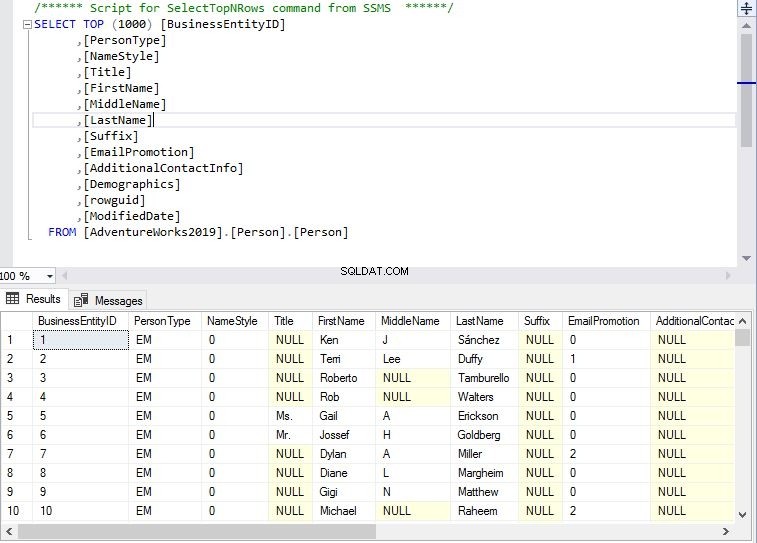
Durch die Verwendung von instr
.
select substr(help, 1, instr(help,' ') - 1)
from ( select 'hello my name is...' as help
from dual )
instr(help,' ') gibt den Positionsindex des ersten Vorkommens des zweiten Arguments im ersten zurück, einschließlich der Zeichenfolge, nach der Sie suchen. d.h. das erste Vorkommen von ' ' in der Zeichenfolge 'Hallo, mein Name ist...' plus das Leerzeichen.
substr(help, 1, instr(help,' ') - 1) nimmt dann die Eingabezeichenfolge vom ersten Zeichen bis zum Index, der in instr(... angegeben ist . Ich entferne dann eines, damit das Leerzeichen nicht enthalten ist..
Für das n-te Vorkommen ändern Sie dies einfach leicht:
instr(help,' ',1,n) ist die nte Vorkommen von ' ' ab dem ersten Zeichen. Sie müssen dann den Positionsindex des nächsten Index instr(help,' ',1,n + 1) finden , ermitteln Sie schließlich den Unterschied zwischen ihnen, damit Sie wissen, wie weit Sie in Ihrem substr(... gehen müssen . Da Sie nach dem n. suchen , wenn n ist 1, bricht dies zusammen und Sie müssen damit umgehen, wie folgt:
select substr( help
, decode( n
, 1, 1
, instr(help, ' ', 1, n - 1) + 1
)
, decode( &1
, 1, instr(help, ' ', 1, n ) - 1
, instr(help, ' ', 1, n) - instr(help, ' ', 1, n - 1) - 1
)
)
from ( select 'hello my name is...' as help
from dual )
Dies wird auch bei n zusammenbrechen . Wie Sie sehen können, wird das langsam lächerlich, also sollten Sie die Verwendung von regulären Ausdrücken
select regexp_substr(help, '[^[:space:]]+', 1, n )
from ( select 'hello my name is...' as help
from dual )