Dies ist der vierte und letzte Teil der Reihe Benchmarking Managed PostgreSQLCloud Solutions . Zum Zeitpunkt des Verfassens dieses Artikels war Microsoft Azure PostgreSQL in Version 10.7, also neuer als die beiden Konkurrenten:Amazon Aurora PostgreSQL in Version 10.6 und Google Cloud SQL für PostgreSQL in Version 9.6.
Microsoft hat sich entschieden, Azure PostgreSQL unter Windows auszuführen:
postgres=> select version();
version
------------------------------------------------------------
PostgreSQL 10.7, compiled by Visual C++ build 1800, 64-bit
(1 row)Für diesen speziellen Test hat das nicht so gut geklappt, und ich wage zu vermuten, dass Microsoft sich der Einschränkungen bewusst ist, der Grund, warum sie unter dem Dach von PostgreSQL auch eine Vorschauversion der Citus Data-Version von PostgreSQL anbieten. Der Ansatz sieht ähnlich aus wie AWS PostgreSQL Flavors, RDS bzw. Aurora.
Als Nebenbemerkung war ich beim Einrichten meines Azure-Kontos überrascht über das Fehlen einer 2FA/MFA-Authentifizierung (Zwei-Faktor-/Mehrfaktor-Authentifizierung), die ich mit AWS Virtual MFA von Amazon und Googles 2-Stufen-Verifizierung als selbstverständlich ansah. Microsoft bietet MFA nur für Unternehmenskunden an, die Active Directory oder Office 365 abonniert haben. Da Citus Cloud 2FA für Produktionsdatenbanken erzwingt, ist Microsoft vielleicht nicht weit davon entfernt, es in Azure zu implementieren.
TL;DR
Es gibt keine Ergebnisse für Azure. Auf der 8-Kern-Datenbankinstanz, die in der Anzahl der Kerne mit denen von AWS und G Cloud identisch ist, konnten die Tests aufgrund von Datenbankfehlern nicht abgeschlossen werden. Auf einer Instanz mit 16 Kernen wurde pgbench abgeschlossen, und sysbench kam so weit, die ersten 3 Tabellen zu erstellen, an welcher Stelle ich den Prozess unterbrach. Obwohl ich bereit war, eine angemessene Menge an Aufwand, Zeit und Geld für die Durchführung der Tests und die Dokumentation der Fehler und ihrer Ursachen aufzuwenden, war das Ziel dieser Übung das Ausführen des Benchmarks, daher habe ich nie daran gedacht, eine erweiterte Fehlerbehebung zu verfolgen oder Kontakt aufzunehmen Azure-Unterstützung, noch habe ich den Sysbench-Test auf der 16-Core-Datenbank beendet.
Cloud-Instanzen
Kunde
Die Azure-Clientinstanz, die der zu Beginn dieser Blogserie ausgewählten AWS-Instanz am nächsten kam, war eine E32s v3-Instanz mit den folgenden Spezifikationen:
- vCPU:32 (16 Kerne x 2 Threads/Kern)
- RAM:256 GiB
- Speicher:Azure Premium SSD
- Netzwerk:Beschleunigtes Netzwerk bis zu 30 Gbit/s
Hier ist ein Screenshot des Portals mit den Instanzdetails:
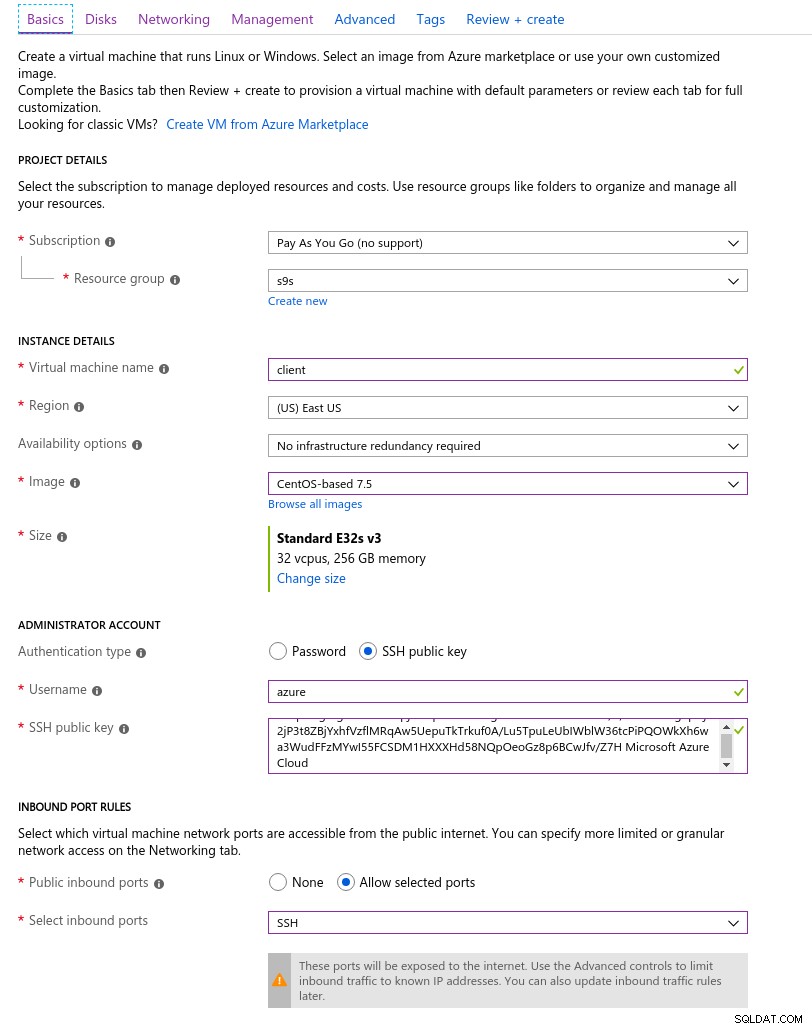 Details der Clientinstanz
Details der Clientinstanz Accelerated Networking ist standardmäßig aktiviert, wenn Sie eine der unterstützten virtuellen Maschinen auswählen:
 Beschleunigter Netzwerkbetrieb Ein
Beschleunigter Netzwerkbetrieb Ein Wie es in der Cloud die Regel ist, müssen sich der Client und der Server in derselben Verfügbarkeitszone befinden, um die beste Netzwerkleistung zu erzielen, was ich getan habe, indem ich die Umgebung im Osten der USA von AZ eingerichtet habe.
Ähnlich wie bei Google Cloud muss für Instanzen mit mehr als 10 Kernen eine Kontingenterhöhung beantragt werden. Microsoft hat das wirklich einfach gemacht. Nachdem ich zu einem kostenpflichtigen Konto gewechselt war, erhielt ich die Genehmigungsbestätigung, bevor ich meine Antwort im Ticket abschließen konnte, in der ich erklärte, warum ich die Erhöhung beantrage.
Datenbank
Bei der Auswahl der Instanzgröße habe ich versucht, die Spezifikationen der auf AWS und Google Cloud verwendeten Instanzen abzugleichen:
- vCPU:8
- RAM:80 GiB (maximal)
- Speicher:6000 IOPS (2 TiB Größe bei 3 IOPS/GB)
- Netzwerk:2.000 MB/s
Die geringe Arbeitsspeichergröße ergibt sich aus der Arbeitsspeicher-pro-vCore-Formel, die für die Arbeitsspeicherzuweisung verwendet wird:
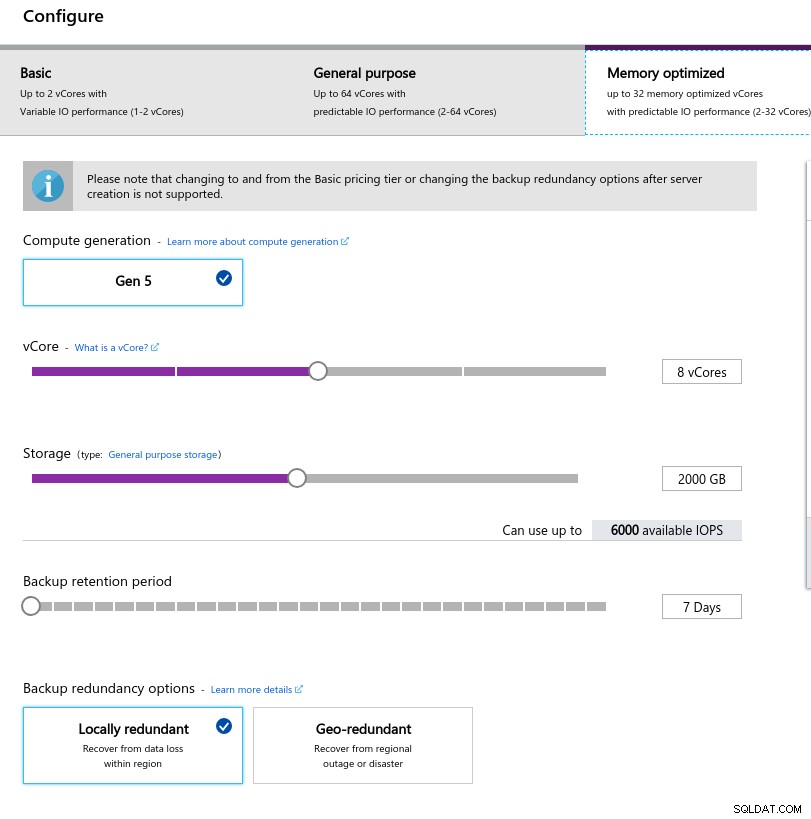 Konfiguration der Datenbankinstanz
Konfiguration der Datenbankinstanz Ähnlich wie bei Google Cloud und im Gegensatz zu AWS sind die IOPS umso höher, je größer der Speicher ist, mit einem Verhältnis von 3:1. Sobald die Größe jedoch 2 TiB erreicht, werden die IOPS auf 6000 IOPS begrenzt.
Benchmarks ausführen
Einrichtung
Die Einrichtung folgte dem in früheren Teilen der Blogserie beschriebenen Prozess, wobei der AWS pgbench-Timing-Patch für 11.1 sauber auf Azure PostgreSQL Version 10.7 angewendet wurde. Patches können auch aus den AWS Labs-Beiträgen zum PostgreSQL-Github-Repository bezogen werden.
Während der Ausführung der Benchmarks habe ich das folgende Skript verwendet, das nur dem Amazon-Leitfaden folgt und in diesem Fall auf die PostgreSQL-Version in Azure (10.7) zugeschnitten ist. Auf dem Clientcomputer wird CentOS 7.5 ausgeführt:
#!/bin/bash
set -eE
trap "exit 1" ERR
yum -y install \
wget ant git php gnuplot gcc make readline-devel zlib-devel \
postgresql-jdbc bzr automake libtool patch libevent-devel \
openssl-devel ncurses-devel
wget https://ftp.postgresql.org/pub/source/v10.7/postgresql-10.7.tar.gz
rm -rf postgresql-10.7
tar -xzf postgresql-10.7.tar.gz
cd postgresql-10.7
wget https://s3.amazonaws.com/aurora-pgbench-patches/pgbench-init-timing.patch
patch --verbose -p1 -b < pgbench-init-timing.patch
./configure
make -j 4 all
make install
cd ..
rm -rf sysbench
git clone -b 0.5 https://github.com/akopytov/sysbench.git
cd sysbench
./autogen.sh
CFLAGS="-L/usr/local/pgsql/lib/ -I /usr/local/pgsql/include/" \
| ./configure \
--with-pgsql \
--without-mysql \
--with-pgsql-includes=/usr/local/pgsql/include/ \
--with-pgsql-libs=/usr/local/pgsql/lib/
make
make install
cd sysbench/tests
make install
sed -i \
'/^export PGHOST=/,/^export LD_LIBRARY_PATH.*pgsql/d' \
~/.bashrc
cat << "__eot__" >> ~/.bashrc
export PGHOST=CHANGEME
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=/usr/local/pgsql/bin:/usr/local/bin:$PATH
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
__eot__
echo "All done."Bearbeiten Sie nach Abschluss des Skripts .bashrc, um die PostgreSQL-Umgebungsvariablen festzulegen. Azure ist in Bezug auf das Format des PostgreSQL-Benutzernamens eigenartig, indem es ein Format {Benutzername}@{Host} und nicht das allgegenwärtige {Benutzername}:
erwartet[example@sqldat.com scripts]# psql
psql: FATAL: Invalid Username specified. Please check the Username and retry connection. The Username should be in <example@sqldat.com> format.Vergewissern Sie sich vor Beginn der Tests, dass wir die richtige Version der Client-Tools verwenden:
[example@sqldat.com scripts]# psql --version
psql (PostgreSQL) 10.7[example@sqldat.com scripts]# pgbench --version
pgbench (PostgreSQL) 10.7[example@sqldat.com scripts]# sysbench --version
sysbench 0.5pgench
Initialisieren Sie die pgbench-Datenbank.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000…und einige Minuten später:
[example@sqldat.com scripts]# pgbench -i --fillfactor=90 --scale=10000
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.04 s, remaining 426.44 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 427.22 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.18 s, remaining 600.63 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.21 s, remaining 530.99 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.30 s, remaining 595.12 s)
...
584300000 of 1000000000 tuples (58%) done (elapsed 2421.82 s, remaining 1723.01 s)
584400000 of 1000000000 tuples (58%) done (elapsed 2421.86 s, remaining 1722.32 s)
584500000 of 1000000000 tuples (58%) done (elapsed 2422.81 s, remaining 1722.29 s)
584600000 of 1000000000 tuples (58%) done (elapsed 2422.84 s, remaining 1721.60 s)
584700000 of 1000000000 tuples (58%) done (elapsed 2422.88 s, remaining 1720.92 s)
584800000 of 1000000000 tuples (58%) done (elapsed 2425.06 s, remaining 1721.76 s)
584900000 of 1000000000 tuples (58%) done (elapsed 2425.09 s, remaining 1721.07 s)
585000000 of 1000000000 tuples (58%) done (elapsed 2425.28 s, remaining 1720.50 s)
...
999700000 of 1000000000 tuples (99%) done (elapsed 4142.69 s, remaining 1.24 s)
999800000 of 1000000000 tuples (99%) done (elapsed 4142.95 s, remaining 0.83 s)
999900000 of 1000000000 tuples (99%) done (elapsed 4142.98 s, remaining 0.41 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 4143.92 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 14805.73 s (insert 4146.94 s, commit 0.02 s, vacuum 6581.15 s, index 4077.61 s)
done.So weit, so gut.
Ein kurzer Blick in die Datenbank, um zu bestätigen, dass sie einsatzbereit ist:
example@sqldat.com:5432 postgres> \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Table space | Description
-------------------+-----------------+----------+----------------------------+----------------------------+-------------------------------------+-----------+------------+--------------------------------------------
azure_maintenance | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | azure_superuser=CTc/azure_superuser | No Access | pg_default |
azure_sys | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | | 12 MB | pg_default |
postgres | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | | 160 GB | pg_default | default administrative connection database
template0 | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | =c/azure_superuser +| 7865 kB | pg_default | unmodifiable empty database
| | | | | azure_superuser=CTc/azure_superuser | | |
template1 | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | =c/azure_superuser +| 7865 kB | pg_default | default template for new databases
| | | | | azure_superuser=CTc/azure_superuser | | |
(5 rows)Da Azure keine Änderung von max_connections zulässt und das Limit für die ausgewählte Instanz auf 960 begrenzt ist, müssen wir die Anzahl der pgbench-Clients entsprechend anpassen:
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=950 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
could not translate host name "postgresql-10-7.postgres.database.azure.com" to address: Name or service not known
connection to database "postgres" failed:
could not translate host name "postgresql-10-7.postgres.database.azure.com" to address: Name or service not knownUnd da ist er, der erste Schluckauf.
Eine schnelle Überprüfung der Host-DNS-Auflösung zeigt keine Probleme:
[example@sqldat.com scripts]# dig +short $PGHOST
cr1.eastus1-a.control.database.windows.net.
191.238.6.43[example@sqldat.com scripts]# cat /etc/resolv.conf
; generated by /usr/sbin/dhclient-script
search 11jv1qvdjs5utlhtlyb5vdyeth.bx.internal.cloudapp.net
nameserver 168.63.129.16Eine Überprüfung meines Bildschirmprotokolls zeigt, dass fast die Hälfte der Verbindungen beendet wurden:
~$ cat screenlog.1 | nl | grep 'could not translate host name "postgresql-10-7.*Name or service not known' | wc -l
469pg_stat_activity erzählt eine detailliertere Geschichte – wir erreichen einen Spitzenwert von 950 Verbindungen:
example@sqldat.com:5432 postgres> select now(), count(*) from pg_stat_activity where usename = 'postgres' and application_name = 'pgbench'; now | count
-------------------------------+-------
2019-05-03 23:39:18.200291+00 | 950
(1 row)…die Überwachung der obigen Abfrage zeigt jedoch einen plötzlichen Rückgang der Anzahl der Verbindungen von 950 auf 628 in nur 10 Sekunden:
example@sqldat.com:5432 postgres> \watch 10
Fri 03 May 2019 11:41:05 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:41:05.044025+00 | 950
(1 row)
...
Fri 03 May 2019 11:43:10 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:43:10.512766+00 | 950
(1 row)
Fri 03 May 2019 11:43:20 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:43:17.419011+00 | 628
(1 row)
Fri 03 May 2019 11:43:30 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:43:31.434638+00 | 613
(1 row)Um das DNS-Problem zu umgehen, habe ich PGHOST die Host-IP-Adresse zugewiesen:
[example@sqldat.com scripts]# set | grep PG
PGDATABASE=postgres
PGHOST=191.238.6.43
example@sqldat.com
PGPORT=5432
example@sqldat.comMit dieser Problemumgehung habe ich den Test neu gestartet:
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=950 --jobs=2048
starting vacuum...end.
progress: 61.1 s, 457.7 tps, lat 559.138 ms stddev 1755.888
progress: 120.1 s, 78.8 tps, lat 3883.772 ms stddev 10551.545
progress: 180.1 s, 17.6 tps, lat 50831.708 ms stddev 31214.512
progress: 240.1 s, 15.2 tps, lat 42474.763 ms stddev 32702.050
progress: 300.1 s, 16.1 tps, lat 43584.559 ms stddev 29818.142
progress: 360.1 s, 26.5 tps, lat 36914.096 ms stddev 37152.588
progress: 420.0 s, 33.4 tps, lat 27542.926 ms stddev 37075.457
progress: 480.0 s, 20.2 tps, lat 47149.060 ms stddev 47087.474
progress: 540.0 s, 13.5 tps, lat 55609.260 ms stddev 60394.287
progress: 600.0 s, 36.5 tps, lat 49566.853 ms stddev 99155.598
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 950
number of threads: 950
duration: 600 s
number of transactions actually processed: 44293
latency average = 12493.888 ms
latency stddev = 40490.231 ms
tps = 60.907130 (including connections establishing)
tps = 64.213520 (excluding connections establishing)Auf den ersten Blick schien alles gut gelaufen zu sein, aber die extrem hohen Latenzwerte, gepaart mit den vorherigen DNS-Problemen und dem „Accelerated Networking“-fähigen Client, deuten darauf hin, dass auf Netzwerkebene etwas nicht stimmt, und das ist sehr wahrscheinlich Ursache für niedrige tps-Ergebnisse. Aber das Schlimmste steht uns noch bevor.
Laden Sie noch heute das Whitepaper PostgreSQL-Verwaltung und -Automatisierung mit ClusterControl herunterErfahren Sie, was Sie wissen müssen, um PostgreSQL bereitzustellen, zu überwachen, zu verwalten und zu skalierenLaden Sie das Whitepaper heruntersysbench
Erstellen Sie zuerst die Tabellen:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepare
After a little while:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
FATAL: PQexec() failed: 7 server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
FATAL: failed query: CREATE TABLE sbtest1 (
id SERIAL NOT NULL,
k INTEGER DEFAULT '0' NOT NULL,
c CHAR(120) DEFAULT '' NOT NULL,
pad CHAR(60) DEFAULT '' NOT NULL,
PRIMARY KEY (id)
)
FATAL: failed to execute function `prepare': 3Das sah überhaupt nicht gut aus, also habe ich die PostgreSQL-Protokolle überprüft:
2019-05-03 23:51:12 UTC-5ccbbe4f.88-WARNING: worker took too long to start; canceled
2019-05-03 23:51:14 UTC-5ccbbe4f.84-PANIC: could not write to log file 000000010000001F000000CD at offset 13664256, length 8192: Invalid argument
+++ NT HARD ERROR (0xd0000144) +++
Parameter 0: 0xffffffffc0000005
Parameter 1: 0x1b80f0f73b
Parameter 2: 0x1
Parameter 3: 0x0Obwohl sich der Dienst von selbst wiederherstellen sollte, habe ich mich entschieden, die Instanz neu zu starten, um den Vorgang zu beschleunigen.
2019-05-04 00:43:23 UTC-5ccce02a.2c-HINT: Is another postmaster already running on port 20108? If not, wait a few seconds and retry.
2019-05-04 00:43:23 UTC-5ccce02a.2c-LOG: could not bind IPv6 address "::": A socket operation was attempted to an unreachable host.
2019-05-04 00:43:23 UTC-5ccce02a.2c-LOG: listening on IPv4 address "0.0.0.0", port 20108
2019-05-04 00:43:24 UTC-5ccce02a.2c-LOG: database system is ready to accept connections
...
2019-05-05 00:03:35 UTC-5cce2856.2c-HINT: Is another postmaster already running on port 20326? If not, wait a few seconds and retry.
2019-05-05 00:03:35 UTC-5cce2856.2c-LOG: could not bind IPv6 address "::": A socket operation was attempted to an unreachable host.
2019-05-05 00:03:35 UTC-5cce2856.2c-LOG: listening on IPv4 address "0.0.0.0", port 20326
2019-05-05 00:03:38 UTC-5cce285a.3c-FATAL: the database system is starting up
2019-05-05 00:03:38 UTC-5cce285a.3c-LOG: connection received: host=127.0.0.1 port=47247 pid=60
2019-05-05 00:03:49 UTC-5cce2865.40-FATAL: the database system is starting up
2019-05-05 00:03:49 UTC-5cce2865.40-LOG: connection received: host=127.0.0.1 port=47284 pid=64
2019-05-05 00:03:59 UTC-5cce286f.44-FATAL: the database system is starting up
2019-05-05 00:03:59 UTC-5cce286f.44-LOG: connection received: host=127.0.0.1 port=47312 pid=68
2019-05-05 00:04:00 UTC-5cce2856.2c-LOG: database system is ready to accept connections
2019-05-05 00:04:00 UTC-5cce2870.38-LOG: database system was shut down at 2019-05-05 00:03:34 UTCAn dieser Stelle habe ich auch Einblicke in die Abfrageleistung aktiviert:
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: parameter "pgms_wait_sampling.query_capture_mode" changed to "ALL"
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: parameter "pg_qs.query_capture_mode" changed to "TOP"
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: received SIGHUP, reloading configuration files
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: received SIGHUP, reloading configuration files
2019-05-05 00:04:13 UTC-5cce287a.6c-ERROR: database "azure_sys" already exists
2019-05-05 00:04:13 UTC-5cce287a.6c-STATEMENT: CREATE DATABASE azure_sys TEMPLATE template0Bevor ich die Sysbench-Aufgabe neu starte, wollte ich sicherstellen, dass die Datenbank fehlerfrei ist, und deshalb habe ich einen zweiten pgbench-Test gestartet:
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=950 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.Laut dem pg_stat_activity-Abfragemonitor starb der Server, als die Anzahl der Verbindungen 710 erreichte:
example@sqldat.com:5432 postgres> \watch 1
Sun 05 May 2019 12:44:11 AM UTC (every 1s)
now | count
-------------------------------+-------
2019-05-05 00:44:11.010413+00 | 220
(1 row)
Sun 05 May 2019 12:44:12 AM UTC (every 1s)
now | count
-------------------------------+-------
2019-05-05 00:44:12.041667+00 | 231
(1 row)
...
now | count
------------------------------+-------
2019-05-05 00:47:33.16533+00 | 710
(1 row)
Sun 05 May 2019 12:47:40 AM UTC (every 1s)
now | count
-------------------------------+-------
2019-05-05 00:47:40.524662+00 | 710
(1 row)Und aus PostgreSQL-Protokollen erfahren wir, dass etwas entlang der Verbindungsleitung passiert ist:
2019-05-05 00:44:11 UTC-5cce31da.c60-LOG: connection received: host=40.114.85.62 port=50925 pid=3168
2019-05-05 00:44:11 UTC-5cce31db.c58-LOG: connection received: host=40.114.85.62 port=55256 pid=3160
2019-05-05 00:44:11 UTC-5cce31db.c5c-LOG: connection received: host=40.114.85.62 port=34526 pid=3164
2019-05-05 00:44:11 UTC-5cce31db.c64-LOG: connection received: host=40.114.85.62 port=1178 pid=3172
...
2019-05-05 00:47:32 UTC-5cce329a.146c-LOG: connection received: host=40.114.85.62 port=41769 pid=5228
2019-05-05 00:47:33 UTC-5cce3287.1404-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce3288.1428-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce3289.1434-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce3291.1448-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce32a3.1484-LOG: connection received: host=40.114.85.62 port=50296 pid=5252
2019-05-05 00:47:33 UTC-5cce32a5.1488-LOG: connection received: host=40.114.85.62 port=28304 pid=5256
2019-05-05 00:47:39 UTC-5cce31d2.a24-LOG: could not send data to client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce31d5.ae8-LOG: could not receive data from client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce31e3.ee4-LOG: could not send data to client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce31e9.1054-LOG: could not receive data from client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce3291.1444-LOG: could not receive data from client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:40 UTC-5cce31cd.8ec-LOG: could not send data to client: An existing connection was forcibly closed by the remote host.Konfrontiert mit der Einschränkung in max_connections und den Problemen, die bei pgbench- und sysbench-Tests aufgetreten sind, begann ich neugierig zu werden, ob eine 16-Core-Datenbank das gleiche Verhalten zeigen würde.
16-Core-Datenbankinstanz
Auf einer 16-Core-Datenbankinstanz ist das max_connections-Limit ausreichend groß, um 1000 Clients aufzunehmen:
example@sqldat.com:5432 postgres> show max_connections ;
max_connections
-----------------
1900
(1 row)Dadurch konnte ich die gleichen Benchmark-Befehle wie bei den vorherigen Cloud-Anbietern ausführen.
Der Benchmark wurde erfolgreich abgeschlossen und die Ergebnisse werden unten angezeigt:
pgbench
- Initialisierung:
[example@sqldat.com scripts]# pgbench -i --fillfactor=90 --scale=10000 NOTICE: table "pgbench_history" does not exist, skipping NOTICE: table "pgbench_tellers" does not exist, skipping NOTICE: table "pgbench_accounts" does not exist, skipping NOTICE: table "pgbench_branches" does not exist, skipping creating tables... 100000 of 1000000000 tuples (0%) done (elapsed 0.08 s, remaining 807.39 s) 200000 of 1000000000 tuples (0%) done (elapsed 0.13 s, remaining 628.37 s) 300000 of 1000000000 tuples (0%) done (elapsed 0.16 s, remaining 527.89 s) ... 600100000 of 1000000000 tuples (60%) done (elapsed 2499.90 s, remaining 1665.90 s) 600200000 of 1000000000 tuples (60%) done (elapsed 2500.07 s, remaining 1665.33 s) ... 999900000 of 1000000000 tuples (99%) done (elapsed 4170.91 s, remaining 0.42 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 4171.29 s, remaining 0.00 s) vacuum... set primary keys... total time: 13701.50 s (insert 4173.33 s, commit 0.05 s, vacuum 7098.74 s, index 2429.39 s) done. - Run:
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048 starting vacuum...end. progress: 81.4 s, 5639.1 tps, lat 80.094 ms stddev 73.213 progress: 120.0 s, 4091.0 tps, lat 224.161 ms stddev 608.523 progress: 180.0 s, 6932.1 tps, lat 145.143 ms stddev 228.925 progress: 240.0 s, 7287.9 tps, lat 136.521 ms stddev 156.643 progress: 300.0 s, 7567.8 tps, lat 132.722 ms stddev 158.754 progress: 360.0 s, 8077.9 tps, lat 123.801 ms stddev 139.033 progress: 420.0 s, 6076.9 tps, lat 163.886 ms stddev 201.121 progress: 480.0 s, 5376.2 tps, lat 186.678 ms stddev 191.270 progress: 540.0 s, 4864.0 tps, lat 205.696 ms stddev 164.261 progress: 600.0 s, 3759.3 tps, lat 266.073 ms stddev 542.717 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 3614386 latency average = 152.935 ms latency stddev = 248.593 ms tps = 6002.082008 (including connections establishing) tps = 6513.306467 (excluding connections establishing)
Das lief recht gut, aber es gibt keine gültige Möglichkeit, diese Ergebnisse mit denen von AWS und G Cloud zu vergleichen, da wir nicht auf einer ähnlichen Plattform testen. Aber das ist gut genug, um uns zum nächsten Punkt zu bringen.
sysbench
Als die pgbench-Tests erfolgreich abgeschlossen wurden, entschied ich mich, das Azure-Guthaben von 200 $ voll auszuschöpfen und zu bestätigen, dass sysbench weiter kommt als der vorherige Lauf auf der 8-Core-Instanz:
sysbench \
--test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=191.238.6.43 \
--pgsql-db=postgres \
example@sqldat.com \
example@sqldat.com \
--pgsql-port=5432 \
--oltp-tables-count=250 \
--oltp-table-size=450000 prepare
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
Creating secondary indexes on 'sbtest2'...
Creating table 'sbtest3'...
Inserting 450000 records into 'sbtest3'
Creating secondary indexes on 'sbtest3'...
Creating table 'sbtest4'...Das schien gut zu funktionieren, und da ich mich meinem Budget näherte, beschloss ich, die Aufgabe zu beenden.
Hyperscale (Citus)
Obwohl diese Option noch nicht produktionsbereit ist, sollte sie in Betracht gezogen werden, da sie erweiterte Funktionen bietet, die in AWS und G Cloud nicht verfügbar sind.
Als Ergebnis des Erwerbs von Citus Data bietet Microsoft eine Vorschauversion seines Flaggschiffprodukts PostgreSQL unter dem Namen Hyperscale (Citus) an.
Der Portalassistent macht die Einrichtung einer ansonsten komplizierten Umgebung zum Kinderspiel:
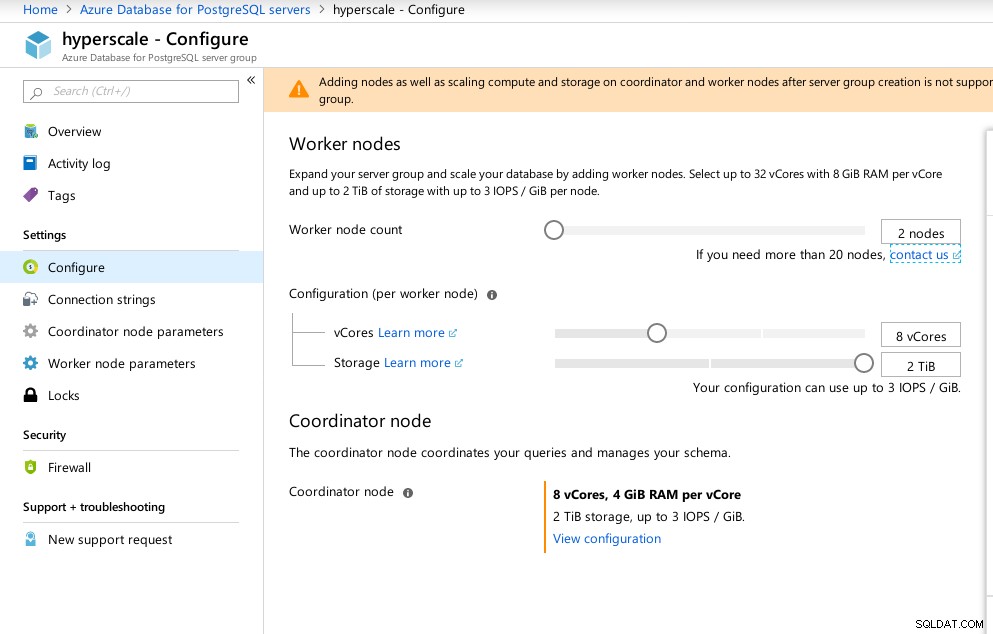 Azure Hyperscale (Citus)-Konfiguration
Azure Hyperscale (Citus)-Konfiguration Ich habe festgestellt, dass Hyperscale im Gegensatz zu Azure PostgreSQL, das unter Windows ausgeführt wird, unter Linux ausgeführt wird:
example@sqldat.com:5432 citus> select version();
version
----------------------------------------------------------------------------------------------------------------
PostgreSQL 11.2 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 5.4.0-6ubuntu1~16.04.5) 5.4.0 20160609, 64-bit
(1 row)Obwohl Hyperscale eine aufregende Reise versprach, konnte ich zu diesem Zeitpunkt leider nicht mit dem Ausführen der Tests fortfahren, da max_connections derzeit auf 300 begrenzt ist und keine Anpassungsoption besteht, obwohl die Fähigkeit für das native Citus PosgreSQL dokumentiert ist:
example@sqldat.com:5432 citus> show max_connections ;
max_connections
-----------------
300
(1 row)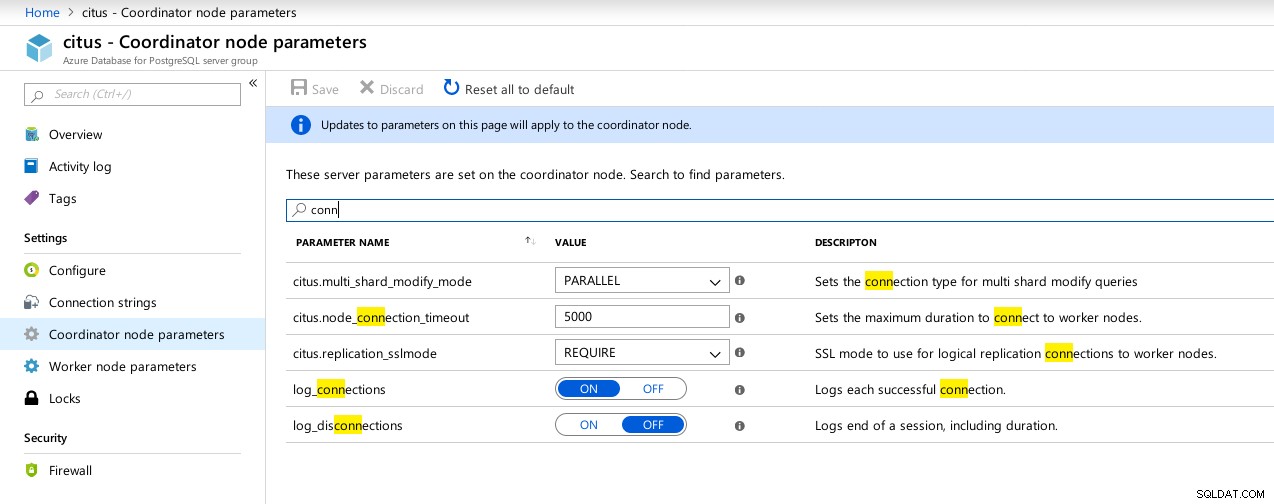 Verfügbare Parameter für Hyperscale (Citus) Coordinator-Verbindungen
Verfügbare Parameter für Hyperscale (Citus) Coordinator-Verbindungen 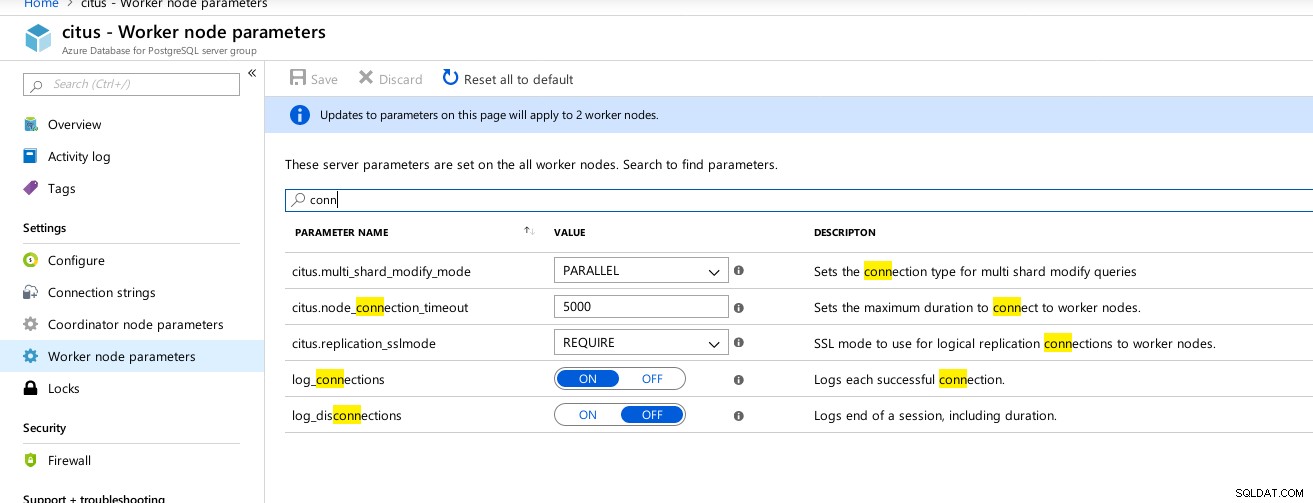 Hyperscale (Citus) Workers:max_connections nicht verfügbar
Hyperscale (Citus) Workers:max_connections nicht verfügbar Benchmark-Metriken
Einige Metriken, die die Leistung und das Verhalten von Clients und Servern angeben:
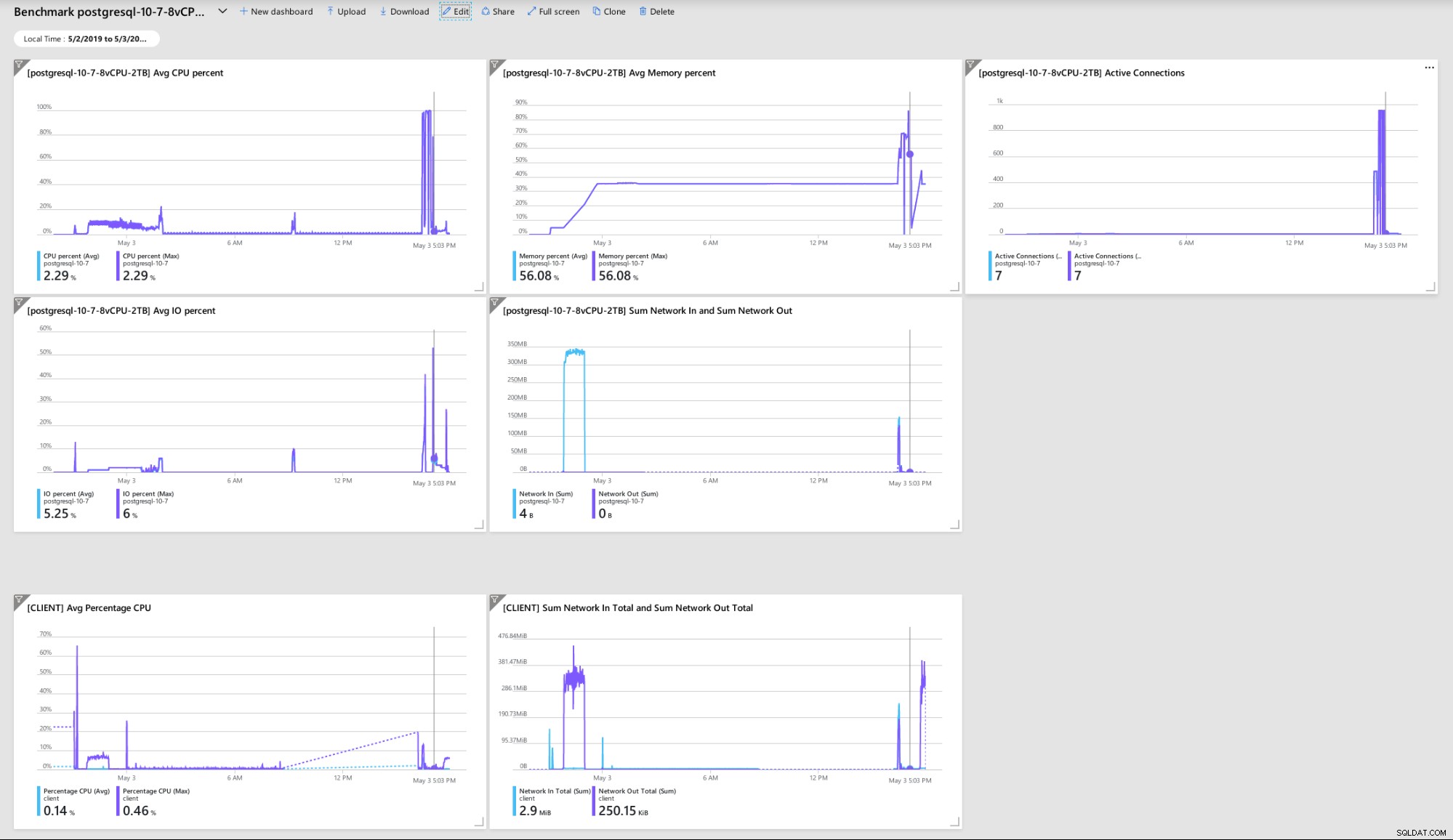 Azure Portal-Dashboard – Metriken für Client und Server
Azure Portal-Dashboard – Metriken für Client und Server PostgreSQL-Metriken, die mithilfe von Query Performance Insight erfasst wurden:
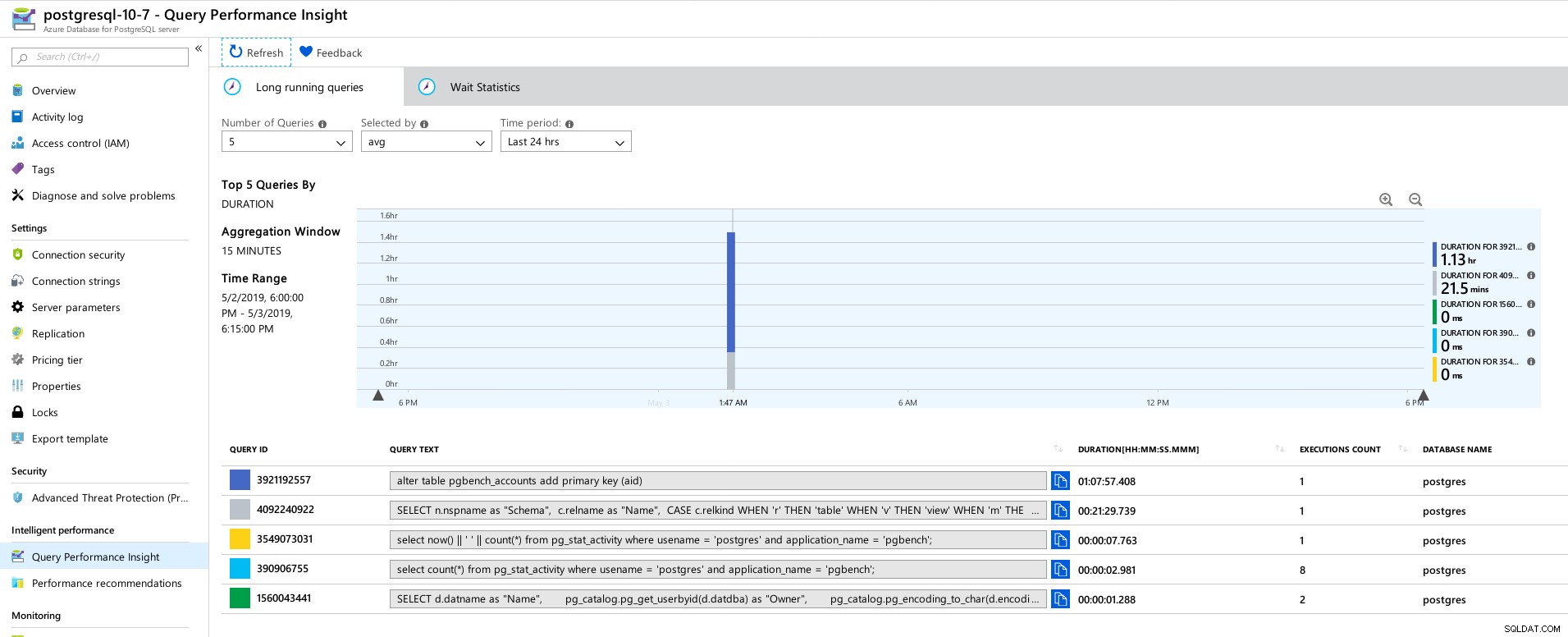 Azure PostgreSQL – Einblicke in die Abfrageleistung:Top 5 Abfragen
Azure PostgreSQL – Einblicke in die Abfrageleistung:Top 5 Abfragen 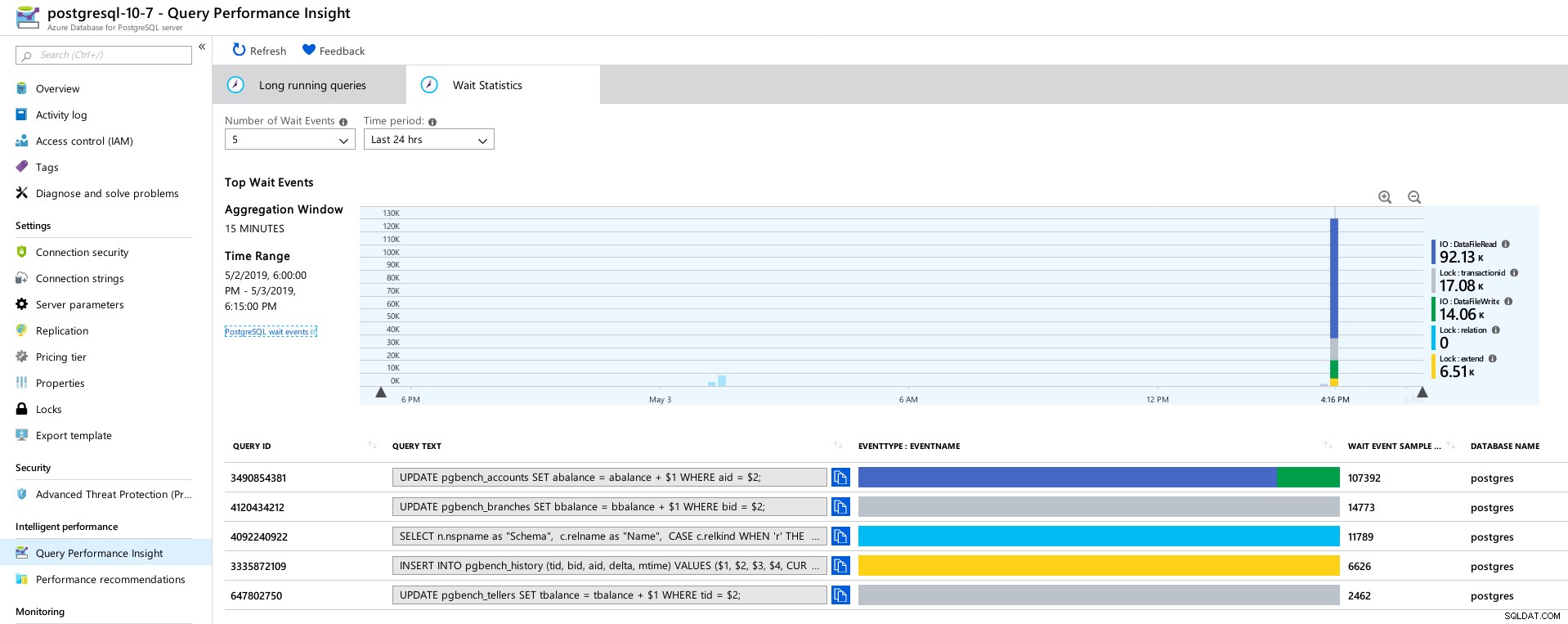 Azure PostgreSQL – Einblicke in die Abfrageleistung:Top 5 Wartezeiten
Azure PostgreSQL – Einblicke in die Abfrageleistung:Top 5 Wartezeiten Schlussfolgerung
Verwandte Ressourcen Benchmarking von verwalteten PostgreSQL-Cloud-Lösungen – Teil 1:Amazon Aurora Benchmarking von verwalteten PostgreSQL-Cloud-Lösungen – Teil 2:Amazon RDS Benchmarking von verwalteten PostgreSQL-Cloud-Lösungen – Teil 3:Google CloudErstens, wenn Sie es bis hierher geschafft haben, vielen Dank für das Lesen, und wenn Sie Fehler entdecken, die möglicherweise zu einem Fehlverhalten der Umgebung geführt haben, würde ich mich sehr über Ihr Feedback freuen. Vorausgesetzt, ich habe etwas Offensichtliches übersehen, bin ich bereit, die Tests zu wiederholen.
Der Absturz der Datenbank-Engine, der zum Hex-Dump „NT HARD ERROR“ führte, weist darauf hin, dass etwas außerhalb der Kontrolle des Benutzers passiert ist und ein guter verwalteter Dienst durch Automatisierung oder Benachrichtigung der zuständigen SREs wiederhergestellt werden würde. Hätte ich länger gewartet, hätte dies der Fall sein können, obwohl es die Frage aufwirft, wie lange Benutzer warten müssen, bis der Dienst wiederhergestellt ist.
Das Festlegen von max_connections auf einen Wert basierend auf der Preisstufe und virtuellen Kernen hat mich überrascht, insbesondere nachdem ich die drei anderen verwalteten Dienste getestet hatte, wobei Google Cloud die Konfiguration des Parameters durch den Benutzer zuließ, obwohl der Standardwert viel niedriger war (600 auf G Cloud vs. 960 auf Azure).
Möglicherweise ist ein Test mit der Datenbankinstanz im 16-Core-Bereich erforderlich, um eine Änderung der Standardwerte zu vermeiden, obwohl ich es zu diesem Zeitpunkt vorziehen würde, mit besseren Tools wie HammerDB zu testen (siehe Teil 1 für eine Diskussion der Tools). .