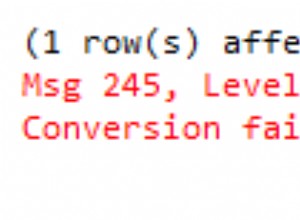
Lassen Sie uns einige interessante Daten mit verketteten Duplikaten zu verschiedenen Attributen haben:
CREATE TABLE data ( ID, A, B, C ) AS
SELECT 1, 1, 1, 1 FROM DUAL UNION ALL -- Related to #2 on column A
SELECT 2, 1, 2, 2 FROM DUAL UNION ALL -- Related to #1 on column A, #3 on B & C, #5 on C
SELECT 3, 2, 2, 2 FROM DUAL UNION ALL -- Related to #2 on columns B & C, #5 on C
SELECT 4, 3, 3, 3 FROM DUAL UNION ALL -- Related to #5 on column A
SELECT 5, 3, 4, 2 FROM DUAL UNION ALL -- Related to #2 and #3 on column C, #4 on A
SELECT 6, 5, 5, 5 FROM DUAL; -- Unrelated
Jetzt können wir mithilfe analytischer Funktionen (ohne Joins) einige Beziehungen erhalten:
SELECT d.*,
LEAST(
FIRST_VALUE( id ) OVER ( PARTITION BY a ORDER BY id ),
FIRST_VALUE( id ) OVER ( PARTITION BY b ORDER BY id ),
FIRST_VALUE( id ) OVER ( PARTITION BY c ORDER BY id )
) AS duplicate_of
FROM data d;
Was ergibt:
ID A B C DUPLICATE_OF
-- - - - ------------
1 1 1 1 1
2 1 2 2 1
3 2 2 2 2
4 3 3 3 4
5 3 4 2 2
6 5 5 5 6
Aber das greift nicht auf, dass #4 mit #5 verwandt ist, das mit #2 und dann mit #1 verwandt ist...
Dies kann mit einer hierarchischen Abfrage gefunden werden:
SELECT id, a, b, c,
CONNECT_BY_ROOT( id ) AS duplicate_of
FROM data
CONNECT BY NOCYCLE ( PRIOR a = a OR PRIOR b = b OR PRIOR c = c );
Aber das wird viele, viele doppelte Zeilen geben (da es nicht weiß, wo die Hierarchie beginnen soll, also wird jede Zeile der Reihe nach als Stamm gewählt) - stattdessen können Sie die erste Abfrage verwenden, um der hierarchischen Abfrage einen Ausgangspunkt zu geben, wenn die ID und DUPLICATE_OF Werte sind gleich:
SELECT id, a, b, c,
CONNECT_BY_ROOT( id ) AS duplicate_of
FROM (
SELECT d.*,
LEAST(
FIRST_VALUE( id ) OVER ( PARTITION BY a ORDER BY id ),
FIRST_VALUE( id ) OVER ( PARTITION BY b ORDER BY id ),
FIRST_VALUE( id ) OVER ( PARTITION BY c ORDER BY id )
) AS duplicate_of
FROM data d
)
START WITH id = duplicate_of
CONNECT BY NOCYCLE ( PRIOR a = a OR PRIOR b = b OR PRIOR c = c );
Was ergibt:
ID A B C DUPLICATE_OF
-- - - - ------------
1 1 1 1 1
2 1 2 2 1
3 2 2 2 1
4 3 3 3 1
5 3 4 2 1
1 1 1 1 4
2 1 2 2 4
3 2 2 2 4
4 3 3 3 4
5 3 4 2 4
6 5 5 5 6
Es werden immer noch einige Zeilen wegen der lokalen Minima in der Suche doppelt vorkommend ein #4 ... was mit einem einfachen GROUP BY entfernt werden kann :
SELECT id, a, b, c,
MIN( duplicate_of ) AS duplicate_of
FROM (
SELECT id, a, b, c,
CONNECT_BY_ROOT( id ) AS duplicate_of
FROM (
SELECT d.*,
LEAST(
FIRST_VALUE( id ) OVER ( PARTITION BY a ORDER BY id ),
FIRST_VALUE( id ) OVER ( PARTITION BY b ORDER BY id ),
FIRST_VALUE( id ) OVER ( PARTITION BY c ORDER BY id )
) AS duplicate_of
FROM data d
)
START WITH id = duplicate_of
CONNECT BY NOCYCLE ( PRIOR a = a OR PRIOR b = b OR PRIOR c = c )
)
GROUP BY id, a, b, c;
Was die Ausgabe ergibt:
ID A B C DUPLICATE_OF
-- - - - ------------
1 1 1 1 1
2 1 2 2 1
3 2 2 2 1
4 3 3 3 1
5 3 4 2 1
6 5 5 5 6