Hochverfügbarkeit aufbauen, Schritt für Schritt
Wenn es um Datenbankinfrastruktur geht, wollen wir sie alle. Wir alle streben danach, ein hochverfügbares Setup aufzubauen. Redundanz ist der Schlüssel. Wir beginnen mit der Implementierung von Redundanz auf der untersten Ebene und setzen den Stack nach oben fort. Das beginnt bei der Hardware – redundante Netzteile, redundante Kühlung, Hot-Swap-Festplatten. Netzwerkschicht – mehrere NICs, die miteinander verbunden und mit verschiedenen Switches verbunden sind, die redundante Router verwenden. Für die Speicherung verwenden wir Festplatten, die in RAID eingerichtet sind, was eine bessere Leistung, aber auch Redundanz bietet. Dann verwenden wir auf der Softwareebene Clustering-Technologien:Mehrere Datenbankknoten arbeiten zusammen, um Redundanz zu implementieren:MySQL Cluster, Galera Cluster.
All dies ist nicht gut, wenn Sie alles in einem einzigen Rechenzentrum haben:Wenn ein Rechenzentrum ausfällt oder ein Teil der Dienste (aber wichtige) offline geht oder selbst wenn Sie die Verbindung zum Rechenzentrum verlieren, wird Ihr Dienst ausfallen - unabhängig von der Menge an Redundanz in den unteren Ebenen. Und ja, solche Dinge passieren.
- Die Unterbrechung des S3-Dienstes richtete im Februar 2017 in der Region US-East-1 Chaos an
- EC2- und RDS-Dienstunterbrechung in der Region USA-Ost im April 2011
- EC2, EBS und RDS wurden im August 2011 in der EU-West-Region gestört
- Stromausfall brachte Rackspace Texas DC im Juni 2009 zum Erliegen
- Ein USV-Ausfall führte dazu, dass Hunderte von Servern im Rackspace London DC im Januar 2010 offline gingen
Dies ist keineswegs eine vollständige Liste der Fehler, sondern nur das Ergebnis einer schnellen Google-Suche. Diese dienen als Beispiele dafür, dass Dinge schief gehen können und werden, wenn Sie alle Eier in denselben Korb legen. Ein weiteres Beispiel wäre der Hurrikan Sandy, der einen enormen Datenabfluss von DCs im US-Ost nach US-West verursachte - zu dieser Zeit konnte man kaum Instanzen im US-Westen hochfahren, da alle in Erwartung ihre Infrastruktur an die andere Küste verlegen wollten dass North Virginia DC ernsthaft vom Wetter beeinflusst wird.
Daher sind Setups mit mehreren Rechenzentren ein Muss, wenn Sie eine Hochverfügbarkeitsumgebung aufbauen möchten. In diesem Blogpost werden wir diskutieren, wie man eine solche Infrastruktur mit Galera Cluster for MySQL/MariaDB aufbaut.
Galera-Konzepte
Bevor wir uns mit bestimmten Lösungen befassen, lassen Sie uns einige Zeit damit verbringen, zwei Konzepte zu erläutern, die in hochverfügbaren Multi-DC-Galera-Setups sehr wichtig sind.
Beschlussfähigkeit
Hochverfügbarkeit erfordert Ressourcen – Sie benötigen nämlich eine Reihe von Knoten im Cluster, um ihn hochverfügbar zu machen. Ein Cluster kann den Verlust einiger seiner Mitglieder tolerieren, aber nur bis zu einem gewissen Grad. Jenseits einer bestimmten Ausfallrate könnten Sie es mit einem Split-Brain-Szenario zu tun haben.
Nehmen wir ein Beispiel mit einem 2-Knoten-Setup. Wenn einer der Knoten ausfällt, wie kann der andere wissen, dass sein Peer abgestürzt ist und es sich nicht um einen Netzwerkfehler handelt? In diesem Fall könnte der andere Knoten genauso gut betriebsbereit sein und Datenverkehr bedienen. Es gibt keinen guten Weg, um mit einem solchen Fall umzugehen … Deshalb beginnt die Fehlertoleranz normalerweise bei drei Knoten. Galera verwendet eine Quorum-Berechnung, um zu bestimmen, ob es für den Cluster sicher ist, den Datenverkehr zu bewältigen, oder ob er den Betrieb einstellen sollte. Nach einem Ausfall versuchen alle verbleibenden Knoten, sich miteinander zu verbinden und festzustellen, wie viele von ihnen aktiv sind. Er wird dann mit dem vorherigen Zustand des Clusters verglichen, und solange mehr als 50 % der Knoten aktiv sind, kann der Cluster weiter betrieben werden.
Daraus ergibt sich Folgendes:
2-Knoten-Cluster - keine Fehlertoleranz
3-Knoten-Cluster - bis zu 1 Absturz
4-Knoten-Cluster - bis zu 1 Absturz (wenn zwei Knoten abstürzen würden, nur 50 % des Clusters verfügbar wäre, benötigen Sie mehr als 50 % der Knoten, um zu überleben)
5-Knoten-Cluster - bis zu 2 Abstürze
6-Knoten-Cluster - bis zu 2 Abstürze
Sie sehen wahrscheinlich das Muster – Sie möchten, dass Ihr Cluster eine ungerade Anzahl von Knoten hat – in Bezug auf Hochverfügbarkeit macht es keinen Sinn, von 5 auf 6 Knoten im Cluster zu wechseln. Wenn Sie eine bessere Fehlertoleranz wünschen, sollten Sie sich für 7 Knoten entscheiden.
Segmente
Typischerweise folgt in einem Galera-Cluster die gesamte Kommunikation dem All-to-All-Muster. Jeder Knoten kommuniziert mit allen anderen Knoten im Cluster.
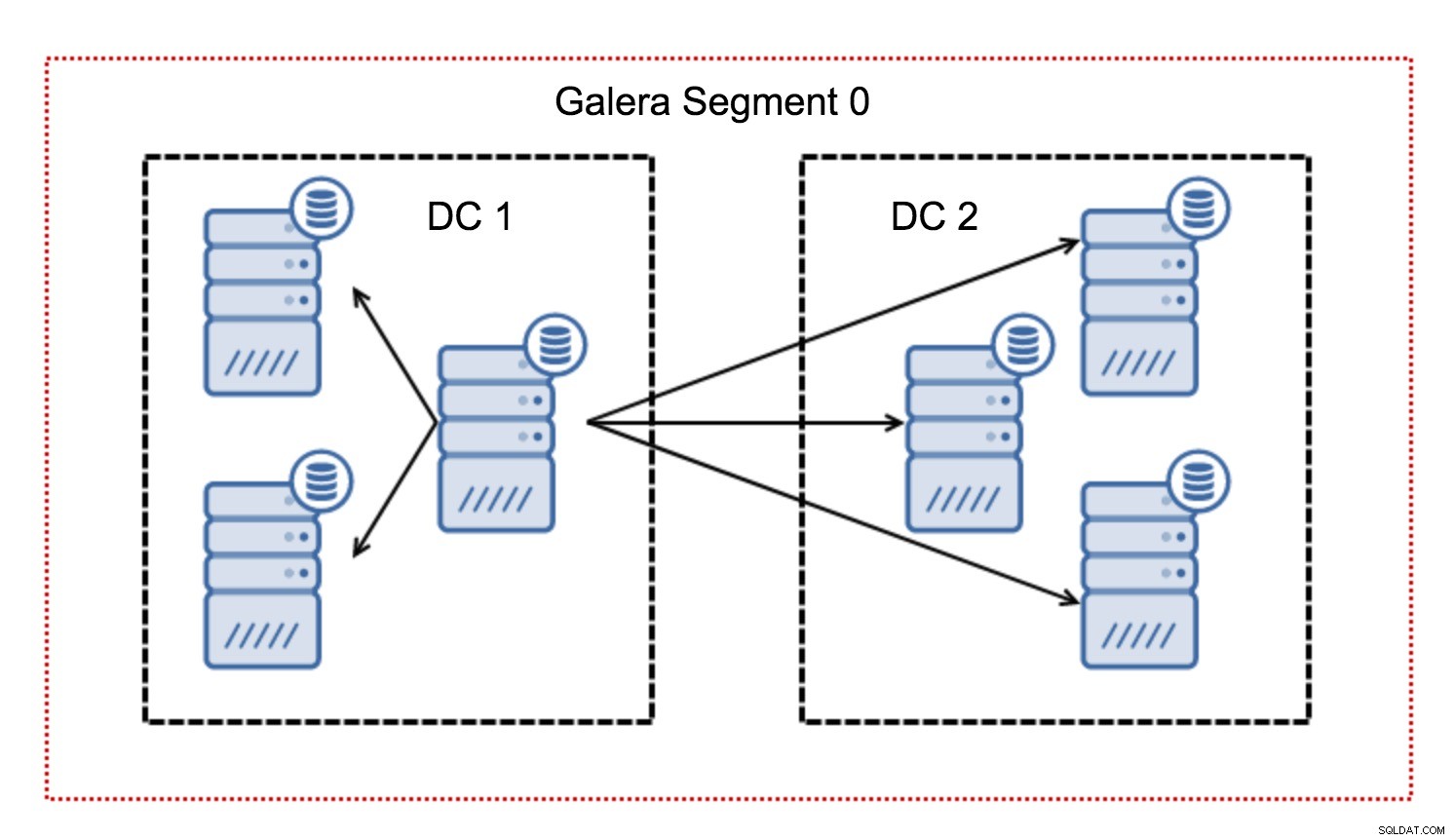
Wie Sie vielleicht wissen, muss jedes Writeset in Galera von allen Knoten im Cluster zertifiziert werden – daher muss jeder Schreibvorgang, der auf einem Knoten erfolgt, an alle Knoten im Cluster übertragen werden. Dies funktioniert in einer Umgebung mit niedriger Latenz problemlos. Aber wenn wir über Multi-DC-Setups sprechen, müssen wir eine viel höhere Latenz berücksichtigen als in einem lokalen Netzwerk. Um es in Clustern, die sich über Wide Area Networks erstrecken, erträglicher zu machen, hat Galera Segmente eingeführt.
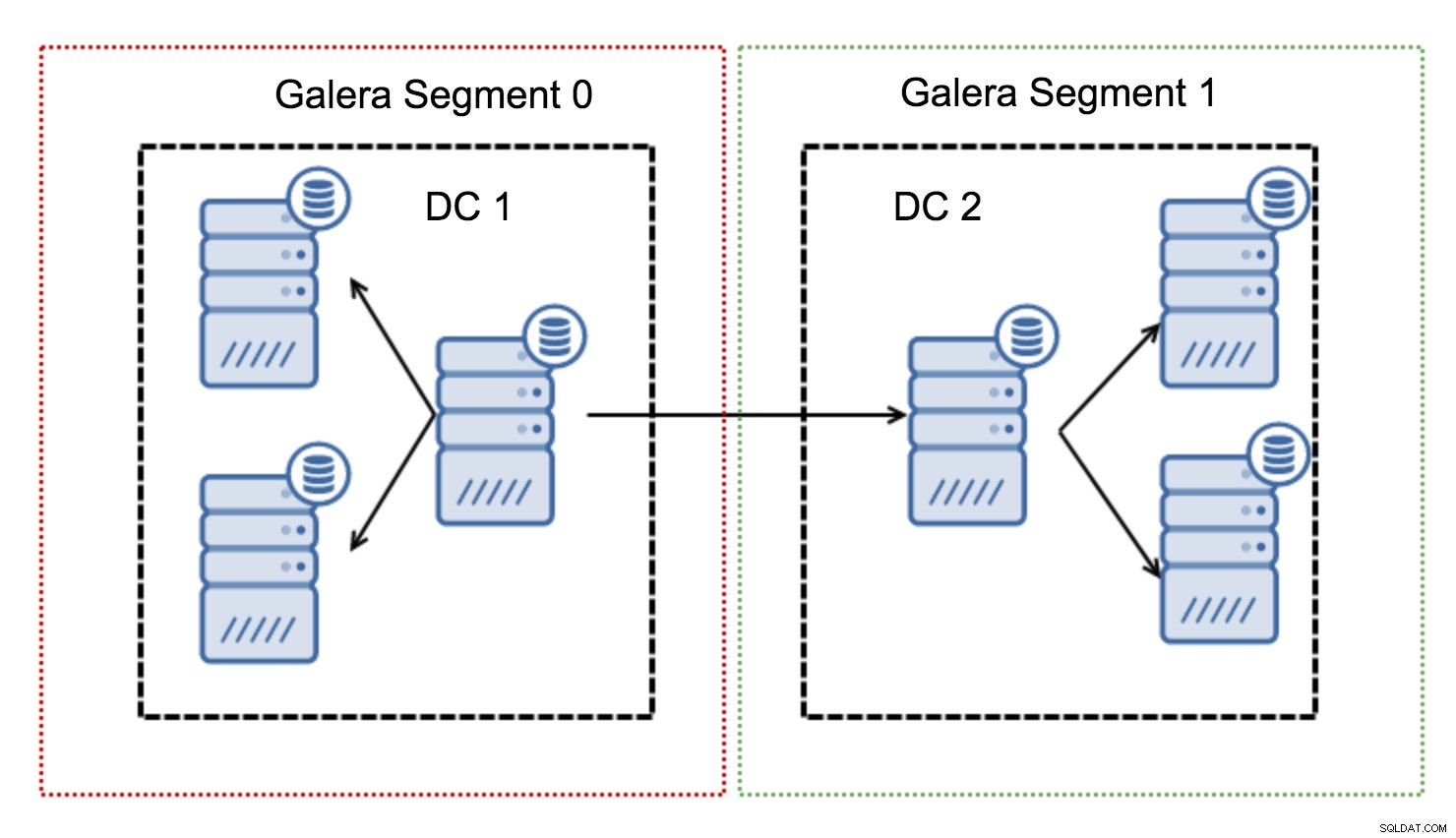
Sie funktionieren, indem sie den Galera-Verkehr innerhalb einer Gruppe von Knoten (Segment) enthalten. Alle Knoten innerhalb eines einzelnen Segments verhalten sich so, als ob sie sich in einem lokalen Netzwerk befänden – sie übernehmen die One-to-All-Kommunikation. Bei segmentübergreifendem Datenverkehr sind die Dinge anders – in jedem der Segmente wird ein „Relais“-Knoten ausgewählt, der gesamte segmentübergreifende Datenverkehr geht durch diese Knoten. Wenn ein Relaisknoten ausfällt, wird ein anderer Knoten gewählt. Dies reduziert die Latenz nicht wesentlich - schließlich bleibt die WAN-Latenz gleich, egal ob Sie eine Verbindung zu einem Remote-Host oder zu mehreren Remote-Hosts herstellen, aber angesichts der Tatsache, dass WAN-Verbindungen in der Regel in der Bandbreite begrenzt sind und es möglicherweise eine Gebühren für die übertragene Datenmenge zu berechnen, ermöglicht Ihnen ein solcher Ansatz, die zwischen den Segmenten ausgetauschte Datenmenge zu begrenzen. Eine weitere zeit- und kostensparende Option ist die Tatsache, dass Knoten im selben Segment priorisiert werden, wenn ein Spender benötigt wird – auch dies begrenzt die über das WAN übertragene Datenmenge und beschleunigt SST höchstwahrscheinlich fast immer als lokales Netzwerk schneller als eine WAN-Verbindung.
Nachdem wir nun einige dieser Konzepte aus dem Weg geräumt haben, schauen wir uns einige andere wichtige Aspekte von Multi-DC-Setups für Galera-Cluster an.
Probleme, mit denen Sie konfrontiert werden
Wenn Sie in Umgebungen arbeiten, die sich über WAN erstrecken, müssen Sie beim Entwerfen Ihrer Umgebung einige Aspekte berücksichtigen.
Quorumberechnung
Im vorherigen Abschnitt haben wir beschrieben, wie eine Quorum-Berechnung im Galera-Cluster aussieht – kurz gesagt, Sie möchten eine ungerade Anzahl von Knoten haben, um die Überlebensfähigkeit zu maximieren. All das gilt immer noch für Multi-DC-Setups, aber einige weitere Elemente werden in die Mischung aufgenommen. Zunächst müssen Sie entscheiden, ob Galera einen Rechenzentrumsausfall automatisch behandeln soll. Dadurch wird bestimmt, wie viele Rechenzentren Sie verwenden werden. Stellen wir uns zwei DCs vor – wenn Sie Ihre Knoten zu 50 % – 50 % aufteilen, wenn ein Rechenzentrum ausfällt, hat das zweite nicht 50 % + 1 Knoten, um seinen „primären“ Zustand aufrechtzuerhalten. Wenn Sie Ihre Knoten ungleichmäßig aufteilen und die meisten davon im „Haupt“-Rechenzentrum verwenden, hat der „Backup“-DC beim Ausfall dieses Rechenzentrums nicht 50 % + 1 Knoten, um ein Quorum zu bilden. Sie können Knoten unterschiedliche Gewichtungen zuweisen, aber das Ergebnis ist genau das gleiche – es gibt keine Möglichkeit, ohne manuellen Eingriff automatisch ein Failover zwischen zwei DCs durchzuführen. Um ein automatisiertes Failover zu implementieren, benötigen Sie mehr als zwei DCs. Auch hier ist idealerweise eine ungerade Zahl – drei Rechenzentren sind eine perfekte Einrichtung. Als nächstes stellt sich die Frage:Wie viele Knoten müssen Sie haben? Sie sollten sie gleichmäßig über die Rechenzentren verteilen. Der Rest hängt nur davon ab, wie viele ausgefallene Knoten Ihr Setup bewältigen muss.
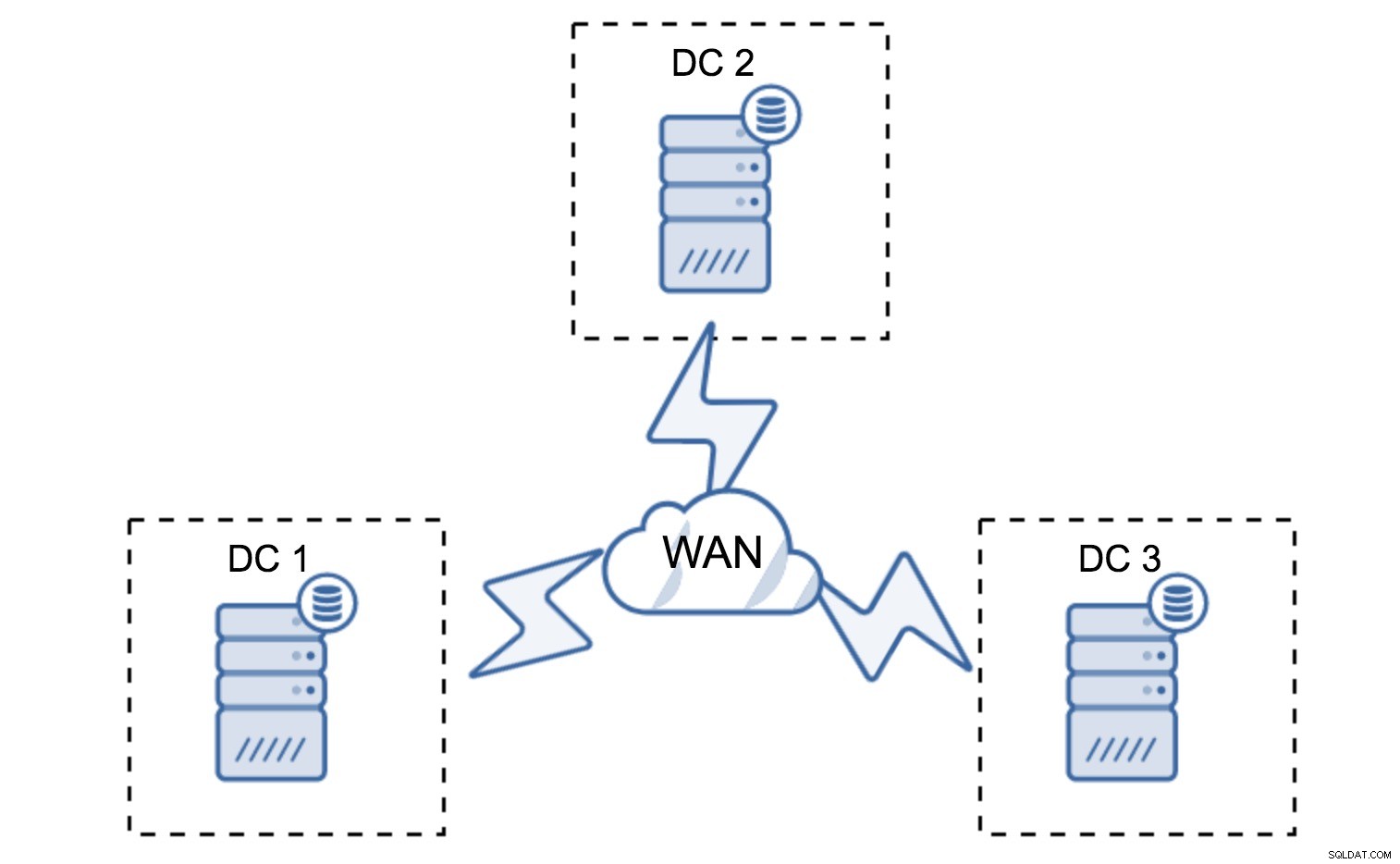
Bei der minimalen Einrichtung wird ein Knoten pro Rechenzentrum verwendet - es hat jedoch ernsthafte Nachteile. Jede Zustandsübertragung erfordert das Verschieben von Daten über das WAN und dies führt entweder zu einem längeren Zeitaufwand für die Durchführung von SST oder zu höheren Kosten.
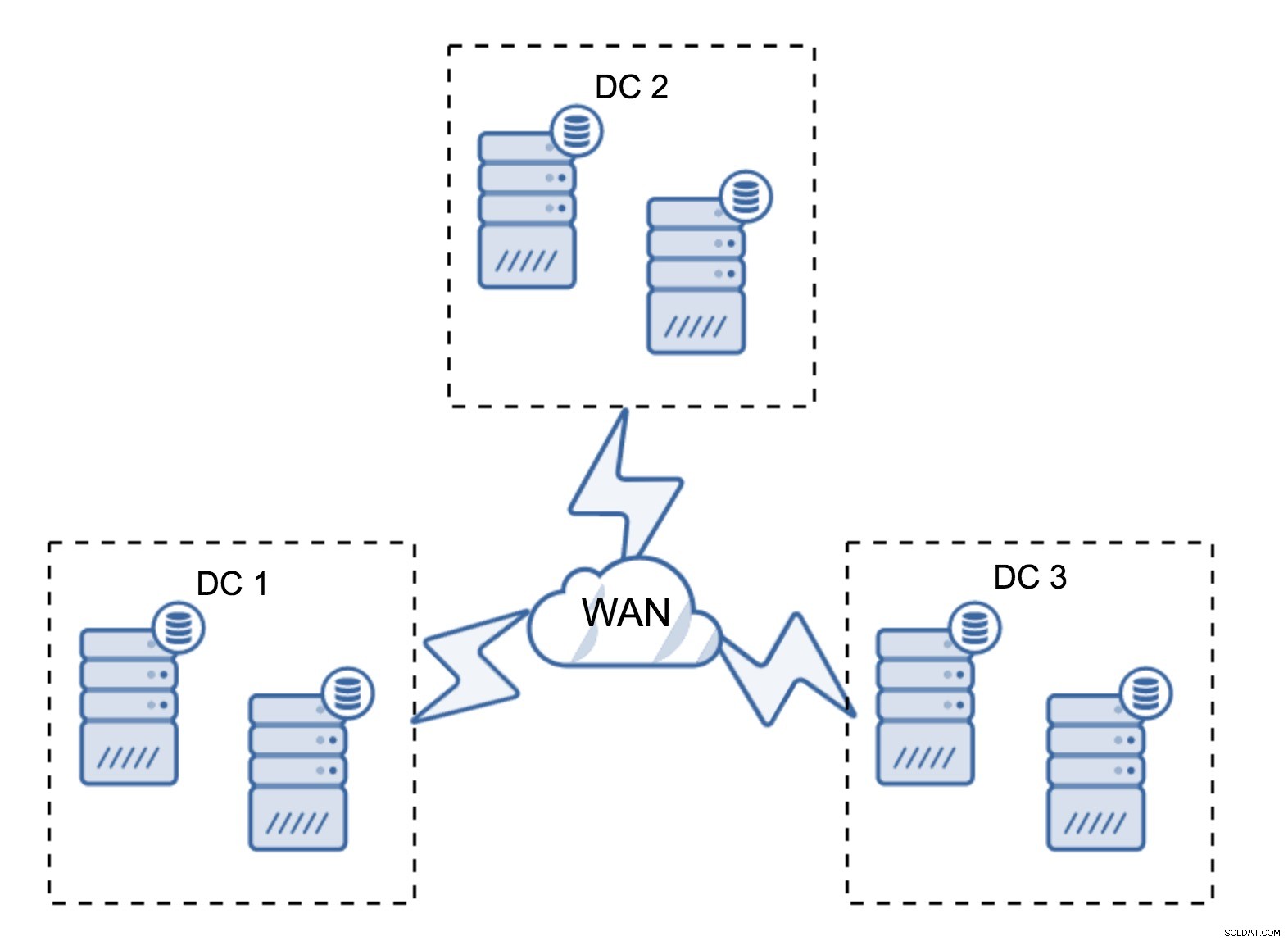
Ein recht typisches Setup besteht aus sechs Knoten, zwei pro Rechenzentrum. Dieses Setup erscheint unerwartet, da es eine gerade Anzahl von Knoten hat. Aber wenn Sie darüber nachdenken, ist es vielleicht kein so großes Problem:Es ist ziemlich unwahrscheinlich, dass drei Knoten gleichzeitig ausfallen, und ein solches Setup wird einen Absturz von bis zu zwei Knoten überleben. Ein ganzes Rechenzentrum kann offline gehen und zwei verbleibende DCs werden den Betrieb fortsetzen. Es hat auch einen großen Vorteil gegenüber dem minimalen Setup – wenn ein Knoten offline geht, gibt es immer einen zweiten Knoten im Rechenzentrum, der als Spender dienen kann. Meistens wird das WAN nicht für SST verwendet.
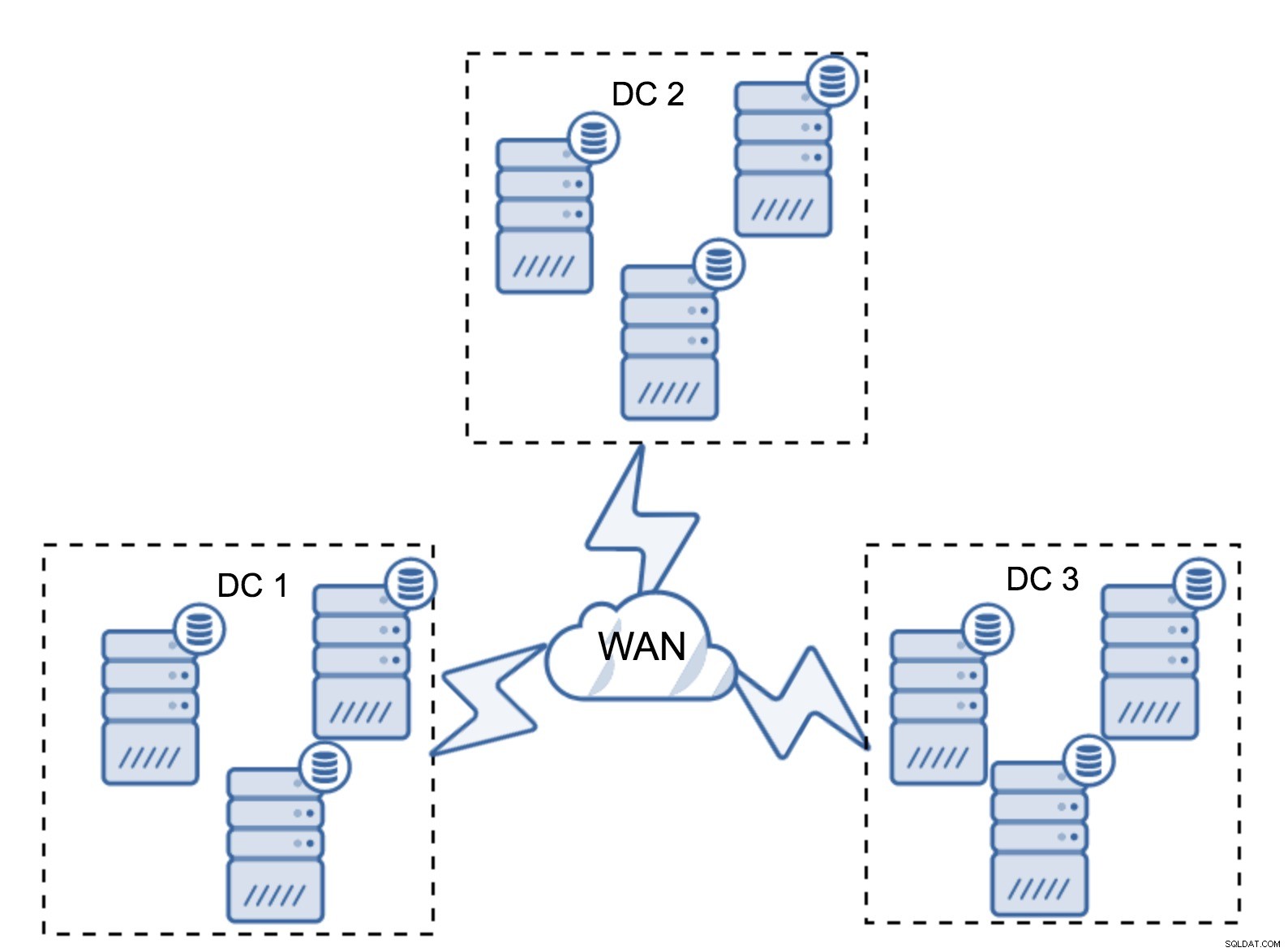
Natürlich können Sie die Anzahl der Knoten auf drei pro Cluster erhöhen, also insgesamt auf neun. Dadurch erhalten Sie eine noch bessere Überlebensfähigkeit:Bis zu vier Knoten können abstürzen und der Cluster wird trotzdem überleben. Andererseits müssen Sie bedenken, dass selbst bei der Verwendung von Segmenten mehr Knoten einen höheren Betriebsaufwand bedeuten und Sie den Galera-Cluster nur bis zu einem gewissen Grad skalieren können.
Es kann vorkommen, dass kein drittes Rechenzentrum erforderlich ist, weil sich Ihre Anwendung beispielsweise nur in zweien davon befindet. Natürlich ist die Anforderung von drei Rechenzentren immer noch gültig, sodass Sie sie nicht umgehen werden, aber es ist vollkommen in Ordnung, einen Galera Arbitrator (garbd) anstelle von voll ausgelasteten Datenbankservern zu verwenden.
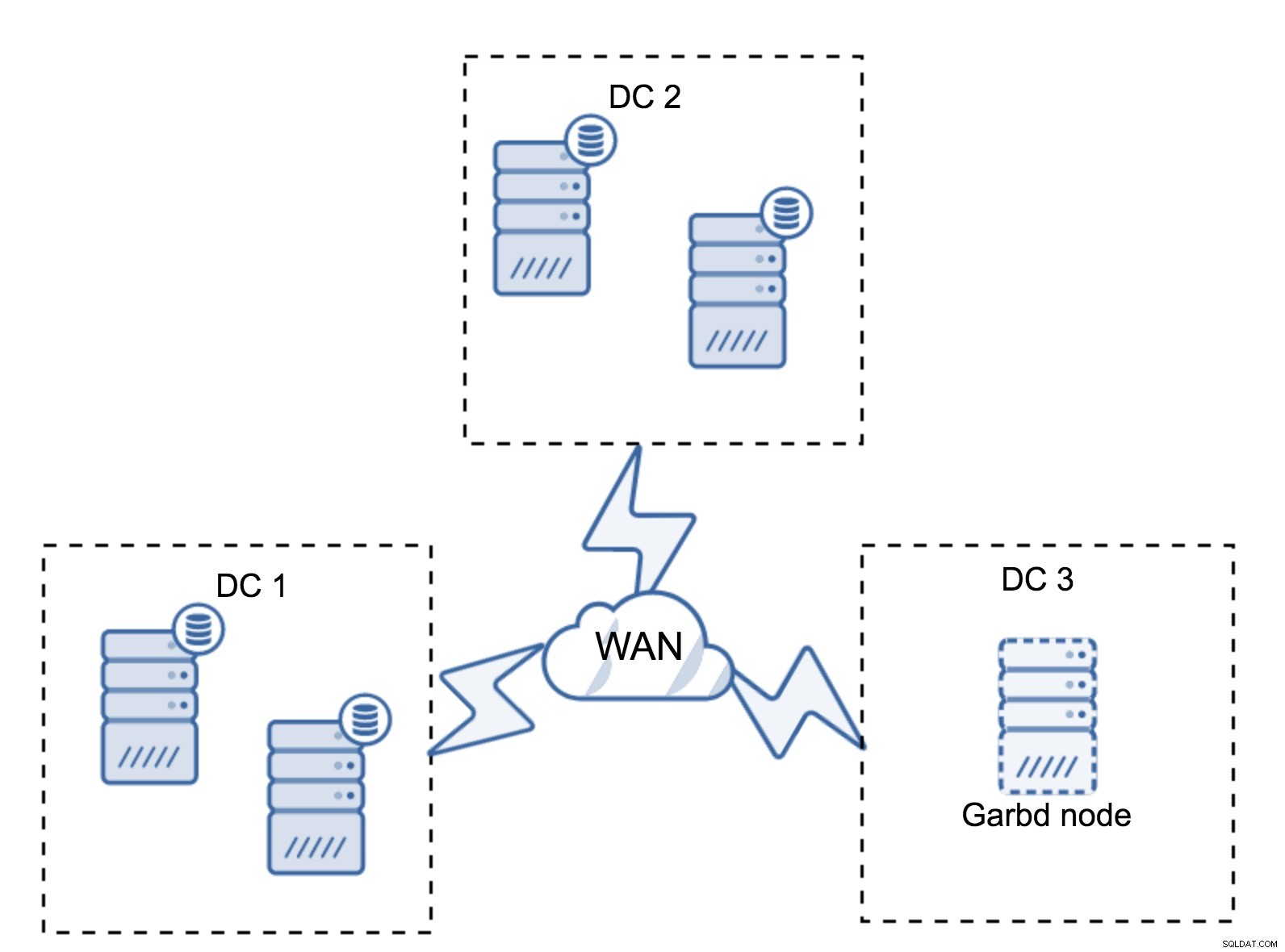
Garbd kann auf kleineren Knoten installiert werden, sogar auf virtuellen Servern. Es erfordert keine leistungsstarke Hardware, speichert keine Daten und wendet keine Writesets an. Aber es sieht den gesamten Replikationsverkehr und nimmt an der Quorum-Berechnung teil. Dank dessen können Sie Setups wie vier Knoten bereitstellen, zwei pro DC + garbd im dritten - Sie haben insgesamt fünf Knoten, und ein solcher Cluster kann bis zu zwei Ausfälle akzeptieren. Es bedeutet also, dass es eine vollständige Abschaltung eines der Rechenzentren akzeptieren kann.
Welche Option ist besser für Sie? Es gibt keine beste Lösung für alle Fälle, alles hängt von Ihren Infrastrukturanforderungen ab. Glücklicherweise gibt es verschiedene Optionen zur Auswahl:mehr oder weniger Knoten, volle 3 DC oder 2 DC und Garbd im dritten - es ist sehr wahrscheinlich, dass Sie etwas Passendes für sich finden.
Netzwerklatenz
Wenn Sie mit Multi-DC-Setups arbeiten, müssen Sie bedenken, dass die Netzwerklatenz deutlich höher ist, als Sie es von einer lokalen Netzwerkumgebung erwarten würden. Dies kann die Leistung des Galera-Clusters im Vergleich zu einer eigenständigen MySQL-Instanz oder einem MySQL-Replikations-Setup erheblich beeinträchtigen. Die Anforderung, dass alle Knoten ein Writeset zertifizieren müssen, bedeutet, dass alle Knoten es empfangen müssen, egal wie weit sie entfernt sind. Bei der asynchronen Replikation muss vor einem Commit nicht gewartet werden. Natürlich hat die Replikation andere Probleme und Nachteile, aber die Latenz ist nicht das Hauptproblem. Das Problem ist besonders sichtbar, wenn Ihre Datenbank Hotspots hat – Zeilen, die häufig aktualisiert werden (Zähler, Warteschlangen usw.). Diese Zeilen können nicht öfter als einmal pro Netzwerk-Roundtrip aktualisiert werden. Bei Clustern, die sich über die ganze Welt erstrecken, kann dies leicht bedeuten, dass Sie eine einzelne Zeile nicht öfter als 2-3 Mal pro Sekunde aktualisieren können. Wenn dies für Sie zu einer Einschränkung wird, kann dies bedeuten, dass der Galera-Cluster nicht gut für Ihre spezielle Arbeitslast geeignet ist.
Proxy-Layer im Multi-DC-Galera-Cluster
Es reicht nicht aus, dass sich Galera-Cluster über mehrere Rechenzentren erstrecken, Sie benötigen immer noch Ihre Anwendung, um darauf zuzugreifen. Eine der gängigen Methoden, um die Komplexität der Datenbankschicht vor einer Anwendung zu verbergen, ist die Verwendung eines Proxys. Proxys werden als Einstiegspunkt zu den Datenbanken verwendet, sie verfolgen den Status der Datenbankknoten und sollten den Datenverkehr immer nur zu den verfügbaren Knoten leiten. In diesem Abschnitt werden wir versuchen, ein Proxy-Layer-Design vorzuschlagen, das für einen Multi-DC-Galera-Cluster verwendet werden könnte. Wir verwenden ProxySQL, das Ihnen ziemlich viel Flexibilität bei der Handhabung von Datenbankknoten gibt, aber Sie können einen anderen Proxy verwenden, solange er den Status von Galera-Knoten verfolgen kann.
Wo finde ich die Proxys?
Kurz gesagt, hier gibt es zwei gängige Muster:Sie können ProxySQL entweder auf separaten Knoten oder auf den Anwendungshosts bereitstellen. Werfen wir einen Blick auf die Vor- und Nachteile jedes dieser Setups.
Proxy-Layer als separater Satz von Hosts
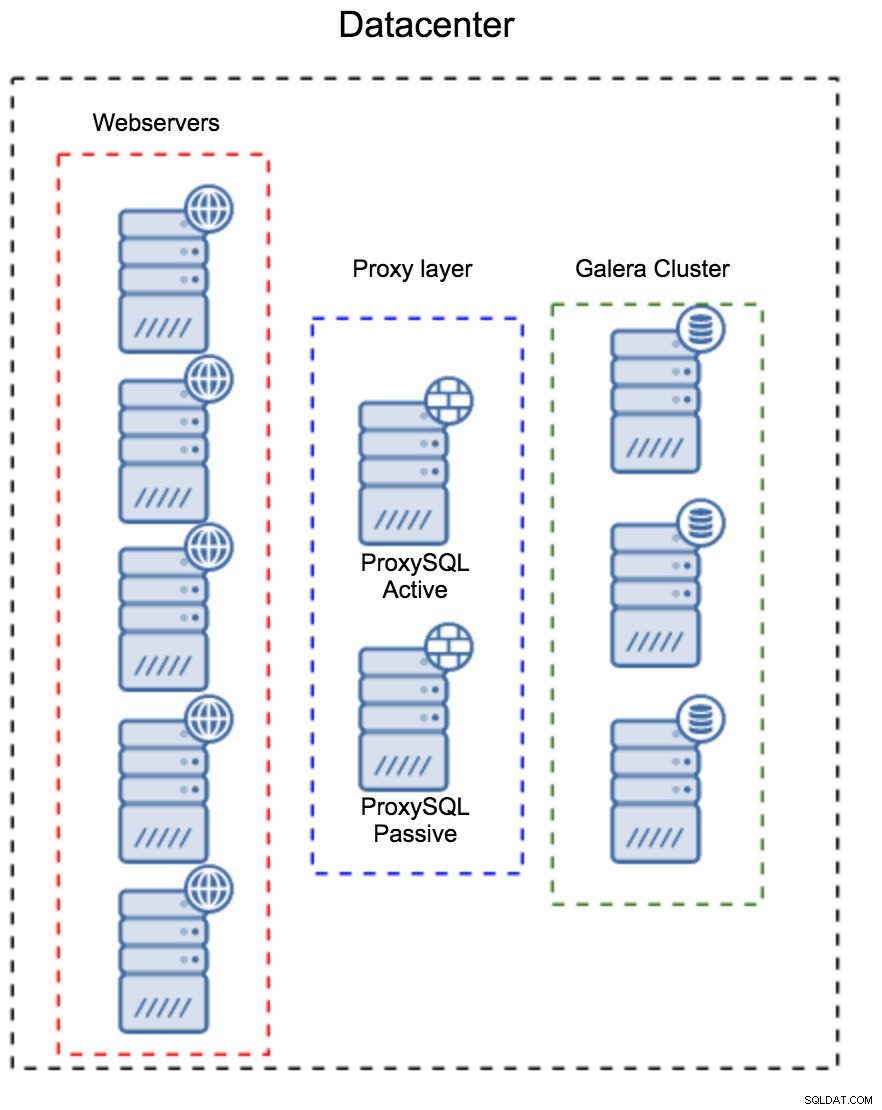
Das erste Muster besteht darin, eine Proxy-Schicht mit separaten, dedizierten Hosts aufzubauen. Sie können ProxySQL auf mehreren Hosts bereitstellen und Virtual IP und Keepalived verwenden, um eine hohe Verfügbarkeit aufrechtzuerhalten. Eine Anwendung verwendet den VIP, um eine Verbindung zur Datenbank herzustellen, und der VIP stellt sicher, dass Anforderungen immer an einen verfügbaren ProxySQL weitergeleitet werden. Das Hauptproblem bei diesem Setup besteht darin, dass Sie höchstens eine der ProxySQL-Instanzen verwenden – alle Standby-Knoten werden nicht zum Routing des Datenverkehrs verwendet. Dies kann Sie dazu zwingen, leistungsstärkere Hardware zu verwenden, als Sie normalerweise verwenden würden. Andererseits ist es einfacher, das Setup zu warten – Sie müssen Konfigurationsänderungen auf alle ProxySQL-Knoten anwenden, aber es wird nur eine Handvoll davon geben. Sie können auch die Option von ClusterControl verwenden, um die Knoten zu synchronisieren. Eine solche Einrichtung muss in jedem Rechenzentrum, das Sie verwenden, dupliziert werden.
Proxy auf Anwendungsinstanzen installiert
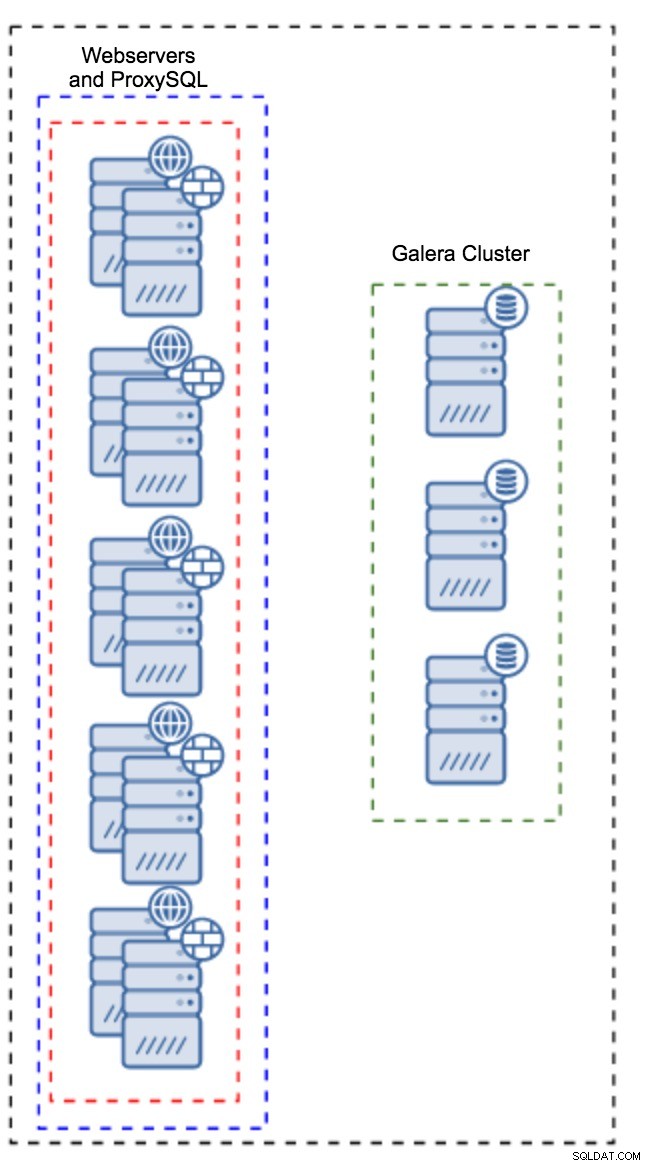
Anstelle eines separaten Satzes von Hosts kann ProxySQL auch auf den Anwendungshosts installiert werden. Die Anwendung stellt eine direkte Verbindung zu ProxySQL auf localhost her, sie könnte sogar einen Unix-Socket verwenden, um den Overhead der TCP-Verbindung zu minimieren. Der Hauptvorteil eines solchen Setups besteht darin, dass Sie über eine große Anzahl von ProxySQL-Instanzen verfügen und die Last gleichmäßig auf sie verteilt wird. Wenn einer ausfällt, ist nur dieser Anwendungshost betroffen. Die verbleibenden Knoten funktionieren weiterhin. Das schwerwiegendste Problem ist das Konfigurationsmanagement. Bei einer großen Anzahl von ProxySQL-Knoten ist es entscheidend, eine automatisierte Methode zu finden, um ihre Konfigurationen synchron zu halten. Sie könnten ClusterControl oder ein Konfigurationsverwaltungstool wie Puppet verwenden.
Tuning von Galera in einer WAN-Umgebung
Die Standardeinstellungen von Galera sind für das lokale Netzwerk konzipiert, und wenn Sie es in einer WAN-Umgebung verwenden möchten, ist eine gewisse Anpassung erforderlich. Lassen Sie uns einige der grundlegenden Optimierungen besprechen, die Sie vornehmen können. Bitte denken Sie daran, dass die genaue Abstimmung Produktionsdaten und Datenverkehr erfordert – Sie können nicht einfach einige Änderungen vornehmen und davon ausgehen, dass sie gut sind, Sie sollten ein angemessenes Benchmarking durchführen.
Betriebssystemkonfiguration
Beginnen wir mit der Betriebssystemkonfiguration. Nicht alle der hier vorgeschlagenen Änderungen beziehen sich auf WAN, aber es ist immer gut, sich daran zu erinnern, was ein guter Ausgangspunkt für eine MySQL-Installation ist.
vm.swappiness = 1Swapiness steuert, wie aggressiv das Betriebssystem Swap verwendet. Es sollte nicht auf Null gesetzt werden, da es in neueren Kerneln das Betriebssystem daran hindert, Swap überhaupt zu verwenden, und ernsthafte Leistungsprobleme verursachen kann.
/sys/block/*/queue/scheduler = deadline/noopDer Scheduler für das Blockgerät, das MySQL verwendet, sollte entweder auf „deadline“ oder „noop“ gesetzt werden. Die genaue Wahl hängt von den Benchmarks ab, aber beide Einstellungen sollten eine ähnliche Leistung liefern, besser als der Standard-Scheduler CFQ.
Für MySQL sollten Sie je nach Kernel die Verwendung von EXT4 oder XFS in Betracht ziehen (die Leistung dieser Dateisysteme ändert sich von einer Kernelversion zur anderen). Führen Sie einige Benchmarks durch, um die bessere Option für Sie zu finden.
Darüber hinaus sollten Sie sich die sysctl-Netzwerkeinstellungen ansehen. Wir werden sie nicht im Detail besprechen (Dokumentation finden Sie hier), aber die allgemeine Idee ist, Puffer, Rückstände und Zeitüberschreitungen zu erhöhen, um es einfacher zu machen, Verzögerungen und instabile WAN-Verbindungen auszugleichen.
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0Zusätzlich zur Optimierung des Betriebssystems sollten Sie in Betracht ziehen, die netzwerkbezogenen Einstellungen von Galera zu optimieren.
evs.suspect_timeout
evs.inactive_timeoutMöglicherweise möchten Sie die Standardwerte dieser Variablen ändern. Beide Zeitüberschreitungen bestimmen, wie der Cluster ausgefallene Knoten entfernt. Fehlerhafte Zeitüberschreitung findet statt, wenn alle Knoten das inaktive Mitglied nicht erreichen können. Das Inaktivitäts-Timeout definiert eine feste Grenze dafür, wie lange ein Knoten im Cluster bleiben kann, wenn er nicht antwortet. Normalerweise werden Sie feststellen, dass die Standardwerte gut funktionieren. Aber in einigen Fällen, insbesondere wenn Sie Ihren Galera-Cluster über WAN ausführen (z. B. zwischen AWS-Regionen), kann das Erhöhen dieser Variablen zu einer stabileren Leistung führen. Wir empfehlen, beide auf PT1M einzustellen, um die Wahrscheinlichkeit zu verringern, dass die Instabilität der WAN-Verbindung einen Knoten aus dem Cluster wirft.
evs.send_window
evs.user_send_windowDiese Variablen, evs.send_window und evs.user_send_window , legen Sie fest, wie viele Pakete gleichzeitig per Replikation versendet werden können (evs.send_window ) und wie viele davon Daten enthalten dürfen (evs.user_send_window ). Bei Verbindungen mit hoher Latenz kann es sich lohnen, diese Werte erheblich zu erhöhen (z. B. 512 oder 1024).
evs.inactive_check_periodDie obige Variable kann auch geändert werden. evs.inactive_check_period , ist standardmäßig auf eine Sekunde eingestellt, was für eine WAN-Einrichtung zu oft sein kann. Wir empfehlen, ihn auf PT30S einzustellen.
gcs.fc_factor
gcs.fc_limitHier möchten wir die Wahrscheinlichkeit minimieren, dass die Flusskontrolle einsetzt, daher empfehlen wir, gcs.fc_factor festzulegen auf 1 und erhöhen Sie gcs.fc_limit B. auf 260.
gcs.max_packet_sizeDa wir mit der WAN-Verbindung arbeiten, bei der die Latenz deutlich höher ist, möchten wir die Größe der Pakete erhöhen. Ein guter Ausgangspunkt wäre 2097152.
Wie wir bereits erwähnt haben, ist es praktisch unmöglich, ein einfaches Rezept für die Einstellung dieser Parameter zu geben, da dies von zu vielen Faktoren abhängt – Sie müssen Ihre eigenen Benchmarks durchführen und Daten verwenden, die Ihren Produktionsdaten so nahe wie möglich kommen, bevor Sie es tun kann sagen, Ihr System ist abgestimmt. Allerdings sollten diese Einstellungen Ihnen einen Ausgangspunkt für die genauere Abstimmung geben.
Das war es fürs Erste. Galera funktioniert ziemlich gut in WAN-Umgebungen, also probieren Sie es aus und lassen Sie uns wissen, wie Sie vorankommen.