ausdruck ist, der Zeilen kleiner als oder nach
istSQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
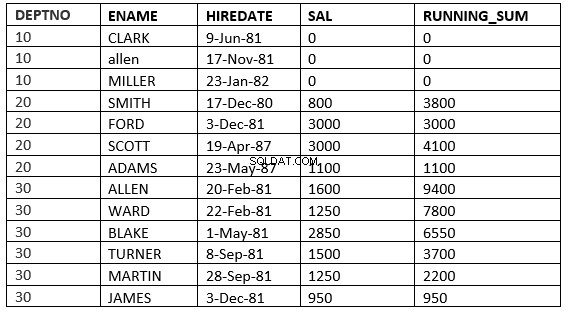
ROWS BETWEEN CURRENT ROW und value_expr FOLLOWING :Das Fenster beginnt mit der aktuellen Zeile und endet mit den Zeilen nach der aktuellen
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
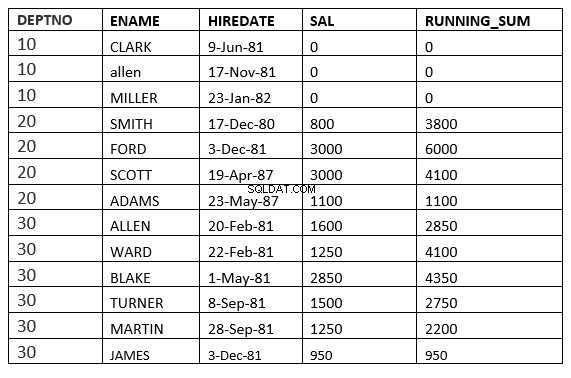
BEREICH ZWISCHEN UNBEGRENZTE VORHERIGE und UNBEGRENZTE FOLGE
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) running_sum from emp;
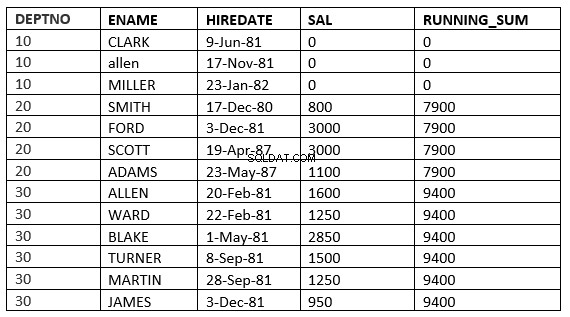
BEREICH ZWISCHEN value_expr PRECEDING und value_expr FOLLOWING
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN 365 PRECEDING and 365 FOLLOWING ) running_sum from emp; 2 DEPTNO ENAME HIREDATE SAL RUNNING_SUM ---------- ---------- --------------- ---------- ----------- 10 CLARK 09-JUN-81 0 0 10 ALLEN 17-NOV-81 0 0 10 MILLER 23-JAN-82 0 0 20 SMITH 17-DEC-80 800 3800 20 FORD 03-DEC-81 3000 3800 20 SCOTT 19-APR-87 3000 4100 20 ADAMS 23-MAY-87 1100 4100 30 ALLEN 20-FEB-81 1600 9400 30 WARD 22-FEB-81 1250 9400 30 BLAKE 01-MAY-81 2850 9400 30 TURNER 08-SEP-81 1500 9400 30 MARTIN 28-SEP-81 1250 9400 30 JAMES 03-DEC-81 950 9400 13 rows selected.
Einige wichtige Hinweise
(1)Analysefunktionen sind die letzten Operationen, die in einer Abfrage ausgeführt werden, mit Ausnahme der abschließenden ORDER BY-Klausel. Alle Joins und alle WHERE-, GROUP BY- und HAVING-Klauseln werden abgeschlossen, bevor die Analysefunktionen verarbeitet werden. Daher können Analysefunktionen nur in der Auswahlliste oder der ORDER BY-Klausel erscheinen.
(2)Analysefunktionen werden häufig verwendet, um kumulative, bewegliche, zentrierte und Berichtsaggregate zu berechnen.
Ich hoffe, Ihnen gefällt diese ausführliche Erklärung der analytischen Funktionen in Oracle (over by Partition Clause)
Verwandte Artikel
LEAD-Funktion in Oracle
DENSE-Funktion in Oracle
Oracle LISTAGG-Funktion
Aggregieren von Daten mithilfe von Gruppenfunktionen
https://docs.oracle.com/cd/E11882_01/ server.112/e41084/functions004.htm