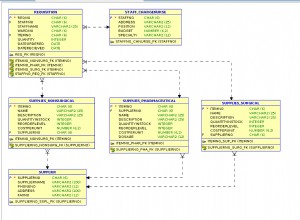
Angenommen, alle Städtenamen bestehen aus Kleinbuchstaben, könnten Sie etwa so vorgehen:
select city
from station
where substr(city, 1, 1) in ('a', 'e', 'i', 'o', 'u')
and substr(city, -1, 1) in ('a', 'e', 'i', 'o', 'u')
substr(city, 1, 1) nimmt den Teilstring von city beginnend bei Position 1 und Länge 1 (d. h. nur der erste Buchstabe). substr(city, -1, 1) ist sehr ähnlich, nur die Position ist anders:-1 bedeutet erster Buchstabe vom Ende der Zeichenfolge - so erhalten Sie den letzten Buchstaben des Stadtnamens.
Wenn city kann im WHERE sowohl Groß- als auch Kleinbuchstaben enthalten -Klausel verwenden Sie lower(city) statt city .
BEARBEITEN :Auf vielfachen Wunsch hier ist, wie das Gleiche mit regulären Ausdrücken gemacht werden kann. Es hat jedoch keinen Sinn, hier einen regulären Ausdrucksansatz zu verwenden; Die Standard-String-Funktionen (wie SUBSTR) sind mit ziemlicher Sicherheit viel schneller als alles, was auf regulären Ausdrücken basiert.
....
where regexp_like(city, '^(a|e|i|o|u).*(a|e|i|o|u)$', 'i')
(a|e|i|o|u) bedeutet genau eines dieser Zeichen. ^ bedeutet Anker am Anfang des Strings und ähnlich $ am Ende der Zeichenfolge. Dazu muss der Städtename streng genommen mindestens zwei Buchstaben lang sein; Wenn Städtenamen mit einem Buchstaben möglich sind, können diese leicht geändert werden. (Der SUBSTR-Ansatz würde keine Änderungen erfordern.)
Das letzte Argument, 'i' , macht die Groß-/Kleinschreibung der Regexp-Übereinstimmung unempfindlich (nur für den Fall, dass dies erforderlich ist).