Ist die eigentliche Forderung, dass die Nebenfolge lückenlos ist? Wenn ja, haben Sie ein riesiges Serialisierungs-/Skalierbarkeitsproblem.
Wenn Sie eine lückenlose Sequenz für den menschlichen Konsum präsentieren müssen, könnten Sie eine tatsächliche Sequenz (oder einen Zeitstempel, was das angeht) verwenden, wie Nick Pierpont vorschlägt, und die Skalierbarkeit bewahren, Sie könnten Analysefunktionen verwenden.
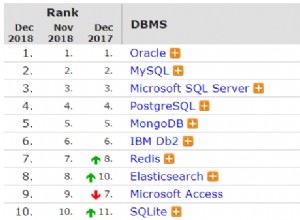
Datensatz (t1):
ID_PERSON SEQUENCE_ID
---------- -----------
1 1
2 2
3 3
1 4
1 5
1 6
2 7
3 8
1 9
SQL:
select *
from
(select id_person,
sequence_id as orig_sequence_id,
rank ()
over (partition by id_person
order by sequence_id)
as new_sequence_id
from t1
)
order by id_person, new_sequence_id;
Ergebnis:
ID_PERSON ORIG_SEQUENCE_ID NEW_SEQUENCE_ID
---------- ---------------- ---------------
1 1 1
1 4 2
1 5 3
1 6 4
1 9 5
2 2 1
2 7 2
3 3 1
3 8 2