Warum MySQL-Replikation wählen?
Zunächst einige Grundlagen zur Replikationstechnologie. Die MySQL-Replikation ist nicht kompliziert! Es ist einfach zu implementieren, zu überwachen und zu optimieren, da es verschiedene Ressourcen gibt, die Sie nutzen können - Google ist eine davon. MySQL Replication enthält nicht viele zu optimierende Konfigurationsvariablen. Die logischen Fehler von SQL_THREAD und IO_THREAD sind nicht so schwer zu verstehen und zu beheben. Die MySQL-Replikation ist heutzutage sehr beliebt und bietet eine einfache Möglichkeit, Hochverfügbarkeit für Datenbanken zu implementieren. Leistungsstarke Funktionen wie GTID (Global Transaction Identifier) anstelle der altmodischen binären Log-Position oder verlustfreie halbsynchrone Replikation machen es robuster.
Wie wir in einem früheren Beitrag gesehen haben, ist die Netzwerklatenz eine große Herausforderung bei der Auswahl einer Hochverfügbarkeitslösung. Die Verwendung von MySQL Replication bietet den Vorteil, dass es nicht so anfällig für Latenzzeiten ist. Es implementiert keine zertifizierungsbasierte Replikation, im Gegensatz zu Galera Cluster, das Gruppenkommunikations- und Transaktionsordnungstechniken verwendet, um eine synchrone Replikation zu erreichen. Daher ist es nicht erforderlich, dass alle Knoten ein Writeset zertifizieren müssen, und es ist nicht erforderlich, vor einem Commit auf dem anderen Slave oder Replikat zu warten.
Die Wahl der traditionellen MySQL-Replikation mit asynchronem Primär-Sekundär-Ansatz bietet Ihnen Geschwindigkeit bei der Abwicklung von Transaktionen innerhalb Ihres Masters; Es muss nicht darauf gewartet werden, dass die Slaves synchronisieren oder Transaktionen festschreiben. Das Setup hat typischerweise einen primären (Master) und einen oder mehrere sekundäre (Slaves). Daher handelt es sich um ein Shared-Nothing-System, bei dem alle Server standardmäßig eine vollständige Kopie der Daten haben. Natürlich gibt es Nachteile. Die Datenintegrität kann ein Problem darstellen, wenn Ihre Slaves aufgrund von SQL- und E/A-Thread-Fehlern oder Abstürzen nicht repliziert werden konnten. Um Probleme mit der Datenintegrität zu beheben, können Sie alternativ die halbsynchrone MySQL-Replikation implementieren (oder in MySQL 5.7 als verlustfreie halbsynchrone Replikation bezeichnet). Das funktioniert so, dass der Master warten muss, bis ein Replikat alle Ereignisse der Transaktion bestätigt. Dies bedeutet, dass es seine Schreibvorgänge in ein Relaisprotokoll beenden und auf die Festplatte leeren muss, bevor es eine ACK-Antwort an den Master zurücksendet. Bei aktivierter halbsynchroner Replikation müssen Threads oder Sitzungen im Master auf die Bestätigung von einem Replikat warten. Sobald es eine ACK-Antwort vom Replikat erhält, kann es die Transaktion festschreiben. Die folgende Abbildung zeigt, wie MySQL die halbsynchrone Replikation handhabt.
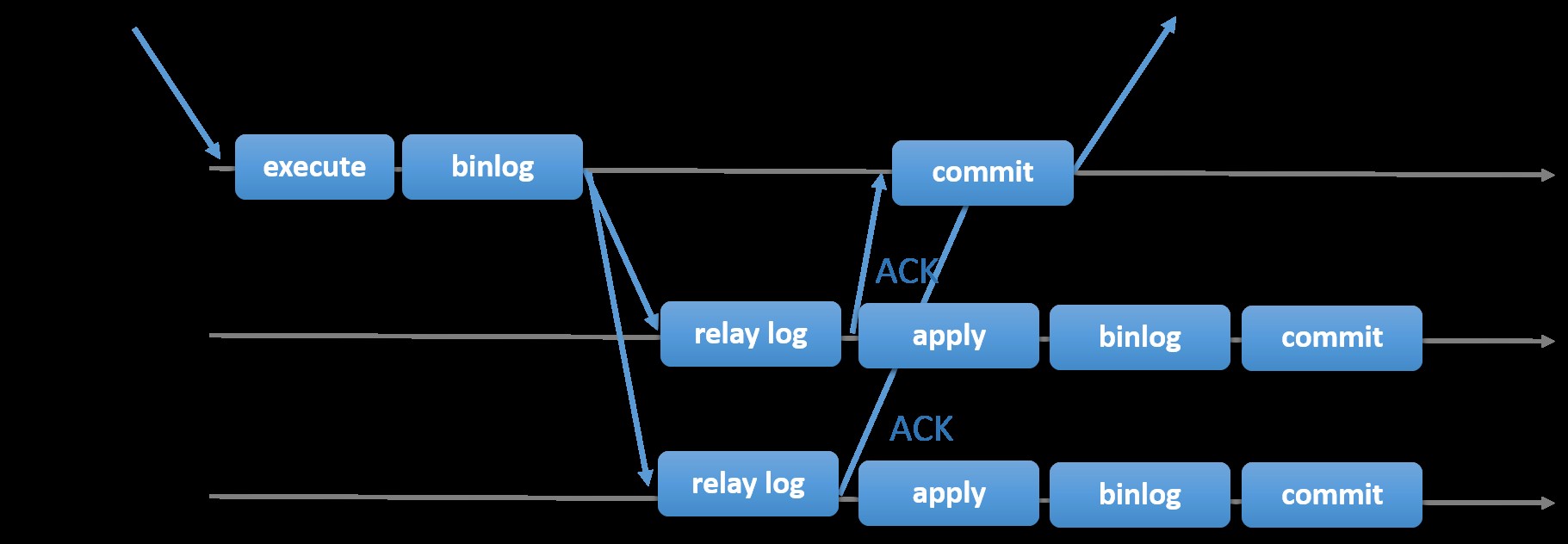 Bild mit freundlicher Genehmigung der MySQL-Dokumentation
Bild mit freundlicher Genehmigung der MySQL-Dokumentation Bei dieser Implementierung werden im Falle eines Master-Crashs bereits alle festgeschriebenen Transaktionen auf mindestens einen Slave repliziert. Semisynchron stellt für sich genommen zwar keine Hochverfügbarkeitslösung dar, ist aber eine Komponente für Ihre Lösung. Am besten kennen Sie Ihre Bedürfnisse und stimmen Ihre Semi-Sync-Implementierung entsprechend ab. Wenn also ein gewisser Datenverlust akzeptabel ist, können Sie stattdessen die traditionelle asynchrone Replikation verwenden.
Die GTID-basierte Replikation ist für den DBA hilfreich, da sie die Aufgabe eines Failovers vereinfacht, insbesondere wenn ein Slave auf einen anderen Master oder neuen Master verwiesen wird. Dies bedeutet, dass mit einem einfachen MASTER_AUTO_POSITION=1 nach dem Festlegen der richtigen Host- und Replikationsanmeldeinformationen die Replikation vom Master gestartet wird, ohne dass die richtigen X- und Y-Positionen des Binärlogs gesucht und angegeben werden müssen. Das Hinzufügen von Unterstützung für parallele Replikation steigert auch die Replikations-Threads, da es die Verarbeitung der Ereignisse aus dem Relay-Protokoll beschleunigt.
Daher ist die MySQL-Replikation eine hervorragende Wahlkomponente gegenüber anderen HA-Lösungen, wenn sie Ihren Anforderungen entspricht.
Topologien für die MySQL-Replikation
Die Bereitstellung von MySQL Replication in einer Multicloud-Umgebung mit GCP (Google Cloud Platform) und AWS ist immer noch derselbe Ansatz, wenn Sie vor Ort replizieren müssen.
Es gibt verschiedene Topologien, die Sie einrichten und implementieren können.
Master mit Slave-Replikation (Einzelreplikation)
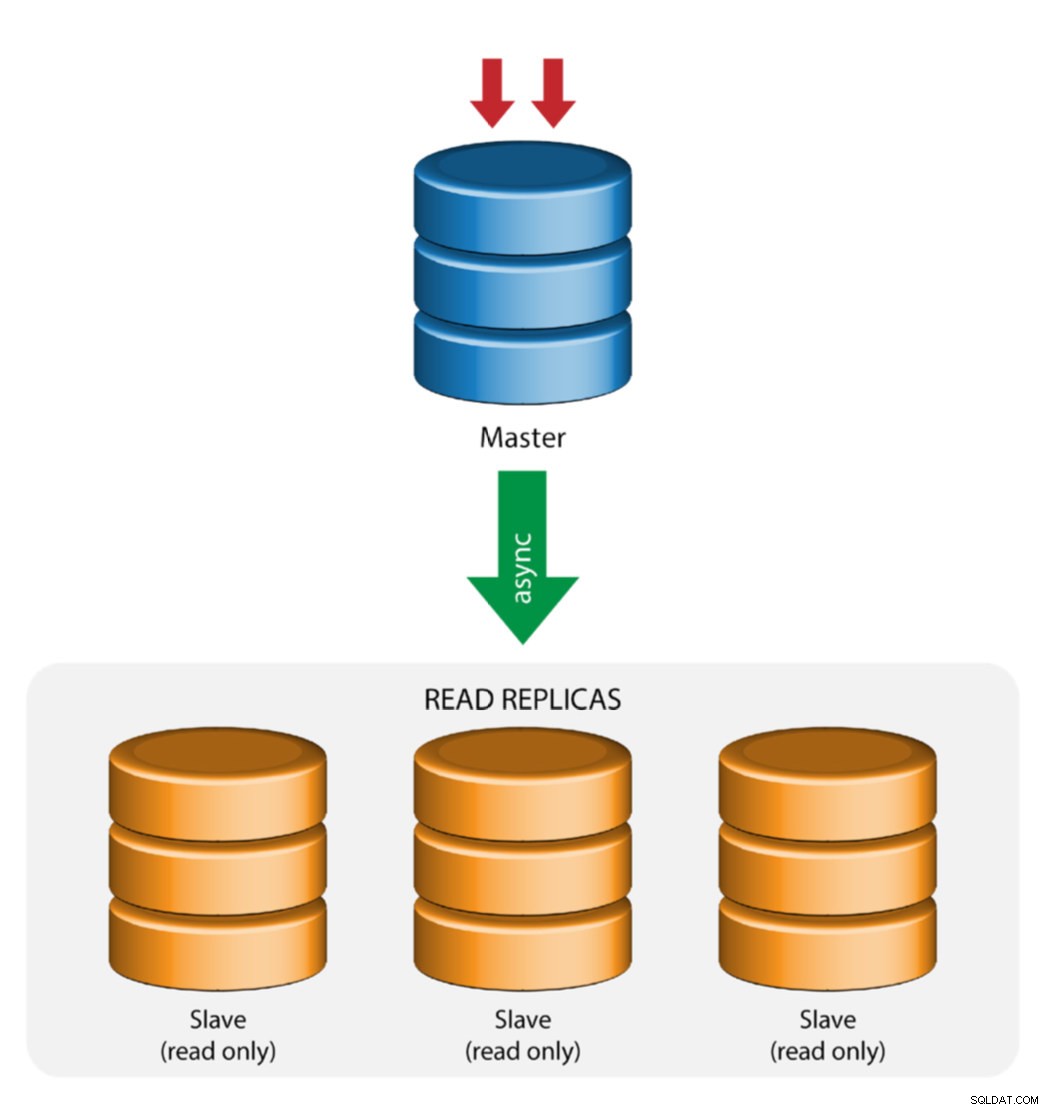
Dies ist die einfachste MySQL-Replikationstopologie. Ein Master empfängt Schreibvorgänge, ein oder mehrere Slaves replizieren von demselben Master über asynchrone oder halbsynchrone Replikation. Fällt der designierte Master aus, muss der aktuellste Slave zum neuen Master befördert werden. Die verbleibenden Slaves setzen die Replikation vom neuen Master fort.
Master mit Relay-Slaves (Kettenreplikation)
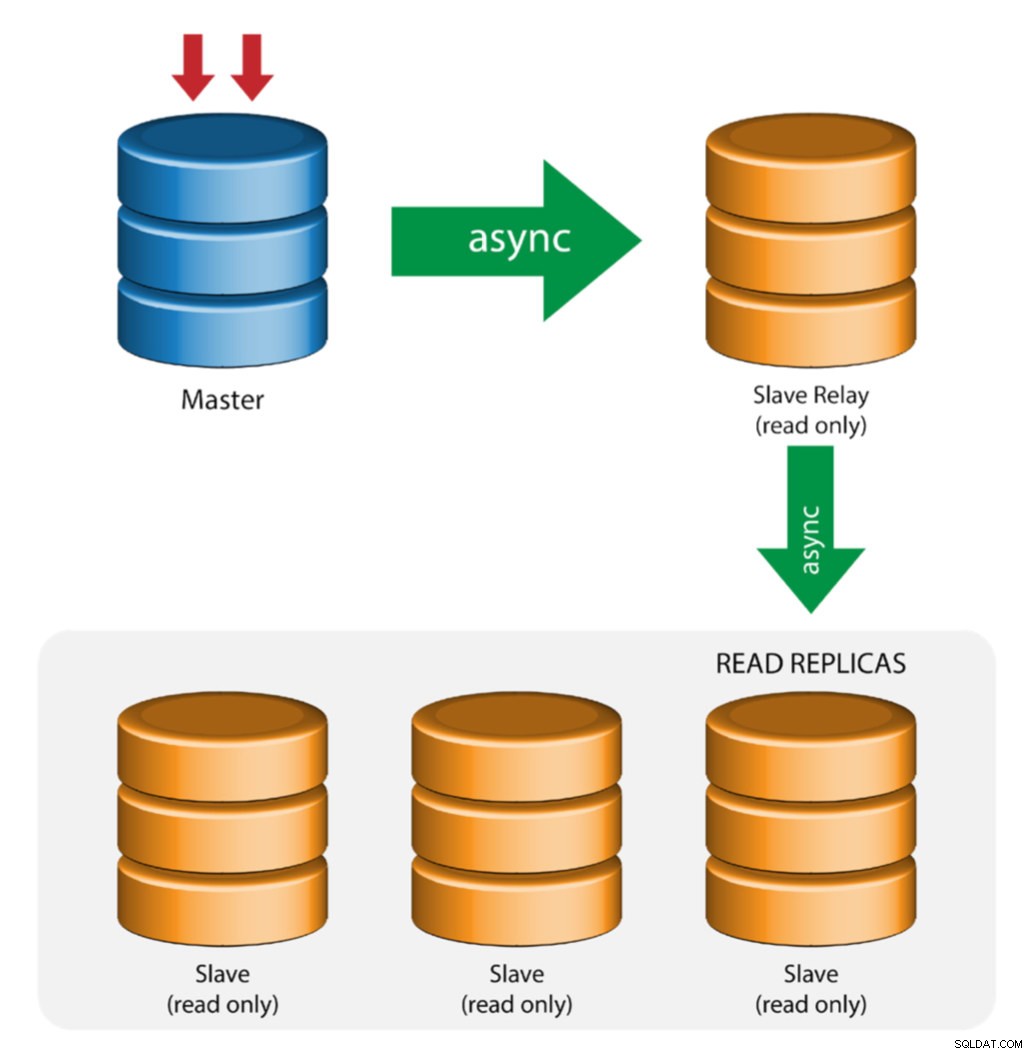
Dieses Setup verwendet einen zwischengeschalteten Master, der als Relais zu den anderen Slaves in der Replikationskette fungiert. Wenn viele Slaves mit einem Master verbunden sind, kann die Netzwerkschnittstelle des Masters überlastet werden. Diese Topologie ermöglicht es den Lesereplikaten, den Replikationsdatenstrom vom Relay-Server abzurufen, um den Master-Server zu entlasten. Auf dem Slave-Relay-Server müssen binäre Protokollierung und log_slave_updates aktiviert sein, wodurch Updates, die der Slave-Server vom Master-Server erhält, im eigenen Binär-Log des Slaves protokolliert werden.
Die Verwendung von Slave-Relais hat ihre Probleme:
- log_slave_updates hat einige Leistungseinbußen.
- Replikationsverzögerung auf dem Slave-Relay-Server führt zu Verzögerungen auf allen seinen Slaves.
- Rogue-Transaktionen auf dem Slave-Relay-Server infizieren alle seine Slaves.
- Wenn ein Slave-Relay-Server ausfällt und Sie GTID nicht verwenden, hören alle seine Slaves auf zu replizieren und müssen neu initialisiert werden.
Master mit aktivem Master (zirkuläre Replikation)
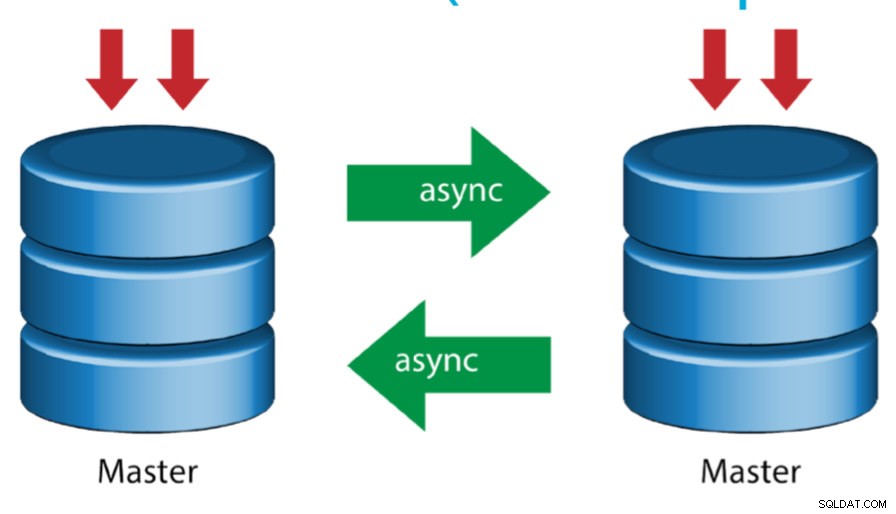
Dieses auch als Ringtopologie bezeichnete Setup erfordert zwei oder mehr MySQL-Server, die als Master fungieren. Alle Master erhalten Writes und generieren Binlogs mit einigen Vorbehalten:
- Sie müssen den Auto-Increment-Offset auf jedem Server einstellen, um Primärschlüsselkollisionen zu vermeiden.
- Es gibt keine Konfliktlösung.
- MySQL Replication unterstützt derzeit kein Sperrprotokoll zwischen Master und Slave, um die Atomarität eines verteilten Updates über zwei verschiedene Server zu gewährleisten.
- Gängige Praxis ist es, nur auf einen Master zu schreiben und der andere Master fungiert als Hot-Standby-Knoten. Wenn Sie jedoch Slaves unterhalb dieser Ebene haben, müssen Sie manuell auf den neuen Master umschalten, wenn der designierte Master ausfällt.
- ClusterControl unterstützt diese Topologie (wir empfehlen nicht mehrere Schreiber in einer Replikationskonfiguration). In diesem vorherigen Blog erfahren Sie, wie Sie mit ClusterControl bereitstellen.
Master mit Backup-Master (Mehrfachreplikation)
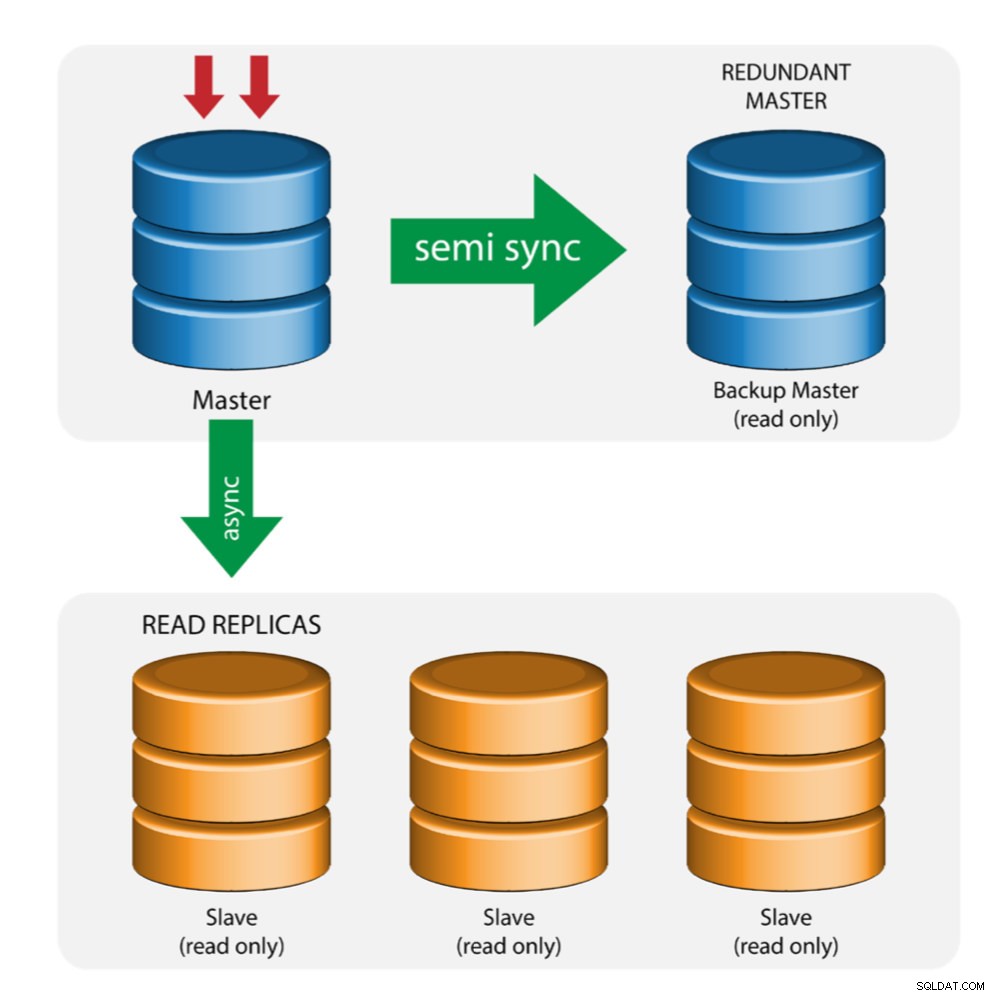
Der Master überträgt Änderungen an einen Backup-Master und an einen oder mehrere Slaves. Zwischen Master und Backup-Master wird eine halbsynchrone Replikation verwendet. Master sendet Update an Backup-Master und wartet mit Transaktionsfestschreibung. Der Backup-Master erhält Updates, schreibt in sein Relay-Log und leert es auf die Festplatte. Der Backup-Master bestätigt dann den Empfang der Transaktion an den Master und fährt mit der Transaktionsfestschreibung fort. Die halbsynchrone Replikation wirkt sich auf die Leistung aus, aber das Risiko eines Datenverlusts wird minimiert.
Diese Topologie funktioniert gut, wenn ein Master-Failover durchgeführt wird, falls der Master ausfällt. Der Backup-Master fungiert als Warm-Standby-Server, da er im Vergleich zu anderen Slaves die höchste Wahrscheinlichkeit hat, über aktuelle Daten zu verfügen.
Mehrere Master zu einem einzelnen Slave (Multi-Source-Replikation)
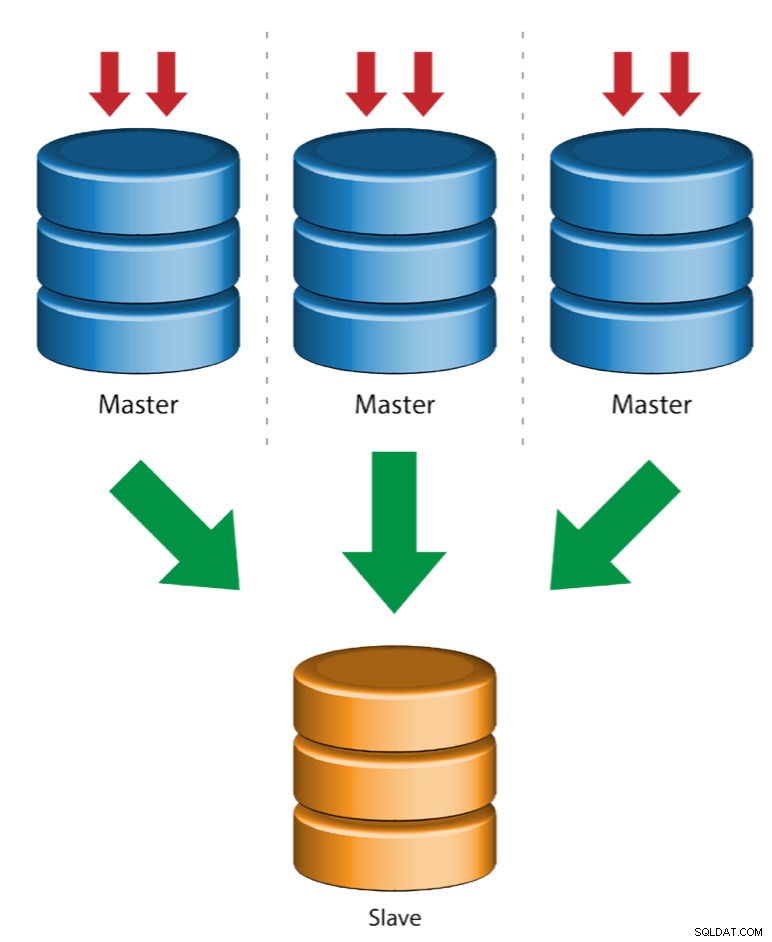
Multi-Source-Replikation ermöglicht einem Replikations-Slave, Transaktionen von mehreren Quellen gleichzeitig zu empfangen. Die Replikation aus mehreren Quellen kann verwendet werden, um mehrere Server auf einem einzigen Server zu sichern, Tabellen-Shards zusammenzuführen und Daten von mehreren Servern auf einem einzigen Server zu konsolidieren.
MySQL und MariaDB haben unterschiedliche Implementierungen der Multi-Source-Replikation, wobei für MariaDB eine GTID mit gtid-domain-id konfiguriert sein muss, um die ursprünglichen Transaktionen zu unterscheiden, während MySQL einen separaten Replikationskanal für jeden Master verwendet, von dem der Slave repliziert. In MySQL können Master in einer Multi-Source-Replikationstopologie so konfiguriert werden, dass sie entweder die globale Transaktionskennung (GTID)-basierte Replikation oder die binäre Log-Positions-basierte Replikation verwenden.
Mehr zur Multi-Source-Replikation von MariaDB finden Sie in diesem Blogbeitrag. Informationen zu MySQL finden Sie in der MySQL-Dokumentation.
Galera mit Replikations-Slave (Hybrid-Replikation)
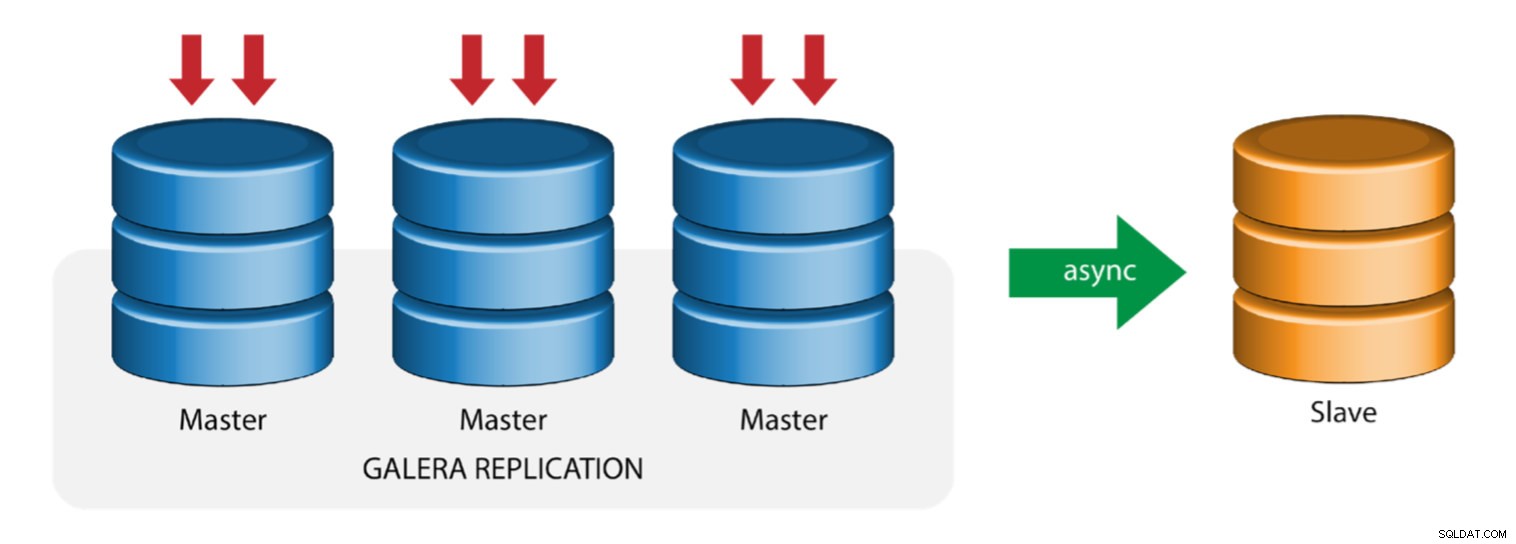
Die hybride Replikation ist eine Kombination aus asynchroner MySQL-Replikation und praktisch synchroner Replikation, die von Galera bereitgestellt wird. Die Bereitstellung wird jetzt durch die Implementierung von GTID in der MySQL-Replikation vereinfacht, wo das Einrichten und Durchführen eines Master-Failovers zu einem unkomplizierten Prozess auf der Slave-Seite geworden ist.
Die Leistung des Galera-Clusters ist so schnell wie der langsamste Knoten. Ein asynchroner Replikations-Slave kann die Auswirkungen auf den Cluster minimieren, wenn Sie lang andauernde Reporting-/OLAP-Abfragen an den Slave senden oder wenn Sie schwere Jobs ausführen, die Sperren wie mysqldump erfordern. Der Slave kann auch als Live-Backup für die Notfallwiederherstellung vor Ort und außerhalb dienen.
Die hybride Replikation wird von ClusterControl unterstützt und Sie können sie direkt über die ClusterControl-Benutzeroberfläche bereitstellen. Weitere Informationen hierzu finden Sie in den Blogbeiträgen – Hybride Replikation mit MySQL 5.6 und Hybride Replikation mit MariaDB 10.x.
GCP- und AWS-Plattformen vorbereiten
Das "reale" Problem
In diesem Blog werden wir die „Multiple Replication“-Topologie demonstrieren und verwenden, bei der Instanzen auf zwei verschiedenen öffentlichen Cloud-Plattformen mithilfe von MySQL Replication in verschiedenen Regionen und in verschiedenen Verfügbarkeitszonen kommunizieren. Dieses Szenario basiert auf einem realen Problem, bei dem eine Organisation ihre Infrastruktur auf mehreren Cloud-Plattformen für Skalierbarkeit, Redundanz, Ausfallsicherheit/Fehlertoleranz aufbauen möchte. Ähnliche Konzepte würden für MongoDB oder PostgreSQL gelten.
Betrachten wir eine US-Organisation mit einer Auslandsniederlassung in Südostasien. Unser Verkehr ist in der asiatischen Region hoch. Die Latenz muss niedrig sein, wenn es um Schreib- und Lesevorgänge geht, aber gleichzeitig kann die Region mit Sitz in den USA auch Datensätze aus dem Datenverkehr aus Asien abrufen.
Der Ablauf der Cloud-Architektur
In diesem Abschnitt gehe ich auf das architektonische Design ein. Erstens wollen wir eine hochsichere Ebene anbieten, für die unsere Google Compute- und AWS EC2-Knoten Pakete aus dem Internet kommunizieren, aktualisieren oder installieren können, sicher, hochverfügbar, falls eine AZ (Availability Zone) ausfällt, replizieren und über eine gesicherte Ebene mit einer anderen Cloud-Plattform kommunizieren. Siehe folgendes Bild zur Veranschaulichung:

Basierend auf der obigen Abbildung werden unter der AWS-Plattform alle Knoten in verschiedenen Verfügbarkeitszonen ausgeführt. Es hat ein privates und ein öffentliches Subnetz, für das sich alle Rechenknoten in einem privaten Subnetz befinden. Daher kann es das Internet verlassen, um seine Systempakete bei Bedarf abzurufen und zu aktualisieren. Es verfügt über ein VPN-Gateway, für das es mit GCP in diesem Kanal interagieren muss, wobei das Internet umgangen wird, jedoch über einen sicheren und privaten Kanal. Wie bei GCP befinden sich alle Rechenknoten in verschiedenen Verfügbarkeitszonen, verwenden Sie NAT Gateway, um Systempakete bei Bedarf zu aktualisieren, und verwenden Sie eine VPN-Verbindung, um mit den AWS-Knoten zu interagieren, die in einer anderen Region gehostet werden, d. h. im asiatisch-pazifischen Raum (Singapur). Auf der anderen Seite wird die in den USA ansässige Region unter us-east1 gehostet. Um auf die Knoten zuzugreifen, dient ein Knoten in der Architektur als Bastion-Knoten, für den wir ihn als Jump-Host verwenden und ClusterControl installieren. Dies wird später in diesem Blog behandelt.
Einrichten von GCP- und AWS-Umgebungen
Bei der Registrierung Ihres ersten GCP-Kontos stellt Google ein Standard-VPC-Konto (Virtual Private Cloud) bereit. Daher ist es am besten, eine separate VPC als die Standard-VPC zu erstellen und sie an Ihre Bedürfnisse anzupassen.
Unser Ziel hier ist es, die Rechenknoten in privaten Subnetzen zu platzieren, oder Knoten werden nicht mit öffentlichem IPv4 eingerichtet. Daher müssen beide Public Clouds miteinander kommunizieren können. Die AWS- und GCP-Rechenknoten arbeiten, wie bereits erwähnt, mit unterschiedlichen CIDRs. Daher sind hier die folgenden CIDR:
AWS-Rechenknoten: 172.21.0.0/16
GCP-Rechenknoten: 10.142.0.0/20
In diesem AWS-Setup haben wir drei Subnetze zugewiesen, die kein Internet-Gateway, sondern ein NAT-Gateway haben; und ein Subnetz, das über ein Internet-Gateway verfügt. Jedes dieser Subnetze wird einzeln in verschiedenen Availability Zones (AZ) gehostet.
ap-southeast-1a =172.21.1.0/24
ap-southeast-1b =172.21.8.0/24
ap-southeast-1c =172.21.24.0/24
In der GCP wird das in einer VPC unter us-east1 erstellte Standardsubnetz mit 10.142.0.0/20 CIDR verwendet. Daher sind dies die Schritte, die Sie befolgen können, um Ihre Multi-Public-Cloud-Plattform einzurichten.
-
Für diese Übung habe ich eine VPC in der Region us-east1 mit dem folgenden Subnetz 10.142.0.0/20 erstellt. Siehe unten:

-
Reservieren Sie eine statische IP. Dies ist die IP, die wir als Kunden-Gateway in AWS einrichten werden
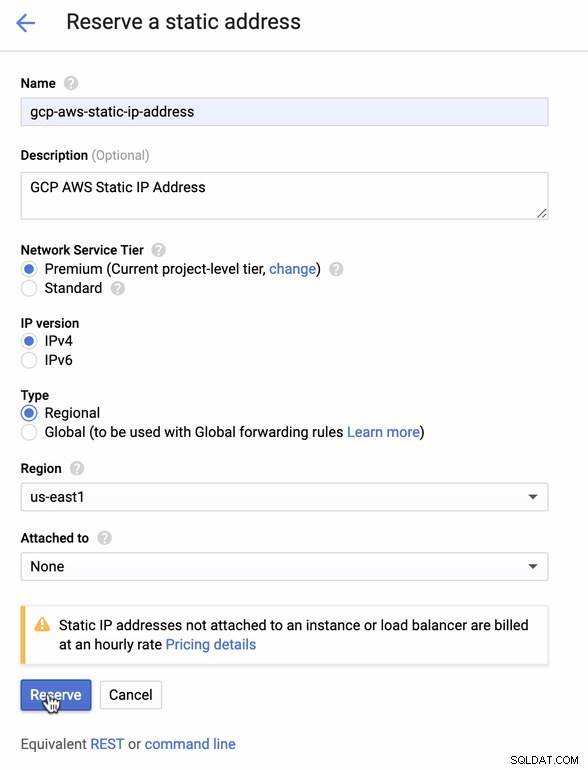
-
Da wir Subnetze eingerichtet haben (bereitgestellt als subnet-us-east1 ) gehen Sie zu GCP -> VPC-Netzwerk -> VPC-Netzwerke und wählen Sie die von Ihnen erstellte VPC aus und gehen Sie zu den Firewall-Regeln . Fügen Sie in diesem Abschnitt die Regeln hinzu, indem Sie Ihren eingehenden und ausgehenden Traffic angeben. Im Grunde sind dies die Inbound/Outbound-Regeln in AWS oder Ihrer Firewall für ein- und ausgehende Verbindungen. In diesem Setup habe ich alle TCP-Protokolle aus dem CIDR-Bereich geöffnet, der in meiner AWS- und GCP-VPC festgelegt ist, um es für die Zwecke dieses Blogs einfacher zu machen. Daher ist dies nicht der optimale Weg für die Sicherheit. Siehe Bild unten:
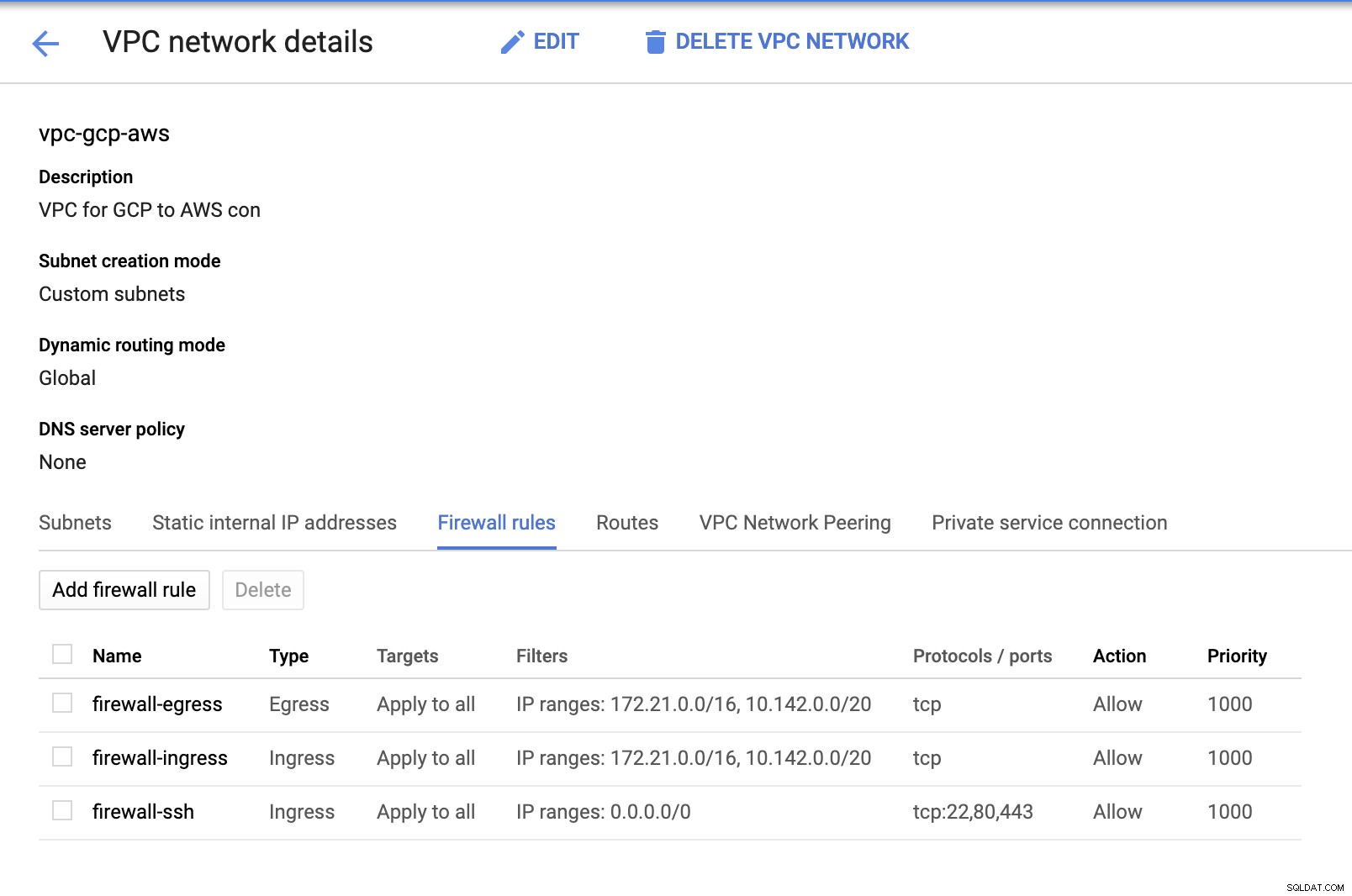
Die Firewall-ssh hier wird verwendet, um eingehende ssh-, HTTP- und HTTPS-Verbindungen zuzulassen.
-
Wechseln Sie nun zu AWS und erstellen Sie eine VPC. Für diesen Blog habe ich CIDR (Classless Inter-Domain Routing) 172.21.0.0/16
verwendet -
Erstellen Sie die Subnetze, für die Sie sie in jeder AZ (Availability Zone) zuweisen müssen; und reservieren Sie mindestens ein Subnetz für ein öffentliches Subnetz, das das NAT-Gateway handhabt, und der Rest ist für EC2-Knoten.

-
Erstellen Sie als Nächstes Ihre Routentabelle und stellen Sie sicher, dass „Ziel“ und „Ziele“ richtig eingestellt sind. Für diesen Blog habe ich 2 Routing-Tabellen erstellt. Eine, die die 3 AZ handhabt, die meinen Rechenknoten einzeln zugewiesen werden, und die ohne Internet-Gateway zugewiesen werden, da sie keine öffentliche IP hat. Dann verwaltet der andere das NAT-Gateway und hat ein Internet-Gateway, das sich im öffentlichen Subnetz befindet. Siehe Bild unten:

und wie bereits erwähnt, zeigt mein Beispielziel für eine private Route, die 3 Subnetze verarbeitet, ein NAT-Gateway-Ziel plus ein virtuelles Gateway-Ziel, das ich später in den eingehenden Schritten erwähnen werde.

-
Erstellen Sie als Nächstes ein „Internet Gateway“ und weisen Sie es der VPC zu, die zuvor im AWS-VPC-Abschnitt erstellt wurde. Dieses Internet-Gateway darf nur als Ziel für das öffentliche Subnetz festgelegt werden, da es der Dienst ist, der eine Verbindung zum Internet herstellen muss. Offensichtlich steht der Name für einen Internet-Gateway-Dienst.
-
Als nächstes erstellen Sie ein "NAT-Gateway". Stellen Sie beim Erstellen eines „NAT-Gateways“ sicher, dass Sie Ihr NAT einem öffentlich zugänglichen Subnetz zugewiesen haben. Das NAT-Gateway ist Ihr Kanal für den Zugriff auf das Internet von Ihrem privaten Subnetz oder EC2-Knoten, denen keine öffentliche IPv4 zugewiesen ist. Erstellen oder weisen Sie dann eine EIP (Elastic IP) zu, da in AWS nur Rechenknoten, denen eine öffentliche IPv4 zugewiesen ist, eine direkte Verbindung zum Internet herstellen können.
-
Jetzt unter VPC -> Sicherheit -> Sicherheitsgruppen (SG) , hat Ihre erstellte VPC eine Standard-SG. Für dieses Setup habe ich „Inbound Rules“ mit Quellen erstellt, die jedem CIDR zugewiesen sind, d. h. 10.142.0.0/20 in GCP und 172.21.0.0/16 in AWS. Siehe unten:

Für "Outbound Rules" können Sie das so lassen, da die Zuweisung von Regeln zu "Inbound Rules" bilateral ist, was bedeutet, dass es auch für "Outbound Rules" geöffnet wird. Beachten Sie, dass dies nicht der optimale Weg zum Festlegen Ihrer Sicherheitsgruppe ist; aber um es einfacher für dieses Setup zu machen, habe ich auch einen größeren Bereich von Portbereich und Quelle gemacht. Außerdem sind die Protokolle nur für TCP-Verbindungen spezifisch, da wir uns in diesem Blog nicht mit UDP befassen werden.
Außerdem können Sie Ihre VPC -> Sicherheit -> Netzwerk-ACLs unberührt, solange es keine TCP-Verbindungen von dem in Ihrer Quelle angegebenen CIDR VERWEIGERT. -
Als Nächstes richten wir die VPN-Konfiguration ein, die auf der AWS-Plattform gehostet wird. Unter VPC -> Kunden-Gateways , erstellen Sie das Gateway mit der statischen IP-Adresse, die zuvor im vorherigen Schritt erstellt wurde. Sehen Sie sich das folgende Bild an:
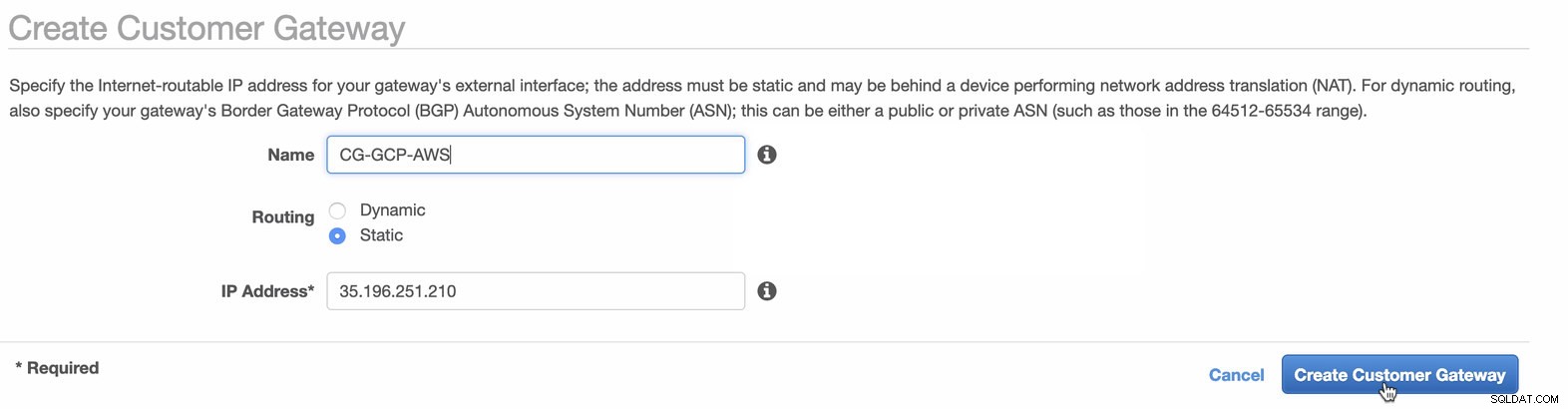
-
Erstellen Sie als Nächstes ein Virtual Private Gateway und hängen Sie dieses an die aktuelle VPC an, die wir zuvor im vorherigen Schritt erstellt haben. Siehe Bild unten:

-
Erstellen Sie nun eine VPN-Verbindung, die für die Site-to-Site-Verbindung zwischen AWS und GCP verwendet wird. Stellen Sie beim Erstellen einer VPN-Verbindung sicher, dass Sie das richtige Virtual Private Gateway und das richtige Kunden-Gateway ausgewählt haben, das wir in den vorherigen Schritten erstellt haben. Siehe Bild unten:
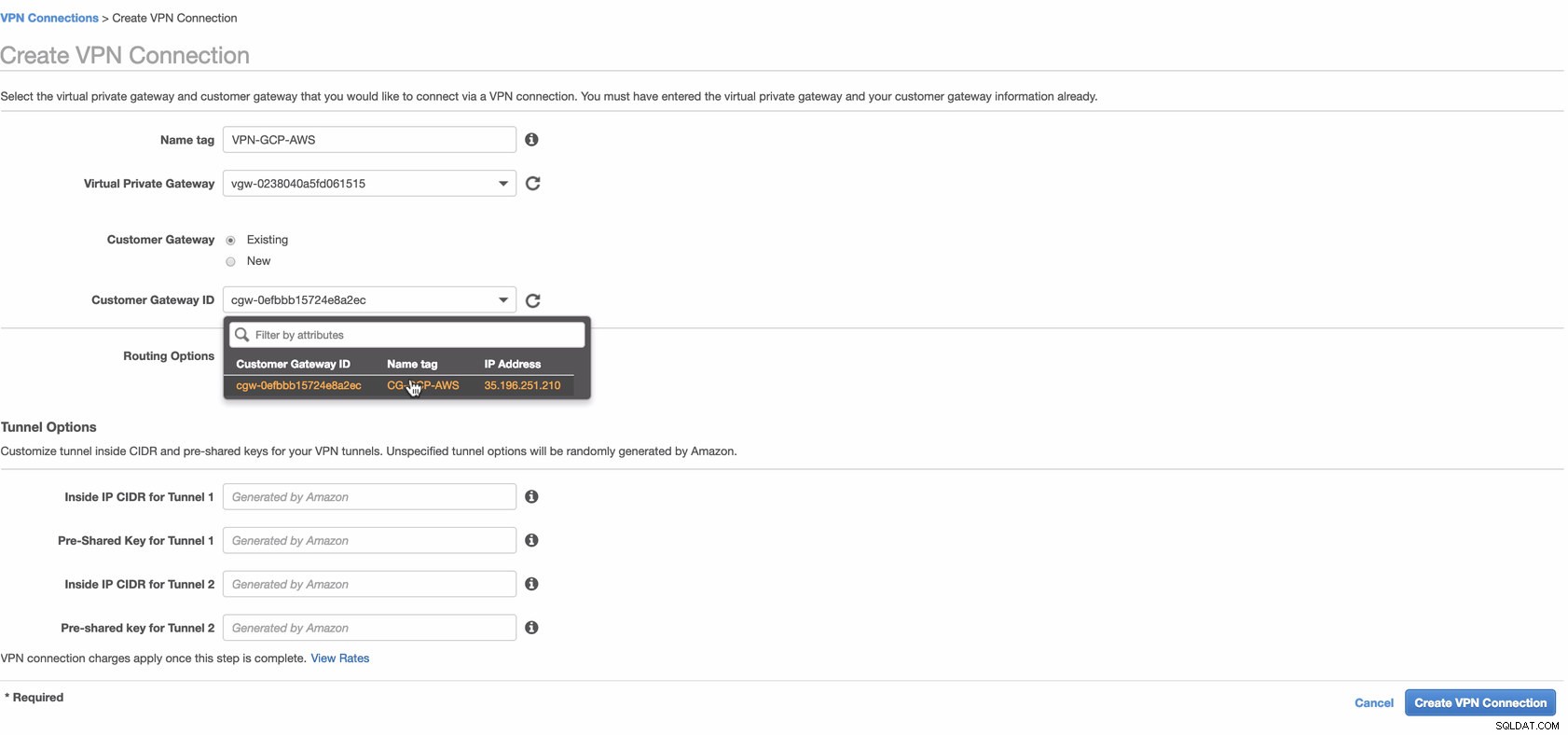
Dies kann einige Zeit dauern, während AWS Ihre VPN-Verbindung herstellt. Wenn Ihre VPN-Verbindung dann bereitgestellt wird, fragen Sie sich vielleicht, warum auf der Registerkarte „Tunnel“ (nachdem Sie Ihre VPN-Verbindung ausgewählt haben) die Außen-IP-Adresse angezeigt wird ist unten. Dies ist normal, da vom Client noch keine Verbindung hergestellt wurde. Sehen Sie sich das folgende Beispielbild an:

Sobald die VPN-Verbindung bereit ist, wählen Sie Ihre erstellte VPN-Verbindung aus und laden Sie die Konfiguration herunter. Es enthält Ihre Anmeldeinformationen, die für die folgenden Schritte zum Erstellen einer Site-to-Site-VPN-Verbindung mit dem Client erforderlich sind.
Hinweis: Falls Sie Ihr VPN dort eingerichtet haben, wo IPSEC AKTIV IST sondern Status ist DOWN genau wie das Bild unten

Dies liegt wahrscheinlich an falschen Werten, die beim Einrichten Ihrer BGP-Sitzung oder Ihres Cloud-Routers für die spezifischen Parameter festgelegt wurden. Sehen Sie sich hier die Fehlerbehebung für Ihr VPN an.
-
Da wir bereits eine VPN-Verbindung in AWS gehostet haben, erstellen wir eine VPN-Verbindung in GCP. Kehren wir nun zur GCP zurück und richten dort die Client-Verbindung ein. Gehen Sie in GCP zu GCP -> Hybridkonnektivität -> VPN . Stellen Sie sicher, dass Sie die richtige Region auswählen. In diesem Blog verwenden wir us-east1 . Wählen Sie dann die in den vorherigen Schritten erstellte statische IP-Adresse aus. Siehe Bild unten:
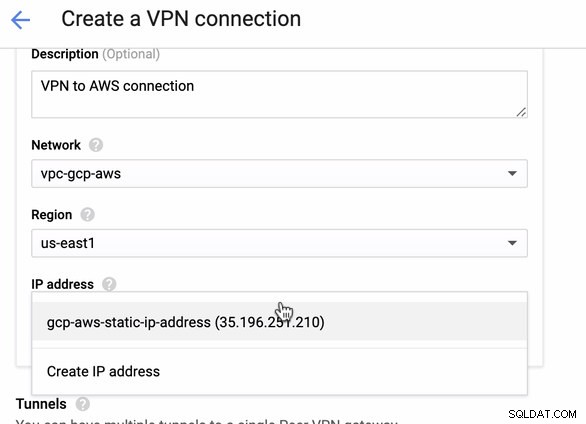
Dann in die Tunnel Abschnitt, hier müssen Sie die Einrichtung basierend auf den heruntergeladenen Anmeldeinformationen von der zuvor erstellten AWS VPN-Verbindung vornehmen. Ich schlage vor, diesen hilfreichen Leitfaden von Google zu lesen. Einer der Tunnel, der eingerichtet wird, ist beispielsweise in der folgenden Abbildung dargestellt:
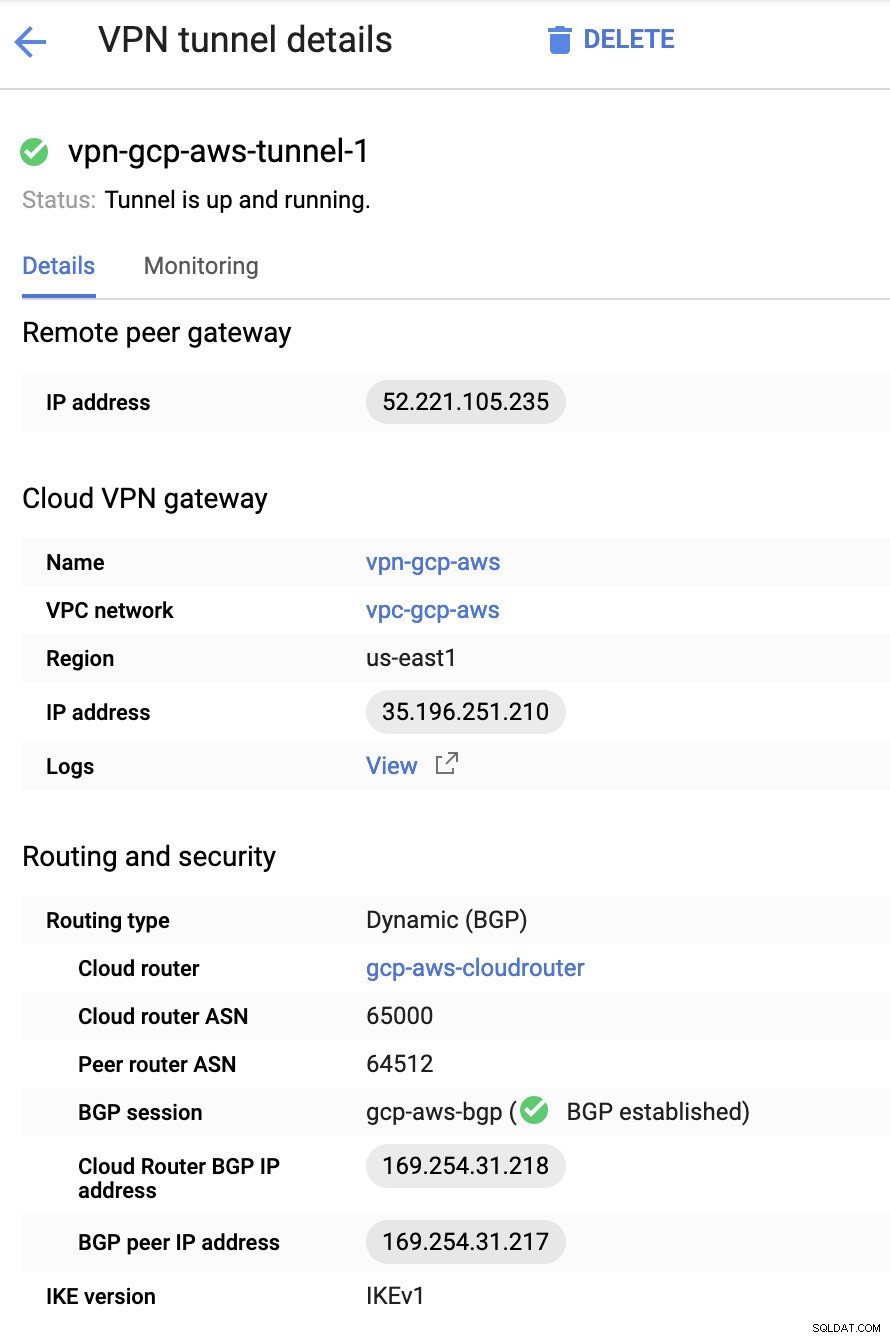
Grundsätzlich sind hier die wichtigsten Dinge:
- Remote-Peer-Gateway:IP-Adresse – Dies ist die IP des VPN-Servers, die unter Tunneldetails -> Externe IP-Adresse angegeben ist . Dies ist nicht mit der statischen IP zu verwechseln, die wir unter GCP erstellt haben. Das ist das Cloud VPN-Gateway -> IP-Adresse obwohl.
- Cloud-Router-ASN – Standardmäßig verwendet AWS 65000. Aber wahrscheinlich erhalten Sie diese Informationen aus der heruntergeladenen Konfigurationsdatei.
- Peer-Router-ASN - Dies ist die Virtual Private Gateway-ASN die sich in der heruntergeladenen Konfigurationsdatei befindet.
- BGP-IP-Adresse des Cloud Routers – Dies ist das Kunden-Gateway in der heruntergeladenen Konfigurationsdatei gefunden.
- BGP-Peer-IP-Adresse – Dies ist das Virtual Private Gateway in der heruntergeladenen Konfigurationsdatei gefunden.
-
Werfen Sie einen Blick auf die Beispielkonfigurationsdatei, die ich unten habe:
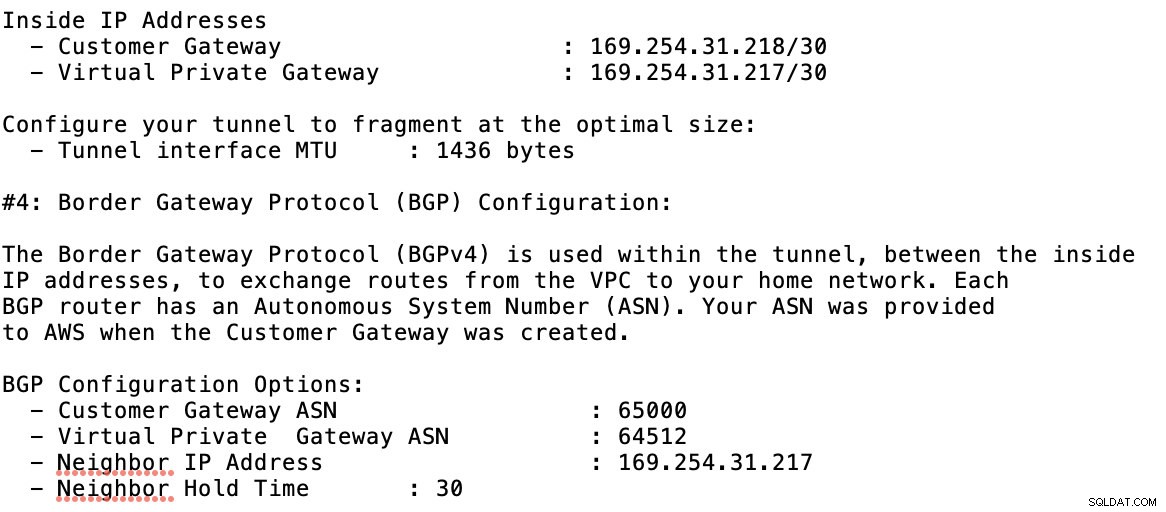
für die Sie dies beim Hinzufügen Ihres Tunnels unter GCP -> Hybrid Connectivity -> VPN anpassen müssen Verbindungsaufbau. Sehen Sie sich das Bild unten an, für das ich beim Erstellen eines Beispieltunnels einen Cloud-Router und eine BGP-Sitzung erstellt habe:
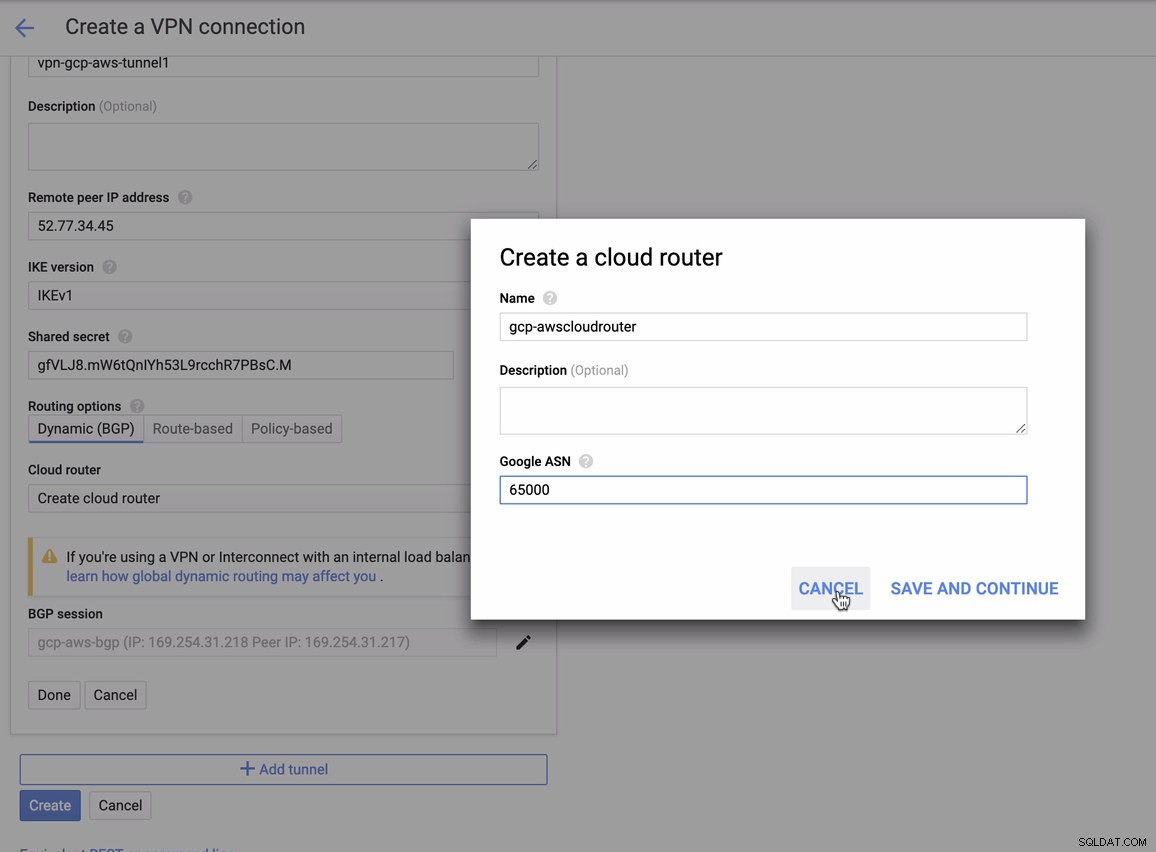
Dann BGP-Sitzung als,

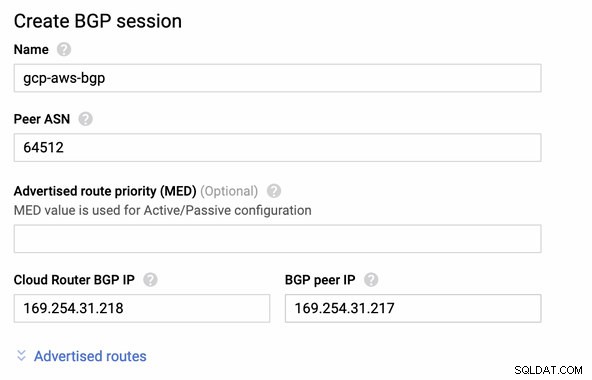
Hinweis: Die heruntergeladene Konfigurationsdatei enthält einen IPSec-Konfigurationstunnel, für den AWS ebenfalls zwei (2) VPN-Server enthält, die für Ihre Verbindung bereit sind. Sie müssen beide einrichten, damit Sie ein hochverfügbares Setup haben. Sobald beide Tunnel korrekt eingerichtet sind, zeigt die AWS-VPN-Verbindung auf der Registerkarte „Tunnel“ an, dass beide Outside IP Address sind oben. Siehe Bild unten:

-
Da wir ein Internet-Gateway und ein NAT-Gateway erstellt haben, füllen Sie schließlich die öffentlichen und privaten Subnetze korrekt mit dem korrekten Ziel aus und Ziel wie im Screenshot aus den vorherigen Schritten bemerkt. Dies kann eingerichtet werden, indem Sie zu Services -> Networking &Content Delivery -> VPC -> Routing Tables gehen und wählen Sie die in den vorherigen Schritten erwähnten erstellten Routentabellen aus. Siehe folgendes Bild:
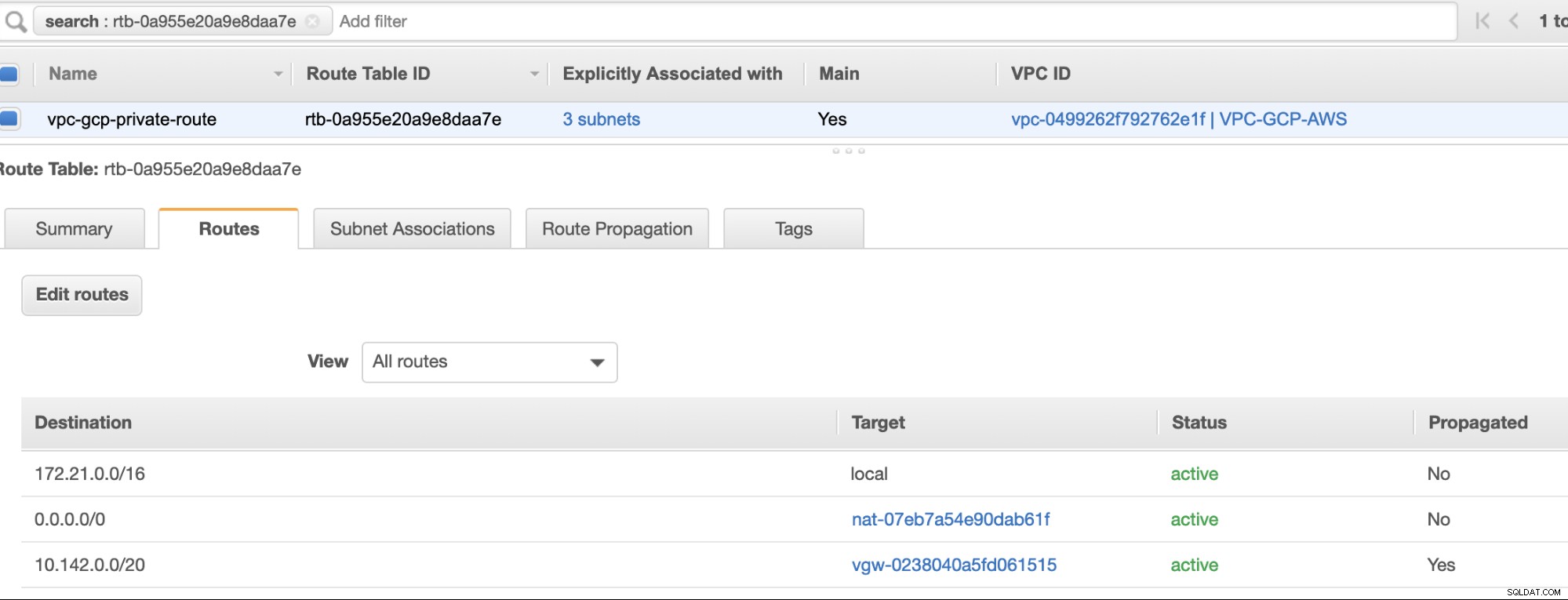
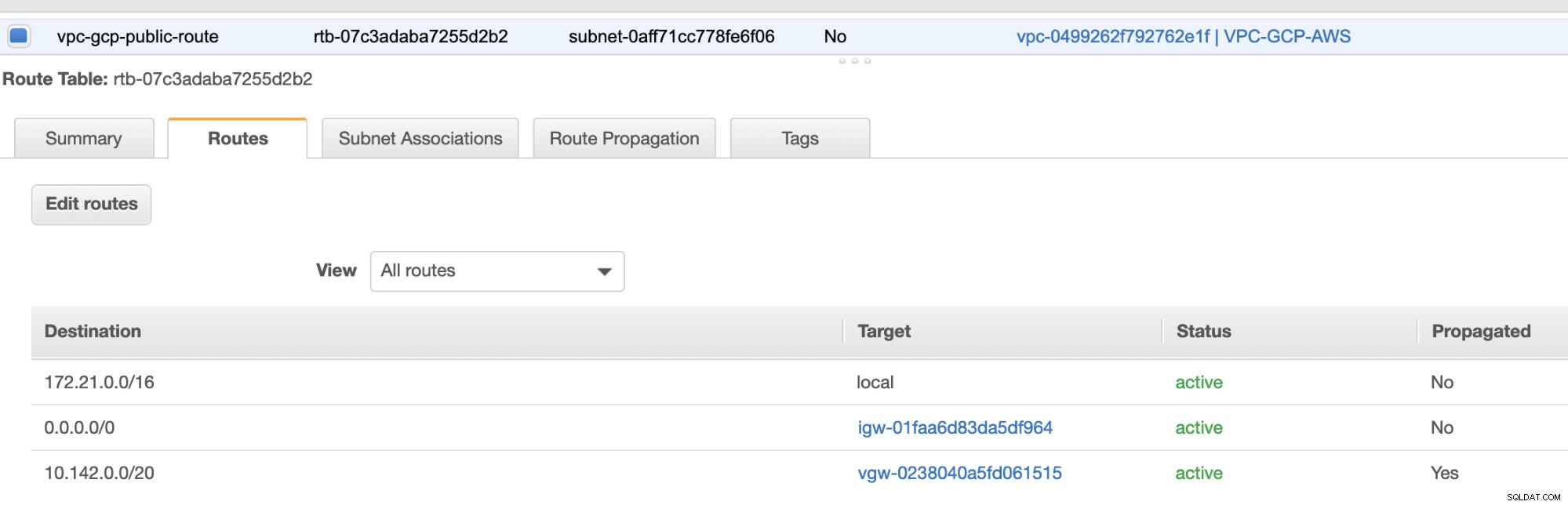
Wie Sie bemerkt haben, ist die igw-01faa6d83da5df964 ist das von uns erstellte Internet-Gateway und wird von der öffentlichen Route verwendet. In der privaten Routing-Tabelle sind Ziel und Ziel hingegen auf nat-07eb7a54e90dab61f festgelegt und beide haben Ziel auf 0.0.0.0/0 setzen, da es verschiedene IPv4-Verbindungen zulässt. Vergessen Sie auch nicht, die Route Propagation einzustellen richtig für das virtuelle Gateway, wie im Screenshot zu sehen, der ein Ziel vgw-0238040a5fd061515 hat . Klicken Sie einfach auf Route Propagation und setzen Sie es auf Yes, genau wie im Screenshot unten:
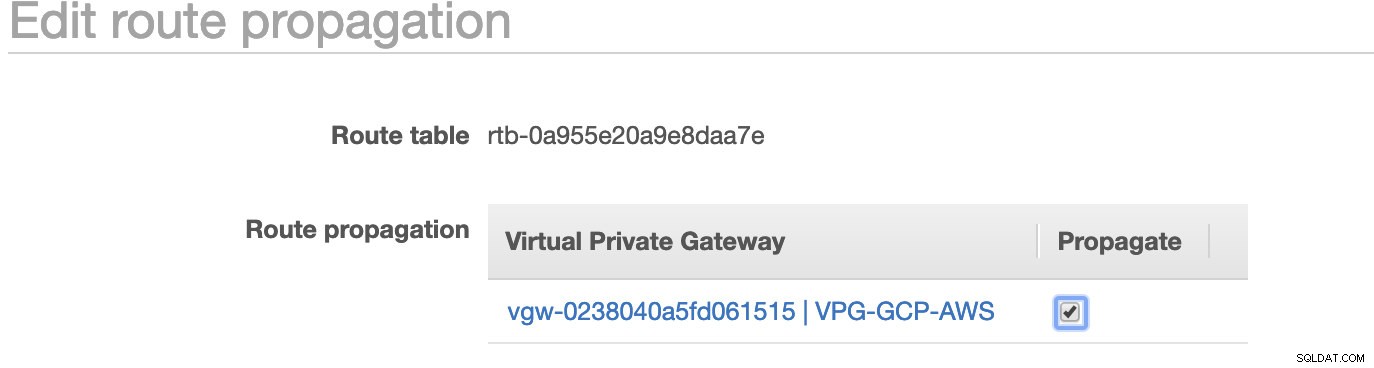
Dies ist sehr wichtig, damit die Verbindung von den externen GCP-Verbindungen zu den Routing-Tabellen in AWS weitergeleitet wird und keine weitere manuelle Arbeit erforderlich ist. Andernfalls kann Ihre GCP keine Verbindung zu AWS herstellen.
Nachdem unser VPN nun eingerichtet ist, werden wir mit der Einrichtung unserer privaten Knoten einschließlich des Bastion-Hosts fortfahren.
Einrichten der Compute Engine-Knoten
Die Einrichtung der Compute Engine/EC2-Knoten wird schnell und einfach sein, da wir alle Einrichtungen eingerichtet haben. Ich werde nicht auf diese Details eingehen, aber sehen Sie sich die Screenshots unten an, um die Einrichtung zu erklären.
AWS EC2-Knoten :

GCP-Rechenknoten :
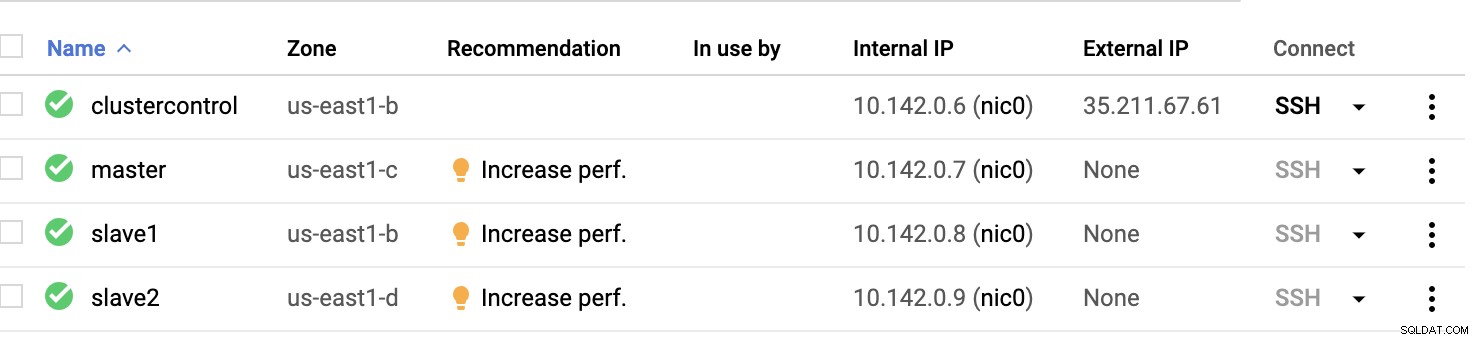
Grundsätzlich bei diesem Setup. Der Host clustercontrol der Bastion oder Jumphost sein und für den die ClusterControl installiert wird. Offensichtlich sind alle Knoten hier nicht über das Internet zugänglich. Ihnen ist kein externes IPv4 zugewiesen und die Knoten kommunizieren über einen sehr sicheren Kanal mit VPN.
Schließlich werden alle diese Knoten von AWS bis GCP mit einem einheitlichen Systembenutzer mit sudo-Zugriff eingerichtet, der in unserem nächsten Abschnitt benötigt wird. Sehen Sie, wie ClusterControl Ihnen das Leben in Multicloud und Multiregion erleichtern kann.
ClusterControl zur Rettung!!!
Der Umgang mit mehreren Knoten und auf verschiedenen öffentlichen Cloud-Plattformen sowie in einer anderen „Region“ kann eine „wirklich schmerzhafte und entmutigende“ Aufgabe sein. Wie überwacht man das effektiv? ClusterControl fungiert nicht nur als Ihr Schweizer Messer, sondern auch als Ihr virtueller DBA. Lassen Sie uns nun sehen, wie ClusterControl Ihr Leben einfacher machen kann.
Erstellen eines Mehrfachreplikationsclusters mit ClusterControl
Lassen Sie uns nun versuchen, einen MariaDB-Master-Slave-Replikationscluster nach der „Multiple Replication“-Topologie zu erstellen.
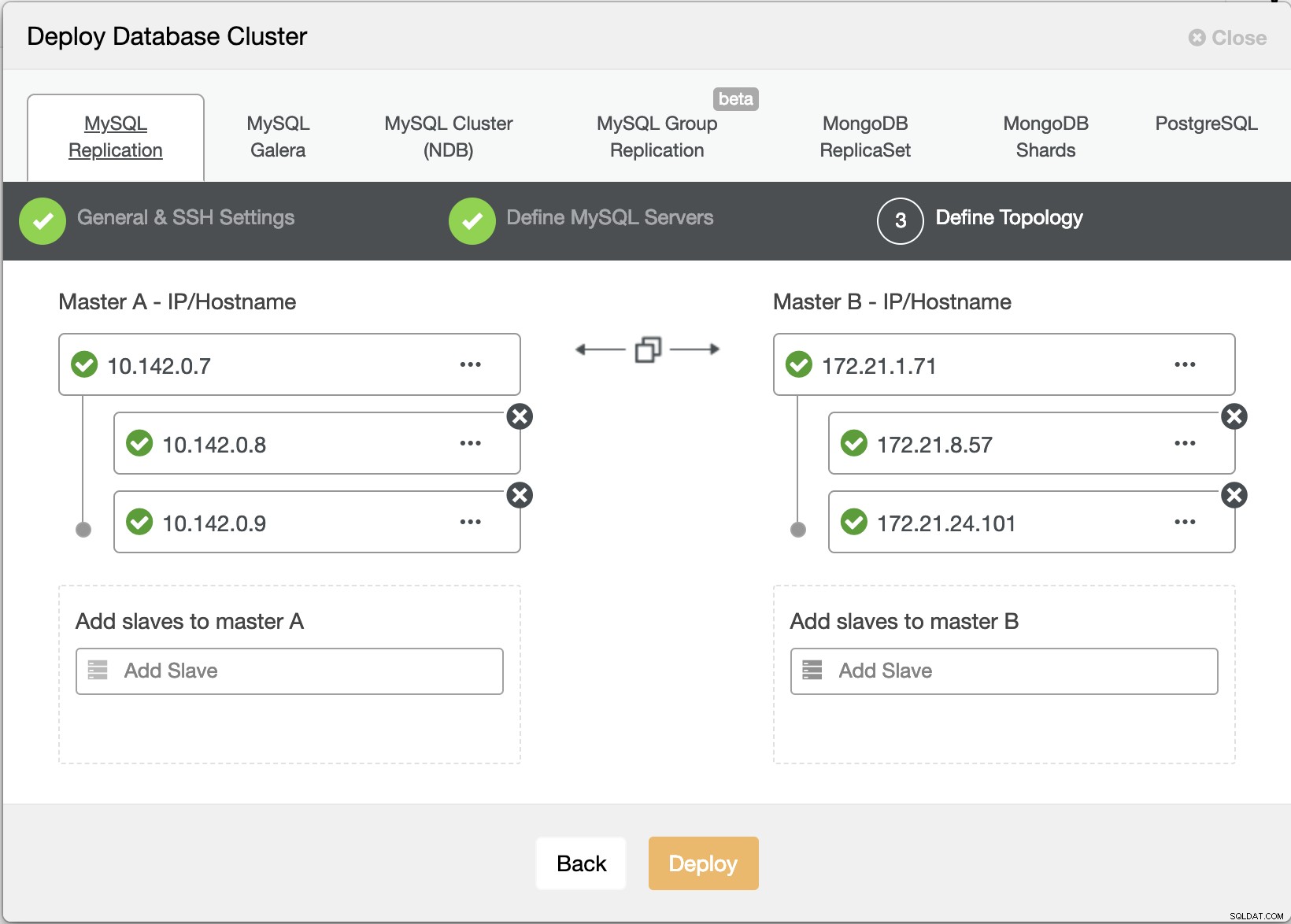 ClusterControl-Bereitstellungsassistent
ClusterControl-Bereitstellungsassistent Klicken Sie auf Bereitstellen Schaltfläche installiert Pakete und richtet die Knoten entsprechend ein. Daher eine logische Ansicht, wie die Topologie aussehen würde:
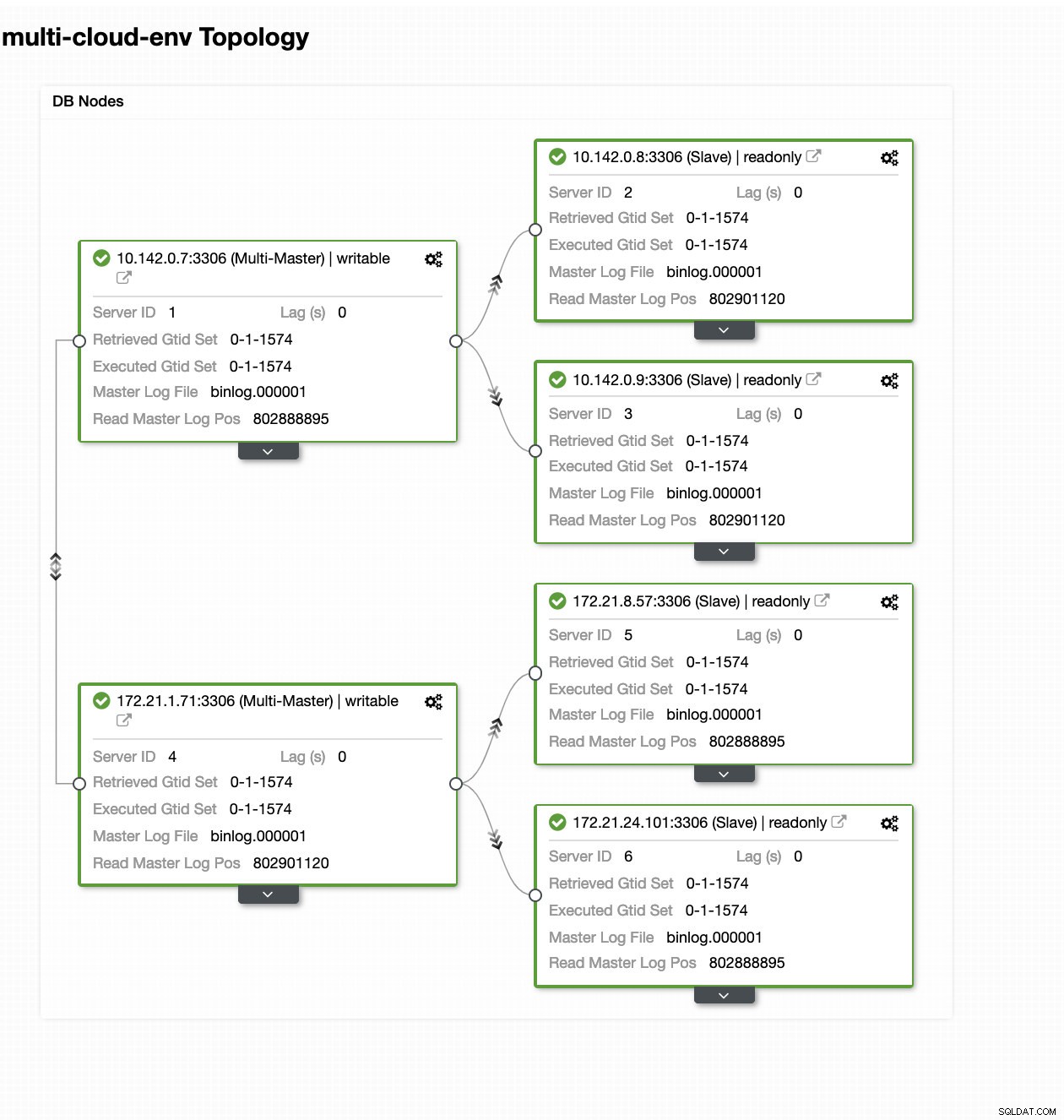 ClusterControl – Topologieansicht
ClusterControl – Topologieansicht Die IP-Bereiche der Knoten 172.21.0.0/16 werden von ihrem Master repliziert, der auf der GCP ausgeführt wird.
Nun, wie wäre es, wenn wir versuchen, ein paar Schreibvorgänge auf den Master zu laden? Alle Probleme mit Konnektivität oder Latenz können zu Slave-Lags führen, Sie können dies mit ClusterControl erkennen. Siehe Screenshot unten:
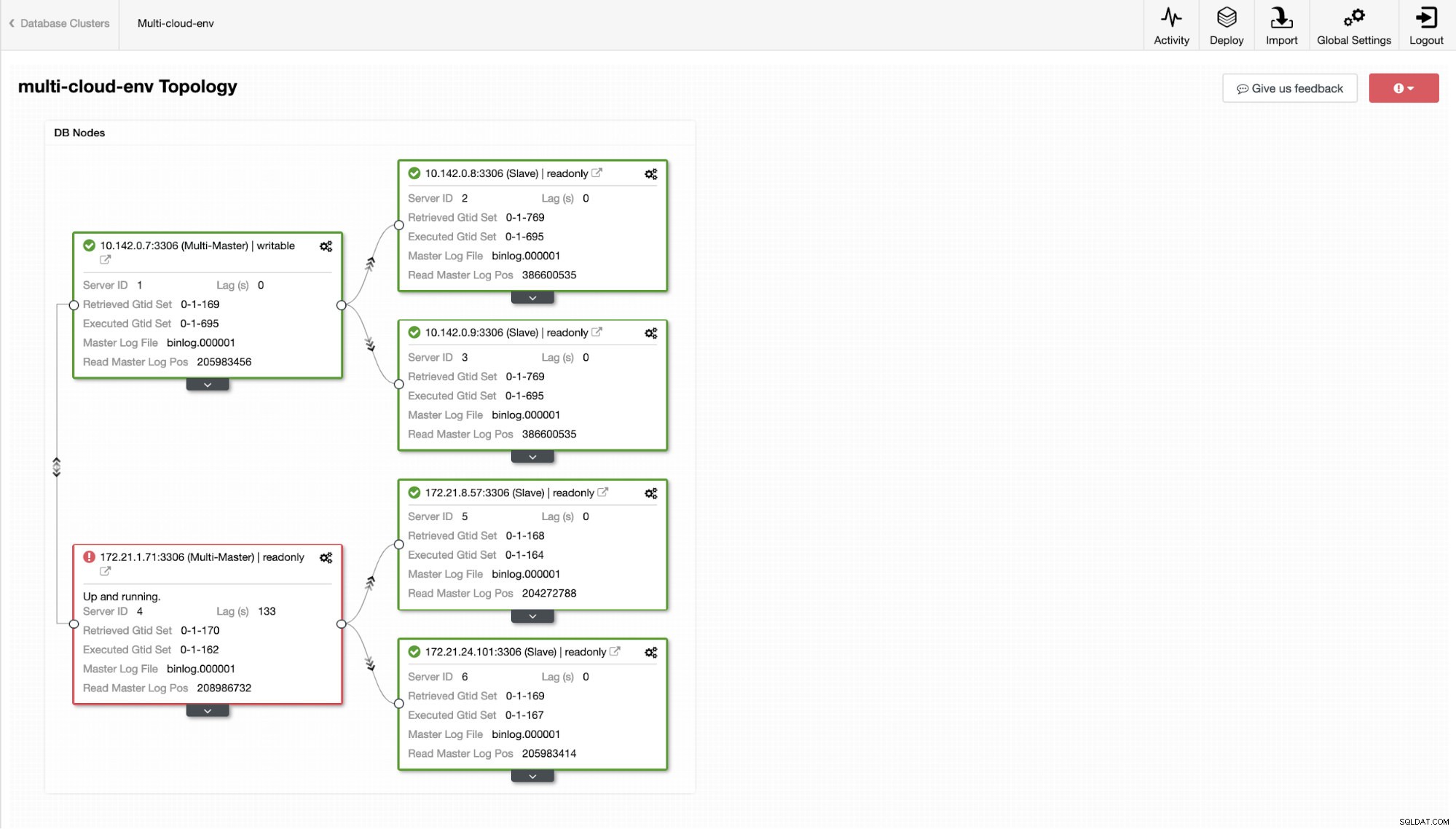
und wie Sie in der oberen rechten Ecke des Screenshots sehen, wird es rot, wenn es darauf hinweist, dass Probleme erkannt wurden. Daher wurde ein Alarm gesendet, während dieses Problem erkannt wurde. Siehe unten:
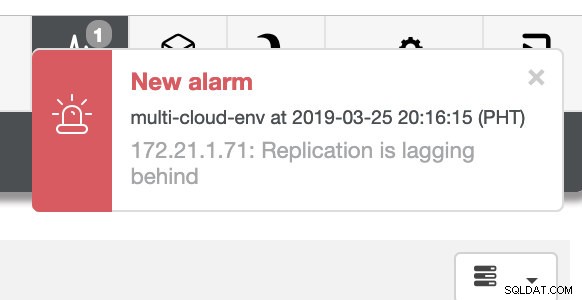
Dem müssen wir auf den Grund gehen. Für eine feinkörnige Überwachung haben wir Agenten auf den Datenbankinstanzen aktiviert. Werfen wir einen Blick auf das Dashboard.
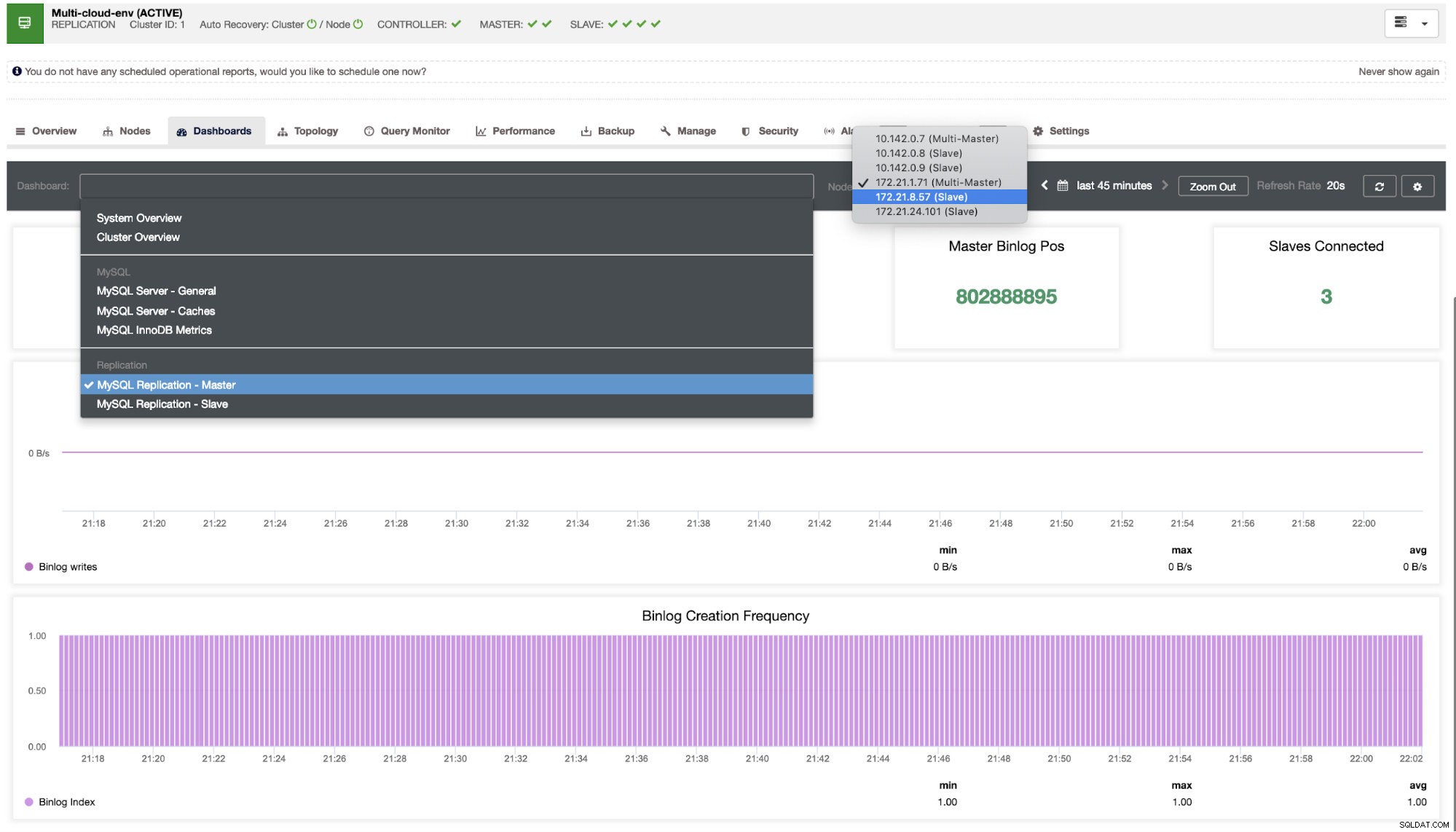
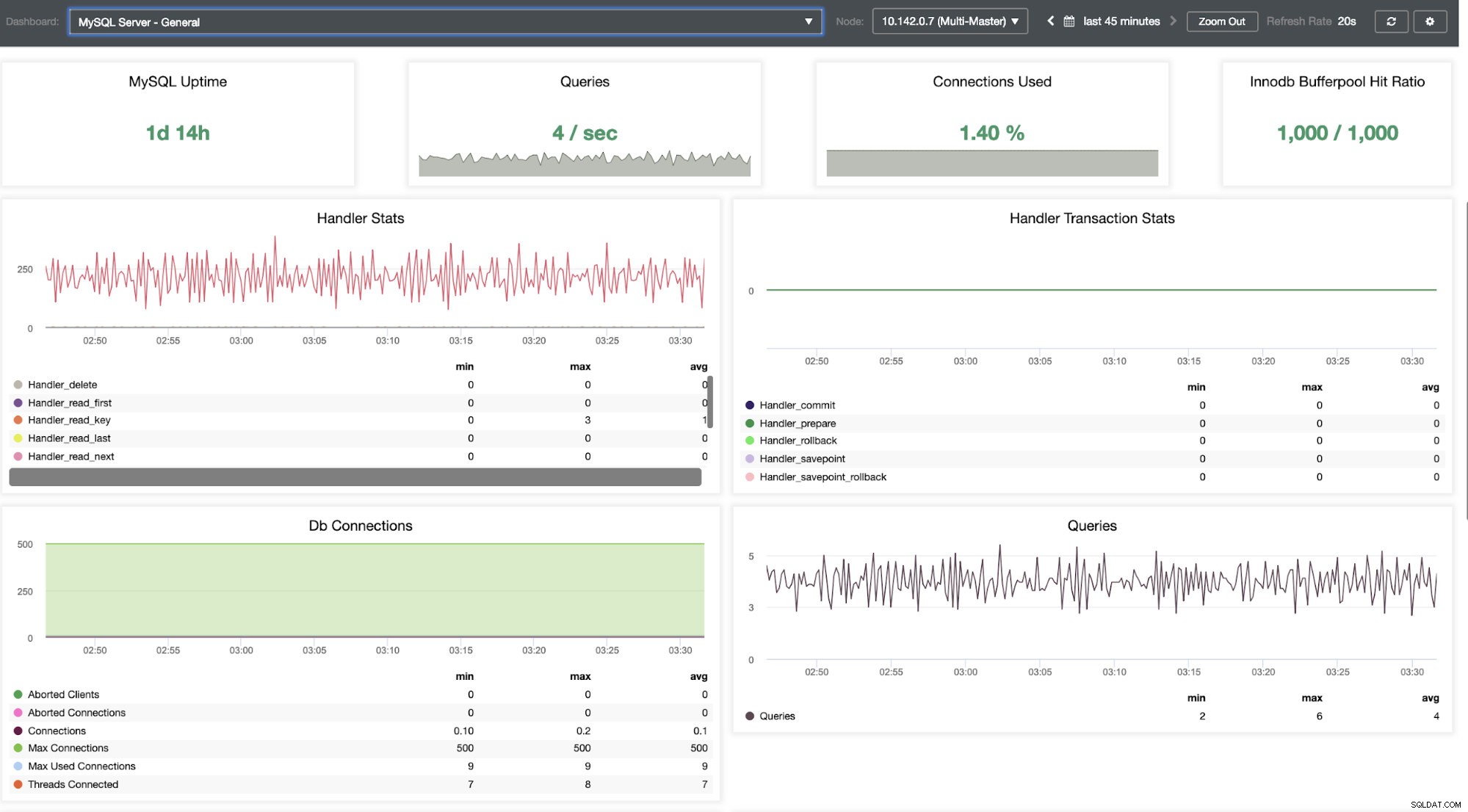
Es bietet eine super reibungslose Erfahrung in Bezug auf die Überwachung Ihrer Knoten.
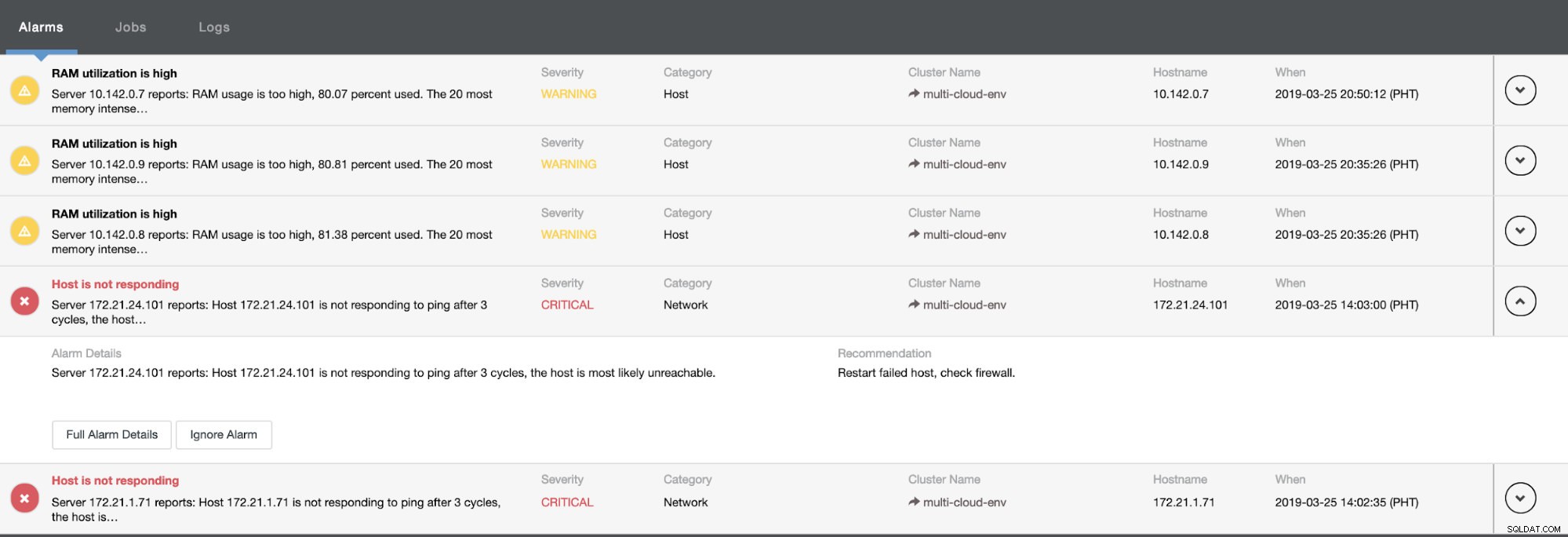
Es sagt uns, dass die Auslastung hoch ist oder der Host nicht antwortet. Obwohl dies nur ein Ping war Response Misserfolg, können Sie die Warnung ignorieren, um Sie davon abzuhalten, sie zu bombardieren. Daher können Sie die Ignorierung bei Bedarf aufheben, indem Sie in der Clustersteuerung zu Cluster -> Alarms gehen. Siehe unten:
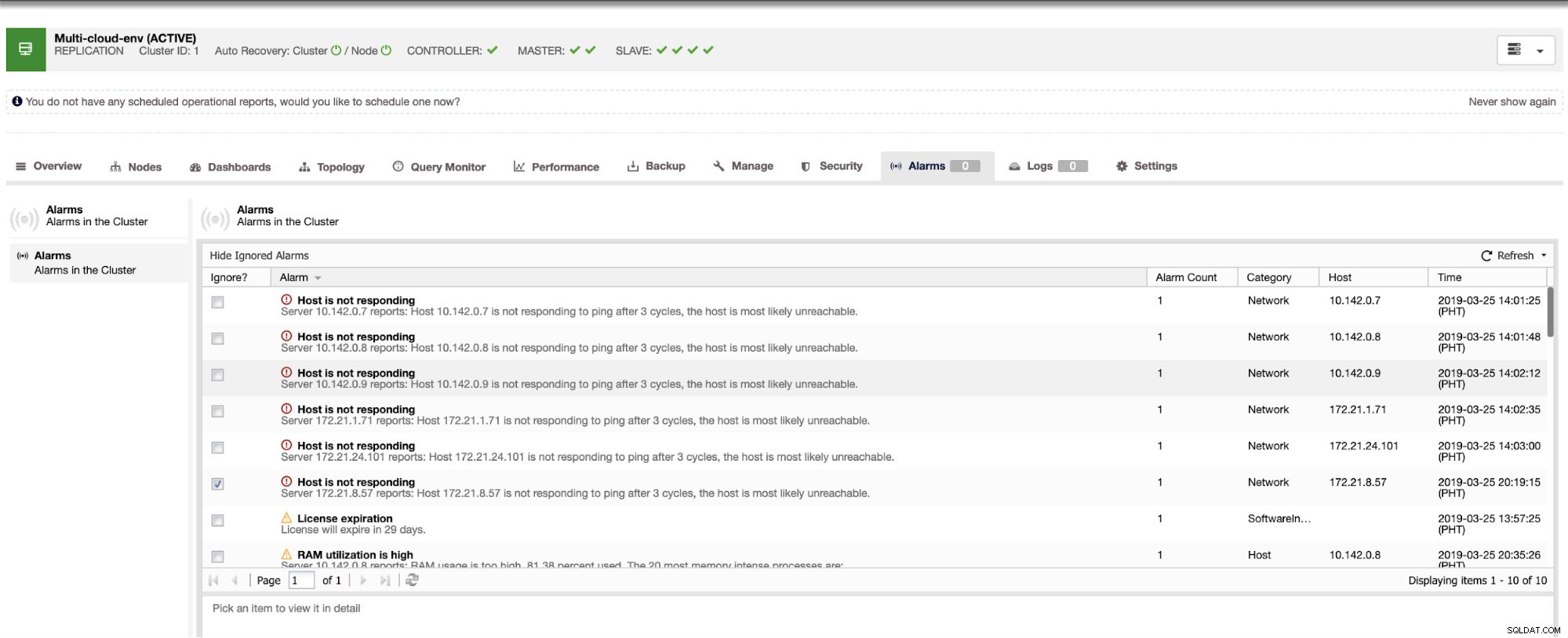
Ausfälle verwalten und Failover durchführen
Nehmen wir an, dass der Master-Knoten us-east1 ausgefallen ist oder aufgrund eines System- oder Hardware-Upgrades eine umfassende Überholung erfordert. Nehmen wir an, dies ist die aktuelle Topologie (siehe Bild unten):
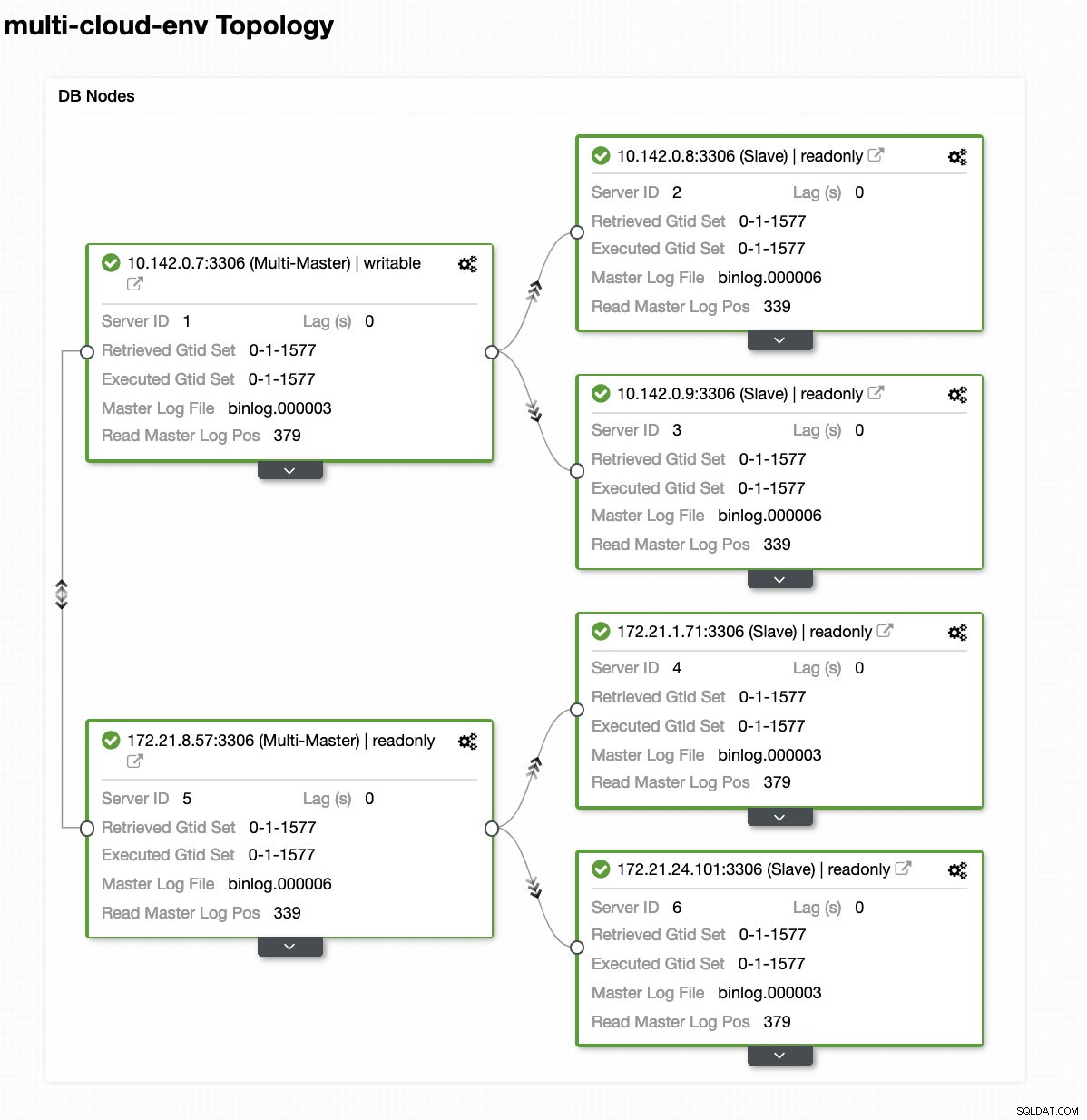
Lassen Sie uns versuchen, Host 10.142.0.7 herunterzufahren, der der Master unter der Region us-east1 ist. Sehen Sie sich die Screenshots unten an, wie ClusterControl darauf reagiert:
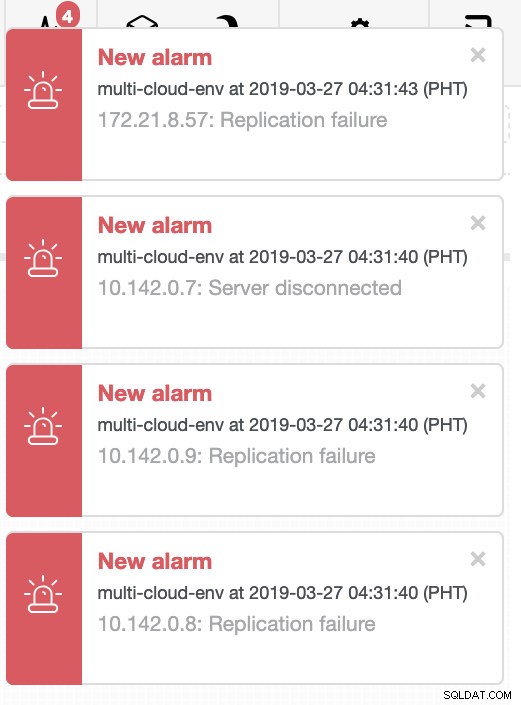
ClusterControl sendet Alarme, sobald es Anomalien im Cluster erkennt. Dann versucht es, ein Failover auf einen neuen Master durchzuführen, indem es den richtigen Kandidaten auswählt (siehe Abbildung unten):

Dann wird der ausgefallene Master, der bereits aus dem Cluster herausgenommen wurde, beiseite gelegt (siehe Abbildung unten):
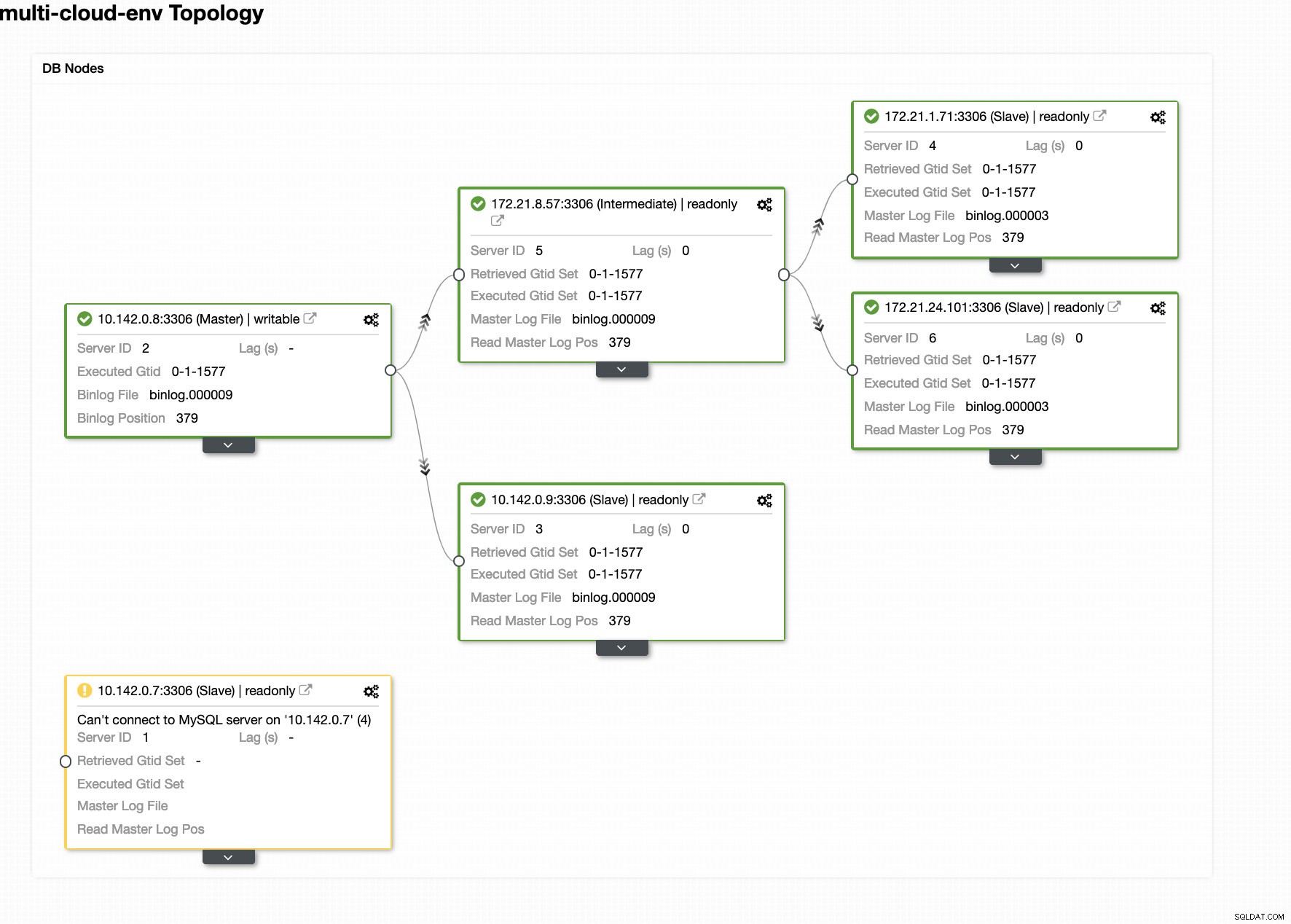
Dies ist nur ein kleiner Einblick in das, was ClusterControl leisten kann, es gibt noch weitere großartige Funktionen wie Backups, Abfrageüberwachung, Bereitstellung/Verwaltung von Load Balancern und vieles mehr!
Schlussfolgerung
Die Verwaltung Ihres MySQL-Replikations-Setups in einer Multicloud kann schwierig sein. Es muss viel Sorgfalt darauf verwendet werden, unser Setup zu sichern, also gibt dieser Blog hoffentlich eine Vorstellung davon, wie man Subnetze definiert und die Datenbankknoten schützt. Nach der Sicherheit gibt es eine Reihe von Dingen zu verwalten, und hier kann ClusterControl sehr hilfreich sein.
Probieren Sie es jetzt aus und lassen Sie uns wissen, wie es läuft. Sie können uns hier jederzeit kontaktieren.