Im vorherigen Beitrag haben wir besprochen, wie Sie überprüfen können, ob die MySQL-Replikation in gutem Zustand ist. Wir haben uns auch einige der typischen Probleme angesehen. In diesem Beitrag werfen wir einen Blick auf einige weitere Probleme, die beim Umgang mit der MySQL-Replikation auftreten können.
Fehlende oder doppelte Einträge
Dies ist etwas, das nicht passieren sollte, aber es passiert sehr oft – eine Situation, in der eine auf dem Master ausgeführte SQL-Anweisung erfolgreich ist, aber die gleiche Anweisung, die auf einem der Slaves ausgeführt wird, fehlschlägt. Hauptgrund ist Slave-Drift – etwas (normalerweise fehlerhafte Transaktionen, aber auch andere Probleme oder Fehler in der Replikation) führt dazu, dass sich der Slave von seinem Master unterscheidet. Beispielsweise existiert eine Zeile, die auf dem Master existierte, nicht auf einem Slave und kann nicht gelöscht oder aktualisiert werden. Wie oft dieses Problem auftritt, hängt hauptsächlich von Ihren Replikationseinstellungen ab. Kurz gesagt, MySQL speichert binäre Log-Ereignisse auf drei Arten. Erstens bedeutet „Anweisung“, dass SQL im Klartext geschrieben wird, so wie es auf einem Master ausgeführt wurde. Diese Einstellung hat die höchste Toleranz gegenüber Slave-Drift, ist aber auch diejenige, die keine Slave-Konsistenz garantieren kann - es ist schwer zu empfehlen, sie in der Produktion zu verwenden. Das zweite Format, „Zeile“, speichert das Abfrageergebnis anstelle der Abfrageanweisung. Ein Ereignis kann beispielsweise wie folgt aussehen:
### UPDATE `test`.`tab`
### WHERE
### @1=2
### @2=5
### SET
### @1=2
### @2=4Das bedeutet, dass wir eine Zeile in der 'Tab'-Tabelle im 'Test'-Schema aktualisieren, wobei die erste Spalte einen Wert von 2 und die zweite Spalte einen Wert von 5 hat. Wir setzen die erste Spalte auf 2 (Wert ändert sich nicht) und die zweite Spalte bis 4. Wie Sie sehen, gibt es hier nicht viel Interpretationsspielraum - es ist genau definiert, welche Zeile verwendet und wie sie geändert wird. Infolgedessen ist dieses Format großartig für die Slave-Konsistenz, aber wie Sie sich vorstellen können, ist es sehr anfällig, wenn es um Datendrift geht. Dennoch ist es die empfohlene Art, die MySQL-Replikation auszuführen.
Schließlich funktioniert die dritte, „gemischt“, so, dass diejenigen Ereignisse, die sicher in Form von Anweisungen geschrieben werden können, das Format „Anweisung“ verwenden. Diejenigen, die Datendrift verursachen könnten, verwenden das „Zeilen“-Format.
Wie erkennt man sie?
Wie üblich hilft uns SHOW SLAVE STATUS dabei, das Problem zu identifizieren.
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000021, end_log_pos 970 Last_SQL_Errno: 1062
Last_SQL_Error: Could not execute Write_rows event on table test.tab; Duplicate entry '3' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log binlog.000021, end_log_pos 1229Wie Sie sehen können, sind Fehler klar und selbsterklärend (und sie sind im Grunde identisch zwischen MySQL und MariaDB.
Wie beheben Sie das Problem?
Das ist leider der komplexe Teil. Zunächst müssen Sie eine Quelle der Wahrheit identifizieren. Welcher Host enthält die richtigen Daten? Herr oder Sklave? Normalerweise würden Sie davon ausgehen, dass es der Master ist, aber nicht standardmäßig davon ausgehen - untersuchen Sie es! Es könnte sein, dass nach dem Failover ein Teil der Anwendung immer noch an den alten Master schreibt, der jetzt als Slave fungiert. Es könnte sein, dass read_only auf diesem Host nicht richtig eingestellt wurde oder dass die Anwendung Superuser verwendet, um eine Verbindung zur Datenbank herzustellen (ja, wir haben dies in Produktionsumgebungen gesehen). In einem solchen Fall könnte der Sklave die Quelle der Wahrheit sein - zumindest bis zu einem gewissen Grad.
Je nachdem, welche Daten bleiben und welche entfernt werden sollen, besteht die beste Vorgehensweise darin, zu ermitteln, was erforderlich ist, um die Replikation wieder synchron zu halten. Zunächst einmal ist die Replikation unterbrochen, also müssen Sie sich darum kümmern. Melden Sie sich beim Master an und überprüfen Sie das Binärlog, selbst wenn die Replikation unterbrochen wurde.
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106672
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106671Wie Sie sehen, fehlt uns ein Ereignis:5d1e2227-07c6-11e7-8123-080027495a77:1106672. Sehen wir es uns in den Binärlogs des Masters an:
mysqlbinlog -v --include-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1106672' /var/lib/mysql/binlog.000021
#170320 20:53:37 server id 1 end_log_pos 1066 CRC32 0xc582a367 GTID last_committed=3 sequence_number=4
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672'/*!*/;
# at 1066
#170320 20:53:37 server id 1 end_log_pos 1138 CRC32 0x6f33754d Query thread_id=5285 exec_time=0 error_code=0
SET TIMESTAMP=1490043217/*!*/;
SET @@session.pseudo_thread_id=5285/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
BEGIN
/*!*/;
# at 1138
#170320 20:53:37 server id 1 end_log_pos 1185 CRC32 0xa00b1f59 Table_map: `test`.`tab` mapped to number 571
# at 1185
#170320 20:53:37 server id 1 end_log_pos 1229 CRC32 0x5597e50a Write_rows: table id 571 flags: STMT_END_F
BINLOG '
UUHQWBMBAAAALwAAAKEEAAAAADsCAAAAAAEABHRlc3QAA3RhYgACAwMAAlkfC6A=
UUHQWB4BAAAALAAAAM0EAAAAADsCAAAAAAEAAgAC//wDAAAABwAAAArll1U=
'/*!*/;
### INSERT INTO `test`.`tab`
### SET
### @1=3
### @2=7
# at 1229
#170320 20:53:37 server id 1 end_log_pos 1260 CRC32 0xbbc3367c Xid = 5224257
COMMIT/*!*/;Wir können sehen, dass es eine Einfügung war, die die erste Spalte auf 3 und die zweite auf 7 setzt. Lassen Sie uns überprüfen, wie unsere Tabelle jetzt aussieht:
mysql> SELECT * FROM test.tab;
+----+------+
| id | b |
+----+------+
| 1 | 2 |
| 2 | 4 |
| 3 | 10 |
+----+------+
3 rows in set (0.01 sec)Nun haben wir zwei Möglichkeiten, je nachdem welche Daten sich durchsetzen sollen. Wenn auf dem Master die richtigen Daten vorhanden sind, können wir auf dem Slave einfach die Zeile mit der ID=3 löschen. Stellen Sie nur sicher, dass Sie die binäre Protokollierung deaktivieren, um fehlerhafte Transaktionen zu vermeiden. Wenn wir andererseits entschieden haben, dass sich die richtigen Daten auf dem Slave befinden, müssen wir den REPLACE-Befehl auf dem Master ausführen, um die Zeile mit id =3 auf den korrekten Inhalt von (3, 10) aus dem aktuellen (3, 7) zu setzen. Auf dem Slave müssen wir jedoch die aktuelle GTID überspringen (oder genauer gesagt, wir müssen ein leeres GTID-Ereignis erstellen), um die Replikation neu starten zu können.
Das Löschen einer Zeile auf einem Slave ist einfach:
SET SESSION log_bin=0; DELETE FROM test.tab WHERE id=3; SET SESSION log_bin=1;Das Einfügen einer leeren GTID ist fast genauso einfach:
mysql> SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672';
Query OK, 0 rows affected (0.00 sec)mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)mysql> COMMIT;
Query OK, 0 rows affected (0.00 sec)mysql> SET @@SESSION.GTID_NEXT=automatic;
Query OK, 0 rows affected (0.00 sec)Eine andere Methode zur Lösung dieses speziellen Problems (solange wir den Master als Quelle der Wahrheit akzeptieren) besteht darin, Tools wie pt-table-checksum und pt-table-sync zu verwenden, um festzustellen, wo der Slave nicht mit seinem Master übereinstimmt und was SQL muss auf dem Master ausgeführt werden, um den Slave wieder synchron zu machen. Leider ist diese Methode eher schwerfällig – dem Master wird eine Menge Last hinzugefügt, und eine Reihe von Abfragen werden in den Replikationsstrom geschrieben, was sich auf die Verzögerung der Slaves und die allgemeine Leistung des Replikations-Setups auswirken kann. Dies gilt insbesondere, wenn eine beträchtliche Anzahl von Zeilen synchronisiert werden muss.
Schließlich können Sie Ihren Slave wie immer mit den Daten des Masters neu aufbauen - auf diese Weise können Sie sicher sein, dass der Slave mit den frischesten, aktuellsten Daten aktualisiert wird. Dies ist eigentlich nicht unbedingt eine schlechte Idee - wenn wir über eine große Anzahl von Zeilen sprechen, die mit pt-table-checksum/pt-table-sync synchronisiert werden sollen, ist dies mit einem erheblichen Mehraufwand bei der Replikationsleistung, der Gesamt-CPU und den E/A-Vorgängen verbunden Last und Arbeitsstunden erforderlich.
ClusterControl ermöglicht es Ihnen, einen Slave neu zu erstellen, indem Sie eine frische Kopie der Stammdaten verwenden.
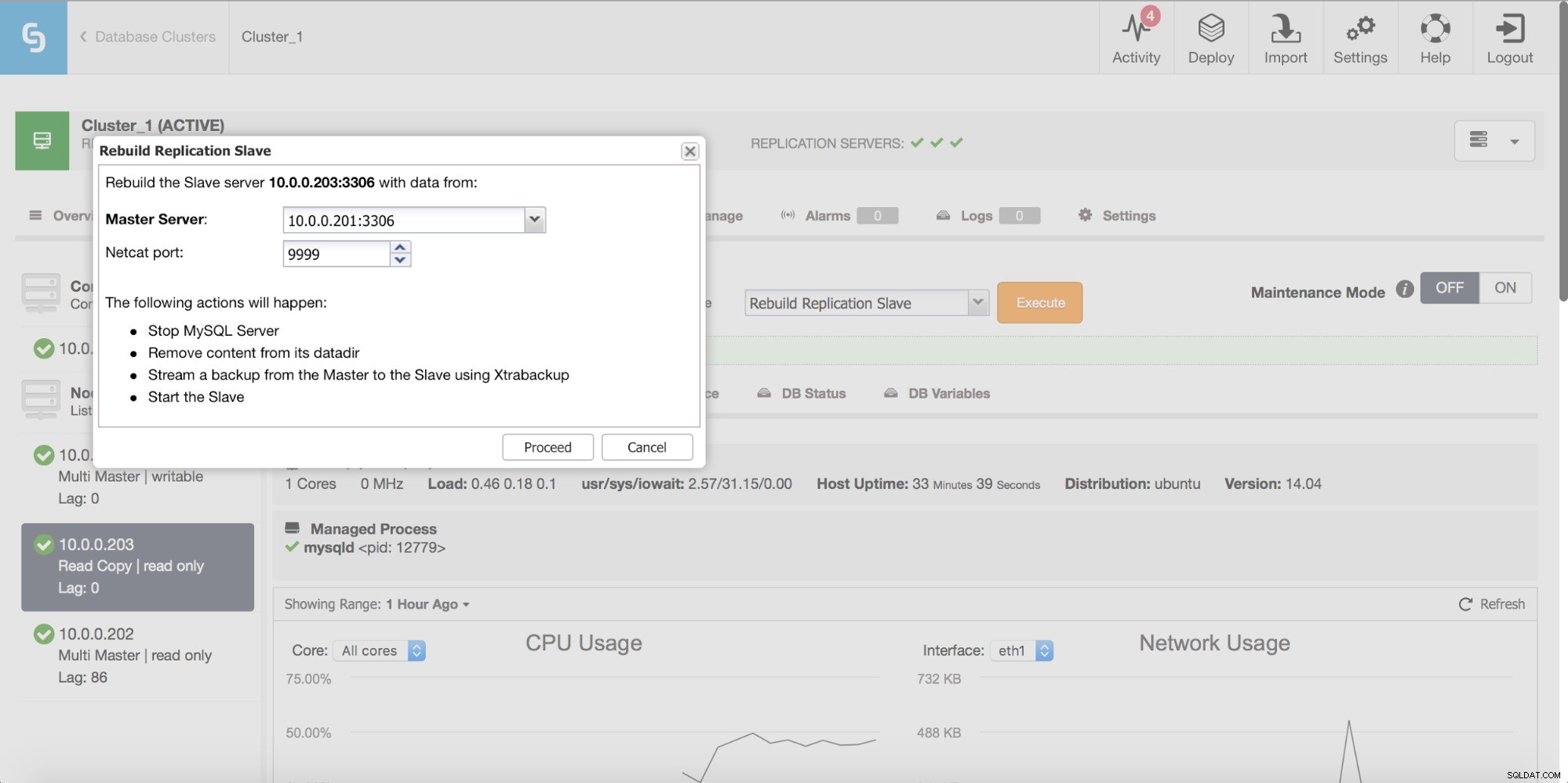
Konsistenzprüfungen
Wie wir im vorigen Kapitel erwähnt haben, kann Konsistenz zu einem ernsthaften Problem werden und Benutzern, die MySQL-Replikations-Setups ausführen, viele Kopfschmerzen bereiten. Sehen wir uns an, wie Sie überprüfen können, ob Ihre MySQL-Slaves mit dem Master synchronisiert sind, und was Sie dagegen tun können.
So erkennen Sie einen inkonsistenten Slave
Unglücklicherweise erfährt ein Benutzer normalerweise, dass ein Slave inkonsistent ist, indem er auf eines der Probleme stößt, die wir im vorherigen Kapitel erwähnt haben. Um zu vermeiden, dass eine proaktive Überwachung der Slave-Konsistenz erforderlich ist. Lassen Sie uns prüfen, wie es gemacht werden kann.
Wir werden ein Tool von Percona Toolkit verwenden:pt-table-checksum. Es wurde entwickelt, um Replikationscluster zu scannen und Diskrepanzen zu identifizieren.
Wir haben mit sysbench ein benutzerdefiniertes Szenario erstellt und bei einem der Slaves eine kleine Inkonsistenz eingeführt. Was wichtig ist (wenn Sie es wie wir testen möchten), müssen Sie einen Patch unten anwenden, um pt-table-checksum zu zwingen, das Schema „sbtest“ als Nicht-Systemschema zu erkennen:
--- pt-table-checksum 2016-12-15 14:31:07.000000000 +0000
+++ pt-table-checksum-fix 2017-03-21 20:32:53.282254794 +0000
@@ -7614,7 +7614,7 @@
my $filter = $self->{filters};
- if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|test/ ) {
+ if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|^test/ ) {
PTDEBUG && _d('Database', $db, 'is a system database, ignoring');
return 0;
}Zuerst werden wir pt-table-checksum auf folgende Weise ausführen:
master:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T20:33:30 0 0 1000000 15 0 27.103 sbtest.sbtest1
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2
03-21T20:34:26 0 0 1000000 15 0 28.503 sbtest.sbtest3
03-21T20:34:52 0 0 1000000 18 0 26.021 sbtest.sbtest4
03-21T20:35:34 0 0 1000000 17 0 42.730 sbtest.sbtest5
03-21T20:36:04 0 0 1000000 16 0 29.309 sbtest.sbtest6
03-21T20:36:42 0 0 1000000 15 0 38.071 sbtest.sbtest7
03-21T20:37:16 0 0 1000000 12 0 33.737 sbtest.sbtest8Einige wichtige Hinweise dazu, wie wir das Tool aufgerufen haben. Zunächst einmal muss der von uns festgelegte Benutzer auf allen Slaves vorhanden sein. Wenn Sie möchten, können Sie auch „--slave-user“ verwenden, um andere, weniger privilegierte Benutzer für den Zugriff auf Slaves zu definieren. Eine weitere Sache, die es wert ist, erklärt zu werden - wir verwenden eine zeilenbasierte Replikation, die nicht vollständig mit pt-table-checksum kompatibel ist. Wenn Sie über eine zeilenbasierte Replikation verfügen, ändert pt-table-checksum das Binärprotokollformat auf Sitzungsebene in „Anweisung“, da dies das einzige unterstützte Format ist. Das Problem besteht darin, dass eine solche Änderung nur auf einer ersten Ebene von Slaves funktioniert, die direkt mit einem Master verbunden sind. Wenn Sie Zwischenmaster haben (also mehr als eine Ebene von Slaves), kann die Verwendung von pt-table-checksum die Replikation unterbrechen. Aus diesem Grund wird das Tool standardmäßig beendet, wenn es eine zeilenbasierte Replikation erkennt, und einen Fehler ausgeben:
„Replica slave1 hat binlog_format ROW, was dazu führen könnte, dass pt-table-checksum die Replikation unterbricht. Bitte lesen Sie „Replikate mit zeilenbasierter Replikation“ im Abschnitt EINSCHRÄNKUNGEN der Dokumentation des Tools. Wenn Sie die Risiken verstehen, geben Sie --no-check-binlog-format an, um diese Prüfung zu deaktivieren.“
Wir haben nur eine Ebene von Slaves verwendet, daher war es sicher, „--no-check-binlog-format“ anzugeben und fortzufahren.
Schließlich setzen wir die maximale Verzögerung auf 5 Sekunden. Wenn dieser Schwellenwert erreicht wird, pausiert pt-table-checksum für die Zeit, die erforderlich ist, um die Verzögerung unter den Schwellenwert zu bringen.
Wie Sie der Ausgabe entnehmen konnten,
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2In Tabelle sbtest.sbtest2 wurde eine Inkonsistenz festgestellt.
Standardmäßig speichert pt-table-checksum Prüfsummen in der Tabelle percona.checksums. Diese Daten können für ein anderes Tool aus dem Percona Toolkit, pt-table-sync, verwendet werden, um zu identifizieren, welche Teile der Tabelle im Detail überprüft werden sollten, um genaue Unterschiede in den Daten zu finden.
So beheben Sie einen inkonsistenten Slave
Wie oben erwähnt, verwenden wir dazu pt-table-sync. In unserem Fall verwenden wir die von pt-table-checksum gesammelten Daten, obwohl es auch möglich ist, pt-table-sync auf zwei Hosts (den Master und einen Slave) zu verweisen und alle Daten auf beiden Hosts zu vergleichen. Es ist definitiv ein zeit- und ressourcenintensiverer Prozess, daher ist es viel besser, es zu verwenden, solange Sie bereits Daten von pt-table-checksum haben. So haben wir es ausgeführt, um die Ausgabe zu testen:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=master --printREPLACE INTO `sbtest`.`sbtest2`(`id`, `k`, `c`, `pad`) VALUES ('1', '434041', '61753673565-14739672440-12887544709-74227036147-86382758284-62912436480-22536544941-50641666437-36404946534-73544093889', '23608763234-05826685838-82708573685-48410807053-00139962956') /*percona-toolkit src_db:sbtest src_tbl:sbtest2 src_dsn:h=10.0.0.101,p=...,u=sbtest dst_db:sbtest dst_tbl:sbtest2 dst_dsn:h=10.0.0.103,p=...,u=sbtest lock:1 transaction:1 changing_src:percona.checksums replicate:percona.checksums bidirectional:0 pid:25776 user:root host:vagrant-ubuntu-trusty-64*/;Wie Sie sehen können, wurde als Ergebnis etwas SQL generiert. Wichtig zu beachten ist die Variable --replicate. Was hier passiert, ist, dass wir pt-table-sync auf eine von pt-table-checksum generierte Tabelle verweisen. Wir zeigen es auch auf master.
Um zu überprüfen, ob SQL sinnvoll ist, haben wir die Option --print verwendet. Bitte beachten Sie, dass das generierte SQL nur zum Zeitpunkt seiner Generierung gültig ist – Sie können es nicht wirklich irgendwo speichern, überprüfen und dann ausführen. Alles, was Sie tun können, ist zu überprüfen, ob die SQL sinnvoll ist, und das Tool sofort danach mit dem --execute-Flag erneut auszuführen:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=10.0.0.101 --executeDies sollte den Slave wieder mit dem Master synchronisieren. Wir können es mit pt-table-checksum überprüfen:
example@sqldat.com:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T21:36:04 0 0 1000000 13 0 23.749 sbtest.sbtest1
03-21T21:36:26 0 0 1000000 7 0 22.333 sbtest.sbtest2
03-21T21:36:51 0 0 1000000 10 0 24.780 sbtest.sbtest3
03-21T21:37:11 0 0 1000000 14 0 19.782 sbtest.sbtest4
03-21T21:37:42 0 0 1000000 15 0 30.954 sbtest.sbtest5
03-21T21:38:07 0 0 1000000 15 0 25.593 sbtest.sbtest6
03-21T21:38:27 0 0 1000000 16 0 19.339 sbtest.sbtest7
03-21T21:38:44 0 0 1000000 15 0 17.371 sbtest.sbtest8Wie Sie sehen können, gibt es in der Tabelle sbtest.sbtest2 keine Unterschiede mehr.
Wir hoffen, Sie fanden diesen Blogbeitrag informativ und nützlich. Klicken Sie hier, um mehr über die MySQL-Replikation zu erfahren. Wenn Sie Fragen oder Anregungen haben, können Sie uns gerne über die folgenden Kommentare erreichen.