Übersicht
Oracle Data Mining (ODM) ist eine Komponente der Oracle Advanced Analytics Database Option. ODM enthält eine Reihe fortschrittlicher Data-Mining-Algorithmen, die in die Datenbank eingebettet sind und es Ihnen ermöglichen, erweiterte Analysen Ihrer Daten durchzuführen.
Oracle Data Miner ist eine Erweiterung von Oracle SQL Developer, einer grafischen Entwicklungsumgebung für Oracle SQL. Oracle Data Miner verwendet die in Oracle Database eingebettete Data-Mining-Technologie, um Workflows zu erstellen, auszuführen und zu verwalten, die Data-Mining-Operationen kapseln. Die Architektur von ODM ist in Abbildung 1 dargestellt.
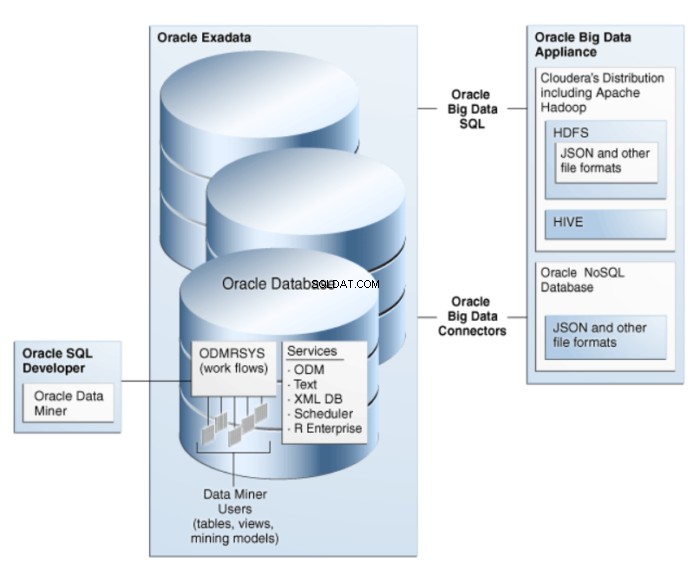
Abbildung 1:Oracle Data Mining-Architektur für Big Data
Algorithmen werden als SQL-Funktionen implementiert und nutzen die Stärken der Oracle-Datenbank. Die SQL-Data-Mining-Funktionen können Transaktionsdaten, Aggregationen, unstrukturierte Daten, d. h. CLOB-Datentypen (unter Verwendung von Oracle Text) und räumliche Daten durchsuchen.
Jede Data-Mining-Funktion spezifiziert eine Klasse von Problemen, die modelliert und gelöst werden können. Data-Mining-Funktionen fallen im Allgemeinen in zwei Kategorien:überwacht und nicht überwacht.
Die Begriffe überwachtes und unüberwachtes Lernen stammen aus der Wissenschaft des maschinellen Lernens, das als Teilbereich der künstlichen Intelligenz bezeichnet wird.
Überwachtes Lernen wird auch als gerichtetes Lernen bezeichnet. Der Lernprozess wird durch ein zuvor bekanntes abhängiges Attribut oder Ziel gesteuert. Directed Data Mining versucht, das Verhalten des Ziels als Funktion einer Reihe unabhängiger Attribute oder Prädiktoren zu erklären.
Unüberwachtes Lernen ist ungerichtet. Es gibt keine Unterscheidung zwischen abhängigen und unabhängigen Attributen. Es gibt kein bisher bekanntes Ergebnis, das den Algorithmus beim Erstellen des Modells anleiten könnte. Unüberwachtes Lernen kann für beschreibende Zwecke verwendet werden.
Von Oracle Data Mining überwachte Algorithmen
| Technik | Anwendbarkeit | Algorithmen (Kurzbeschreibung) |
|---|---|---|
Klassifizierung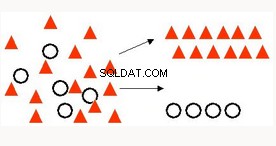 | Am häufigsten verwendete Technik zur Vorhersage eines bestimmten Ergebnisses, z. B. Identifizierung von Krebstumorzellen, Stimmungsanalyse, Drogenklassifizierung, Spam-Erkennung. | Logistische Regression mit verallgemeinerten linearen Modellen – klassische statistische Technik, die innerhalb der Oracle-Datenbank in einer hochleistungsfähigen, skalierbaren, parallelisierten Implementierung verfügbar ist (gilt für alle OAA-ML-Algorithmen). Unterstützt Text- und Transaktionsdaten (gilt für fast alle OAA ML-Algorithmen) Naive Bayes – Schnell, einfach, allgemein anwendbar. Support Vector Machine – Algorithmus für maschinelles Lernen, unterstützt Text und breite Daten. Entscheidungsbaum - Beliebter ML-Algorithmus für Interpretierbarkeit. Stellt für Menschen lesbare „Regeln“ bereit. |
Regression | Technik zur Vorhersage eines kontinuierlichen numerischen Ergebnisses wie astronomische Datenanalyse, Gewinnung von Erkenntnissen über Verbraucherverhalten, Rentabilität und andere Geschäftsfaktoren, Berechnung kausaler Beziehungen zwischen Parametern in biologischen Systemen. | Verallgemeinerte lineare Modelle Mehrfachregression – klassische statistische Technik, aber jetzt in der Oracle-Datenbank als hochleistungsfähige, skalierbare, parallelisierte Implementierung verfügbar. Unterstützt Ridge-Regression, Feature-Erstellung und Feature-Auswahl. Unterstützt Text und Transaktionsdaten. Support Vector Machine – Algorithmus für maschinelles Lernen, unterstützt Text und breite Daten. |
Attributwichtigkeit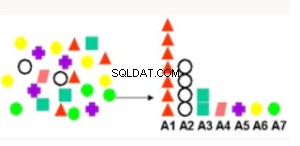 | Ordnet Attribute nach der Stärke der Beziehung zum Zielattribut ein. Anwendungsfälle umfassen das Finden von Faktoren, die am ehesten mit Kunden in Verbindung gebracht werden, die auf ein Angebot reagieren, und Faktoren, die am ehesten mit gesunden Patienten in Verbindung gebracht werden. | Mindestbeschreibungslänge - Betrachtet jedes Attribut als einfaches Vorhersagemodell der Zielklasse und bietet relativen Einfluss. |
Unüberwachte Data-Mining-Algorithmen von Oracle
| Technik | Anwendbarkeit | Algorithmen |
|---|---|---|
Clustering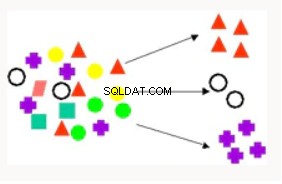 | Clustering wird verwendet, um die Datensätze einer Datenbank in Teilmengen oder Cluster zu unterteilen, wobei Elemente in einem Cluster einen Satz gemeinsamer Eigenschaften teilen. Beispiele hierfür sind die Suche nach neuen Kundensegmenten und Filmempfehlungen. | K-Means – Unterstützt Text-Mining, hierarchisches Clustering, entfernungsbasiert. Orthogonal Partitioning Clustering – Hierarchisches Clustering, dichtebasiert. Erwartungsmaximierung - Clustering-Technik, die bei Data-Mining-Problemen mit gemischten Daten (dicht und spärlich) gut funktioniert. |
Anomalieerkennung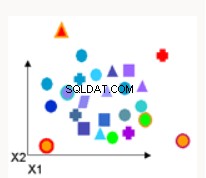 | Anomalieerkennung identifiziert Datenpunkte, Ereignisse und/oder Beobachtungen, die vom normalen Verhalten eines Datensatzes abweichen. Gängige Beispiele sind Bankbetrug, ein baulicher Defekt, medizinische Probleme oder Fehler in einem Text | One-Class Support Vector Machine - trainiert ungetaggte Daten und versucht festzustellen, ob ein Testpunkt zur Verteilung von Trainingsdaten gehört. |
Merkmalsauswahl und -extraktion | Erzeugt neue Attribute als lineare Kombination vorhandener Attribute. Anwendbar für Textdaten, latente semantische Analyse (LSA), Datenkomprimierung, Datenzerlegung und -projektion sowie Mustererkennung. | Nicht-negative Matrixfaktorisierung – Ordnet die ursprünglichen Daten dem neuen Satz von Attributen zu Hauptkomponentenanalyse (PCA) – erstellt weniger neue zusammengesetzte Attribute, die alle darstellen Attribute. Singular Vector Decomposition - etablierte Merkmalsextraktionsmethode mit breitem Anwendungsbereich. |
Verknüpfung | Findet Regeln, die häufig gleichzeitig vorkommenden Artikeln zugeordnet sind, die für Warenkorbanalysen, Cross-Selling und Ursachenanalysen verwendet werden. Nützlich für Produktbündelung und Fehleranalyse. | Apriori – Hashing eines Baums, um Informationen in einer Datenbank zu sammeln |
Aktivieren der Oracle Data Mining-Option
Ab 12c Release 2 das Oracle Advanced Analytics Die Option umfasst Data Mining und Oracle R-Funktionalität.
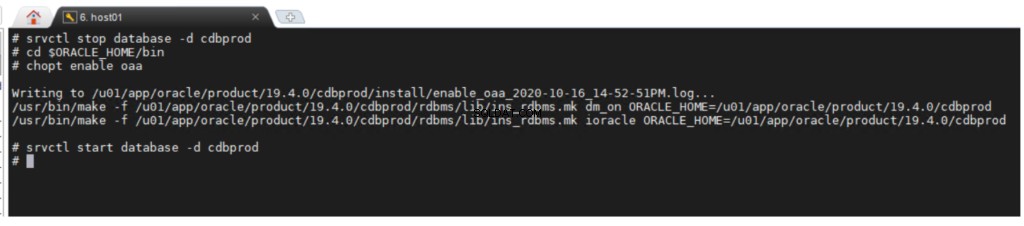
Die Option Oracle Advanced Analytics ist während der Installation von Oracle Database Enterprise Edition standardmäßig aktiviert. Wenn Sie eine Datenbankoption aktivieren oder deaktivieren möchten, können Sie das Befehlszeilenprogramm chopt verwenden .
chopt [ enable | disable ] oaa
So aktivieren Sie die Oracle Advanced Analytics-Option:
Tablespace und ODM-Schema erstellen
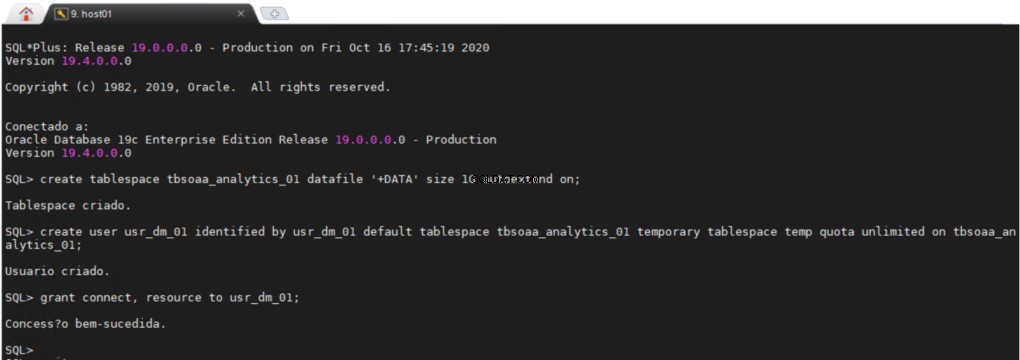
Alle Benutzer benötigen einen permanenten Tablespace und einen temporären Tablespace, in dem sie ihre Arbeit erledigen können. Es kann sehr nützlich sein, einen separaten Bereich in Ihrer Datenbank zu haben, in dem Sie alle Ihre Data-Mining-Objekte erstellen können.
Der usr_dm_01 Schema enthält alle Ihre Data-Mining-Arbeiten.
ODM-Repository erstellen
Sie müssen ein Oracle Data Mining-Repository erstellen in der Datenbank. Gehen Sie in SQL Developer zum Data Miner-Navigator.
Wählen Sie Ansicht -> Data Miner -> Data Miner-Verbindungen:
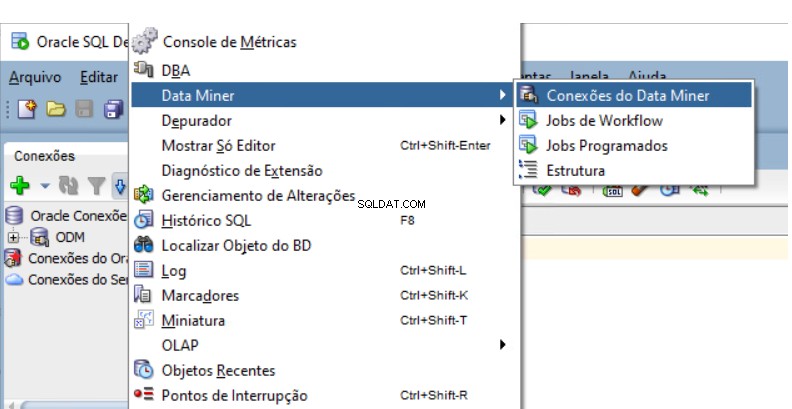
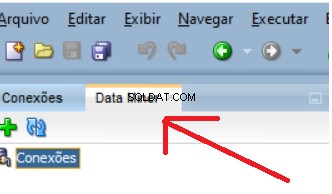
Neben Ihrer bestehenden Registerkarte "Verbindungen" wird eine neue Registerkarte geöffnet:
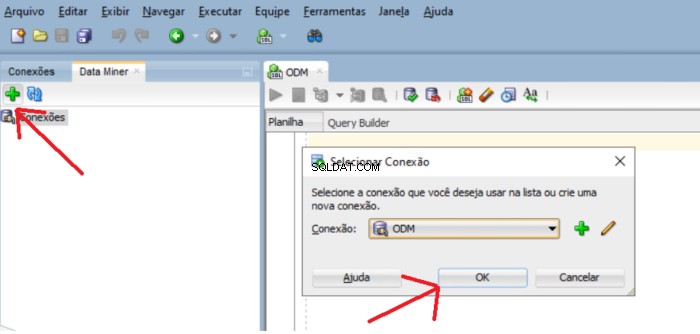
So fügen Sie usr_dm_01 hinzu Schema zu dieser Liste hinzuzufügen, klicken Sie auf die grünen Plus-Fenster und OK
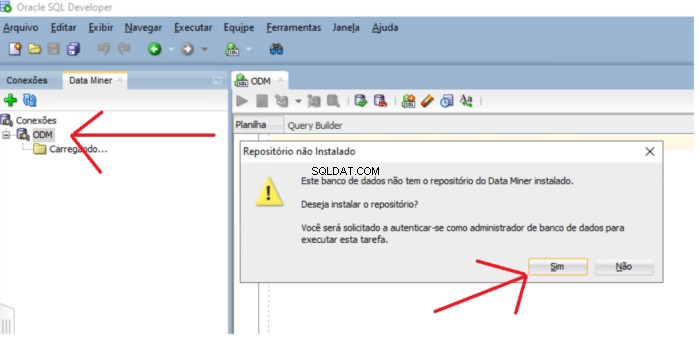
Wenn das Repository nicht existiert, wird eine Meldung angezeigt, in der Sie gefragt werden, ob Sie das Repository installieren möchten. Klicken Sie auf Ja Schaltfläche, um mit der Installation fortzufahren.
Sie müssen das SYS-Passwort eingeben
Repository-Installationseinstellung
Fortschrittsfenster für die Installation des Data Miner-Repositorys
Aufgabe erfolgreich abgeschlossen
Protokolldatei
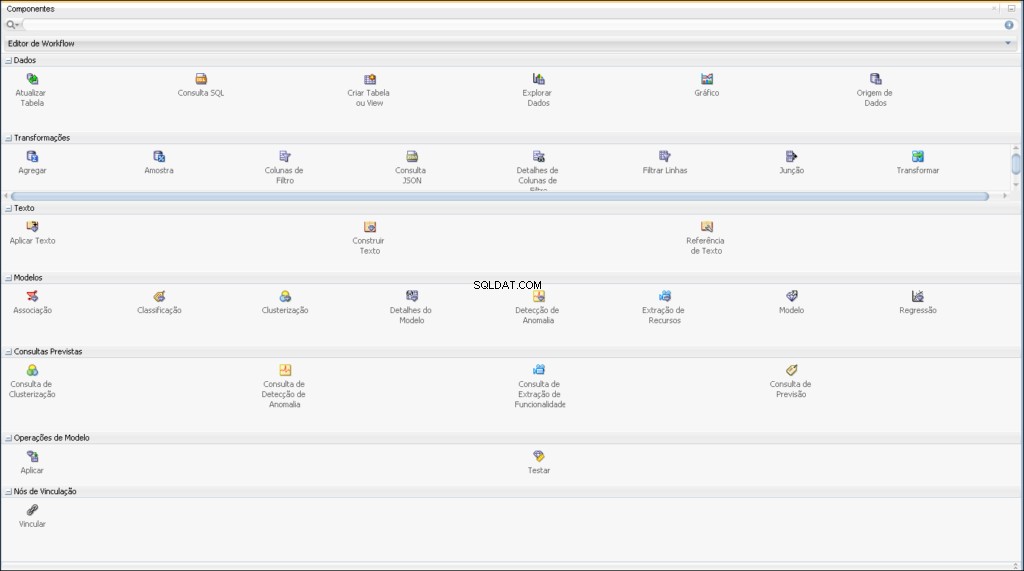
Oracle Data Mining-Komponenten
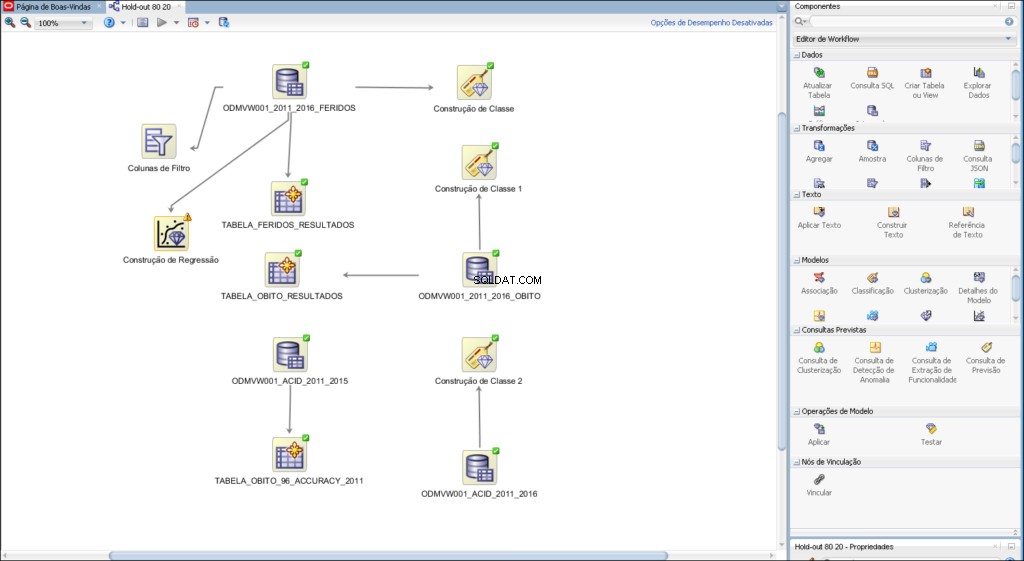
Der Workflow ermöglicht es Ihnen, eine Reihe von Knoten aufzubauen, die die gesamte erforderliche Verarbeitung Ihrer Daten durchführen.
Beispiel eines für Predictive Analytics entwickelten Workflows
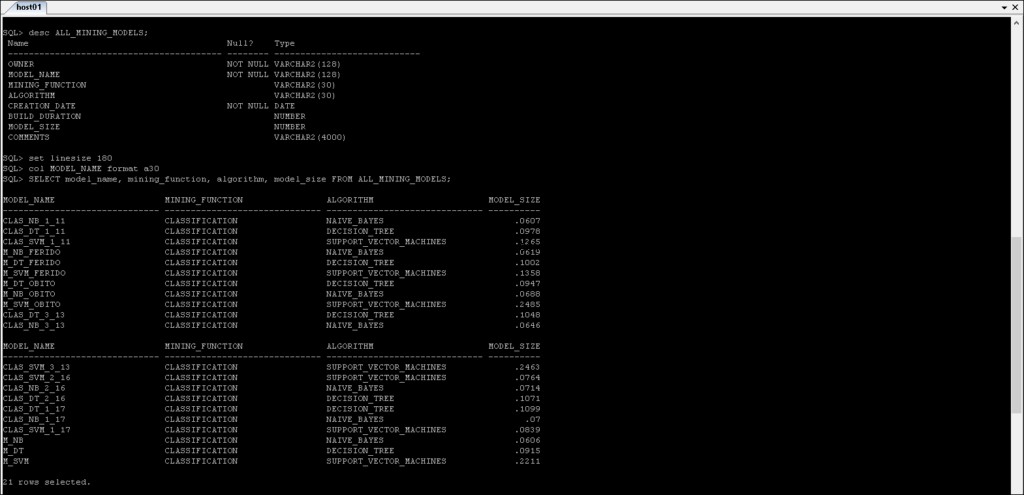
Ansichten des ODM-Datenwörterbuchs
Informationen zu Mining-Modellen erhalten Sie im Data Dictionary.
Die Ansichten des Data Mining-Datenwörterbuchs werden wie folgt zusammengefasst:
Hinweis:* kann durch ALL_, USER_, DBA_ und CDB_ ersetzt werden
*_MINING_MODELS :Informationen über die erstellten Mining-Modelle.
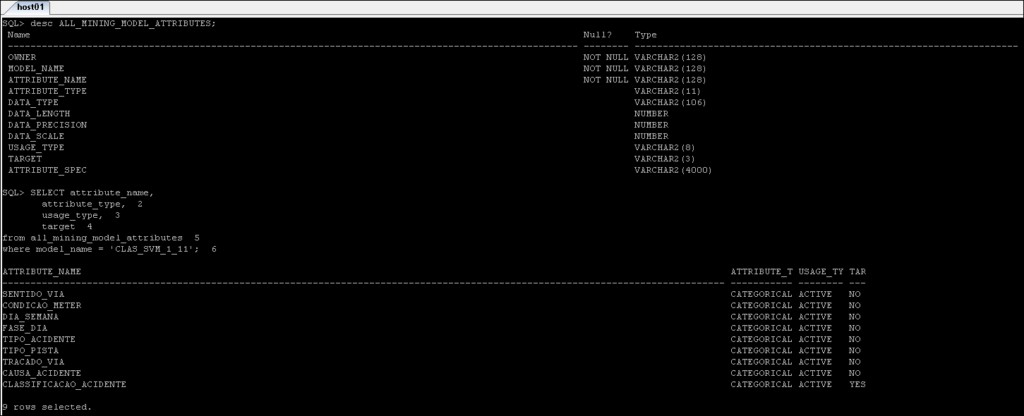
*_MINING_MODEL_ATTRIBUTES :Enthält die Details der Attribute, die verwendet wurden, um das Oracle Data Mining-Modell zu erstellen.
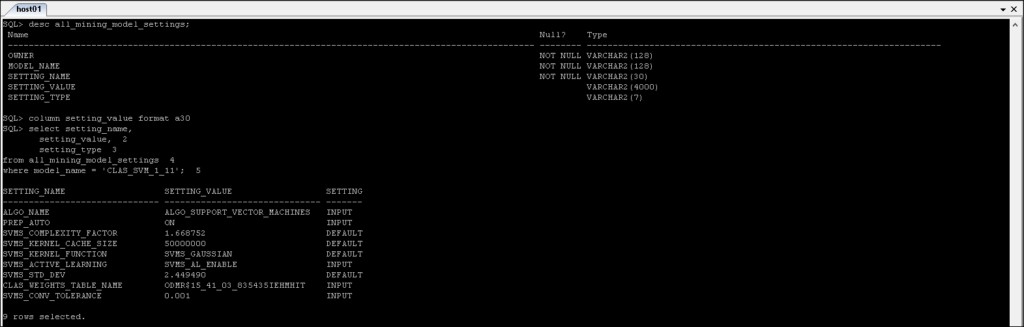
*_MINING_MODEL_SETTINGS :Gibt Informationen zu den Einstellungen für die Mining-Modelle zurück, auf die Sie Zugriff haben.
Referenzen
Oracle Data Mining-Benutzerhandbuch. Verfügbar unter:https://docs.oracle.com/en/database/oracle/oracle-database/19/dmprg/lot.html
Oracle Data Mining – Skalierbare datenbankinterne Vorhersageanalyse. Verfügbar unter:https://www.oracle.com/database/technologies/advanced-analytics/odm.html
Überblick über das Oracle Data Miner-System. Verfügbar unter:https://docs.oracle.com/database/sql-developer-17.4/DMRIG/oracle-data-miner-overview.htm#DMRIG124